.png)


【摘要】科技竞争正从硬件芯片转向数据“数芯”。由华天科技停牌与雷军造芯感慨所揭示的核心要素争夺,预示着行业焦点正转向RDA(真实数据资产)。文章类比芯片制造,剖析RDA的形成价值链,并论证未来科技竞争将升级为算法、算力、数据(RDA)的三维格局。
引言
九月的科技圈,空气中弥漫着一丝紧张与躁动。
一边是资本市场的波澜。9月25日,国内半导体封测领域的龙头企业华天科技,一纸停牌公告,宣告其正筹划一场关乎产业链纵深布局的重大资产购买。目标直指其控股股东旗下的功率半导体企业华羿微电。此举,无疑是这家传统封测巨头,在行业景气度悄然回暖之际,向新能源汽车、光伏等高增长赛道发起的一次精准突袭。
另一边是创业者的心声。几乎在同一时间,小米的掌舵人雷军,在其年度演讲前夕,罕见地袒露了内心的巨大压力。他将同时推进的造车与造芯业务,比作“同时供家里两个孩子上大学”,坦言这两项事业几乎押上了小米过去十年积累的全部家底。一句“令人窒息的压力”,道尽了投身硬核科技研发的艰辛与决绝。
华天科技的纵向整合,与雷军的“双线豪赌”,看似是两条平行线,却在某个深层维度上交汇。 它们共同指向了一个不容回避的现实,硬核科技领域的竞争,已经演变为一场对核心生产要素的殊死争夺。
过去,我们谈论的核心是“芯片”,是那个刻在硅基上的物理奇迹,是数字时代的硬件基石。然而,当人工智能的浪潮席卷而来,一个新的名词正悄然浮出水面,它的战略价值,丝毫不亚于芯片。
它就是“数芯”(Data-Core)。
如果说芯片解决了“计算”的物理载体问题,那么“数芯”则关乎“智能”的根本食粮。这篇文章,将从华天科技与雷军的行业共鸣出发,深入剖析“数芯”这一新兴概念,探讨它如何重塑科技竞争的维度,并为身处其中的企业,提供一份未来的行动指南。
一、🌪️ 硬核科技的“风暴眼”——核心要素的争夺战
%20拷贝.jpg)
任何产业的变革,都始于对最稀缺资源的争夺。在当前的科技领域,这种争夺正以前所未有的激烈程度展开。华天科技与小米的最新动态,便是这场风暴中最具代表性的两个缩影。
1.1 华天科技的“纵向一跃”——从封装到设计的产业链深潜
华天科技的停牌,并非一次简单的资本运作。它更像是一次蓄谋已久的战略深潜,意图打通产业链的“任督二脉”。
这次收购的核心标的——华羿微电子,是一家专注于功率半导体器件设计、制造与销售的企业。这意味着,华天科技的业务版图,将从后端的封装测试,直接向上游的设计与制造环节延伸。
这一步棋,背后有深层的逻辑。
首先,这是对利润空间的向上探索。在半导体价值链中,设计环节(Fabless)通常占据着最高的利润率,其次是制造(Foundry),而封装测试(OSAT)环节则相对利润较薄。华天科技通过整合华羿微电,能够切入价值更高的环节,提升整体盈利能力。
其次,这是对市场需求的精准响应。功率半导体是新能源汽车、光伏储能、工业控制等领域的“心脏”,市场需求极为旺盛。掌握了从设计到封测的全流程能力,意味着华天科技能更好地服务这些高增长客户,提供更具定制化和竞争力的解决方案。
最后,这是构建技术护城河的必然选择。单纯的封测业务,技术壁垒相对较低,容易陷入价格战的泥潭。而向上游整合,能够积累更深厚的设计与工艺Know-how,形成难以被模仿的综合技术优势。
所以,华天科技的停牌,本质上是一场围绕“芯片”这一核心生产要素的控制权争夺战。它要的,不仅仅是封装订单,更是对整个价值链的话语权。
1.2 雷军的“千亿豪赌”——“芯片+汽车”的双线突破
如果说华天科技的行动是“步步为营”,那么雷军和他的小米,则更像是“孤注一掷”。
