.png)
.png)

【摘要】本文系统梳理了DeepSeek大模型在提示词工程与幻觉规避领域的最新实践,深入探讨推理型与非推理型模型的提示词设计策略、幻觉成因、检测与缓解技术,并结合行业案例与未来趋势,全面展现AI可信应用的技术路径与挑战。
引言
随着大语言模型(LLM)在各行各业的广泛应用,如何高效设计提示词(Prompt Engineering)并有效规避“幻觉”(Hallucination)问题,成为AI落地的核心挑战。DeepSeek等新一代大模型在推理能力、知识覆盖和生成质量上不断突破,但其输出的可靠性、可控性和可解释性,依然受到提示词设计和幻觉问题的深刻影响。本文将以技术论坛深度文章的标准,系统梳理推理型与非推理型模型的提示词工程、幻觉成因与检测、规避技术、行业实践与未来趋势,力求为AI开发者、产品经理和研究者提供一份兼具深度与广度的实战指南。
一、🧩 推理型与非推理型模型的提示词设计

1.1 模型特性与适用场景
1.1.1 推理型模型
推理型大模型(如DeepSeek-R1、GPT-4 O1等)具备多步推理和“思维链”(Chain-of-Thought, CoT)能力,能够自动拆解复杂问题,输出带有推理过程的答案。这类模型适用于:
复杂逻辑推理
数学与科学计算
编程与代码生成
决策分析与流程规划
推理型模型在处理上述任务时,能够通过结构化提示词引导其逻辑路径。例如,提示词可要求“分步骤说明解题过程”,模型会自动生成推理链条,提升答案的可解释性和准确性。
1.1.2 非推理型模型
非推理型模型(如DeepSeek-V3、传统GPT-3.5等)响应速度快,适合常规文本生成、摘要、翻译、闲聊、创意生成等标准化或多样性任务。这类模型的提示词设计应简洁明确,注重结果导向,避免复杂的推理链条。
1.2 提示词设计核心原则
1.2.1 推理型模型的提示词设计
简洁明了:直接描述核心问题,避免冗余和过度分步引导,信任模型的自主推理能力。
结构化分隔:利用Markdown、分隔符(如“---”或“##”)区分任务模块,防止指令冲突。
背景信息充分:采用“六何分析法”(5W1H:Who、What、When、Where、Why、How)明确任务目标、时间、角色等要素。
输出格式明确:指定输出格式、长度、风格,减少后续修改。
思维链强化:通过示例(Few-shot)展示解题步骤,提升推理链条的清晰度。
适度延长推理时间:如“请充分思考”,提升准确性。
1.2.2 非推理型模型的提示词设计
结构化引导:通过分步提示、示例、角色设定等方式补偿推理能力短板。
分步拆解复杂任务:将复杂任务拆解为多个子任务,逐步引导模型完成。
示例驱动:适当提供高质量示例,帮助模型理解任务要求,但避免过多以防过拟合。
模糊容忍度:允许结果多样性,如“生成3种不同风格的标题”。
快速响应优化:限制输出长度以提升效率。
明确上下文与目标:提供足够背景信息,明确任务目标和输出要求。
1.2.3 通用提示词设计要点
明确目标,避免模糊表达。
提供必要上下文,减少歧义。
设定输出格式和风格。
反馈与迭代优化,持续调优提示词。
高质量提示词与高质量用户输入同等重要。
1.2.4 误区规避
