.png)
%20%E6%8B%B7%E8%B4%9D-bixw.jpg)

【摘要】AI重塑交易边界,算力与算法构建新护城河,但黑箱与过拟合风险仍是达摩克利斯之剑。
在金融科技的演进历程中,量化交易正经历着从“因子挖掘”向“端到端深度学习”的范式转移。过去,量化分析师(Quants)依赖线性回归和人工构造的因子来解释市场;如今,人工智能(AI)特别是深度学习(Deep Learning)和强化学习(Reinforcement Learning)的引入,使得机器能够处理海量非结构化数据,捕捉人类难以察觉的非线性规律。
然而,技术红利的背后并非坦途。金融市场的低信噪比(Low Signal-to-Noise Ratio)特性,使得AI模型极易陷入过拟合的泥潭。更深层次的隐忧在于,当深度神经网络接管了数万亿资金的决策权,其“黑箱”特性与潜在的算法共振,可能为全球金融系统埋下未知的系统性风险。
本文将从技术架构、算法原理及市场生态三个维度,深入剖析AI量化交易的显著优势、核心技术挑战及潜在的系统性风险,旨在为专业投资者和技术从业者提供一个冷静、客观的分析框架。
🚀 一、 核心优势:技术维度的降维打击
%20拷贝-uujz.jpg)
AI量化并非简单的自动化交易,而是对传统量化策略在数据处理广度、预测模型深度以及执行策略精度上的全面升维。
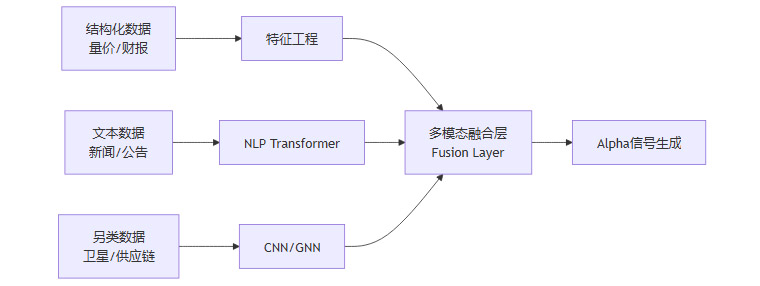
1.1 多源异构数据的全景解析能力
传统量化模型主要依赖结构化数据(如开盘价、收盘价、成交量、财务报表)。这类数据虽然规范,但信息密度已被市场充分挖掘,超额收益(Alpha)日益稀薄。AI技术,尤其是自然语言处理(NLP)和计算机视觉(CV),打破了数据模态的壁垒。
1.1.1 非结构化数据的特征提取
深度学习模型能够直接从非结构化数据中提取有效因子,构建信息优势:
文本数据(NLP): 利用BERT、FinBERT等预训练模型,AI可以实时解析美联储会议纪要、上市公司财报电话会(Earnings Calls)的文本情绪,甚至分析社交媒体(Twitter、Reddit)上的散户情绪指标。这种语义理解能力远超传统的词频统计(Bag-of-Words)。
图像数据(CV): 卷积神经网络(CNN)被应用于卫星图像分析(如监测原油储罐液位、沃尔玛停车场车流)以预测大宗商品或零售股走势。
图数据(Graph Neural Networks): 利用图神经网络分析供应链关系、股权穿透图谱,捕捉个股风险在产业链上的传导路径。
1.1.2 数据融合架构
AI系统通过多模态学习(Multimodal Learning),将异构数据映射到统一的向量空间进行融合。
1.2 非线性特征与高维模式识别
金融市场本质上是一个复杂的非线性动力系统。传统的多因子模型(Multi-factor Model)通常假设因子与收益率之间存在线性关系(R=α+βX+ϵR=α+βX+ϵ),这种假设在极端行情或复杂市场结构下往往失效。
捕捉非线性关系: 深度神经网络(DNN)通过多层非线性激活函数(ReLU, Tanh),能够逼近任意复杂的函数关系。这意味着AI可以自动发现因子之间的高阶交互作用(Interaction Effects),例如“只有在波动率高且流动性低时,动量因子才有效”这类条件逻辑,而无需人工预设。
