.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】谷歌 Gemini 3 Pro 图像模型预览版发布。该模型以推理为核心,支持 4K 分辨率、对话式多轮编辑、精准长文本渲染与事实接地,旨在重塑复杂创意工作流。
引言
图像生成领域在过去数年间经历了爆发式增长,扩散模型(Diffusion Models)已成为技术主流。然而,当行业逐渐适应了“文生图”的基本范式后,新的瓶颈也日益凸明。现有模型普遍在两个层面表现不佳。其一,逻辑一致性与事实准确性。模型常生成不合常理的画面,或在需要精确信息的场景中出现偏差。其二,复杂指令遵循与精细化控制。长文本渲染、特定布局要求、多轮迭代修改等高级需求,往往超出当前主流模型的能力边界。
2023年11月20日,谷歌正式发布 Gemini 3 Pro Image Preview。该模型在社区中常被称为“Nano Banana Pro”,被视为谷歌在多模态领域解决上述瓶颈的关键一步。它并未简单地提升像素或风格,而是从底层架构入手,将推理(Reasoning)能力深度融入生成流程。这一设计哲学上的转变,预示着图像AIGC正从“随机生成”迈向“规划生成”的新阶段。本文将对该模型的核心技术、关键能力、应用场景及开发者实践进行系统性拆解与分析。
一、💡 模型概览与市场定位
%20拷贝.jpg)
Gemini 3 Pro Image Preview 的发布,并非一次常规的产品迭代。它承载了谷歌在多模态AI战略上的重要布局,其定位清晰地指向了专业级与企业级应用市场。
1.1 身份厘清:Gemini 3 Pro Image 与 “Nano Banana Pro”
首先需要明确的是,Gemini 3 Pro Image Preview 与社区流传的 “Nano Banana Pro” 指向的是同一模型实体。后者更像是项目代号或在开发者社区中的俗称,而前者是其在谷歌云与AI Studio中的正式产品名称。根据官方文档与发布说明,二者在功能、技术栈和API接口上完全等同。本次发布的 Preview 版本,可以理解为该模型从内部研发走向商业化应用的重要里程碑。
与早期的 Nano Banana 系列模型(如与 Gemini 2.5 相关的 Nano Banana 2)相比,Gemini 3 Pro Image 在多个维度实现了质的飞跃,尤其是在多模态推理、输出控制力与事实准确性上。
1.2 接入渠道与目标用户
模型的部署与开放体现了其双轨并行的市场策略。
企业级部署:Google Cloud Vertex AI
目标用户:需要将图像生成能力深度集成到自身业务系统、对服务稳定性(SLA)、数据安全与可扩展性有高要求的企业客户。
特点:提供企业级的管理、计费与支持服务,适合大规模、高并发的生产环境调用。
开发者与原型验证:Google AI Studio
目标用户:个人开发者、研究人员、以及希望快速验证产品原型(PoC)的团队。
特点:提供更为便捷的Web UI与统一的 Gen AI SDK(支持 Python 和 Go),降低了上手门槛,便于快速实验与迭代。
这种分层开放的模式,既满足了大型企业的生产需求,也兼顾了开发者社区的创新活力。
1.3 核心定位:面向复杂工作流的“规划式”生成引擎
Gemini 3 Pro Image 的核心定位并非与 Midjourney、Stable Diffusion 等工具在通用创意领域直接竞争。它的目标是解决后者难以胜任的复杂、多轮、高保真的生成任务。
“工作流”是理解其定位的关键词。传统模型更像一个“一次性”的画师,用户给出一个指令,它返回一幅作品。而 Gemini 3 Pro Image 则致力于成为一个可长期协作的“设计伙伴”。它能够理解连续的修改指令,在多轮对话中保持上下文一致性,这使其天然适合需要反复打磨、精益求精的专业设计与内容生产流程。