雷军在演讲中的感慨,绝非矫情。造车和造芯,任何一项都足以拖垮一家巨头,而小米选择同时在两条战线上发起总攻。累计投入超千亿元,这对于任何一家企业而言,都是一场关乎生死的豪赌。
这场豪赌的赌注,同样是未来的核心生产要素。
造芯,是为了掌握智能终端的“灵魂”。从早期的澎湃S1,到后来的影像芯片澎湃C1、充电芯片澎湃P1、电池管理芯片澎湃G1,小米的造芯之路虽然坎坷,但从未停止。因为小米深知,在智能手机、智能汽车、AIoT设备中,芯片不仅决定了产品的性能上限,更定义了用户体验的边界。没有自研芯片,就永远无法摆脱对上游供应商的依赖,就永远无法实现真正的软硬件深度协同。
造车,是为了抢占下一个超级智能终端的入口。汽车正在从一个机械产品,迅速演变为一个集计算、通信、感知、控制于一体的“轮式机器人”。它不仅是芯片的集大成者,更是未来最大的数据生成和消费平台。谁掌握了智能汽车,谁就掌握了连接物理世界与数字世界的关键枢纽。
雷军的压力,源于这两项事业的共同点,它们都需要长期、巨额、且充满不确定性的投入。但这种“明知山有虎,偏向虎山行”的决绝,恰恰反映了顶尖科技企业对未来竞争格局的深刻洞察,不掌握核心要素,就没有未来。
1.3 冰山之下——共鸣的本质
将华天科技与小米的案例并置,我们可以清晰地看到冰山的全貌。水面之上,是停牌公告和领袖演讲;水面之下,则是整个科技行业对核心生产要素近乎白热化的争夺。
这些核心要素,构成了一个金字塔结构。
顶层是算法(Algorithm),它定义了智能的逻辑和上限。
中间是算力(Compute),它为算法的实现提供了物理基础,以芯片为代表。
底层是数据(Data),它是训练算法、驱动智能的燃料。
过去,行业的目光更多聚焦在算法的创新和算力的突破上。但现在,一个深刻的转变正在发生。随着人工智能进入深水区,数据的战略地位被提到了前所未有的高度。一个全新的战场,正在围绕“数据”这一核心要素展开。
而这场新战争的“军火”,就是我们即将深入探讨的“数芯”。
二、💡 从“芯片”到“数芯”——AI时代的战略新高地
芯片的英文是Chip,或者更专业的叫法是IC(Integrated Circuit)。它是一个物理实体。而我们所说的“数芯”,其英文对应的是Data-Core,它并非一个物理硬件,而是一个逻辑上的概念,其技术实现载体,正是近年来备受关注的RDA(Real Data Assets,真实数据资产)。
2.1 “数芯”的诞生——RDA概念解析
RDA这一概念,由上海数据交易所率先提出并实践。它不是对“大数据”的简单包装,而是一次根本性的范式革命。它的核心思想,是将现实世界中那些高质量、高价值、且来源可信的数据,通过一系列技术和法律手段,转化为一种标准化的、可交易、可融资的数字资产单元。
为了更清晰地理解RDA与传统大数据的区别,我们可以看下面这张对比表。
从这张表中可以明显看出,RDA的出现,标志着数据正在从一种生产的“副产品”,转变为一种可以直接进入市场流通的“主产品”。它让数据的价值不再是模糊的、估算的,而是清晰的、可交易的。
这种转变的背后,是技术的成熟。
物联网(IoT)技术,使得海量、真实的物理世界数据得以被自动化、低成本地采集。
区块链技术,为数据提供了不可篡改的确权、存证和溯源能力,解决了“数据是谁的”以及“数据是否被篡改”的信任难题。
隐私计算(Privacy-Enhancing Technologies)技术,如联邦学习、安全多方计算等,实现了“数据可用不可见”,在保护隐私的前提下,让数据价值得以安全流动和融合计算。
正是这些技术的组合,才让“数芯”——RDA,从一个理论构想,变为了一个触手可及的现实。
2.2 “数芯”的战略价值——AI大模型的“终极燃料”
为什么RDA在今天变得如此重要?
