.png)
%20%E6%8B%B7%E8%B4%9D-wqsf.jpg)

【摘要】白皮书揭示AI Agent与具身智能两大核心趋势。北京AI产业规模领跑,技术生态完善,未来竞争将转向智能体能力与物理世界落地深度。
引言
近期发布的《北京人工智能产业白皮书(2025)》并非一份常规的产业报告。它更像一份技术路线图与产业宣言,清晰地勾勒出人工智能下一阶段的演进方向。报告的核心洞察直指两个关键领域,AI Agent(人工智能代理) 与 具身智能(Embodied AI)。这两个概念正从学术前沿迅速走向产业实践,预示着人与机器的协作关系、乃至整个社会生产力结构,都将迎来一次深刻的重塑。本文将基于白皮书的内容,结合技术架构与产业观察,对这两大趋势进行深度拆解。
一、北京AI产业的基石:规模、生态与政策驱动
%20拷贝-lcgz.jpg)
任何技术浪潮的兴起,都离不开坚实的产业土壤。北京在人工智能领域的领先地位,并非偶然,而是规模、生态与顶层设计合力作用的结果。理解这一点,是看懂其未来趋势的前提。
1.1 产业规模的硬指标
数据是衡量产业体量最直观的标尺。白皮书披露了一系列关键数据,共同描绘出北京AI产业的增长曲线与领先态势。
核心产业规模:2025年上半年,北京人工智能核心产业规模达到2152.2亿元,同比增速为25.3%。这一增速远超传统行业,显示出其作为数字经济核心引擎的强劲动力。白皮书预测,2025年全年产业规模有望突破4500亿元。
企业集群效应:北京目前拥有超过2500家人工智能企业。这个数字背后,是一个从底层技术研发到上层应用落地的完整企业梯队。其中,海淀区作为核心承载区,聚集了约1900家企业,形成了高密度的创新集群。
大模型备案数量:截至报告发布,北京已备案的大模型数量高达183款,持续位居全国首位。这不仅是数量上的领先,更代表了在当前大模型技术竞赛中,北京掌握了关键的“入场券”和话语权。
这些数据共同指向一个结论,北京已经构建起一个具备强大内生增长动力的AI产业基本盘。
1.2 全栈协同的产业生态
规模优势的背后,是北京日趋完善的全栈式产业生态。当前全球AI的竞争,已不再是单点技术的比拼,而是演变为“战略主导、技术竞速、规模扩张、应用拓展、生态竞合”的综合博弈。北京的生态优势恰恰体现在这种系统性能力上。
1.2.1 创新链的完整闭环
北京的AI创新链条,覆盖了从理论研究到商业化落地的全部环节。
科研机构:以智源研究院、通用人工智能研究院、科学智能院等为代表的新型研发机构,负责前沿理论的突破和原始创新。
龙头企业:百度、字节跳动等平台型公司,拥有强大的工程化能力、海量数据和丰富的应用场景,是技术商业化的主导力量。
创新型中小企业:大量专注于细分领域(如计算机视觉、自然语言处理、AI芯片)的“专精特新”企业,构成了生态的活力源泉。
应用场景方:金融、医疗、交通、政务等行业为AI技术提供了丰富的试验场和落地场景。
这种“产学研用”紧密协同的生态网络,极大地缩短了技术从实验室走向市场的时间。
1.2.2 产业链的纵向贯通
从纵向看,北京的AI产业链也已形成相对完整的布局。
