.png)
%20%E6%8B%B7%E8%B4%9D-qcmk.jpg)

【摘要】本文深入剖析了检索增强生成(RAG)技术的演进与挑战,指出传统向量检索“语义相似≠答案相关”的核心矛盾。文章提出一种将向量库从“知识载体”降级为“语义路由器”,并与结构化知识库相结合的RAG新范式,旨在通过意图理解与精确查询的分离,实现更合理、精准、可追溯的答案生成,并探讨了该混合架构的实现路径、优势与工程挑战。
引言
在人工智能浪潮席卷全球的今天,检索增强生成(RAG)技术无疑是聚光灯下的明星。它如同一座桥梁,巧妙地连接了大型语言模型(LLM)强大的生成能力与海量的外部知识,有效缓解了模型知识陈旧、容易产生“幻觉”等固有顽疾。一时间,RAG被视为企业知识库、智能客服、私有数据问答等场景的“银弹”,似乎只要将文档向量化,一切问题便迎刃而解。
然而,当我们将目光从宏大的技术叙事转向崎岖的工程实践,便会发现这条路远非坦途。随着模型上下文窗口的不断扩展,以及企业知识库的日益复杂,单纯依赖向量相似度检索的传统RAG方法,其内在的局限性愈发凸显。我们常常陷入这样的困境:系统召回了大量在“语义”上看似相关的文本片段,但生成的答案却与用户的真实意图南辕北辙,甚至驴唇不对马嘴。
这引发了一个根本性的反思:我们是否从一开始就对向量库寄予了过高的期望?当语义的相似性无法保证答案的相关性时,我们是否应该重新审视其在RAG链路中的核心角色?本文将带您踏上一段从RAG的喧嚣到沉静的思辨之旅,深入剖析向量化的双刃剑效应,并大胆提出一种全新的架构范式:将向量库从无所不包的“知识载体”降级为专注而敏锐的“语义路由器”。这并非对向量技术的否定,而是一次深刻的角色重塑,旨在回归问题的本质,让AI的回答更加合理、精准,也更加值得信赖。
一、🗺️ 拨开迷雾:RAG与Agent平台的关系梳理
%20拷贝-haeo.jpg)