答案很简单,因为AI大模型需要它。
如果说算法是大模型的“大脑”,算力是大模型的“肌肉”,那么高质量的数据,就是维持其生命和智慧的“血液与养分”。在当前阶段,大模型的性能,在很大程度上已经不再取决于模型结构的微小创新,而是取决于所喂养数据的质量和数量。
高质量、独家、合规的RDA,已经成为AI大模型性能和商业价值的真正分水岭。
这里的“高质量”包含几个层面。
真实性。数据必须真实反映物理世界或商业活动的本来面貌。基于虚假或模拟数据训练出的模型,在现实世界中往往表现不佳,甚至会产生“模型幻觉”。
独家性。公开数据集(如维基百科、Common Crawl)已经快被全球的大模型厂商“榨干”了。谁掌握了别人没有的、独特的专有数据集,谁的模型就能在特定领域建立起绝对优势。
合规性。随着全球数据安全和隐私保护法规(如GDPR、国内的《数据安全法》)日趋严格,使用未经授权、来源不明的数据进行训练,将面临巨大的法律和声誉风险。合规的RDA,是模型商业化的“通行证”。
让我们来看两个具体的行业案例。
中远海科,作为航运科技领域的巨头,掌握着全球主要港口的船舶动态、集装箱流转、航线状况等实时数据。这些数据如果被封装成RDA,就可以用来训练一个“全球航运大模型”。这个模型可以精准预测港口拥堵、优化航线规划、动态调整运力,其商业价值不可估量。这是任何一家通用大模型厂商,仅靠公开数据无法企及的高度。
上海钢联,深耕大宗商品领域二十余年,积累了海量的钢材、铁矿石等品种的交易、库存、价格、物流数据。这些数据通过RDA的方式进行资产化,不仅可以为金融机构提供精准的风险评估模型,甚至可以探索发行与真实钢材库存挂钩的“数字仓单”或稳定币,彻底改变大宗商品的贸易结算方式。
在这两个案例中,数据不再仅仅是业务的记录,它本身就是最核心的资产,是驱动新商业模式的“数芯”。
三、⚙️ “数芯”的炼金术——类比芯片制造的价值链
%20拷贝.jpg)
理解了“数芯”是什么以及为什么重要之后,我们还需要知道它是如何被“制造”出来的。一个非常恰当的类比,就是芯片的制造流程。从一粒沙子到一枚精密的CPU,中间经历了一系列复杂的物理和化学变化。同样,从原始的、杂乱的数据,到一枚标准化的、高价值的RDA,也需要一条精密的“工业化流水线”。
我们可以用一张流程图来直观地展示这个过程。
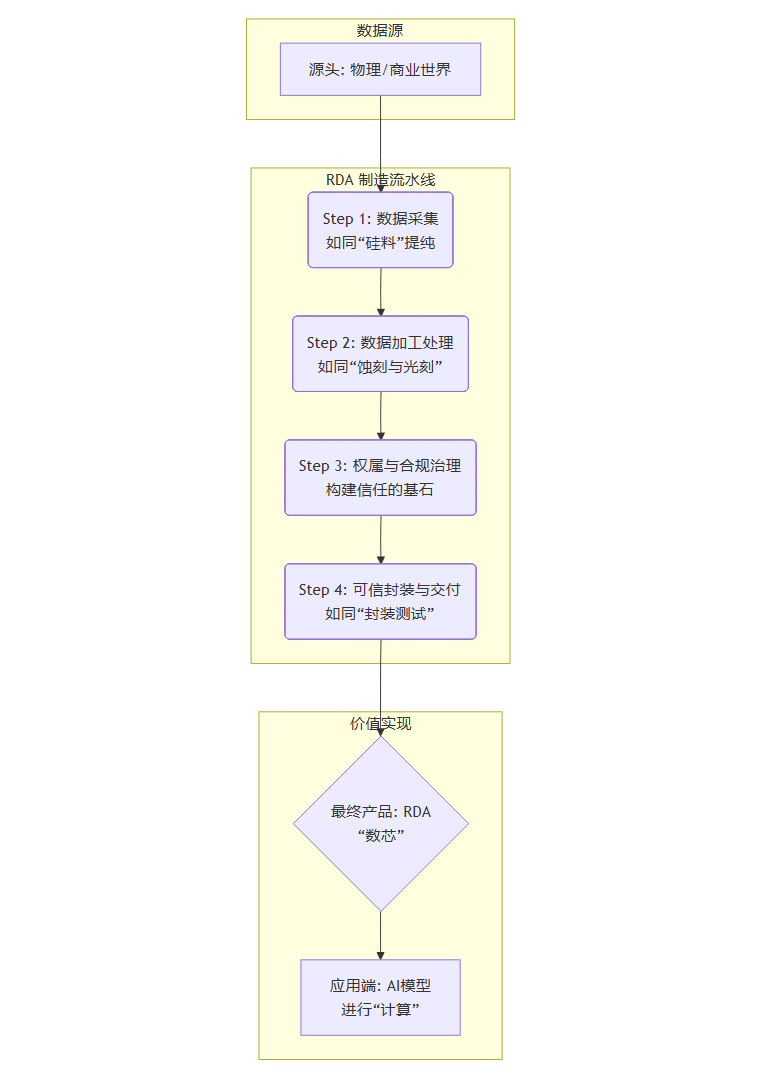
下面,我们来详细拆解这条“炼金术”流水线上的每一个关键环节。
3.1 Step 1 数据采集——如同“硅料”提纯
芯片的起点是高纯度的单晶硅,而“数芯”的起点,是高保真度的原始数据。
这个环节的核心目标,是最大限度地排除人为干预,确保数据的原始真实性。就像从沙子中提纯硅料一样,任何杂质都会影响最终产品的质量。
主要来源,物联网(IoT)设备、工业传感器、车载摄像头与雷达、企业的ERP/CRM业务系统、金融交易系统等。
关键技术,自动化采集协议、边缘计算网关、时间戳服务。通过在数据产生的源头就打上可信的时间戳,并进行加密传输,保证数据从诞生的一刻起就是“原装正品”。