复杂提示词未必更好,简洁聚焦为主。
不同模型需定制化提示词。
用户输入质量同样关键。
1.3 提示词设计流程图
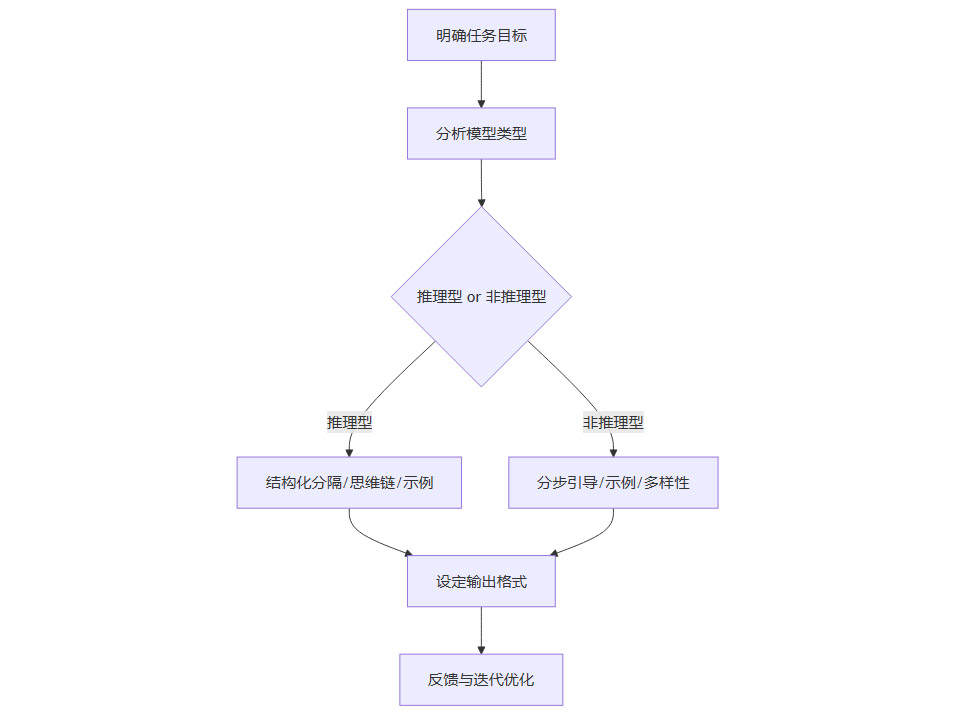
1.4 行业实践案例
医疗场景:结构化提示模板,要求标注推荐级别、剂量调整依据等,若输出有争议自动触发知识库检索。
企业知识管理:如腾讯云HAI平台结合DeepSeek+RAG,显著降低幻觉风险。
跨模型协作系统:如Manus智能体,通过任务拆解、多轮校验和工具调用(如Wolfram Alpha)减少幻觉。
二、🔍 幻觉问题的成因、类型与解决方案
2.1 幻觉类型与成因
2.1.1 幻觉类型
事实性幻觉:输出内容与客观事实不符(如虚构数据、错误引用)。
忠实性幻觉:输出偏离用户指令或上下文(如虚构未提及的数据)。
逻辑性幻觉:推理过程自相矛盾、因果倒置。
语境性幻觉:脱离输入语境的错误延伸。
认知性幻觉:对常识的严重偏离。
2.1.2 幻觉成因
数据层面:训练数据覆盖不全、包含噪声或过时信息。
模型架构与训练:自回归生成机制导致错误累积,采样策略(高温度、top-k)增加随机性,预训练与微调知识不一致。
推理阶段:长文本生成时关注局部,易遗忘全局上下文。
评估与对齐机制:缺乏真实性校验,RLHF等对齐方法难以覆盖所有场景,模型有时更倾向于“取悦”用户。
2.2 幻觉检测与评估
2.2.1 检测方法
一致性检测:多次生成同一问题答案,检查一致性与事实吻合度。
事实核查:结合知识库(如RAG)、外部工具、事实核查API自动验证内容。
置信度标注:要求模型输出置信度评分,提示用户核实关键信息。
多模型交叉验证:不同模型对同一问题输出结果,取多数一致答案。
人工溯源核查:对关键数据要求标注来源链接。
2.2.2 检测流程表
2.3 幻觉规避与缓解实战
2.3.1 用户层应对策略
提示词约束:限定信息源与时间范围(如“基于2023版指南回答”),要求置信度标注。
多模型交叉比对:同步向不同模型提问并对比核心事实。
多轮对话与追问:通过多轮交互揭示潜在错误,动态修正答案。
批判性思维与人工审核:关键场景(如医疗、法律)需人工复核。
2.3.2 开发层技术优化
检索增强生成(RAG):结合外部知识库实时检索,显著降低幻觉率,适用于知识密集型场景。
高质量数据微调:用权威、最新、领域专有数据微调模型。
对抗训练与事实一致性约束:在损失函数中引入知识验证项。
解码策略优化:降低温度、限制采样范围,减少随机性。
链式验证(CoVe)与自我修正:模型先生成初步答案,再自动生成验证问题并自查修正。
后处理验证系统:自动进行事实核查、实体抽取、矛盾检测与修正。
参数调优与惩罚项:通过调整温度参数、增加惩罚项抑制虚构内容。
2.3.3 行业实践案例
医疗场景:结构化提示模板,要求标注推荐级别、剂量调整依据等,若输出有争议自动触发知识库检索。
企业知识管理:如腾讯云HAI平台结合DeepSeek+RAG,显著降低幻觉风险。
跨模型协作系统:如Manus智能体,通过任务拆解、多轮校验和工具调用(如Wolfram Alpha)减少幻觉。
2.4 幻觉规避技术流程图