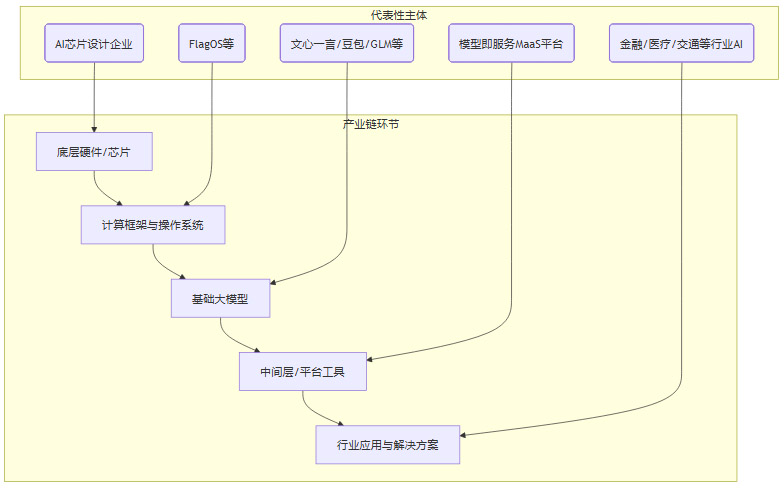
这张简化的产业链图谱显示,北京在从芯片、框架到模型的各个关键节点均有布局,形成了技术内循环和自我迭代的能力。
1.3 商业化路径的清晰化
技术的最终价值在于商业落地。白皮书指出,北京AI产业的商业化路径正逐渐清晰。以百度、抖音等为代表的头部企业,其AI相关业务的营收和产品活跃用户数持续创新高。这标志着AI应用正从早期的“工具化”探索,向成熟的“产品化”和“平台化”演进,具备了可持续的造血能力。
二、技术前沿的脉动:从大模型到“模芯协同”
产业的繁荣离不开技术的持续突破。北京不仅是产业高地,更是技术创新的策源地。一批代表性成果,展示了其在前沿技术领域的深度探索。
2.1 新型研发机构的引领作用
与企业追求短期商业回报不同,新型研发机构更侧重于长周期、高风险的底层技术创新。
北京智源人工智能研究院:其发布的FlagOS(智源操作系统),目标是实现“模芯协同”。这并非简单的软件适配,而是试图从操作系统层面,将大模型的算法特性与国产芯片的硬件架构深度耦合,以实现极致的性能优化。这是解决“卡脖子”问题、构建自主可控AI技术体系的关键一步。
北京通用人工智能研究院:其发布的**“通通2.0”**,是一个重要的里程碑。它致力于实现通用人工智能(AGI)的理论创新,并将其转化为可验证的技术原型。“通通2.0”的发布,标志着其研究完成了从纯理论构建到初步能力验证的重大跨越。
北京科学智能院:发布的**“玻尔科研空间站”**,是全球首个覆盖科研全流程的AI平台。它整合了“读文献-做计算-做实验-多学科协同”等环节,旨在将AI打造为科学家的强大助手,变革传统的科研范式。
中关村人工智能研究院:其打造的**“超级软件智能”**,是一个极具前瞻性的方向。它尝试让AI理解并操作软件的底层运行机理,实现对软件开发、测试、运维全生命周期的自动化和智能化,这可能颠覆整个软件工程领域。
2.2 国产大模型的群体性崛起
大模型是本轮AI浪潮的技术基座。北京在该领域形成了强大的企业矩阵。
这些模型不仅在技术指标上持续追赶国际顶尖水平,更重要的是,它们在本土化数据、中文语境理解和国内应用场景适配方面具备天然优势。这种群体性的崛起,为上层AI Agent和具身智能的发展提供了坚实的模型基础。
三、AI Agent:从工具到自主智能体的范式革命
%20拷贝-hsxe.jpg)
白皮书将AI Agent列为即将爆发的核心趋势。这并非空穴来风,而是基于大模型能力溢出后,AI应用形态演进的必然结果。Agent的出现,标志着AI正从一个被动响应指令的“工具”,进化为一个能够主动感知、决策并执行任务的“智能体”。
3.1 AI Agent的技术架构拆解
一个典型的AI Agent系统,通常包含以下几个核心模块。理解其架构,是理解其能力边界和潜力的关键。
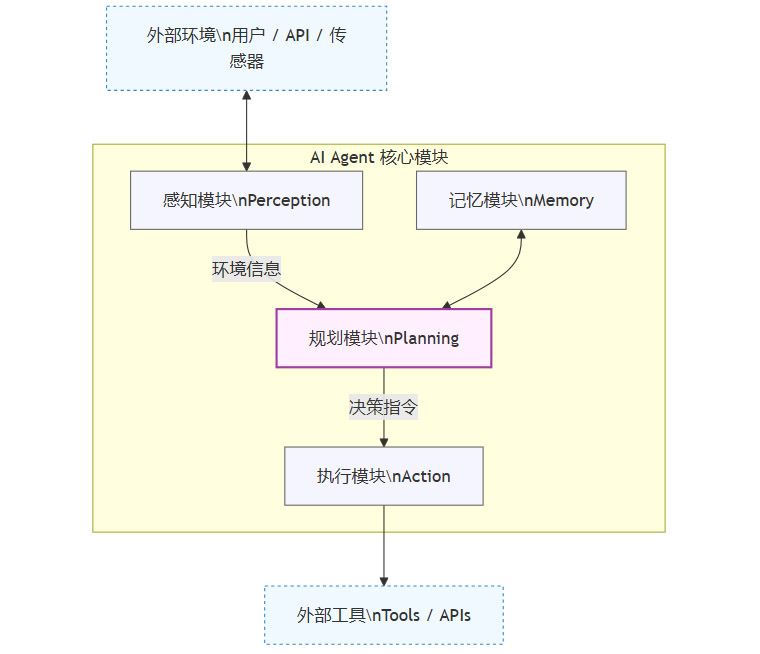