核心原则,“机器信机器”。尽可能减少人工录入和干预的环节。例如,智能工厂中的一条产线,其能耗、转速、温度等数据,应该由传感器直接采集上传,而不是由工人手动填写报表。
这个阶段的产出,是海量的、带有“原生胎记”的原始数据流。它们虽然真实,但往往是异构的、杂乱的,还不能直接使用。
3.2 Step 2 数据加工处理——如同“蚀刻与光刻”
有了高纯度的硅锭,芯片制造的下一步就是通过光刻、蚀刻等复杂工艺,在硅片上刻画出亿万个晶体管电路。
数据加工处理环节,扮演的正是类似的角色。它的目标,是将原始数据转化为结构化的、高质量的、可供机器理解的信息。
这个过程通常包括以下步骤。
数据清洗,识别并处理原始数据中的错误值、缺失值、异常值。
数据标注,对于图片、文本、语音等非结构化数据,由人工或AI辅助进行打标,赋予其语义信息。例如,将一张图片中的“猫”框选出来,并标记为“cat”。这是监督学习模型训练的关键步骤。
数据脱敏,对数据中包含的个人信息或其他敏感信息(如身份证号、手机号、银行卡号)进行遮蔽、替换或加密处理,以满足合规要求。
数据结构化,将不同来源、不同格式的数据,转换为统一的、标准化的格式,方便后续的存储和计算。
质量评估,建立一套量化指标,评估处理后数据的完整性、一致性、准确性,确保达到可用标准。
经过这个环节,杂乱的“数据硅料”变成了规整的、高质量的“数据晶圆”,为下一步的资产化做好了准备。
3.3 Step 3 权属与合规治理——构建信任的基石
这是“数芯”制造流程中最具革命性,也是与传统数据处理最大的不同之处。它要解决两个终极问题,“数据是谁的”和“数据如何安全地给别人用”。
这个环节融合了法律、技术与管理。
数据确权与登记,通过智能合约等区块链技术,将数据的所有权、使用权、收益权等权属关系清晰地记录在分布式账本上。每一份数据资产,都会生成一个独一无二的“数字身份ID”,就像房产证一样,明确其归属。上海数据交易所的RDA登记平台,做的就是这件事。
价值评估,引入专业的第三方评估机构,综合考虑数据的成本、质量、稀缺性、应用场景等多种因素,对数据资产进行公允的价值评估。这为后续的交易和融资提供了定价依据。
合规审查,确保数据的采集、处理、流通全过程,都符合国家《网络安全法》、《数据安全法》、《个人信息保护法》以及相关行业法规的要求。
隐私增强技术(PETs)的应用,这是实现“数据可用不可见”的核心技术保障。
通过这一系列复杂的治理流程,数据完成了从“信息”到“资产”的惊险一跃。它不再是藏在企业服务器里的“私有财产”,而是获得了能够在市场上安全、合规流通的“合法身份”。
3.4 Step 4 可信封装与交付——如同“封装测试”
芯片在制造完成后,需要进行封装,保护内部电路不受损害,并提供与外部连接的引脚。
RDA的“封装”,也有异曲同工之妙。它通过技术手段,将经过治理的数据资产,打包成一个标准化的、防篡改的、可交付的产品。
区块链封装,将RDA的元数据(如数据摘要、权属信息、合规证书、流转记录等)记录在区块链上。任何人都可以验证这个RDA的“前世今生”,但无法篡改其历史。这提供了极强的公信力。
标准化交付,RDA产品以标准化的格式(如API接口、数据包、模型服务等)进行交付。数据需求方可以像调用一个云服务一样,方便地接入和使用这些“数芯”。