二、⚙️ 核心架构解析:推理优先的生成范式
Gemini 3 Pro Image 最具颠覆性的特质,在于其**“推理优先”(Reasoning-First)**的架构设计。这标志着图像生成技术从单纯的模式匹配,向包含理解、规划与执行的认知过程演进。
2.1 传统扩散模型的局限
要理解“推理优先”的价值,需先审视当前主流扩散模型的内在局限。扩散模型本质上是一个概率生成过程,它从纯噪声中逐步“去噪”,最终还原出一张符合文本描述的图像。这个过程虽然强大,但存在几个固有问题。
组合性谬误(Compositional Errors):当提示词包含多个对象及其复杂关系时(如“一个红色的立方体在一个蓝色的球体上方”),模型常常混淆属性与位置。
文本渲染难题:模型将文字视为像素图案,而非具有语义的符号。这导致它难以准确渲染长句,常出现拼写错误、字符粘连或无意义的“伪文字”。
缺乏常识与物理约束:模型可能生成违反基本物理常识或逻辑的图像,因为它缺少对世界运作方式的深层理解。
指令的脆弱性:微小的提示词变动可能导致生成结果的巨大差异,控制性与可预测性较弱。
2.2 Gemini 3 Pro Image 的概念工作流
Gemini 3 Pro Image 通过在生成流程前置一个强大的推理与规划阶段来应对上述挑战。虽然谷歌未公布其底层具体实现,但我们可以构建一个高度概括的概念工作流来理解其运作机制。
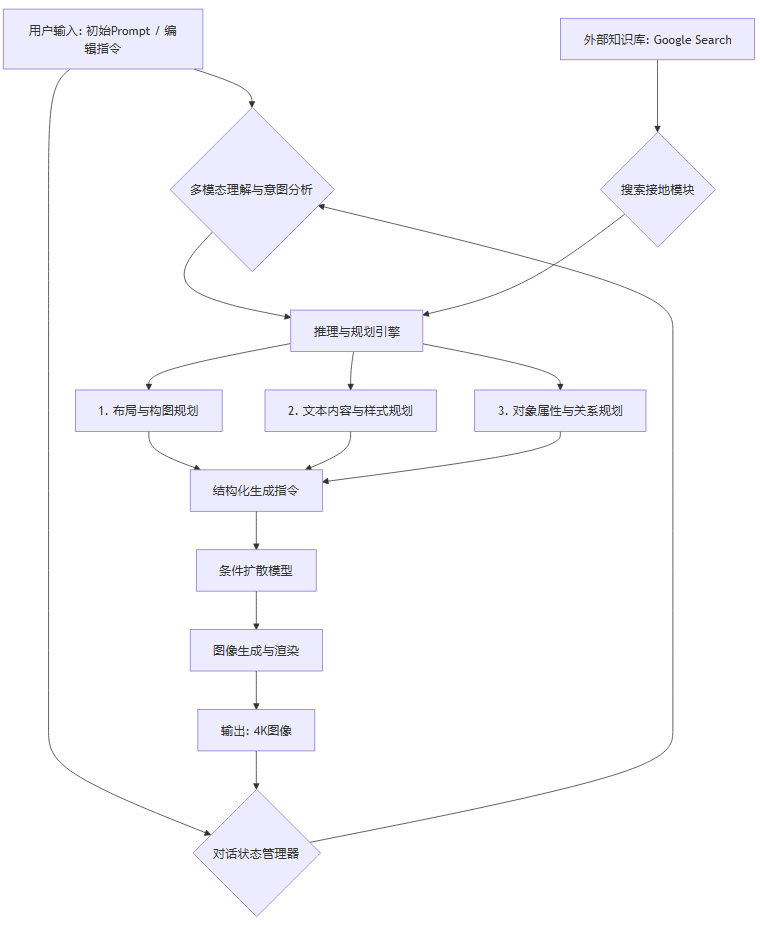
工作流解析:
多模态理解与意图分析:系统首先解析用户的输入,无论是初始的文本提示,还是后续的修改指令(如“把背景换成海滩”)。它需要准确理解用户的核心意图。
推理与规划引擎:这是整个系统的“大脑”。它接收到用户意图后,并不直接驱动生成,而是进行一系列规划。
搜索接地模块(Search Grounding):如果指令涉及事实性信息(如“生成一张包含最新财报数据的图表”),该模块会调用谷歌搜索等外部知识库,获取准确、实时的信息,并将其反馈给推理引擎。这是一种典型的**检索增强生成(RAG)**模式的应用。
规划分解:推理引擎会将复杂的生成任务分解为多个子任务。
布局与构图规划:决定画面中各个元素的位置、大小和比例。
文本内容与样式规划:确定要渲染的文字内容、字体、颜色和位置。
对象属性与关系规划:明确每个对象的具体属性(颜色、形状)以及它们之间的空间和逻辑关系。
结构化生成指令:规划阶段的输出不是一张图,而是一份高度结构化的“蓝图”或内部指令。这份指令详细描述了最终图像应包含的所有细节。
条件扩散模型:最终的图像生成器(很可能是一个先进的扩散模型)接收这份结构化指令作为强条件,然后执行生成任务。由于条件极其明确和详细,生成过程的随机性被大大降低,可控性显著增强。
对话状态管理器:在多轮编辑中,该模块负责记录和维护对话历史与当前的图像状态,确保后续指令能够在前一轮结果的基础上进行,实现连贯的创作体验。
2.3 关键机制深度剖析
2.3.1 推理能力如何提升图像质量
推理能力并非一个空泛的概念,它具体体现在以下几个方面,从而直接提升了最终的图像质量与可用性。
减少“幻觉”:通过逻辑推理和事实核查,模型能有效减少凭空捏造、不合常理的内容。例如,它会知道“鱼”通常在“水”里,而不是在“天上飞”。
提升组合准确性:在处理复杂场景时,推理引擎会预先规划好对象间的关系,再指导生成。这使得它在处理“红方块在蓝球上”这类指令时,准确率远高于传统模型。
增强细节一致性:对于需要精细描绘的场景,如机械内部结构或建筑蓝图,推理能力可以确保各个部件之间的连接和比例符合逻辑。
2.3.2 对话式多轮编辑的状态管理
实现流畅的多轮编辑,关键在于状态管理。Gemini 3 Pro Image 必须能够将每一轮的对话和图像结果编码为一个可更新的“状态”。
