.png)


【摘要】AI市场热度与落地成功率形成巨大反差。问题的症结已从模型算法转向系统性架构。AI Infra正成为破解算力、协同与历史债务困局,连接AI创新与业务价值的核心引擎。
引言
生成式AI(GenAI)与大模型技术,正在驱动企业数智化转型。中国的AI基础设施市场随之爆发。IDC数据显示,2025年上半年,这一市场规模达到198.7亿元,同比增长122.4%,并预计在2029年逼近1500亿元。
数字的狂欢之下,是企业落地的普遍困境。Gartner的报告揭示了一个严峻现实,超过50%的AI项目因架构问题无法上线。赛迪顾问的数据更为具体,尽管83%的企业将AI列为战略优先级,但实际落地成功率仅有29%。
巨大的落差说明,AI规模化应用的瓶颈,已不再是单纯的算法或模型问题。真正的挑战,潜藏在水面之下——那个支撑着一切、却又常常被忽视的底层IT架构。 它像一个隐形的天花板,限制了企业AI创新的高度。本文将深入剖析企业在AI落地过程中面临的架构困局,并阐述AI Infra(AI基础设施平台)如何成为打破这一天花板的关键力量。
一、表象之下的裂痕:企业AI落地的三重困局
%20拷贝-cjst.jpg)
企业在AI落地过程中遇到的障碍,并非孤立的技术点缺陷,而是一个由历史、组织和认知共同交织而成的系统性难题。我们可以将其归结为架构、流程与认知三个维度的困局。
1.1 架构之困:历史债务与资源孤岛
企业的IT系统是持续演进的,而非一蹴而就。这种演进过程留下了沉重的“历史技术债务”,在AI时代集中爆发。
1.1.1 多代际IT架构的叠加效应
多数企业的IT环境是一个复杂的多代同堂结构。从最早的物理服务器,到后来的虚拟化集群(如VMware),再到近年的云原生容器化平台(如Kubernetes),以及为AI而生的GPU/NPU异构计算节点。每一代技术都解决了当时的问题,但也形成了独立的管理平面和资源池。
这种叠加效应导致了架构的复杂性与割裂。数据和服务在不同代际的架构之间流转不畅,形成了一个个技术壁垒。
1.1.2 算力资源的碎片化现实
多代际架构的直接后果就是算力资源的严重碎片化。IDC的《2025企业算力管理报告》指出,制造企业平均拥有4.2个独立的算力池。这些算力池之间缺乏统一的视图和调度能力,导致资源利用率低下。
具体表现为:
跨池调度效率低下:报告显示,跨池调度效率仅为28%。当一个AI训练任务需要大量GPU资源时,系统无法智能地从其他空闲的、不同类型的资源池中调度算力,造成“旱的旱死,涝的涝死”。
升级跟不上迭代:67%的制造企业坦言,其算力与存储的升级速度,远远跟不上大模型迭代的步伐。当需要为新模型扩容GPU集群时,往往要面临复杂的网络、存储和管理系统的重新规划。
算力缺口加剧:Gartner预测,到2025年,全球AI训练算力缺口将达到42%,中国市场的这一比例更是高达55%。在供给侧紧张的背景下,存量算力的低效使用无疑是雪上加霜。
1.1.3 紧耦合设计的迭代枷锁
为了追求项目快速上线,很多企业在初期采用了紧耦合的AI架构。根据统计,53%的企业将模型训练、推理服务与具体的业务系统直接绑定。这种“一次性搭建”的模式,在项目PoC(概念验证)阶段或许高效,但进入规模化迭代阶段后,其弊端便暴露无遗。
模型更新困难:当需要升级AI模型时,由于与业务逻辑深度绑定,整个应用系统可能都需要重新开发、测试和部署,流程漫长且风险高。
技术栈锁定:紧耦合架构使得更换底层的推理引擎、计算框架或硬件变得异常困难,企业被锁定在特定的技术栈上,无法享受技术进步带来的红利。