计量与计费,封装好的RDA产品,内置了清晰的计量和计费逻辑。可以按调用次数、数据量、使用时长等多种方式进行计费,实现了价值的精准兑现。
至此,一枚“数芯”正式诞生。它就像一颗功能强大的CPU,内部蕴含着来自真实世界的智慧,外部则有标准化的接口,随时准备被插入AI模型的“主板”中。
3.5 Step 5 供给AI模型“计算”——驱动智能的引擎
这是“数芯”价值实现的最后一环,也是其最终目的。
封装好的RDA产品,被供给给各类AI大模型,用于训练(Training)、微调(Fine-tuning)或推理(Inference)。
在训练阶段,高质量的RDA可以帮助模型从零开始学习特定领域的知识和规律,决定了模型的“智商”下限。
在微调阶段,针对特定任务的独家RDA,可以快速让一个通用大模型,适配到具体的业务场景中,成为一个“行业专家模型”,极大提升其解决实际问题的能力。
在推理阶段,实时的RDA数据流,可以作为模型的输入(Prompt的一部分),让模型能够基于最新的真实世界信息,做出更准确、更及时的判断和决策。
可以说,“数芯”的质量和丰富度,直接决定了AI模型的能力上限、泛化能力、鲁棒性和最终的商业落地效果。没有源源不断的、高质量的“数芯”供给,再强大的算法和算力,也只是无源之水、无本之木。
四、⚔️ 竞争新维度——从二维到三维的终极升级
“数芯”的出现,以及其背后一整套工业化的制造流水线,正在从根本上改写科技竞争的规则。过去,我们习惯于在一个二维平面上观察这场战争。而现在,一个新的维度正在被打开。
4.1 旧战场——算法与算力的二维战争
在很长一段时间里,科技巨头的军备竞赛主要围绕两个核心展开。
算法(Algorithm),这是智慧的“设计图”。从AlexNet在ImageNet上的惊艳亮相,到Transformer架构的一统江湖,再到如今各种大模型(LLM、MoE)的百花齐放。算法的创新,是驱动人工智能浪潮一波又一波向前的核心引擎。谁能提出更高效、更强大的模型结构,谁就能在性能上取得领先。
算力(Compute),这是实现智慧的“物理引擎”。算法的复杂性,需要海量的计算能力来支撑。因此,对高性能计算芯片,特别是GPU的争夺,成为了另一条至关重要的战线。英伟达之所以能成为市值一度超越苹果的“宇宙总龙头”,正是因为它卡住了算力这个关键的咽喉。
这场“算法+算力”的二维战争,催生了无数技术奇迹。但它的壁垒,正在被逐渐削弱。
一方面,开源模型的普及,正在拉平算法的鸿沟。从Meta的Llama系列,到Mistral AI的崛起,再到国内的智源、百川等,高质量的开源大模型层出不穷。这使得中小企业和开发者,不再需要从零开始构建复杂的模型,而是可以站在巨人的肩膀上,快速进行微调和应用。
另一方面,云计算的成熟,正在实现算力的普惠。AWS、Azure、Google Cloud等云服务商,提供了弹性的、按需付费的GPU算力资源。企业不再需要一次性投入巨资自建数据中心,就可以获得世界顶级的算力支持。
当算法可以被借鉴,算力可以被租用时,一个问题自然浮现,未来的核心壁垒,究竟在哪里?
