.png)


【摘要】苹果发布Pico-Banana-400K数据集,利用谷歌Gemini模型构建,旨在解决AI图像编辑领域高质量、开放训练数据的稀缺问题,为行业树立了新的基准。
引言
近年来,生成式AI在图像领域的进展令人瞩目。文本引导的图像编辑技术,作为其中的关键分支,正从“玩具”阶段迈向实用化。用户期望通过简单的自然语言指令,实现对图像内容的精准、可控修改。然而,模型能力的跃升背后,一个长期存在的瓶颈愈发凸显,那就是高质量训练数据的极度匮乏。多数前沿模型依赖私有、未公开的数据集进行训练,这不仅阻碍了学术界的复现与跟进,也限制了技术的开放创新。
在此背景下,苹果公司发布了Pico-Banana-400K。这个包含约40万图像对的大规模数据集,不仅完全开放用于非商业研究,其构建过程本身也极具开创性。它借助谷歌顶尖的Gemini系列模型,建立了一套自动化、高标准的“数据生产线”。这不仅是苹果在AI基础资源建设上的一次重要布局,也为整个行业如何构建下一代AI训练数据提供了范本。
一、 数据集发布的背景:破解图像编辑模型的“数据困境”
%20拷贝.jpg)
要理解Pico-Banana-400K的价值,必须先审视当前AI图像编辑领域面临的共同挑战。
1.1 AI图像编辑的技术现状与挑战
当前主流的文本引导图像编辑技术,大多基于扩散模型(Diffusion Models)。其核心思想是通过在噪声分布上进行迭代去噪,逐步生成符合文本描述的图像。诸如InstructPix2Pix、ControlNet等模型的出现,使得对现有图像的编辑成为可能。
尽管技术路径日渐清晰,但实际应用中仍面临诸多挑战。
指令遵从度(Instruction Following)。模型能否准确理解并执行复杂的、包含多个约束条件的编辑指令。
保真度(Fidelity)。在编辑目标区域的同时,如何最大限度地保留非编辑区域的原始细节与风格。
泛化能力(Generalization)。模型是否能处理多样化的图像风格、主题和编辑任务,而不是仅在特定领域表现良好。
提升这些能力,本质上依赖于模型“见过”足够多、足够好的“编辑范例”。数据,正是这一切的基础。
1.2 现有数据集的“三大短板”
在Pico-Banana-400K出现之前,研究社区可用的公开数据集普遍存在以下问题,严重制约了模型研发的进展。苹果的研究团队在论文中也明确指出了这些痛点。
这些短板共同构成了一道“数据壁垒”,使得图像编辑模型的研究陷入了“闭门造车”或“小作坊”式的困境。
1.3 Pico-Banana-400K的破局之道
Pico-Banana-400K的设计初衷,正是为了系统性地解决上述三大短板。它的核心思路是,利用当前最先进的大模型(SOTA Models)作为“生产工具”和“质检员”,自动化地构建一个大规模、高质量、多样化的开放数据集。
破局规模与开放性。通过自动化流程生成约40万样本,并采用非商业研究许可完全开放,为社区提供了前所未有的资源。
破局质量与一致性。采用“生成-评估”双模型闭环,确保每一条数据都经过严格的质量检验,保证了高度的一致性。
破局多样性与覆盖度。精心设计了覆盖8大类、35种子任务的编辑指令体系,系统性地保证了数据集的多样性。
二、 Pico-Banana-400K数据集深度解析
Pico-Banana-400K的构建流程,是其技术价值的核心体现。它展示了一套先进、可复现的数据工程方法论。
2.1 核心理念:自动化、规模化与高质量的统一
数据集的构建摒弃了传统依赖大量人工标注的模式,转而采用“模型协同”的范式。其流水线(Pipeline)设计的关键在于将复杂的任务拆解,并为每个环节选择最合适的AI模型。
生成模型。选用谷歌的Gemini 2.5-Flash-Image(即Nanon-Banana),该模型在图像编辑任务上表现出色,被认为是当前最先进的工具之一。