时序依赖性建模: 循环神经网络(RNN)及其变体LSTM、GRU,以及最新的Transformer架构(如Time-Series Transformer),擅长处理时间序列的长短期依赖。它们不仅关注当前时刻的输入,还能“记忆”历史市场状态,从而在趋势识别和反转预测上表现出更高的鲁棒性。
1.3 强化学习驱动的执行优化
在交易执行环节,AI的目标不再是预测价格涨跌,而是以最优价格完成买卖,减少市场冲击成本(Market Impact)。
智能算法交易(Algorithmic Trading): 传统的TWAP(时间加权平均价格)或VWAP(成交量加权平均价格)算法规则固定,容易被对手方识别并进行“掠夺性交易”。
强化学习(RL)代理: 基于RL的执行算法(如PPO, DQN)将交易过程建模为马尔可夫决策过程(MDP)。智能体(Agent)在模拟环境或实盘中通过不断试错,学习如何在流动性、波动率和时间紧迫性之间通过动态调整挂单策略(Limit Order vs. Market Order)来最大化回报。这种策略具有极强的自适应性,能在市场微观结构变化时自动调整执行逻辑。
🧊 二、 核心挑战:“黑箱”难题与可解释性危机
尽管AI在预测精度上表现卓越,但其“端到端”的学习方式带来了一个致命缺陷——缺乏可解释性(Interpretability)。在金融领域,这不仅是技术问题,更是合规与信任问题。
2.1 深度神经网络的“黑箱”本质
深度学习模型通常包含数百万甚至数十亿个参数。输入数据经过数十层矩阵运算和非线性变换后输出结果,中间过程对于人类而言如同“黑箱”。
逻辑缺失: 当模型发出“买入”指令时,基金经理无法像传统量化那样解释是因为“低市盈率”还是“动量效应”。模型可能关注了数据中的某些微小噪声或虚假关联。
归因困难: 在模型亏损时,难以快速定位是数据源问题、模型结构问题,还是市场环境发生了根本性变化。这种不可知性在管理大资金时是巨大的心理负担和风控隐患。
2.2 信任鸿沟与监管压力
金融监管机构(如SEC、CSRC)要求金融机构必须能够解释其投资决策的依据,以防止市场操纵或歧视性定价。
合规风险: 如果AI模型在无意中学习到了某种非法的市场操纵手法(如Spoofing,虚假挂单),或者基于某种偏见进行交易,机构将面临巨额罚款。由于无法审查模型内部逻辑,合规部门难以进行事前风控。
投资者信任: 对于机构投资者(LP)而言,他们需要理解策略的收益来源(Source of Return)。如果只能展示回测曲线而无法解释策略逻辑,很难获得长期资金的信任。
2.3 试图打开黑箱:XAI的局限
为了解决这一问题,可解释性AI(Explainable AI, XAI)技术应运而生,但在金融场景下仍面临挑战。
事后解释(Post-hoc Explanation): 常用的SHAP(Shapley Additive Explanations)值或LIME方法,试图通过扰动输入数据来观察输出变化,从而推断特征重要性。然而,这种解释往往是局部的、近似的,并不一定真实反映了模型的全局决策逻辑。
特征相关性干扰: 金融特征之间存在高度相关性(如价格与成交量、不同技术指标之间)。这种多重共线性(Multicollinearity)会导致XAI工具给出的特征归因不稳定,误导风控人员。
📉 三、 统计陷阱:过拟合与幸存者偏差
%20拷贝-rabg.jpg)