可以设想其内部维护着一个**场景图(Scene Graph)**或类似的数据结构。
初始生成:第一个 prompt 会生成一个初始的场景图,描述了图像中的所有对象、属性和关系。
编辑指令:当用户输入“把苹果变成橙色”时,系统会:
解析指令,定位到场景图中代表“苹果”的节点。
修改该节点的“颜色”属性为“橙色”。
基于更新后的场景图,重新生成或局部重绘图像。
这种机制使得编辑过程精确、高效,避免了每次修改都像是在“开盲盒”。
2.3.3 文本渲染的技术猜想
精准的文本渲染是该模型的一大亮点。其背后可能采用了多种技术的结合。
字形感知(Glyph-Aware)注意力机制:在模型的注意力层中,可能引入了专门处理字符字形的机制,使其能够理解单词的结构,而不仅仅是像素块。
OCR-in-the-Loop 训练:在训练过程中,可能引入了一个OCR(光学字符识别)模型作为判别器的一部分。如果生成的图像中的文字无法被OCR模型准确识别,就会给生成器一个负向的反馈信号,从而迫使生成器学习如何渲染清晰、可读的文字。
独立的文本渲染模块:一种更直接的方式是,在图像生成后,由一个专门的、高度可控的文本渲染模块将文字“贴”到指定位置。但这需要解决融合自然度的问题。更可能的方式是,文本渲染与图像生成在潜在空间(Latent Space)中就已深度耦合。
三、🚀 关键能力与应用场景剖析
%20拷贝.jpg)
理论上的架构优势,最终需要通过具体的功能和应用场景来体现。Gemini 3 Pro Image 的各项能力紧密围绕其“专业级、工作流”的定位展开。
3.1 输出与渲染能力
3.1.1 高达 4K 的分辨率输出
支持 1K (1024x1024)、2K (2048x2048) 和 4K (4096x4096) 等多种分辨率输出,是其专业性的直接体现。
技术挑战:生成高分辨率图像对计算资源(特别是显存)要求极高。同时,需要确保在放大分辨率后,图像的细节、纹理和整体一致性不会丢失。这通常需要采用先进的上采样技术或分块渲染(Tiled Diffusion)等策略。
应用价值:
印刷行业:4K分辨率足以满足大多数商业印刷品(如海报、宣传册、包装)的精度要求。
数字媒体:可直接用于高清显示屏、网站大图、社交媒体高质量素材。
影视制作:可作为概念设计图、背景板(Matte Painting)或纹理贴图的素材。
3.1.2 稳定可靠的长文本渲染
这是 Gemini 3 Pro Image 的核心差异化优势之一。它不仅能渲染文字,还能很好地处理长段落、多语言混合、以及与复杂背景的融合。
应用场景:
营销海报:生成包含完整广告语、活动详情、联系方式的海报。
社交媒体帖子:制作图文并茂的帖子,文字部分清晰可读。
产品说明图:为产品图片添加详细的功能注解和使用说明。
资讯图表:生成包含标题、数据标签、信息来源等大量文本的图表。
3.2 交互与控制能力
3.2.1 对话式多轮编辑
这是提升工作流效率的关键。用户无需在每次微调时都重写一个冗长复杂的 prompt,而是可以通过自然语言对话进行迭代。
示例工作流:
用户:“生成一张科技公司发布会的宣传海报,主色调为蓝色,主题是‘AI的未来’。”
模型:生成第一版海报。
用户:“很好。把中间的产品图换成一个发光的芯片。”
模型:更新海报,替换中心元素。
用户:“把右上角的logo变大一些,然后在底部加上一行小字‘2024年12月1日,全球直播’。”
模型:再次更新海报,调整logo大小并添加文字。
用户:“字体换成无衬线的,看起来更现代。”
模型:最终版海报生成。
这个过程极大地模拟了设计师与甲方的沟通流程,使得AI工具能更好地融入现有的创意工作体系。
3.2.2 基于搜索的“接地”机制
该功能确保了生成内容的事实准确性与时效性。