评估模型。选用谷歌的Gemini 2.5-Pro,利用其强大的多模态理解与逻辑推理能力,充当自动化“质量评估员”。
这种“左右互搏”式的设计,确保了数据生产的效率与质量。
2.2 数据生成流水线(Pipeline)详解
整个数据集的生成过程可以被清晰地划分为四个阶段。
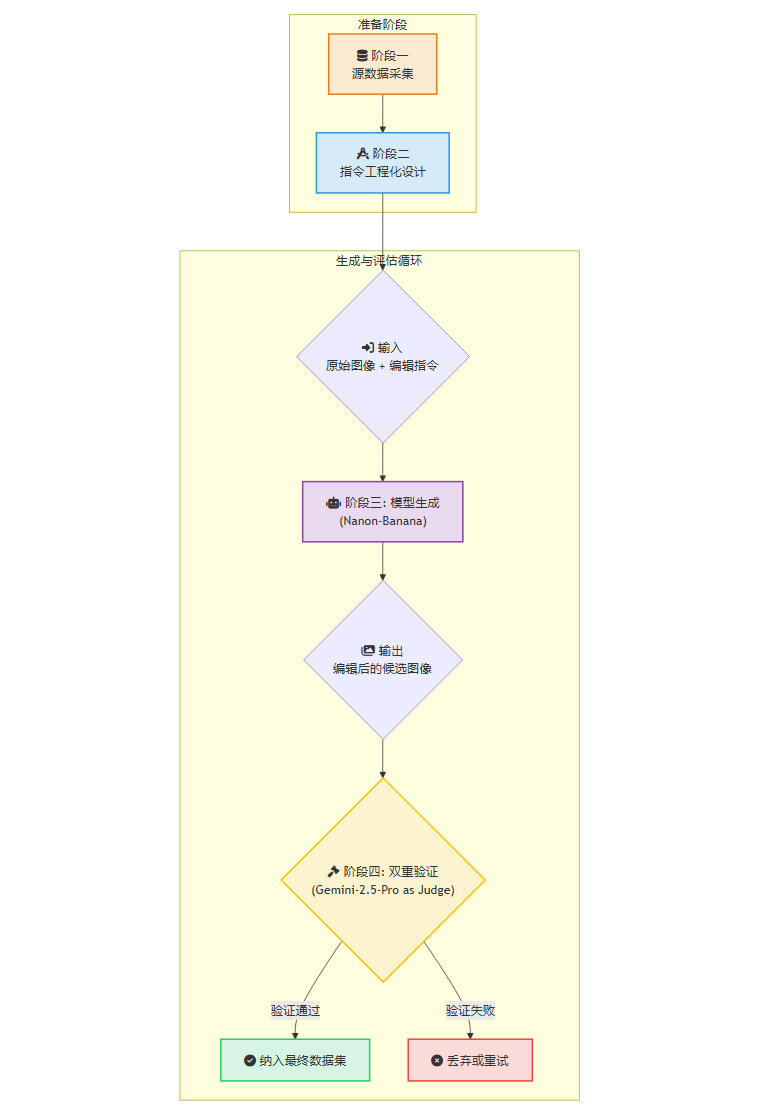
2.2.1 阶段一:源数据采集
数据集的起点是真实世界的图像。研究团队选择了OpenImages数据集作为源。这是一个由谷歌构建的大规模、包含复杂场景的图像库。
选择OpenImages的优势在于。
真实性与多样性。图像来源于真实生活场景,避免了合成数据带来的领域偏移问题。
内容丰富。涵盖了人物、动物、物体、建筑以及包含文字的各种场景,为后续多样化的编辑任务提供了坚实基础。
2.2.2 阶段二:指令工程化设计
这是确保数据集多样性的关键环节。团队没有随机生成指令,而是系统性地设计了一套指令框架。该框架包含8个大类(Categories)和35种具体的编辑任务(Tasks)。
这套指令体系确保了Pico-Banana-400K能够全面地测试和训练模型在不同维度上的编辑能力。
2.2.3 阶段三:模型驱动的图像生成
在此阶段,流水线将一张从OpenImages中选取的原始图像和一条设计好的编辑指令,共同输入到Nanon-Banana模型中。模型会根据指令对图像进行编辑,并输出一张候选结果。
例如,输入是“一张汽车在晴天的照片”和指令“Change the weather to snowy”,Nanon-Banana会生成一张“汽车在雪天的照片”。
2.2.4 阶段四:双重验证的质量控制
这是Pico-Banana-400K区别于其他数据集的核心步骤。Nanon-Banana生成的图像不会被直接采纳。相反,它会连同原始图像和编辑指令一起,被送入Gemini 2.5-Pro模型进行评估。
Gemini 2.5-Pro会扮演“裁判”的角色,从两个维度进行打分。
指令遵循度。编辑后的图像是否准确、完整地执行了指令?例如,要求“将黄花变为紫花”,结果是否真的变紫了,且没有改变其他内容。
视觉质量。编辑后的图像是否存在明显的伪影、扭曲、模糊或不合逻辑之处?整体视觉效果是否自然、协调。
只有同时满足这两个标准的图像,才会被判定为“成功样本”,并被纳入最终的数据集。如果验证失败,该样本将被丢弃,或者系统会尝试重新生成。这个闭环质控流程,极大地提升了数据的可靠性。
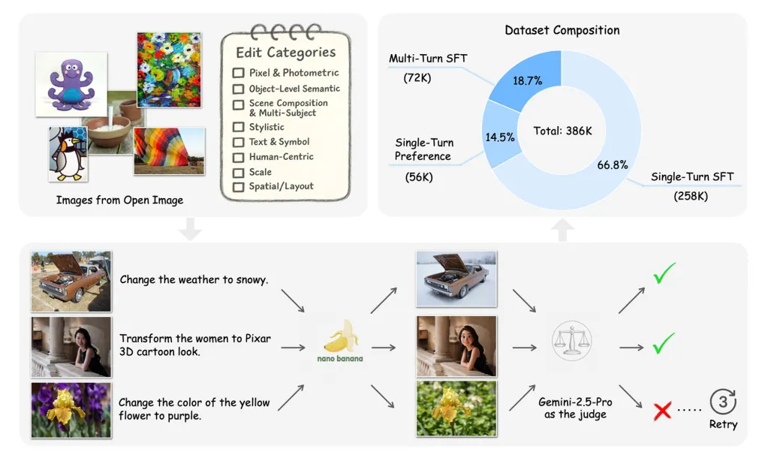
2.3 数据集结构与组成
最终生成的Pico-Banana-400K数据集(总计约38.6万,接近40万)并非单一结构,而是由三种不同类型的样本构成,以满足不同训练范式的需求。
这种复合式的数据结构设计,使得Pico-Banana-400K不仅能用于基础的模型能力训练,还能支持更前沿的模型对齐(Alignment)研究,极大地扩展了其应用价值。
2.4 编辑指令的多样性与覆盖度
数据集的强大之处,直观地体现在其丰富的编辑效果上。从简单的季节变换到复杂的人物风格化,Pico-Banana-400K提供了大量高质量的“前后对比”范例。

上图展示了数据集中部分编辑类型的实际效果。例如。
季节变换。将夏日的自行车场景无缝转换为冬日雪景。
艺术风格迁移。将一张普通的轮船照片渲染成梵高《星夜》的风格。
对象添加。在宁静的湖面场景中,合乎逻辑地加入一只野鸭。
人物风格化。将真实人物照片转换为乐高小人或Funko-Pop玩偶的3D形象,同时保持了人物的基本特征和姿态。
文本编辑。精准地修改漫画对话框中的文字内容。
这些多样化的样本,为训练能够应对各种创意需求的通用图像编辑模型奠定了坚实的基础。
三、 技术局限性与未来研究方向
%20拷贝.jpg)