大脑/规划模块 (Brain/Planning):这是Agent的核心,通常由一个强大的语言模型(LLM)承担。它负责理解复杂的用户意图,将宏大目标分解为一系列可执行的子任务。目前主流的规划技术包括思维链(Chain of Thought, CoT)、ReAct(Reasoning and Acting) 等,它们赋予了Agent逻辑推理和规划的能力。
感知模块 (Perception):负责从外部环境中收集信息。这些信息可以是用户的文本指令、图片、声音,也可以是来自传感器或API的实时数据流。多模态大模型的发展,极大地增强了Agent的感知能力。
记忆模块 (Memory):Agent需要记忆来维持对话的连贯性、学习用户偏好并从过去的经验中吸取教训。记忆通常分为:
短期记忆:用于处理当前任务的上下文。
长期记忆:通过向量数据库等技术存储,用于持久化知识和经验。
执行模块 (Action):负责将大脑规划出的指令转化为实际行动。这通常通过调用外部工具(Tools)或API来实现。例如,订机票的Agent会调用航空公司的API,分析数据的Agent会调用代码解释器。
3.2 AI Agent的应用场景爆发
白皮书明确指出了AI Agent即将爆发的三个主要方向。
3.2.1 C端个人助理
这将是用户感知最强的领域。未来的个人助理Agent将不再是简单的语音助手,而是能够跨应用、跨平台为用户完成复杂任务的“数字管家”。
任务场景:自动规划并预订一次包含机票、酒店、当地交通和餐厅的完整旅行;根据用户的健康数据和日程安排,自动生成并订购一周的健康餐;整合所有信息源,生成每日定制化的新闻简报。
核心价值:极大降低用户的认知负荷和操作成本,将人们从繁琐的日常事务中解放出来。
3.2.2 B端企业流程自动化
在企业端,AI Agent将化身为“数字员工”,深度参与到业务流程中,实现更高层次的自动化。
任务场景:
财务Agent:自动完成发票审核、费用报销、财务报表生成。
客服Agent:不仅能回答问题,还能主动进行用户回访、处理退款申请、升级复杂问题给人类专家。
HR Agent:自动筛选简历、安排面试、处理入职流程。
核心价值:从“流程自动化(RPA)”升级为“认知自动化”。传统的RPA处理的是结构化、规则化的任务,而AI Agent能够处理非结构化数据和复杂的决策逻辑,应用范围和深度远超前者。
3.2.3 科研助手
这是AI Agent最具想象力的应用领域之一。它将成为科研人员的“智能搭档”,加速科学发现的进程。
任务场景:自动追踪、阅读并总结特定领域的最新文献;根据研究假设,设计实验方案并编写模拟代码;操作自动化实验设备执行实验并分析结果。
核心价值:将科研人员从重复性、劳动密集型的工作中解放出来,使其能更专注于创造性的思考和理论突破。北京科学智能院的“玻尔科研空间站”就是这一趋势的早期实践。
3.3 市场前景与挑战
全球资本市场已经对AI Agent赛道表现出极大的热情。有行业报告预测,2025年仅中国企业级AI Agent市场的规模就可能达到数百亿元,年增长率超过100%。
然而,挑战同样存在。
可靠性与可控性:如何确保Agent在开放环境中执行任务时,行为是安全、可靠且符合预期的?