工作原理:当模型识别到 prompt 中包含需要事实支撑的元素时(如“最新的市场份额数据”、“某公司的CEO”),它会触发搜索模块,获取权威信息,并将这些信息作为生成图像的强约束。
典型应用:
新闻配图:根据新闻事件,生成包含准确人物、地点和场景的插图。
电商促销:生成包含实时折扣信息、库存数量的商品海报。
教育科普:制作包含准确科学数据、历史年份的科普图。
3.3 场景应用矩阵
为了更直观地展示其能力与应用场景的对应关系,可以整理如下矩阵。
四、👨💻 开发者接入与集成实践
对于技术人员而言,理解模型的API设计与集成方式至关重要。Gemini 3 Pro Image 提供了清晰的接入路径和灵活的参数配置。
4.1 API 核心参数解析
虽然具体的SDK实现会不断迭代,但其核心API必然会围绕以下参数展开。这些参数的设计,直接反映了模型的能力边界。
4.2 Python SDK 集成示例 (伪代码)
以下是一个基于推测的 Python SDK 使用示例,演示了如何进行一次包含多轮编辑的调用。
python:
import google.generativeai as genai
import uuid
# 配置你的API Key
genai.configure(api_key="YOUR_API_KEY")
# 1. 初始化模型
# 在实际SDK中,模型名称可能有所不同
model = genai.GenerativeModel('gemini-3-pro-image-preview')
# 2. 创建一个唯一的会话ID用于多轮对话
session_id = str(uuid.uuid4())
# 3. 第一次生成 (初始海报)
print("--- Round 1: Generating initial poster ---")
initial_prompt = "A promotional poster for a new sci-fi movie 'Cosmic Rift'. Main colors are deep blue and purple. Include the title 'Cosmic Rift' in a futuristic font."
response_1 = model.generate_content(
prompt=initial_prompt,
session_id=session_id,
resolution="2048x2048",
aspect_ratio="2:3"
)
# 假设 response_1.image 是生成的图像对象
generated_image_1 = response_1.image
generated_image_1.save("poster_v1.png")
print("Poster v1 saved.")
# 4. 第二次生成 (编辑指令)
print("\n--- Round 2: Editing the poster ---")
edit_prompt = "Change the title font to be more bold and add a tagline below it: 'The universe is not what it seems.'"
response_2 = model.generate_content(
prompt=edit_prompt,
session_id=session_id, # 使用相同的session_id来维持上下文
image_context=generated_image_1 # 将上一轮的图像作为上下文
)
generated_image_2 = response_2.image
generated_image_2.save("poster_v2.png")
print("Poster v2 saved.")