AI模型强大的拟合能力是一把双刃剑。在图像识别领域,过拟合可以通过数据增强解决;但在金融领域,过拟合是导致策略实盘失效(Fail in Live Trading)的头号杀手。
3.1 金融数据的“低信噪比”诅咒
与图像或语音数据不同,金融时间序列数据具有极低的信噪比。市场价格的大部分波动是随机噪声,只有极少部分包含确定性的规律。
噪声拟合: 深度学习模型参数众多,极易将历史数据中的随机噪声误认为是市场规律并加以记忆。这种模型在训练集和回测中表现完美(Sharpe Ratio > 3),但一旦上线实盘,面对全新的随机噪声,表现就会一落千丈。
非平稳性(Non-Stationarity): 市场结构是动态变化的(Regime Shift)。2008年的市场规律不一定适用于2024年。AI模型如果过度依赖历史数据训练,往往缺乏泛化能力(Generalization),无法适应新的市场环境。
3.2 回测中的“纸面富贵”
AI量化开发过程中,极易陷入各种统计偏差,制造出虚假的高收益回测。
前视偏差(Look-ahead Bias): 在训练模型时,不小心使用了未来时刻的数据(例如使用当天的收盘价来决定当天的开盘买入),导致回测结果虚高。
幸存者偏差(Survivorship Bias): 训练数据只包含当前上市的公司,忽略了历史上退市或破产的公司。模型会错误地认为“买入低价股”总能翻身,而忽略了归零的风险。
多重测试陷阱(P-hacking): 研究员尝试了成千上万种模型结构和参数组合,最终只挑出一个在历史上表现最好的。这本质上是在“拷问数据直到它招供”,选出的策略往往只是运气好,而非具备真实Alpha。
3.3 对抗过拟合的技术手段
为了缓解上述问题,专业的AI量化团队通常采用严格的验证流程:
清除式交叉验证(Purged K-Fold Cross Validation): 在划分训练集和测试集时,强制剔除由于序列相关性导致的信息泄露部分,确保测试数据的独立性。
特征正交化与降维: 使用PCA(主成分分析)或Autoencoder对输入特征进行降维和去噪,减少模型可利用的噪声信息。
对抗性训练(Adversarial Training): 在训练数据中人为加入扰动,强迫模型学习更鲁棒的特征,而不是死记硬背历史点位。
🌪️ 四、 系统性风险:算法共振与流动性黑洞
当视角从单个模型上升到整个市场生态时,AI量化的广泛应用可能催生新型的系统性风险。这种风险不再源于基本面恶化,而源于算法行为的同质化。
4.1 策略同质化与“算法拥挤”
尽管各家机构声称拥有独家模型,但大家使用的数据源(交易所行情、主流另类数据)和基础算法架构(Transformer、LSTM、XGBoost)往往高度相似。
同质化决策: 这种底层的相似性可能导致不同机构的AI模型在特定市场信号触发下,做出完全相同的交易决策。例如,当某一技术指标跌破阈值,所有模型同时发出卖出指令。
拥挤交易(Crowded Trade): 当大量资金涌入同一类策略时,该策略的Alpha会迅速衰减。更危险的是,一旦市场反转,所有算法同时试图平仓,会导致踩踏效应。
4.2 瞬时流动性枯竭与闪崩
AI交易的高速特性意味着市场反应速度被压缩到毫秒级。
流动性幻觉: 在平稳市场中,高频做市商(HFT)提供了大量挂单,看似流动性充裕。然而,一旦发生突发事件(黑天鹅),AI风控系统会瞬间撤单(Cancel Orders)以自保。