4.2 新竞技场——“算法+算力+数据(RDA)”的三维铁人三项
答案,就在那个新增加的维度上,数据,或者更准确地说,是RDA。
未来的科技竞争,将不再是二维平面上的对决,而是升级为一场“算法+算力+数据(RDA)”的三维铁人三项。在这场新的竞赛中,RDA扮演着决定性的角色。
如果说算法和算力决定了你能跑多快,那么RDA则决定了你能跑多远,以及你跑的方向是否正确。
为什么RDA能成为最坚固的护城河?
独占性与稀缺性,算法可以被复现,算力可以被购买,但高质量的、独家的、经过长期积累的行业数据,是无法被简单复制的。特斯拉通过其数百万辆汽车在全球路面上行驶所采集的驾驶数据,是其FSD(全自动驾驶)算法迭代的核心优势,这是任何竞争对手在短期内都无法企及的。
价值的复利效应,数据资产具有强大的网络效应和复利效应。拥有的数据越多、质量越高,训练出的模型就越智能。更智能的模型能吸引更多用户,产生更多的数据,从而形成一个正向的、不断加速的飞轮。
场景的深度绑定,RDA往往与特定的业务场景深度绑定。一个基于某医院数十年匿名化病例数据训练出的肺癌影像诊断模型,其精准度必然远超一个用公开医疗数据集训练的通用模型。这种源于真实场景的“领域知识”,是无法通过通用模型暴力堆砌算力来弥补的。
因此,在这场三维竞赛中,三个要素不再是孤立的,而是相互协同、相互定义的。
谁能在这三个维度上都建立起优势,并让它们高效协同,谁就掌握了通往通用人工智能(AGI)的“战略地图”。
4.3 行业生态的演变——“巨头主导+垂直突围”
在新的三维竞争格局下,各行各业的AI应用生态,也呈现出新的面貌,即“巨头主导+垂直突围”。
巨头主导,在通用领域,如搜索、翻译、内容生成等,科技巨头凭借其在算法、算力、数据三个维度上的全面优势,占据着绝对的主导地位。例如,谷歌的翻译服务,背后是其强大的Transformer算法、全球化的TPU算力集群,以及通过搜索引擎和图书扫描计划积累的、无与伦比的多语言平行语料库(一种高质量的RDA)。
垂直突围,在专业领域,如自动驾驶、智慧医疗、工业质检、法律合同分析等,创业公司和行业龙头则有机会通过构建独特的RDA壁垒,实现“垂直突围”。它们可能在通用算法和算力上不占优势,但它们拥有巨头所不具备的、深度的行业Know-how和独家的场景数据。
以自动驾驶为例,行业内已经形成了清晰的梯队。特斯拉和Waymo处于第一梯队,它们的核心优势正是“算法+算力+数据”的完美闭环。而一些专注于特定场景(如矿山、港口、末端物流)的自动驾驶公司,则通过在这些场景下积累的、独特的RDA,找到了自己的生存空间和商业价值。
4.4 金融前沿——数据要素的市场化与金融化
RDA的终极价值,不仅在于驱动AI模型,更在于它作为一种新型资产,能够被纳入经济循环,实现价值的直接兑现。这催生了数据要素市场化和金融化的前沿探索。
数据资产入表,2024年1月1日起,中国正式施行《企业数据资源相关会计处理暂行规定》。这意味着,符合条件的数据资源,可以作为“资产”被列入企业的财务报表。这为数据资产的估值、交易、融资提供了会计准则上的依据,是数据资产化的里程碑事件。
数据交易,以上海数据交易所、深圳数据交易所为代表的专业平台,正在积极探索RDA的挂牌、交易、结算流程。它们为数据供需双方提供了一个合规、安全的市场环境,让“数芯”能够像商品一样被自由流通。
数据金融化,这是更具想象力的探索。当RDA的价值被公允评估和确认后,一系列金融创新便成为可能。
数据信托,企业可以将数据资产委托给信托公司进行管理和运营,获取收益。
数据抵押融资,企业可以用其持有的高价值RDA作为抵押物,向银行等金融机构申请贷款。
数据资产证券化(ABS),将未来能够产生稳定现金流的数据资产打包,发行证券进行融资。
发行专属稳定币,正如前文提到的上海钢联案例,基于可信的、与实体库存挂钩的RDA,可以发行用于贸易结算的稳定币,极大地提升交易效率和安全性。