成本问题:复杂Agent每次执行任务都需要进行大量的模型推理,其计算成本目前依然高昂。
工具生态:Agent的能力上限,很大程度上取决于其能够调用的工具(API)的丰富程度和标准化水平。
四、具身智能:AI迈向物理世界的终极跨越
如果说AI Agent是AI在数字世界的延伸,那么具身智能则是AI向物理世界的进军。白皮书将其视为实现从“虚拟信息处理”到“物理世界作业”的关键跨越,这一定位极其精准。
4.1 具身智能的核心内涵
具身智能(Embodied AI)强调智能体必须拥有一个“身体”(如机器人),并通过这个身体与物理环境进行实时交互来感知、学习和完成任务。它与传统AI最大的区别在于,智能的产生和发展,离不开与环境的物理互动。
4.2 关键技术挑战:跨越Sim2Real的鸿沟
具身智能面临的最大技术瓶颈之一是**“从模拟到现实的鸿沟”(Sim2Real Gap)**。由于在真实物理世界中训练机器人成本高、风险大、效率低,目前主流的训练方式是在模拟器中进行。但模拟环境与真实世界总存在差异(如光照、摩擦力、物体材质),导致在模拟器中表现完美的模型,到现实中可能完全失效。
弥合这一鸿沟的技术路径包括:
域随机化 (Domain Randomization):在模拟器中引入大量随机变化(如改变颜色、纹理、光照),让模型学会适应各种环境,提升其泛化能力。
模仿学习 (Imitation Learning):让机器人通过观察和模仿人类专家的操作来学习技能。
强化学习 (Reinforcement Learning):通过“试错”机制,让机器人在与环境的交互中自主学习最优策略。特别是结合人类反馈的强化学习(RLHF),可以有效指导机器人学习复杂的任务。
4.3 应用场景的物理化拓展
具身智能的落地,将对依赖物理操作的行业产生颠覆性影响。
工业制造:未来的“黑灯工厂”中,具身智能机器人将不再是执行固定程序的机械臂,而是能够自主适应产线变化、处理异常情况、与人类工人协同工作的“智能工匠”。
物流仓储:从货物的分拣、搬运到装车,全流程将由具身智能机器人自主完成,它们能够灵活避障、处理各种形状和尺寸的包裹。
家庭服务:能够打扫卫生、烹饪、照顾老人和小孩的家庭服务机器人,将真正走进千家万户,深刻改变人们的生活方式。
特种作业:在救灾、勘探、高空作业等高危环境中,具身智能机器人将替代人类执行任务,保障生命安全。
五、未来图景的技术支点:世界模型、AI for Science与端侧智能
%20拷贝-hkns.jpg)
AI Agent和具身智能的宏大叙事,需要更底层的技术创新来支撑。白皮书同样指出了几个关键的技术支点。
5.1 世界模型:赋予AI“预见未来”的能力
白皮书特别强调了“世界模型”(World Model)的重要性。它被认为是提升AI系统泛化能力和可靠性的关键。
什么是世界模型?
简单来说,世界模型是AI在内部构建的一个关于外部世界如何运作的、可预测的、可模拟的简化模型。拥有世界模型的智能体,可以在其“脑海”中对未来的不同行动序列进行推演和规划,而无需在真实世界中进行高成本的试错。
核心价值:
提升规划效率:智能体可以在内部模型中快速模拟成千上万种可能性,从中选择最优策略,再到现实世界中执行。
增强泛化能力:通过对世界基本规律的学习,智能体在面对从未见过的场景时,也能做出合理的推理和决策。
保障安全性:对于高风险任务(如自动驾驶、手术机器人),可以在安全的内部模拟中充分验证策略,再付诸实施。
世界模型的研究,将是实现高级AI Agent和自主具身智能的理论基石。
5.2 AI for Science:科研范式的系统性变革
“AI for Science”代表了AI应用的终极价值之一,即加速人类知识边界的拓展。它并非简单的工具应用,而是将AI深度融入科学发现的全流程,形成一种新的科研范式。
从数据驱动到知识驱动:AI不仅能从海量实验数据中发现规律,还能学习和理解科学文献中的理论知识,提出新的科学假设。
加速“理论-实验”循环:AI可以根据理论假设,快速进行大规模模拟计算,预测实验结果,从而指导物理实验的设计,极大地缩短了科研周期。
应用领域:在新材料发现、新药研发、气候变化模拟、能源科学等领域,AI for Science已经展现出巨大潜力。
5.3 端侧智能:让AI无处不在的新蓝海
白皮书将端侧智能视为应用的新蓝海。随着大模型向终端设备(智能手机、PC、智能汽车、AR/VR眼镜)的迁移,一个全新的智能应用生态正在形成。
云端与端侧的协同架构:
未来的主流模式将是“云端大模型 + 端侧轻量模型”的混合架构。
端侧智能的普及,将极大提升用户体验,例如更快的语音响应、更安全的个人数据处理、更流畅的AR交互。它将推动AI从云端走向千行百业与千家万户,成为真正的普惠技术。
结论
《北京人工智能产业白皮书(2025)》清晰地传递了一个信号:以大模型为技术基座的AI上半场竞赛已近尾声,而下半场的竞争焦点正在转移。未来的较量,将不再是单纯的模型参数比拼,而是转向三个更具决定性的维度:
AI Agent的自主与协同能力。
具身智能在物理世界的落地深度。
全产业链的协同与生态构建能力。
北京凭借其深厚的产业基础、完整的创新链条和前瞻性的技术布局,正积极抢占这一新周期的制高点。从“AI技术高地”向“全球竞争力的产业生态”升级,这不仅是北京的目标,也为中国人工智能产业的整体跃迁提供了可供参考的蓝本。AI Agent和具身智能的浪潮已至,一场关于“人机分工”的深刻变革,正在拉开序幕。
📢💻 【省心锐评】
大模型竞赛进入下半场。Agent的自主性与具身智能的物理执行力,将是衡量AI价值的终极标尺。北京的布局,正是瞄准这一未来。

评论