可复用性差:为特定业务场景开发的AI能力,很难被抽象和复用至其他业务线,造成重复建设和资源浪费。
1.2 流程之困:组织惯性与协同失灵
技术架构的问题,往往会映射为组织与流程的混乱。
1.2.1 IT与业务的“三重矛盾”
在当前的转型压力下,企业IT部门普遍陷入了林源所描述的“既要,又要,还要”的三重矛盾之中。
这三重矛盾让IT部门疲于奔命,常常在“救火”和“创新”之间挣扎,难以形成有效的技术战略和执行力。
1.2.2 中心与边缘的协同鸿沟
随着AI推理任务向边缘设备下沉,企业需要同时管理数据中心的训练集群和分布广泛的边缘计算节点。然而,中心与边缘的协同调度能力严重不足。赛迪顾问的数据显示,仅有19%的企业实现了中心与边缘算力的协同调度。
这种脱节导致:
模型部署与更新效率低:无法自动化、批量化地将云端训练好的新模型推送到成千上万的边缘节点。
数据闭环链路不畅:边缘端产生的数据和推理结果,难以高效、安全地回传至中心进行再训练,阻碍了模型的持续优化。
运维管理复杂:需要维护两套甚至多套独立的管理体系,运维成本高昂。
1.3 认知之困:从技术验证到体系化转型的跨越
许多企业对AI落地的认知,仍停留在“技术尝鲜”或PoC阶段。他们关注的是某个模型的精度、某个算法的性能,而忽视了支撑其规模化运行的底层体系。
当DeepSeek等开源模型的爆发,让企业意识到AI可以真正深入业务时,这种认知偏差的后果便显现出来。企业发现,将一个在实验室跑通的模型,部署到生产环境中并服务于成千上万的用户,完全是两码事。这不再是一个算法问题,而是一个涉及算力供给、数据治理、系统协同、安全合规的系统工程问题。
从PoC到规模化,企业需要完成一次关键的认知跃迁,即从关注“单点技术”,转向构建“企业级AI架构与治理体系”。而历史遗留的架构碎片和组织流程障碍,正是完成这次跨越的最大阻碍。
二、破局之道:AI Infra作为连接未来的“桥梁”
面对上述困局,业界逐渐形成共识,需要一座能够衔接历史IT与未来AI的“桥梁”。AI Infra(AI Infrastructure Platform)应运而生。赛迪顾问将2025年定义为“中国AI Infra平台应用元年”,标志着其已从概念走向规模化实践。
AI Infra并非简单的硬件堆砌,而是一个软件定义的、标准化的基础设施平台。其核心价值在于通过四大能力,解决企业的三重矛盾。
2.1 AI Infra的核心价值主张
AI Infra的根本目标,是屏蔽底层异构硬件和复杂环境的差异,为上层AI应用提供统一、标准、弹性的资源供给与服务。
2.1.1 从“资源孤岛”到“一体化平台”
AI Infra通过三大技术路径,将碎片化的算力资源整合为统一的平台。
全域调度:将企业内部的通算(CPU)、智算(GPU/NPU)、超算,乃至中心和边缘的算力资源,通过统一的调度层进行纳管,形成一个逻辑上的“超级算力池”。
弹性伸缩:基于云原生技术,实现资源的按需分配和动态扩容。当AI任务来临时,平台能秒级拉起所需资源;任务结束后,资源立即释放,极大提升利用效率。
能效优化:通过智能调度算法,综合考虑任务特性、硬件能效和电力成本等因素,将任务分配到最合适的计算节点,实现绿色低碳运营。
2.1.2 实现“降本、提效、安全、可控”的闭环
AI Infra的最终价值,体现在为企业带来的商业回报上。
2.2 关键技术路径解析
要实现上述价值,AI Infra在技术层面依赖于几大关键路径的突破。
2.2.1 全域算力调度与异构兼容