在深入探讨RAG的技术细节之前,我们有必要先厘清一个常见的认知误区:将RAG技术与各类Agent开发平台混为一谈。事实上,RAG是一种独立的技术范式,而Agent平台则是实现和承载这种范式的工具或框架。它们之间是“道”与“器”的关系,理解这一点,有助于我们更清晰地定位问题和选择合适的工具。
之所以会产生混淆,是因为Agent平台是许多开发者和产品经理首次接触并应用RAG的入口。这些平台极大地降低了构建复杂AI应用的门槛,而知识库问答(其核心便是RAG)则是它们最基础、最核心的功能之一。
当前市面上的主流平台,根据其定位和目标用户,大致可以分为以下几类。为了更直观地对比,我们可以将其归纳如表1所示:
表1:主流Agent平台类型与选型参考
1.1 低/零代码平台:敏捷验证的利器
代表平台:Coze、Dify
核心特点:这类平台通过可视化的拖拽界面和预置的插件,让非技术背景的用户(如产品经理、运营、HR)也能快速构建和部署AI应用。它们通常内置了完善的知识库上传、处理和检索功能,是进行快速原型验证(POC)和敏捷迭代的绝佳选择。
适用场景:当你需要快速验证一个想法,或者为某个业务部门搭建一个简单的智能问答助手时,这类平台能让你在数小时内看到成果,而无需编写一行代码。
1.2 高代码/开发者平台:深度定制的基石
代表平台:LangChain、n8n
核心特点:面向开发者,提供了一系列模块化的组件和灵活的API,允许对RAG链路的每一个环节进行深度定制和控制。无论是替换嵌入模型、调整分块策略,还是集成复杂的重排(Rerank)逻辑,开发者都拥有极高的自由度。
适用场景:当项目进入正式开发阶段,需要与企业现有的复杂业务系统(如ERP、CRM)深度集成,或者对性能、安全性有严苛要求时,高代码平台提供了必要的灵活性和可扩展性。
1.3 专注知识库问答的平台:垂直领域的专家
代表平台:FastGPT
核心特点:这类平台将所有功能都聚焦于企业知识库的构建与应用上,尤其擅长处理结构化和半结构化数据。它们通常提供了更精细的数据处理流程、权限管理和多知识库联动能力。