4.3 集成工作流建议
在将 Gemini 3 Pro Image 集成到实际应用中时,建议遵循以下工作流。
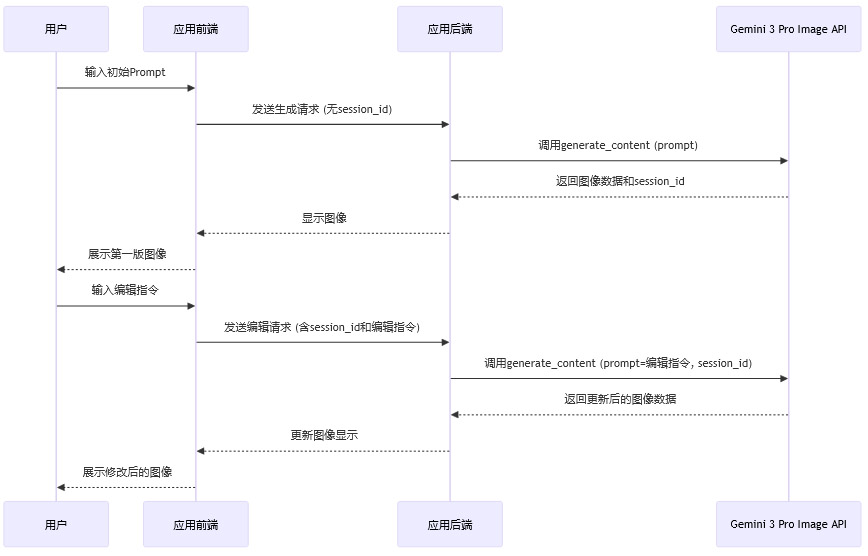
这个流程的核心是由后端服务来管理 session_id,并将其与特定的用户会话或创作项目绑定,从而为前端用户提供无缝的多轮编辑体验。
五、🌐 行业影响与未来展望
%20拷贝.jpg)
Gemini 3 Pro Image 的发布,不仅是谷歌自身产品线的补强,也可能对整个AIGC行业生态产生深远影响。
5.1 从“炼丹”到“协同”
当前,高质量的AI图像生成在很大程度上依赖于复杂的提示词工程(Prompt Engineering),这个过程被戏称为“炼丹”。用户需要不断尝试和调整关键词、权重、风格描述,才能得到满意的结果。
Gemini 3 Pro Image 的多轮对话编辑能力,有望将这种交互模式从**“指令式炼丹”转变为“对话式协同”**。用户不再需要一次性写出完美的 prompt,而是可以像与人类设计师沟通一样,通过逐步求精的方式达到目标。这将极大地降低专业级图像生成的使用门槛,让更多非技术背景的创意人员也能高效利用AI。
5.2 对创意工作流的重塑
对于广告、设计、营销等行业,Gemini 3 Pro Image 可能成为一种基础性的生产力工具,深度嵌入其工作流中。
创意构思阶段:快速生成大量高质量的视觉概念(Moodboard),并进行迭代。
物料生产阶段:自动化生成不同尺寸、不同文案版本的营销素材,极大提升效率。
个性化营销:结合用户数据,动态生成千人千面的广告图片和电商主图。
它不会完全取代人类设计师,但会将其从大量重复、机械的执行工作中解放出来,更专注于创意、策略和审美把控。
5.3 未来技术演进方向
Gemini 3 Pro Image Preview 只是一个开始。基于其“推理优先”的架构,未来的演进方向充满想象空间。
视频生成:将推理能力扩展到时序维度,生成逻辑连贯、情节合理的短视频。
3D资产生成:根据文本或2D图像,生成结构合理、拓扑正确的3D模型。
交互式场景生成:生成可交互的虚拟环境,用户可以在其中通过自然语言修改场景中的对象和布局。
更深度的生态集成:与 Google Workspace(如幻灯片、文档)、Google Ads 等产品深度打通,实现AI能力的原生化。
结论
Gemini 3 Pro Image Preview 的发布,是图像生成技术从“感知智能”向“认知智能”跨越的重要标志。它通过将推理能力置于生成流程的核心,系统性地解决了当前AIGC在逻辑性、准确性和可控性上的诸多痛点。其支持的4K分辨率、多轮对话编辑、精准长文本渲染以及事实接地功能,共同构成了一个面向专业级应用的强大工具集。
对于开发者和企业而言,这不仅意味着一个更强大的API,更代表了一种全新的、更符合人类创作习惯的交互范式。它预示着AI在创意领域的角色,正在从一个捉摸不定的“灵感缪斯”,转变为一个逻辑清晰、沟通顺畅、值得信赖的“数字设计助理”。随着模型的持续迭代和生态的不断完善,我们有理由相信,一个由AI深度赋能的、更高效、更智能的视觉内容创作时代正在加速到来。
📢💻 【省心锐评】
Gemini 3 Pro Image 不再是简单的“画图匠”,而是进化为带“脑子”的“设计合伙人”。推理先行,解决了AIGC的逻辑硬伤;多轮对话,让修改不再靠“玄学”。这是生产力,而非玩具。

评论