一篇客观的技术分析,必须正视其局限性。Pico-Banana-400K的质量上限,直接受限于其“生产者”——Nanon-Banana模型的能力天花板。苹果的研究团队对此有清醒的认识,并在论文中坦诚地指出了当前存在的短板。这些短板不仅是该数据集的固有属性,也为未来的研究指明了方向。
3.1 当前模型能力的边界
尽管Nanon-Banana已是业界顶尖的图像编辑模型,但它在处理某些高度精细化的任务时,仍会表现出不足。这些不足主要集中在以下三个方面。
3.1.1 精细空间控制 (Fine-grained Spatial Control)
这是当前所有主流扩散模型面临的共同难题。模型在理解“什么”上表现出色,但在理解“在哪里”和“多大”上仍有欠缺。
问题表现。当指令涉及精确的位置、尺寸或计数时,模型往往难以完美执行。例如,“将图中左边第三本书变成红色”或者“在桌子上放一个5厘米高的苹果”,模型可能无法准确识别“第三本”,也无法精确控制“5厘米”。
技术根源。扩散模型在潜空间(Latent Space)中进行操作,潜空间中的表征与图像的像素级笛卡尔坐标并非线性对应。虽然注意力机制(Attention Mechanism)能够建立文本与图像区域的关联,但这种关联通常是“模糊”的,而非“像素级精确”的。
3.1.2 复杂布局外推 (Complex Layout Extrapolation)
当编辑指令要求对场景布局进行重大改变时,模型的“想象力”和物理常识会受到考验。
问题表现。例如,指令为“在汽车后面加盖一座房子”。模型不仅要生成房子的纹理,还必须正确处理遮挡关系(房子遮挡部分背景)、光影一致性(房子的阴影应与汽车的阴影方向一致)以及透视关系(房子的尺寸和角度应符合场景的整体透视)。在复杂的场景中,模型很容易出现逻辑错误。
技术根源。这要求模型具备深层次的场景理解能力,甚至是一种隐式的3D几何感知。当前的2D扩散模型主要从海量图像数据中学习像素统计规律,对于三维世界的物理规则缺乏显式的建模。
3.1.3 高保真排版 (High-Fidelity Typography)
在图像中生成或编辑清晰、准确的文字,是生成式AI的一大技术难点。
问题表现。模型生成的文字常常出现拼写错误、字符扭曲、字体混乱或与背景融合不自然等问题。虽然Pico-Banana-400K包含了文本编辑任务,但其成功样本也反映了Nanon-Banana在这一领域的当前上限。
技术根源。文字的本质是符号系统,具有严格的结构和笔画。而扩散模型处理的是像素的连续分布,两者在底层逻辑上存在冲突。模型很难在生成像素的同时,完美地遵循字符的矢量结构。
3.2 数据集如何助力突破瓶颈
Pico-Banana-400K的设计,巧妙地将模型的局限性转化为了研究的机遇。
失败样本的价值。数据集中的“偏好对”(preference pairs)包含了大量失败案例。研究人员可以专门针对这些失败案例,分析模型犯错的模式,从而设计出更具鲁棒性的新模型架构或训练策略。
提供可量化的评测基准。有了这个标准化的数据集,任何新的模型都可以在相同的起跑线上进行测试。研究者可以针对上述“精细空间控制”、“复杂布局”等特定子集进行评测,量化新模型在解决这些难题上的进步。
驱动新算法的诞生。该数据集可以激励社区开发新的技术。例如,为了解决空间控制问题,可能会催生出结合了坐标输入或场景图(Scene Graph)的新型多模态模型。为了解决排版问题,可能会出现扩散模型与字符渲染引擎相结合的混合架构。
四、 行业影响与应用场景展望
Pico-Banana-400K的发布,其意义远不止于一个开源资源。它将对AI图像编辑领域的研究范式、技术迭代速度乃至商业应用落地产生深远影响。
4.1 对AI研究社区的价值
4.2 潜在的商业应用场景
一个强大、可控的图像编辑模型,背后是巨大的商业价值。Pico-Banana-400K将加速这些应用的成熟与落地。