适用场景:专注于构建企业内部的知识中心、智能FAQ系统或需要处理大量结构化文档的场景。
综上所述,RAG是一种技术思想,而Agent平台是其落地的载体。选择哪个平台,取决于你的团队构成、项目阶段和业务复杂度。厘清了这一点,我们便可以抛开工具的表象,直抵RAG技术的核心——那条看似简单,实则暗礁丛生的数据处理链路。
二、⛓️ 环环相扣:RAG链路与向量化的双刃剑
一个标准的RAG系统,其背后是一条精密的数据处理与信息检索流水线。理解这条流水线的每一个环节,是诊断问题、优化效果的前提。
2.1 标准RAG流程:从原始数据到生成答案
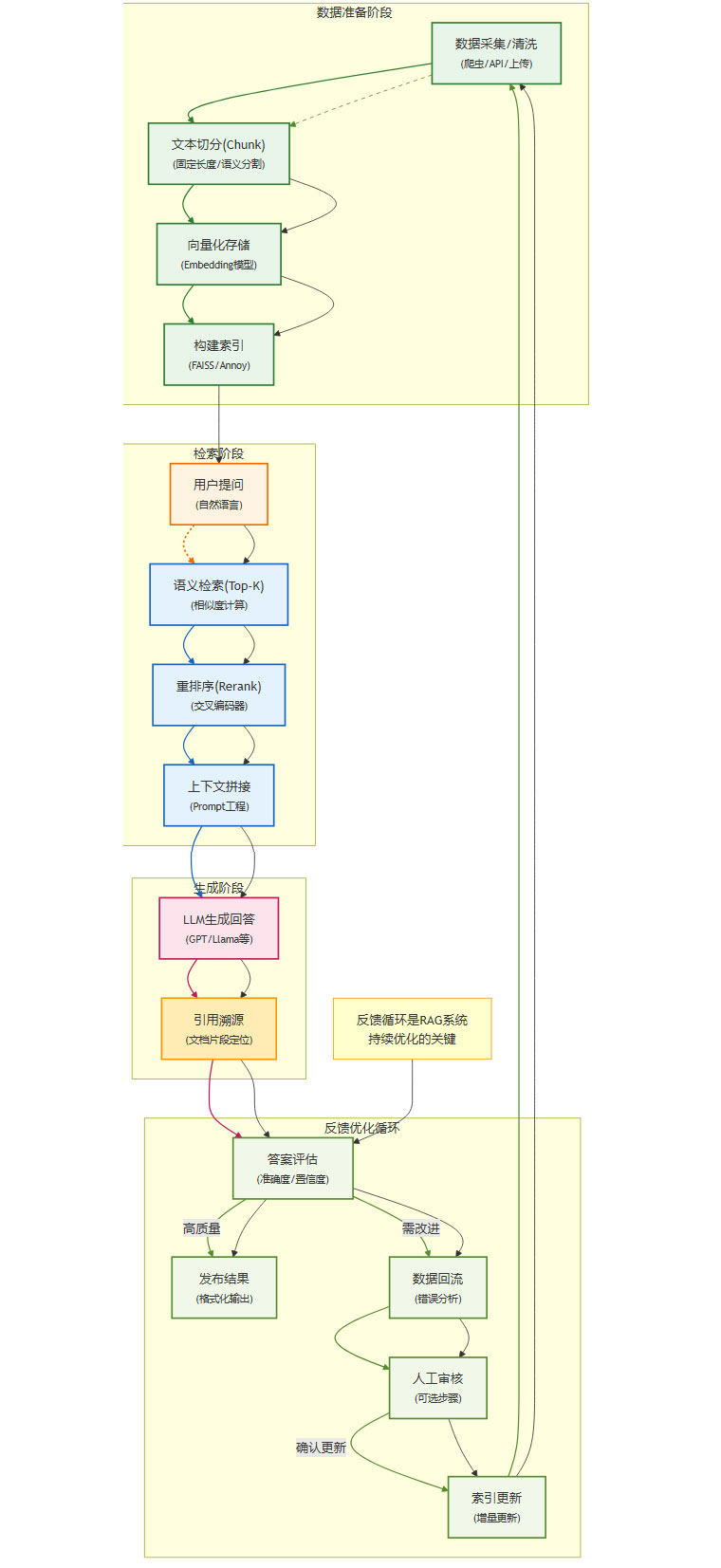
我们可以将RAG的完整生命周期解构为以下一系列步骤,它涵盖了从数据准备到最终应用的全过程。
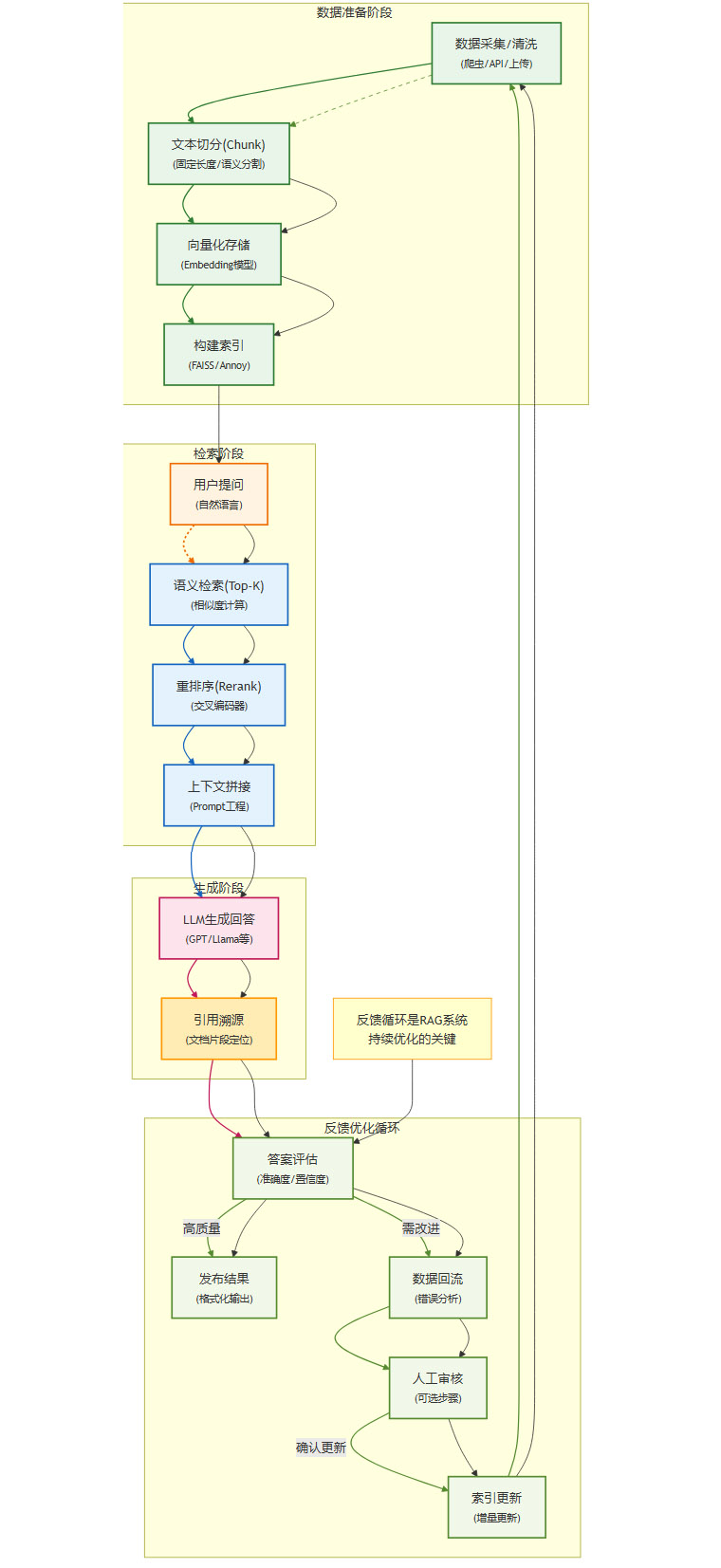
这个流程可以分为两个阶段:
离线构建:从
采集/清洗到建索引,这个阶段的目标是构建一个可供检索的知识库索引。在线检索:从
用户提问到LLM生成,这个阶段在用户发起请求时实时触发,目标是找到最相关的知识并生成答案。
在这条链路中,向量化(Vectorization)无疑扮演着心脏的角色。它负责将非结构化的文本数据转化为机器可以理解和计算的数学实体,是实现语义检索的基石。
2.2 向量化的魅力:语义检索的魔法
向量化的核心思想,是将每一个文本片段(Chunk)映射到一个高维向量空间中。在这个空间里,语义上相近的文本,其对应的向量在空间中的距离也更近。
高效的语义检索:一旦文本被向量化,我们就可以利用高效的近似最近邻(ANN)算法,在数百万甚至数十亿的向量中,毫秒级地找出与用户查询向量最相似的Top-K个结果。
强大的泛化能力:与传统的关键词匹配不同,向量化能够理解同义词、近义词和更复杂的语义关系。用户问“咖啡怎么提神”,系统能够召回包含“咖啡因能刺激中枢神经”的段落,即使两者没有共享任何关键词。