这是AI Infra的基石。平台需要能够屏蔽底层不同品牌、不同架构芯片的差异。
统一调度核心:基于云原生技术(特别是Kubernetes)的统一调度平台成为核心。通过算力标签(如
gpu-model=A100,interconnect=nvlink)和性能预测模型,调度器能够精准地将AI任务与最匹配的硬件资源进行匹配。异构芯片整合:AI Infra需要内置对主流异构芯片(如NVIDIA GPU、Google TPU、AMD DCU)的驱动和管理能力。更重要的是,它为国产化算力提供了一个统一的承载平台。
华为昇腾910B:已实现千亿参数大模型的稳定训练。
寒武纪CMX-9:以15瓦的低功耗实现64TOPS算力,适配边缘推理场景。
燧原科技:在庆阳部署的国产异构智算中心,单集群算力达100PFLOPS,成本较进口方案降低35%,成为“东数西算”的示范项目。
通过AI Infra,企业可以在不改变上层应用的情况下,平滑地引入和使用这些国产化算力,实现自主可控。
2.2.2 云原生驱动的解耦与进化
云原生技术为解决紧耦合问题提供了最佳方案。AI Infra深度融合了容器、微服务、服务网格(Service Mesh)等云原生理念,推动架构的现代化演进。
其核心是实现模型、推理引擎与业务应用的彻底解耦。
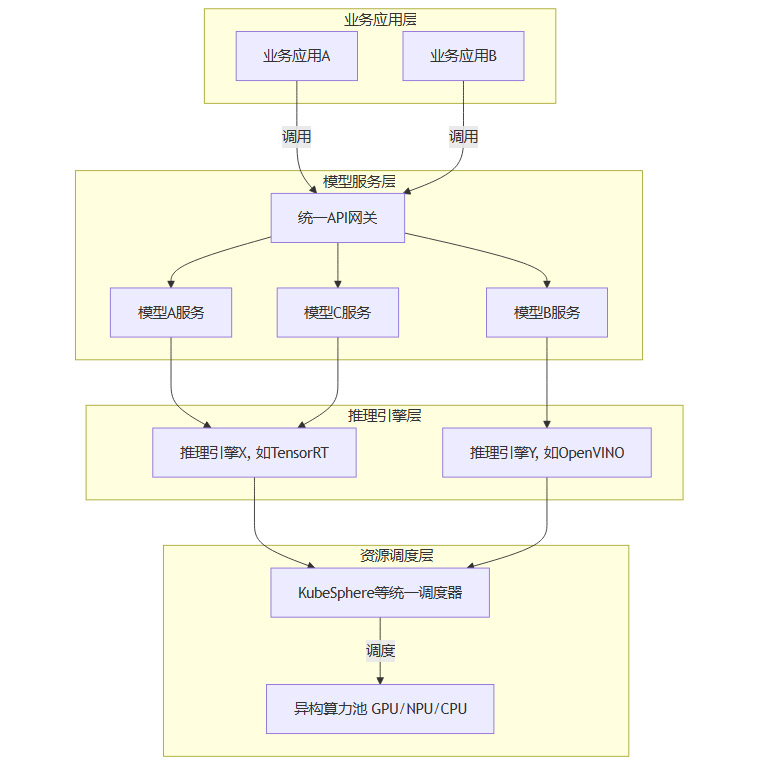
图1:基于AI Infra的解耦架构示意图
这种解耦架构带来了巨大的灵活性:
独立升级:模型团队可以随时更新
模型A,而无需触碰业务应用A或底层的推理引擎X。按需选择:业务应用可以根据需求,灵活选择最适合的推理引擎,以达到性能或成本的最优。
渐进式演进:企业可以在不推倒重来的前提下,将老旧的、单体的业务系统,逐步改造为基于模型服务的现代化应用。
2.2.3 统一的数据治理与安全体系
AI的生命周期与数据紧密相连。AI Infra必须提供平台级的、贯穿始终的数据治理与安全能力。
统一元数据管理:对所有接入平台的数据进行统一的元数据注册和管理,实现数据的可发现、可理解。
全流程安全机制:提供从数据接入、清洗、标注,到模型训练、部署、推理的全流程数据脱敏、权限管控、加密传输和访问审计。
合规性保障:内置数据水印、血缘追溯等功能,满足GDPR、数据安全法等国内外合规要求。
三、行胜于言:AI Infra的实践范式与业务成效
%20拷贝-jxpp.jpg)
理论的先进性,最终需要通过实践来检验。国内外的先行企业和技术服务商,已经探索出了一套行之有效的AI Infra实践范式,并取得了显著的业务成效。
3.1 平台架构范式:分层解耦与统一调度
成功的AI Infra平台,通常采用分层解耦的架构,以实现最大的灵活性和可扩展性。以青云科技的AI Infra 3.0架构为例,其设计思想颇具代表性。
内核层(PrimusOS):这是最底层,负责屏蔽物理硬件的差异,将不同品牌、不同代际的服务器、存储、网络设备虚拟化为标准的资源。
调度层(KubeSphere):这是平台的核心大脑,基于Kubernetes构建,实现了对通算、超算、智算的全域统一调度。它向上层提供标准的容器、虚拟机、裸金属等资源交付能力。
服务层:在统一调度层之上,可以按需部署和组合不同的能力组件,如完整的虚拟化能力、全栈云能力、云原生能力以及AI智算能力(模型训练、推理服务等)。
这种“桥梁式架构”的最大优势在于,它尊重了企业的历史投资。企业原有的虚拟化平台、云原生应用,都可以平滑地纳管到这个统一平台中,与新增的AI智算能力协同工作,而不是相互割裂。