电商与营销。商家可以快速生成产品在不同场景、不同搭配下的展示图。例如,对一件衣服,可以通过指令“更换模特背景为巴黎街头”或“将衣服颜色改为天蓝色”,极大地降低了营销物料的制作成本。
创意设计与广告。设计师可以将其作为高效的灵感激发和草图细化工具。通过“将草图转换为写实风格”或“为画面增加赛博朋克元素”,可以快速探索不同的视觉方案。
个人娱乐与社交媒体。用户可以轻松创造出个性化的、有趣的内容。类似“把我变成一个宇航员,背景是火星”这样的指令,将成为下一代图像滤镜和特效的核心驱动力。
影视与游戏制作。在概念设计和后期制作环节,可以用于快速生成场景氛围图、修复画面瑕疵或添加视觉特效,提升生产效率。
4.3 “巨头合作”的启示
苹果使用谷歌的模型来构建自己的研究资源,这一事件本身就传递出行业发展的重要信号。
在AI基础模型时代,“合作”与“竞争”的边界正在变得模糊。基础大模型(Foundation Models)正逐渐演变为一种类似于云计算的“基础设施”。公司间的竞争,将更多地体现在如何利用这些基础能力,结合自身的数据、场景和工程优势,构建出差异化的上层应用和极致的用户体验。
对于苹果而言,其优势在于庞大的设备生态、强大的端侧计算能力以及对用户体验的深刻理解。Pico-Banana-400K的发布,可以看作是其在“AI应用层”发力前的一次重要基础建设。
五、 如何获取与使用数据集
%20拷贝.jpg)
对于开发者和研究人员而言,最关心的是如何将这一资源应用到自己的工作中。
5.1 资源访问
研究论文。详细介绍数据集构建方法、技术细节和实验结果的论文,已发布在预印本平台arXiv上,可供公开查阅。
数据集。完整的Pico-Banana-400K数据集已托管在GitHub上,研究人员可以根据指引进行下载。
5.2 许可协议
数据集采用的是非商业性研究许可(non-commercial research license)。这意味着。
允许。学术机构、非营利组织和个人研究者可以自由下载、使用该数据集进行学术研究、发表论文。
禁止。任何将该数据集直接或间接用于商业产品、服务或盈利目的的行为都是不允许的。在使用前,务必仔细阅读并遵守其许可条款。
5.3 实践指南:一个简化的训练流程
假设我们希望使用Pico-Banana-400K的单轮SFT数据,来微调一个已有的文本到图像模型(如Stable Diffusion),使其具备编辑能力。一个简化的流程如下。
python:
# 伪代码: 使用Pico-Banana-400K微调图像编辑模型
import torch
from torch.utils.data import Dataset, DataLoader
from some_diffusion_model_library import StableDiffusionEditor, load_model
# 1. 定义数据集类
class PicoBananaSFTDataset(Dataset):
def init(self, data_file, image_processor, text_processor):
# data_file 通常是一个json或csv文件,包含图像路径和指令
self.data = self.load_data(data_file)
self.image_processor = image_processor
self.text_processor = text_processor
def len(self):
return len(self.data)
def getitem(self, idx):
item = self.data[idx]
original_image = self.load_image(item['original_path'])