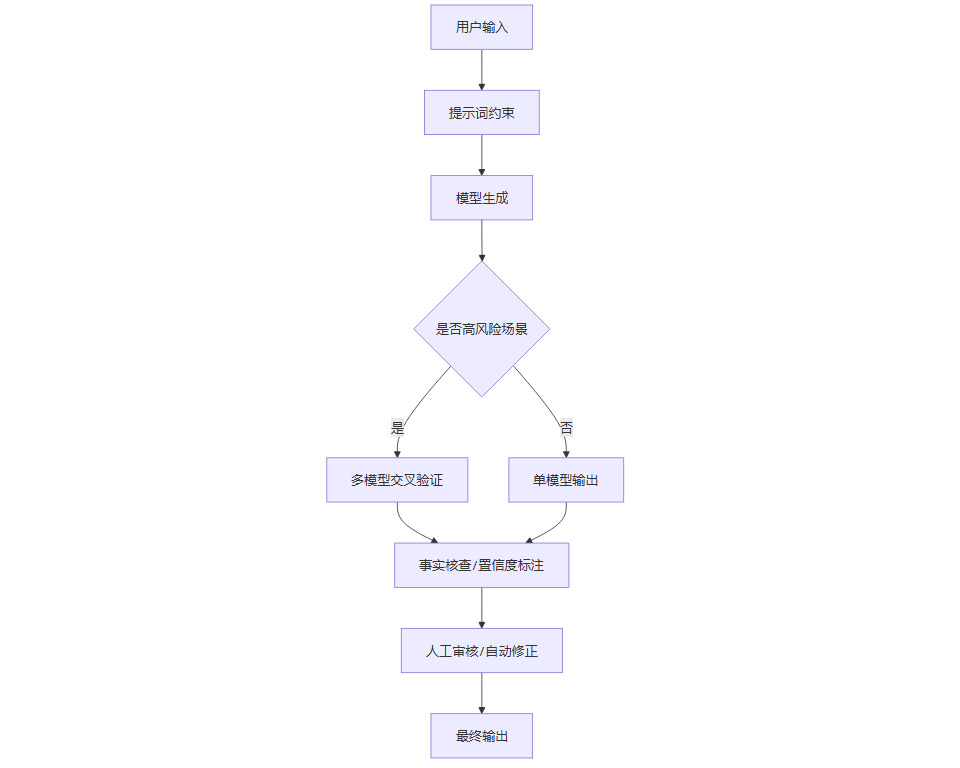
三、🚀 未来挑战与趋势

3.1 神经符号系统结合
将符号逻辑规则嵌入模型推理过程,提升事实一致性和可解释性。神经符号系统通过结合符号推理与神经网络的强大表达能力,为AI模型带来更强的逻辑约束和知识可控性。
3.2 动态幻觉检测
实时监控生成内容的逻辑矛盾,触发自修正机制。通过动态检测和反馈,模型能够在生成过程中及时发现并修正潜在幻觉,提升输出的可靠性。
3.3 多模态幻觉规避
如OPERA等新型解码方法,通过注意力惩罚与回退机制缓解多模态幻觉。多模态模型在处理文本、图像、音频等多种数据时,幻觉问题更为复杂,需要更精细的解码与校验机制。
3.4 伦理与合规
随着欧盟《AI法案》等法规的推进,高风险系统将被强制要求配备幻觉校正模块,未来AI输出需标注溯源信息,提升透明度和可追溯性。
3.5 提示词工程持续优化
结合自动化提示词生成与人工调优,基于用户反馈持续优化提示词设计,提升模型适应性和用户体验。
3.6 行业应用的深度与广度
3.6.1 医疗健康领域
在医疗健康领域,AI大模型的应用对提示词工程和幻觉规避提出了极高要求。医生和医疗决策者依赖AI辅助诊断、用药建议、病例分析等,任何事实性幻觉都可能带来严重后果。行业实践中,常见的做法包括:
结构化提示模板:要求模型输出时必须包含诊断依据、推荐级别、参考文献等结构化信息,便于后续人工审核和溯源。
知识库联动:模型输出如遇到罕见疾病、最新药物等高风险内容,自动触发知识库检索,确保答案基于权威数据。
置信度与风险提示:模型需对每条建议标注置信度,并在置信度低于阈值时自动提示用户核查。
3.6.2 金融与法律领域
金融和法律行业对AI输出的准确性、合规性要求极高。幻觉一旦出现,可能导致合规风险、经济损失甚至法律责任。行业内的应对措施包括:
多模型交叉验证:对同一法律条文、金融数据,采用多模型并行生成,取交集或多数一致答案,降低单一模型幻觉风险。
事实核查API集成:与权威法律数据库、金融数据API集成,自动校验模型输出的条文、数据、案例等内容。
输出溯源与责任链:每一条AI建议都需标注数据来源、生成时间、模型版本,便于后续责任追溯和合规审计。
3.6.3 教育与科研领域
教育和科研领域对AI的创造力和准确性有双重需求。提示词工程需兼顾启发性与事实性,幻觉规避则侧重于知识准确性和逻辑一致性。
分步推理与思维链强化:在解题、论文写作等场景,提示词要求模型分步推理,输出推理链,便于学生和研究者理解和复查。
多轮追问与自我修正:通过多轮对话,逐步揭示模型潜在错误,鼓励用户对AI输出进行批判性思考。
自动化事实核查工具:集成学术数据库、文献检索工具,对模型输出的学术观点、数据进行自动核查。
3.6.4 企业知识管理与智能客服
企业知识管理和智能客服场景下,AI模型需在保证效率的同时,最大限度降低幻觉风险,提升用户满意度。
RAG检索增强生成:结合企业内部知识库,实时检索并生成答案,确保输出内容权威、最新。
多轮对话与上下文保持:通过多轮对话保持上下文一致性,减少因上下文丢失导致的幻觉。
自动化工单分流与人工兜底:对高风险、复杂问题自动分流至人工客服,AI仅处理标准化、低风险问题。