3.2 行业落地案例剖析
AI Infra的价值,在不同行业中得到了具体的体现。
3.2.1 制造业:IT响应效率的跃迁
某大型制造企业,原先面临典型的多代际架构管理困境。管理虚拟化、云原生应用和智算平台需要三套独立的系统和流程,跨团队协调成本极高,内耗严重。
引入基于统一架构的AI Infra后,该企业实现了:
统一纳管:无论是数据存储分析、云原生应用部署,还是AI推理算力供给,都在一个平台上进行搭建和交付。
全链路自动化:IT部门响应业务部门需求的速度,从过去的平均1小时,大幅缩短到15分钟。
竞争力重塑:这不仅仅是IT效率的提升,更意味着业务部门可以更快地将创新想法付诸实践,直接转化为市场竞争力。
3.2.2 生物制药:研发周期的颠覆性压缩
一家生物制药公司,利用AI Infra架构中成熟的模型服务能力,快速对接专业的药物研发大模型。其采用的模型与推理引擎分离架构,使其能够为不同的分子设计任务,选择最优的推理引擎。
最终实现的业务成果是:
新药研发加速:将新型药物的分子设计周期,从18个月压缩至12个月。
材料模拟提效:将高性能复合材料的微观结构模拟时间,从72小时缩短到43小时。
这些案例清晰地表明,底层架构的优化,能够直接转化为核心业务指标的改善。
3.3 量化价值评估
IDC在其《2025 AI Infra价值评估报告》中,对部署了新一代AI Infra的企业进行了量化评估,结果令人振奋。
数据不会说谎。对底层架构的投资,是企业AI战略中回报率最高的环节之一。
四、群雄逐鹿:AI Infra的产业格局与竞赛
AI Infra的战略价值和巨大的市场潜力,已经引发了全球科技厂商的激烈角逐。Dell'OroGroup预测,2025年全球AI Infra市场规模将突破800亿美元,年复合增长率(CAGR)高达58%。在这片蓝海中,一个多元化、多层次的竞争格局正在形成。
4.1 国内市场:三类玩家与本土化优势
中国市场因其独特的政策环境(如信创)、庞大的应用场景和对成本的高度敏感,催生了具有鲜明本土特色的三类玩家。他们围绕“信创适配、架构整合、成本控制”三大核心需求展开竞争。
4.1.1 全栈型玩家:从芯到云的垂直整合
这类玩家试图提供从底层芯片到上层应用的全栈式解决方案,构建强大的技术壁垒和生态护城河。
青云科技:以其独特的“桥梁式架构”为核心竞争力,通过PrimusOS内核层与KubeSphere调度层的结合,专注于解决企业多代际架构整合的痛点,强调平滑演进和历史投资保护。
华为:依托其昇腾(Ascend)系列AI芯片,构建了从“芯片-CANN(异构计算架构)-MindSpore(AI框架)-ModelArts(AI开发平台)-应用”的垂直全栈能力。其昇腾910B芯片已成为支撑国内千亿参数大模型训练的核心力量。
阿里云:凭借其强大的公共云规模优势和深厚的生态整合能力,其灵骏AI集群支持千卡规模的并行训练,GPU弹性算力的响应时间已缩短至5分钟以内。其服务于比亚迪等车企,将自动驾驶模型训练周期缩短了50%。
4.1.2 垂直技术型玩家:单点突破的尖兵
这类玩家聚焦于AI Infra链条中的某个关键环节,通过技术深耕建立起难以逾越的优势。
浪潮信息:作为全球领先的AI服务器供应商,其全球市占率高达47%。在硬件工程能力上优势显著,其先进的液冷技术可将数据中心的PUE(电源使用效率)降至1.15,为某智算中心年均节省电费280万元。2025年第一季度,其AI服务器出货量同比增长62%,稳居全球第一。