闪崩(Flash Crash): 此时,买盘瞬间消失,而趋势跟踪算法仍在疯狂抛售,导致资产价格在几秒钟内自由落体。2010年美股“5·6闪崩”事件便是算法引发流动性枯竭的典型案例。AI模型的自动化和去情绪化,在恐慌时刻反而可能加速市场的崩溃,因为它们缺乏人类交易员在极端时刻“暂停思考”的机制。
4.3 难以预测的“黑天鹅”
AI模型是基于历史数据训练的归纳法工具。它只能预测“历史上发生过”或“与历史相似”的情景。
分布外样本(OOD): 对于前所未有的地缘政治危机、突发公共卫生事件(如COVID-19初期)或从未出现过的市场结构突变,AI模型处于“盲飞”状态。
错误置信度: 在面对未知数据时,深度学习模型往往不能诚实地输出“我不知道”,而是会给出一个基于错误逻辑的高置信度预测,误导交易系统进行重仓操作,造成巨额亏损。
🛡️ 五、 架构设计与风控:人机协同的最佳实践
%20拷贝-psva.jpg)
面对AI量化的机遇与风险,构建稳健的交易系统需要超越单纯的算法竞赛,转向架构设计与人机协同的深层融合。
5.1 “半人马”模式(Centaur Model)
完全的自动化在当前技术条件下仍具高风险,理想的模式是“AI负责战术,人类负责战略”。
AI的角色: 负责海量数据的清洗、特征提取、短周期信号生成以及高精度的执行算法。AI在处理微观结构和高频数据上具有绝对优势。
人类的角色: 负责宏观逻辑判断、策略组合配置以及极端风险管理。人类交易员需要监控模型的运行状态,当市场出现模型未曾见过的宏观事件时,及时介入干预或熔断。
5.2 分层风控体系
构建独立于AI模型之外的硬风控系统是生存的关键。
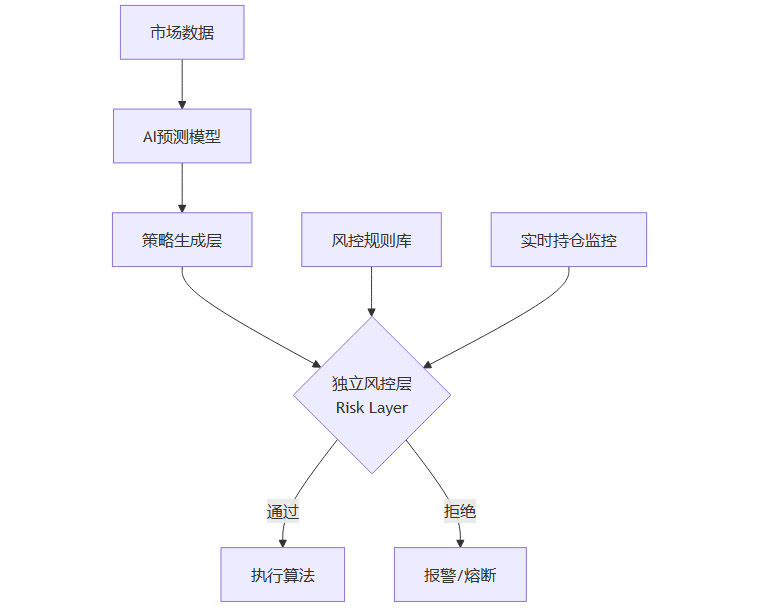
白名单与黑名单机制: 限制AI只能在特定的股票池或资产类别中交易,避免其介入流动性差或风险不可控的标的。
硬约束(Hard Constraints): 设定严格的最大持仓限制、单日最大亏损限制(Max Drawdown)、最大杠杆率。无论AI模型预测的胜率有多高,都不能突破这些硬性边界。
异常检测: 监控AI模型的行为模式。如果模型的换手率突然飙升,或者持仓集中度异常提高,风控系统应自动切断交易权限,防止代码Bug或模型失控导致的损失。
5.3 持续的算法审计与压力测试
影子交易(Shadow Trading): 新模型上线前,必须在实盘环境中进行长时间的影子交易(只产生信号不执行),验证其在真实市场环境下的表现与回测是否一致。
压力测试(Stress Testing): 模拟历史上的极端行情(如2008年金融危机、2020年美股熔断),观察AI模型在这些极端场景下的净值波动和流动性风险,确保其具备穿越周期的生存能力。
结论
AI量化交易是金融市场不可逆转的进化方向。它以极致的效率、客观的纪律和强大的数据洞察力,正在重构投资的底层逻辑。然而,技术并非万能的炼金术。黑箱模型的可解释性缺失、统计学上的过拟合陷阱,以及算法同质化带来的系统性共振,构成了悬在投资者头顶的达摩克利斯之剑。
对于从业者而言,成功的关键不在于拥有最复杂的神经网络,而在于对市场的敬畏之心。通过建立“人机结合”的决策体系,在利用AI提升效率的同时,保留人类对宏观风险的终极把控,才是驾驭这一强大工具的正确之道。在算法与数据的海洋中,唯有理性与风控,是通往长期复利的唯一灯塔。
📢💻 【省心锐评】
AI是显微镜,能看清微观规律;但不是望远镜,看不清宏观黑天鹅。别把油门当刹车,人机协同才是量化的终局。

评论