良好的可扩展性:现代向量数据库(如Milvus, Pinecone)被设计为分布式系统,能够水平扩展以支持海量数据的存储和检索。
正是这些优势,让向量化成为了RAG技术的首选方案,开启了非结构化数据检索的新纪元。然而,当我们沉浸在这份“魔法”带来的便利中时,其背后隐藏的“诅咒”也开始悄然显现。
2.3 向量化的诅咒:“语义相似”不等于“答案相关”
所有问题的根源,都指向一个深刻而难以回避的矛盾:向量模型优化的目标是语义相似性,而RAG应用追求的目标是答案的精准相关性,这两者并非总是一致的。这个核心矛盾,如同一道幽灵,贯穿于RAG实践的始终,并衍生出了一系列具体的挑战。
上下文污染:这是最常见的问题。召回的文本片段虽然在主题上与查询相关,但可能包含了错误、过时或无关的信息,这些“污染物”会严重误导LLM的生成过程。
关键信息丢失:向量化是一个有损压缩的过程。一个高维向量无法百分之百地捕捉原始文本中所有的细节、逻辑和上下文关系。特别是对于需要精确匹配的数字、代码、法规条文等,向量检索往往力不从心。
结构化数据处理乏力:面对表格、JSON或任何具有内在结构的数据,强行将其“拍平”成文本再进行向量化,会破坏其原有的结构信息,导致无法进行有效的查询。比如,你无法可靠地通过向量检索来回答“第二季度销售额最高的产品是什么?”这类问题。
对数据质量的极端敏感:向量化的效果高度依赖于输入数据的质量。如果原始文档未经清洗,包含了大量的页眉、页脚、广告、URL等噪声,这些噪声也会被编码进向量,严重干扰检索的准确性。
2.4 两个案例:从咖啡配方到医疗诊断
让我们通过两个具体的案例,来感受向量化这把双刃剑的锋利。
2.4.1 失败的咖啡配方案例
一位初级开发者接到一个任务:构建一个能回答咖啡知识的智能助手。他拿到一份PDF文档,图省事,未做任何清洗,直接按固定长度切块并向量化。
当用户提问:“标准拿铁咖啡的配方是什么?需要多少毫升牛奶?”
系统发生了什么?