燧原科技:作为国产GPU的代表企业,其云燧T20 GPU已适配超过100个主流AI模型。在庆阳异构智算中心项目中,其方案不仅实现了100PFLOPS的算力规模,更将成本较进口方案降低了35%,在政务、金融等信创关键领域的渗透率已达18%。
4.1.3 生态整合型玩家:连接与赋能的平台
这类玩家自身可能不生产硬件,但擅长通过云平台和软件能力,整合各类资源,构建繁荣的应用生态。
腾讯云:以“云原生+Agent”为抓手,推动生态协同。其推出的国内首个跨型号GPU调度的Serverless平台,将模型启动速度提升了17倍。其Agent Infra解决方案支持数十万实例并发,服务于货拉拉等企业,将车路协同的响应时延降至15毫秒。
百度智能云:其战略核心是“云智一体”,将自家的文心一言大模型与千帆AI平台深度整合。这种模型与Infra的协同优化,为开发者提供了从模型开发到部署推理的一站式流畅体验。
4.2 国际市场:技术壁垒与生态垄断
与国内厂商相比,国际巨头在全球化布局、核心技术研发和开发者生态建设上仍保持领先。他们主要通过“云+自研芯片+顶级生态”的模式,构筑高端市场的壁垒。
微软Azure:通过与OpenAI的深度绑定,以及对NVIDIA最新技术的率先集成,占据了超大规模AI训练的制高点。Azure打造了全球首个NVIDIA GB300 NVL72集群,拥有超过4600颗Blackwell Ultra GPU,支持OpenAI进行超大规模推理。同时,其自研的Maia 100 AI芯片(5nm工艺)功耗较竞品降低30%,已部署于GPT-3.5 Turbo的推理服务。尽管技术领先,其在中国区市场的占有率仅为5%。
AWS:作为全球云计算的开创者和领导者,AWS凭借其模块化、高性价比和深厚的企业服务经验占有一席之地。其自研的第二代AI训练芯片Trainium2,性能是第一代的4倍,训练成本较同等性能的GPU方案可降低30-40%。其IoT Greengrass服务则将云端AI能力无缝扩展至边缘,与SageMaker云端训练平台形成闭环。
4.3 未来走向:双轨并行的市场格局
综合来看,未来3-5年,全球AI Infra市场将呈现清晰的“双轨并行”格局。
中国市场:国产化加速替代
赛迪顾问预测,中国市场的国产化率将从2025年的45%快速提升至2027年的65%。在政务、金融、电信等关系国计民生的关键领域,有望实现100%的国产化替代。本土厂商将在场景理解、成本控制和服务响应上持续保持优势。全球高端市场:巨头主导格局难撼
在需要极致性能的超大规模模型训练、前沿科学计算等领域,全球高端市场仍将由NVIDIA、微软、AWS等巨头主导,其市占率预计将保持在70%以上。核心芯片、基础软件和全球化生态是他们难以被轻易超越的护城河。
这场竞赛已经超越了单一产品的比拼,升级为“技术-生态-场景”的综合较量。对于国内厂商而言,在保持成本与场景优势的同时,必须在高端芯片、基础软件等核心技术上取得突破,才能在全球竞争中赢得一席之地。
五、行动指南:企业AI Infra落地路线图
%20拷贝-wpvq.jpg)
面对复杂的架构挑战和繁多的技术选项,企业应如何规划自己的AI Infra建设路径?这里提供一个可操作的、渐进式的落地路线图。
5.1 阶段一:诊断与规划 (Architecture Assessment)
在投入任何资源之前,首先要对现有IT基础设施进行一次全面的“架构体检”。
资产盘点:梳理企业内所有的计算、存储、网络资源,识别出不同代际、不同技术栈的“算力孤岛”。