这些探索,正在将“数芯”从一个技术概念,真正推向经济活动的核心舞台。
五、🧭 企业行动指南——如何在“数芯”时代构建壁垒
%20拷贝.jpg)
面对从“芯片”到“数芯”的时代变局,以及竞争维度的全面升级,企业应该如何行动,才能抓住机遇,构建属于自己的护城河?以下是一些关键的行动建议。
5.1 构建多源异构的数据采集体系
这是构建一切“数芯”能力的基础。企业需要将数据采集视为一项持续的、战略性的基础设施投资,而不是一个临时的项目。
打通数据孤岛,建立统一的数据中台,整合来自ERP、CRM、SCM、IoT等不同业务系统的数据,实现数据的互联互通。
拥抱物联网,在生产、物流、服务的关键节点,部署传感器和智能设备,实现对物理世界的高频、自动化数据采集。
重视非结构化数据,除了传统的业务数据,图片、视频、语音、文本等非结构化数据,是训练更强大AI模型的宝贵财富,需要建立相应的采集和存储体系。
5.2 建立端到端的数据治理与合规能力
没有治理和合规的数据,是“数据毒药”,是随时可能引爆的“地雷”,而不是资产。
采用统一标准,建立企业级的数据标准和元数据管理体系,确保所有人对数据的理解和使用都是一致的。
落地隐私增强技术,根据业务场景,综合运用联邦学习、安全多方计算、可信执行环境等技术,在保障数据安全和隐私的前提下,实现跨部门、跨机构的数据协作。
组建专业团队,设立首席数据官(CDO),并组建包含数据工程师、数据科学家、合规专家、法务专家的跨职能数据治理团队。
5.3 打造RDA的产品化与交易化能力
数据团队需要具备“产品经理”思维,将数据作为产品来打造和运营。
定义RDA产品,识别企业内部和外部对数据的高价值需求场景,将原始数据封装成可复用的、标准化的RDA产品(如API服务、数据集、分析报告等)。
建立价值模型,为每个RDA产品建立清晰的成本和价值评估模型,明确其商业价值和定价策略。
探索交易场景,积极与数据交易所等外部平台对接,探索将企业内部的非核心、但对行业有价值的RDA产品进行合规交易,开辟新的收入来源。
5.4 将“算法-算力-RDA”协同设计为技术栈
未来的技术竞争力,来自于三个要素的深度协同,而不是单点的领先。
数据驱动的模型设计,根据RDA的数据特征(如数据分布、噪声水平、稀疏性等),来选择或设计最适合的AI模型架构。
软硬件协同优化,针对关键的AI应用场景,将RDA的数据处理流程、算法的计算范式、底层算力硬件的特性进行联合优化,实现端到端的性能最大化。
构建闭环迭代系统,建立一个从数据采集、模型训练、线上推理、到效果反馈、再到数据回流的自动化闭环系统(MLOps)。让模型在真实的应用中不断迭代进化,持续巩固RDA的价值。
结论
我们正处在一个深刻变革的十字路口。
从华天科技对产业链上游的奋力一跃,到雷军在造车与造芯双重压力下的悲壮前行,我们看到的是,旧有的“硬件为王”的竞争逻辑,虽然依旧重要,但已不再是故事的全部。
一个以“数据为核”的新时代,正拉开序幕。
“数芯”(RDA)的崛起,不是一个空洞的概念炒作,它是人工智能发展的必然要求,是数字经济深化的必然结果。它将数据的价值,从间接的、模糊的后台支撑,推向了直接的、清晰的前台交易。
这场从“芯片”到“数芯”的演进,重塑了竞争的维度。未来的胜利者,将不再是单项冠军,而是能够在“算法、算力、数据”这三个维度上都取得领先,并实现高效协同的“三项全能选手”。
对于每一个身处其中的企业和个人而言,看清这一趋势,并及早布局,或许是未来十年,最重要的一件事。因为在这场新的竞赛中,谁掌握了更优质、更多元的“数芯”,谁就掌握了通往未来的钥匙。
📢💻【省心锐评】
别再卷模型参数了。未来AI的护城河,不在云端,而在田间地头、在生产线上。谁的数据更“脏”、更“野”、更“真”,谁的智能就更值钱。

评论