召回:向量检索模块忠实地召回了几个与“拿铁”、“咖啡”、“牛奶”语义最相似的片段。
片段一:来自文档的引言部分,讲述拿铁咖啡的历史起源。
片段二:来自某个章节,解释“Caffè latte”在意大利语中的含义。
片段三:一个不完整的步骤描述,提到了“取200ml牛奶加热”,但缺少咖啡粉用量和完整的制作流程。
生成:这些被污染的、不完整的片段被一股脑地塞给了LLM。模型尽其所能地在这些碎片化的信息中寻找答案,最终“编造”出一个看似合理但完全错误的配方,甚至可能引用了历史故事来凑数。
症结所在:问题不在于向量检索“错了”,它恰恰是“对”的——它精确地找到了语义最相似的片段。问题在于,这些语义相似的片段,并不能为回答用户的问题提供直接、准确的支持。只有经过精细清洗和结构化处理,将配方信息提炼成一个干净、独立的知识单元,才能保证召回的精准性。
2.4.2 高风险的医疗问诊案例
想象一个更严肃的场景:一个基于RAG的医疗自诊助手。
用户输入:“我最近总是心口疼,特别是饭后躺下的时候。”
传统RAG系统可能会:
召回:“心口疼”这个强信号,会使向量检索高度倾向于召回与“心脏病”、“心肌梗死”相关的权威文档,比如《心肌梗死护理指南》。因为这些文档在语义上与“心口疼”高度相关。
生成:LLM基于这些召回的片段,可能会生成一个非常吓人的答案,建议用户警惕心脏病风险,并立即就医。
然而,结合“饭后躺下加重”这个关键的上下文信息,经验丰富的医生可能会首先怀疑是胃食管反流。这是一个完全不同的病症,其相关的知识文档在向量空间中,可能与“心口疼”的查询向量距离更远。
症结所在:传统向量检索缺乏对多维特征和复杂逻辑的推理能力。它只能抓住最表层的语义相似性,却无法像专家一样,结合多个看似不相关的线索进行综合判断。这再次证明,单纯依赖向量相似度,在需要深度推理和精确诊断的领域是极其危险的。
三、💡 范式革命:从“知识载体”到“语义路由”
%20拷贝-ctsp.jpg)
面对向量化的内在困境,我们不禁要问:出路在何方?
一个有趣的观察是,随着LLM的上下文窗口从几千Token扩展到百万级别,一种看似“返璞归真”的思路开始出现:如果知识库不大,我为什么不直接把所有清洗后的文本都塞给模型呢?这样不就完全绕开了向量检索的不确定性吗?
这个想法虽然在成本和效率上不切实际,但它却给了我们一个重要的启示:也许我们从一开始就用错了向量库。我们不应该强迫它去承载它无法完美承载的“知识”本身,而应该让它回归到它最擅长的事情上——理解语义。
这便是我们提出的新范式:将向量库从“知识载体”降级为“语义路由器”,并与一个高确定性的结构化知识库相结合,形成一种混合架构。
3.1 架构核心思想:分工与协作
在这个新的架构中,系统的两大核心组件将进行明确的分工:
向量库 (语义路由器)
角色:不再是知识的最终来源。它的唯一任务是理解用户用自然语言提出的模糊查询,并将其精准地“路由”到一个或多个预先定义好的、结构化的概念、类别或索引键上。
能力:它负责回答“用户在问什么领域/主题/意图?”这个问题。例如,将“饭后心口灼烧样疼”映射到
[症状:胸痛, 诱因:体位, 时间:饭后]这样的结构化标签上。
结构化知识库 (知识载体)
角色:知识的最终、权威来源。它存储着经过精心组织、清洗、关联的领域知识。
形式:可以是知识图谱、关系型数据库、文档数据库(带有丰富的元数据),甚至是规则库。
能力:它不直接处理自然语言,而是基于从“语义路由器”传来的精确键(Key)进行高效、准确的查询。它负责回答“关于这个精确的问题,答案是什么?”。
这种分工,本质上是将不确定性的语义理解任务,与确定性的知识查询任务分离开来。向量库负责处理前者,结构化知识库负责处理后者。
3.2 新架构下的工作流程
让我们用新的架构重新审视之前的医疗诊断案例:
在这个流程中:
语义路由层不再是单一的向量检索,而是多信号融合的决策中心。它会综合利用向量相似度、关键词提取、实体识别甚至轻量级规则,共同理解用户意图。
路由的结果不是一堆文本片段,而是一个结构化的查询指令。
知识载体层(这里是知识图谱)执行这个精确的指令,通过实体和关系的遍历,进行逻辑推理,最终锁定最可能的病症。