3.6.5 智能创作与内容生成
在新闻、广告、文学创作等内容生成领域,AI的创造力与事实性需平衡。提示词设计需明确创作风格、事实边界,幻觉规避则侧重于防止虚假信息传播。
风格与事实分离:通过提示词明确哪些内容可自由创作,哪些必须基于事实,防止模型“自由发挥”时混淆事实与虚构。
事实核查与内容标注:对涉及事实的数据、事件自动标注来源,便于后续核查和内容合规。
3.7 提示词工程与幻觉规避的协同演进
3.7.1 提示词工程的自动化与智能化
随着AI技术进步,提示词工程正从“手工调优”向“自动化生成”演进。未来,基于用户历史输入、任务类型、模型反馈,系统可自动生成最优提示词,极大提升开发效率和模型适应性。
提示词生成器:基于任务描述和历史数据,自动推荐或生成高质量提示词。
自适应提示词优化:模型根据用户反馈自动调整提示词结构和内容,实现持续优化。
多语言与多模态支持:提示词工程将支持多语言、多模态输入,适应全球化和多元化应用需求。
3.7.2 幻觉规避的全链路集成
幻觉规避不再是单一环节的“补丁”,而是贯穿数据、模型、推理、输出全链路的系统工程。
数据层面:持续清洗、更新训练数据,剔除噪声和过时信息,提升模型知识基础。
模型层面:引入知识约束、对抗训练、符号逻辑等机制,提升模型事实一致性。
推理层面:动态监控推理过程,实时检测并修正逻辑矛盾和事实偏差。
输出层面:集成事实核查、置信度标注、人工审核等多重保障,确保最终输出可信。
3.7.3 技术与伦理的双重挑战
随着AI模型能力提升,幻觉问题的技术挑战与伦理挑战同步加剧。未来,AI系统需在提升创造力与保障事实性之间找到平衡点,既能激发创新,又能防止虚假信息扩散。
合规与透明:AI输出需标注数据来源、生成机制、置信度等信息,提升透明度和可追溯性。
用户教育与引导:加强用户对AI幻觉风险的认知,鼓励批判性思维和多源核查。
行业标准与法规:推动行业标准和法规建设,明确AI幻觉规避的技术要求和合规底线。
3.8 未来展望:AI助手的可信进化
未来,随着神经符号系统、多模态解码、自动化提示词工程和合规要求的不断推进,AI助手将从“工具”向“可信助手”演进。AI不仅能高效完成任务,更能主动提示风险、标注来源、解释推理过程,成为人类知识与决策的有力伙伴。
可信推理链:每一步推理均可追溯、可解释,用户可随时复查模型的思考过程。
动态知识更新:模型可实时接入最新知识库,自动更新知识体系,减少因知识过时导致的幻觉。
多模态协同:文本、图像、音频等多模态信息协同处理,提升AI助手的综合能力和应用广度。
合规与伦理保障:AI系统内置合规校验和伦理约束,确保输出内容安全、合法、可信。
结论
DeepSeek等大模型的提示词工程与幻觉规避,是AI可信落地的核心环节。只有深入理解模型类型,精细设计提示词,结合多层次的幻觉检测与规避机制,并持续反馈迭代,才能真正释放大模型的生产力,保障其在各行业的安全与可靠应用。未来,随着神经符号系统、多模态解码和合规要求的推进,AI助手将从“工具”向“可信助手”演进,成为人类知识与决策的有力伙伴。
💬 【省心锐评】
“提示词与幻觉规避,决定AI能否成为真正的生产力工具,值得每一位开发者深挖。”

评论