.png)


两天前,Cloudflare,一家全球领先的网络基础设施公司,开始用AI对抗AI爬虫,这简直可以载入AI发展史册。

🌟 事情的起因
让我们先从一个乌克兰的小公司Triplegangers说起。这家公司只有7个人,专门卖3D数字模型。他们的网站上有65000个产品页面,每个页面都有高清照片和详细描述。然而,就在今年1月的一个普通周六早上,一场风暴打破了平静。
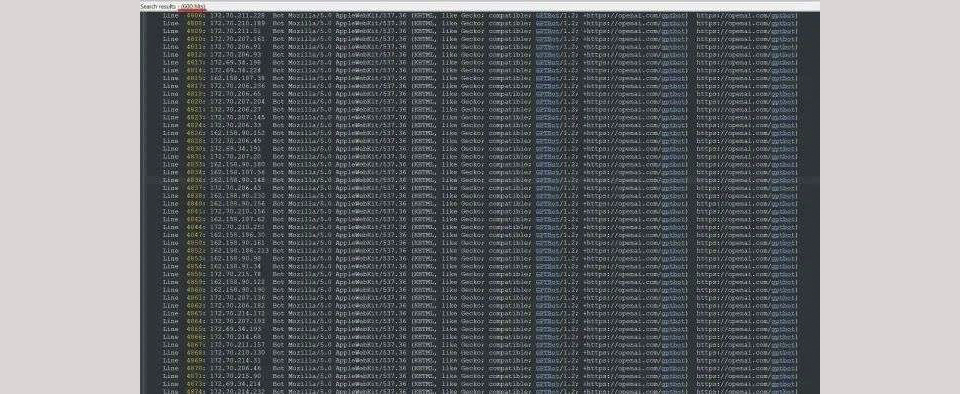
Triplegangers的创始人Tomchuk收到了一条紧急通知:公司网站崩溃了。经过调查,他发现是OpenAI的爬虫机器人GPTBot在疯狂爬取网站数据。这些爬虫使用了600个IP地址,导致服务器瞬间瘫痪。更糟糕的是,由于服务器压力暴涨,公司还面临巨额的AWS账单。
🔍 问题的根源
Triplegangers原本禁止爬虫未经许可抓取数据,但因为没有严格配置robot.txt文件,等于默认允许了OpenAI的抓取行为。几天后,Tomchuk终于设置好了robot.txt文件,并启用了Cloudflare服务来屏蔽更多爬虫。
📈 不只是Triplegangers
类似的事件也发生在其他公司。比如iFixit,一个老牌维修教程网站,被Anthropic公司的爬虫ClaudeBot疯狂访问,差点把网站挤爆。尽管iFixit明确禁止未经许可抓取内容用于AI训练,但ClaudeBot依然我行我素。
🤔 robots协议的尴尬
robots协议是一个君子协定,网站管理员可以在robots.txt文件中告诉爬虫哪些地方不能爬。长期以来,大多数搜索引擎都遵守这个协议。然而,现在许多AI爬虫为了获取数据,无视这一协议,即使网站明确禁止,他们仍然会强行爬取。
 🛡️ Cloudflare的反击
🛡️ Cloudflare的反击
在这种背景下,Cloudflare决定用AI对抗AI。他们为AI爬虫制造了一个迷宫,所有页面、链接和内容都是AI生成的虚假信息。这些迷宫对正常用户是隐形的,但AI爬虫会被引诱进去,白白浪费计算资源。

🏆 省心锐评
当大模型训练变成"数据零元购",Cloudflare的AI反制证明——魔法只能用魔法打败