生成层拿到的是结构化的、高确定性的查询结果,它的任务只是将其“翻译”成通顺、易懂的自然语言,并附上清晰的引证来源。
3.3 架构的显著优势
这种混合架构,完美地解决了传统RAG的诸多痛点:
解决了语义与相关性的核心矛盾:路由层确保了意图的精准对齐,知识查询层确保了信息的准确无误。从根本上杜绝了“上下文污染”的问题。
更贴近人类的认知模式:这套流程非常像人类专家的思考方式——先听懂问题(路由),然后在大脑中结构化的知识体系里检索、推理,最后组织语言作答。
强大的灵活性与可扩展性:结构化知识库可以容纳多种数据类型,如事实表、规则集、API接口等。可以根据业务需求,灵活地为不同类型的查询路由到最合适的知识载体。
天然的可解释性与可追溯性:由于最终答案来源于结构化的查询,其推理路径清晰可见,每一份信息都有源可溯,这在金融、法律、医疗等高风险领域至关重要。
3.4 不容忽视的工程挑战
当然,天下没有免费的午餐。这套架构在带来巨大优势的同时,也对工程实现提出了更高的要求:
结构化知识库的构建成本高昂:设计和构建一个高质量的知识图谱或领域数据库,是一项复杂的系统工程。它需要领域专家的深度参与,以及在数据清洗、实体关系建模、知识更新维护等方面持续投入大量资源。
路由与知识库的协同设计:如何定义路由的目标(即结构化知识库的查询接口),如何设计高效的路由策略,如何让两者无缝衔接,是整个系统设计的核心难点。
对团队能力的要求更高:团队不仅需要具备LLM和向量技术的知识,还需要掌握数据工程、知识图谱、数据库设计等多方面的技能。
四、🛠️ 落地实践:平台选型与实施建议
%20拷贝-kehv.jpg)
理论的先进性最终要通过实践来检验。在理解了“语义路由”这一新范式后,如何选择合适的工具将其落地,便成为下一个关键问题。结合业务场景、团队能力和项目阶段,我们可以制定出务实的选型策略。
4.1 快速POC/原型
当项目处于探索阶段,或需要快速向业务方展示一个可交互的原型时,效率是第一位的。此时,应优先选用Coze、Dify等低/零代码平台。它们极大地降低了技术门槛,让非技术用户和小团队也能在短时间内搭建起功能完备的RAG应用,从而快速验证业务场景和原型设计。
4.2 复杂业务系统/深度定制
当项目通过验证,进入正式的企业级应用开发阶段,灵活性和可扩展性便成为核心诉求。此时,推荐n8n、LangChain等高代码平台。它们为开发者提供了丰富的工具集和高度的自由度,适合需要与现有系统进行深度集成、实现复杂业务逻辑或对性能有特殊要求的场景。
4.3 知识库问答/结构化场景
对于那些以高精度知识问答为核心,特别是涉及大量结构化数据的场景,我们需要更专业的解决方案。此时,可以考虑结合FastGPT、RagFlow等专注知识库的工具,它们在处理结构化数据和保证答案精准性方面有更深厚的积累。更进一步,对于追求极致性能和可靠性的核心业务,自建“语义路由+结构化知识库”的混合架构将是最终的理想选择,以满足高精度、可追溯的知识问答需求。
为了帮助您根据具体需求快速决策,下表提供了一个清晰的选型对比:
表2:不同需求场景下的平台选型策略
结论
我们正处在RAG技术从“野蛮生长”到“精耕细作”的转折点。单纯依赖向量相似度的“一把梭”模式,其红利正在逐渐消退。实践反复证明,RAG的本质,是一场围绕“数据工程”的持久战,其上限不由模型决定,而由我们对知识的理解、组织和运用能力决定。
将向量库从神坛上请下,让它回归“语义理解”的本职,成为一个敏锐的“路由器”;同时,投入真正的精力去构建和维护一个高质量的、可信的结构化知识库。这种“模糊理解”与“精确查询”相结合的混合范式,虽然在工程上更具挑战,但它直面了“语义相似≠答案相关”这一核心矛盾,为我们构建更智能、更可靠、更负责任的AI应用,指明了一条清晰而坚实的道路。
这不仅是一次技术架构的升级,更是一次思想的转变——从迷信单一技术的“魔法”,转向尊重领域知识、拥抱系统工程的“匠心”。而这,或许才是通往真正通用人工智能的必经之路。
📢💻 【省心锐评】
抛弃对向量检索的盲目崇拜吧。RAG的未来,在于将“语义理解”的模糊性与“结构化查询”的确定性优雅结合。这考验的不是算法,而是数据工程的智慧与耐心。

评论