瓶颈识别:分析当前AI项目在开发、部署、运维过程中遇到的具体瓶颈,是算力不足、数据不通,还是流程过慢?将问题量化。
短板评估:重点评估数据治理、安全合规、自动化运维等方面的短板,这些往往是规模化落地的最大障碍。
制定蓝图:基于诊断结果,明确AI Infra的建设目标。是优先统一调度,还是先解决数据治理?制定一个分阶段、可落地的演进蓝图。
5.2 阶段二:平台构建 (Platform Foundation)
这是技术实施的核心阶段,关键在于构建一个统一的、可扩展的底座。
建立统一调度面:这是最关键的一步。选择一个成熟的容器调度平台(如KubeSphere),将所有通算、GPU、边缘节点纳入统一管理,实现资源的集中可见、可调度。
推进模型-引擎-应用解耦:引入API网关和模型服务框架(如KServe),将AI能力以标准化的API服务形式暴露给业务应用,切断紧耦合的依赖。
强化数据治理与安全:部署统一的数据湖或数据平台,建立元数据管理、权限控制和安全审计机制,确保数据在平台内的流动是安全合规的。
5.3 阶段三:场景驱动与优化 (Scenario-driven Adoption)
平台建成后,应采用场景驱动的方式,逐步推广和优化。
选择试点场景:从业务价值高、技术耦合度低的场景入手,例如离线的报表分析、内部的智能客服等,进行首批应用的迁移和部署。
打通中心-边缘一体化:针对有边缘计算需求的场景(如智慧门店、智能制造产线),打通模型从云端训练到边缘部署、数据从边缘回传到云端优化的闭环链路。
建立度量体系:建立一套完善的度量体系,持续监控平台的资源利用率、任务成功率、业务响应时间等关键指标,用数据驱动平台的持续优化。
5.4 阶段四:组织协同与文化变革 (Organizational Enablement)
技术平台的成功,离不开组织和文化的支撑。
建立跨部门协同机制:成立由IT、数据、业务、安全等部门共同组成的虚拟团队(或称AI卓越中心CoE),共同推进AI Infra的建设和应用。
IT部门角色转型:推动IT部门从传统的“资源提供者”,向“平台化服务运营者”转型。IT团队需要提供稳定、易用、自动化的平台服务,赋能业务团队快速创新。
推广平台思维:在企业内部倡导“能力复用、服务共享”的平台思维,鼓励不同业务线基于AI Infra构建和分享自己的AI能力,避免重复造轮子。
结论
AI产业的狂奔,正将底层架构从幕后推向台前。过去被视为理所当然的基础设施,如今已成为决定企业AI战略成败的“隐形天花板”。企业在AI落地过程中面临的算力碎片化、新旧系统兼容、组织流程协同等三重困局,其根源都在于系统性的架构失衡。
单点的算法创新或模型引入,已无法应对规模化、敏捷性与合规性的复杂要求。AI Infra作为连接“历史与未来”的桥梁,通过统一调度、云原生解耦和平台化服务,为破解这一困局提供了系统性的解决方案。它正在成为企业智能转型的核心底座。
随着市场爆发与生态整合的加速,这场关于底层架构的变革已经全面展开。谁能率先理顺内部的IT基础,融通异构的系统,打通数据与安全的脉络,谁就能在这场智能化浪潮中,将AI的潜力真正转化为可持续的商业红利。企业必须正视这场转型,以AI Infra为载体,系统性地构筑一个可演进、可信赖的智能化未来。
📢💻 【省心锐评】
AI落地的核心矛盾已从“模型好不好”转向“架构行不行”。AI Infra不是选择题,而是必答题。它决定了企业AI创新的上限,是连接技术投入与商业价值的最短路径。

评论