edited_image = self.load_image(item['edited_path'])
instruction = item['instruction']
# 预处理数据
original_tensor = self.image_processor(original_image)
edited_tensor = self.image_processor(edited_image)
instruction_ids = self.text_processor(instruction)
return {
"original_pixels": original_tensor,
"edited_pixels": edited_tensor,
"instruction_ids": instruction_ids
}
# 2. 初始化模型和数据加载器
model = load_model("path/to/pretrained/model", model_class=StableDiffusionEditor)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
dataset = PicoBananaSFTDataset("path/to/pico_banana_sft.json", ...)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# 3. 训练循环
model.train()
for epoch in range(num_epochs):
for batch in dataloader:
# 将数据移至GPU
original_pixels = batch["original_pixels"].to("cuda")
edited_pixels = batch["edited_pixels"].to("cuda")
instruction_ids = batch["instruction_ids"].to("cuda")
optimizer.zero_grad()
# 模型前向传播,计算损失
# 损失函数通常是预测的噪声与真实噪声间的L1或L2距离
loss = model.get_loss(
original_pixels=original_pixels,
edited_pixels=edited_pixels,
instruction_ids=instruction_ids
)
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item()}")
# 4. 保存模型
model.save_pretrained("path/to/finetuned_editor")
这个伪代码展示了利用该数据集进行监督微调的基本逻辑,开发者可以此为基础,构建自己的训练管线。
结论
Pico-Banana-400K的发布,是AI图像编辑领域的一个里程碑事件。它不仅仅是提供了一个“更大”的数据集,更重要的是,它提供了一个“更好”的数据集构建范式。通过**“顶尖模型生成 + 顶尖模型评估”**的自动化流水线,苹果在保证规模的同时,实现了前所未有的质量控制和多样性覆盖。
这个数据集的出现,将极大地降低研究门槛,统一评测标准,从而加速整个领域的技术创新。它为全球的AI研究者和开发者铺设了一条通往更强大、更通用、更可控的图像编辑模型的坚实道路。尽管其底层生成模型仍有局限,但Pico-Banana-400K无疑为我们窥见下一代AI图像编辑能力的曙光,提供了一扇明亮的窗口。
📢💻 【省心锐评】
苹果借谷歌之力,造福AI社区。Pico-Banana-400K不仅是数据集,更是高质量AI数据工程的范本,为图像编辑的下一站备足了燃料。

评论