.png)


【摘要】RAG通过“先检索、后生成”的工程化闭环,为大模型接入外部知识库作为事实锚点,有效抑制幻觉,实现知识的动态更新与答案的精准可溯源。
引言
大语言模型(LLM)在商业化落地中,幻觉问题始终是绕不开的障碍。模型基于其庞大的训练数据,以概率方式生成文本,这导致其输出在逻辑上看似连贯,却可能与事实相悖或凭空捏造。同时,模型的知识被固化在训练截止日期,无法感知实时信息,这在许多动态场景下是致命的。
检索增强生成(Retrieval-Augmented Generation, RAG)是当前解决上述问题的核心工程范式。它并非试图改变模型本身,而是为其外挂一个动态、可控的“事实引擎”。通过在生成答案前,先从外部知识库中精准检索相关信息,RAG将模型的生成过程从“无据猜测”转变为“有据可依”的推理。
这套方法论不仅显著提升了答案的准确性与时效性,也为系统的可解释性与用户信任度提供了坚实基础。本文将从RAG的价值定位、底层机理、系统全流程、工程挑战、落地实践到前沿演进,进行一次体系化的深度拆解。
一、🎯 RAG的价值定位:从概率生成到事实驱动
%20拷贝.jpg)
1.1 大语言模型的内在局限
理解RAG的必要性,首先要看清LLM自身无法回避的两个核心局限。
1.1.1 概率式生成的“幻觉”原罪
LLM的本质是一个概率分布模型。它在生成下一个词元(token)时,是基于上文预测可能性最高的选项,而非进行事实核查。这种机制使其擅长模仿人类的语言风格与逻辑结构,但也注定了它会“一本正经地胡说八道”。当模型内部知识库中不存在或信息模糊时,它会倾向于编造一个概率上最“合理”的答案,这就是幻觉的根源。1.1.2 静态知识的“时效性”枷锁
训练一个千亿级参数的LLM成本极高,周期漫长。这导致模型的知识存在一个明确的截止日期。对于需要实时信息的应用,如新闻问答、金融分析、产品支持等,静态的LLM无法满足需求。传统的微调(Finetuning)方案虽能注入新知识,但成本高、周期长,且可能引发“灾难性遗忘”,并非理想的动态更新手段。
1.2 RAG的核心解法:检索增强范式
RAG通过引入一个外部知识库,从根本上改变了LLM的工作流,其核心价值体现在以下几个方面。
1.2.1 将“黑盒”推理变为“白盒”溯源
传统的LLM如同一个知识黑盒,用户无法知晓其答案的来源。RAG将知识源外置,每一次回答都基于从知识库中检索出的明确片段。系统可以将这些片段作为引用来源附在答案后,用户可以自行核验,极大增强了系统的可解释性与用户信任。1.2.2 实现“模型不变,知识常新”
RAG架构将LLM的推理能力与外部知识库解耦。知识的更新不再依赖于成本高昂的模型重训或微调。只需要更新外部知识库中的文档,系统就能即时获取最新信息。这种低成本、高效率的知识更新机制,是RAG在企业级应用中备受青睐的关键。1.2.3 降低幻觉,提升领域专注度
通过在提示(Prompt)中注入强相关的、可信的上下文信息,RAG为模型的生成过程提供了明确的“锚点”。模型被引导基于这些证据进行回答,而不是自由发挥,从而显著抑制了幻觉的产生。同时,通过构建特定领域的专业知识库,RAG可以快速让一个通用大模型变成特定领域的“专家”,适配性极强。
二、⚙️ 底层机理:Embedding与向量检索
RAG系统的“事实引擎”能够运转,依赖于两大核心技术,Embedding模型与向量数据库。它们共同构成了语义检索的基石。
2.1 Embedding模型:语义的数学表达
要让计算机理解并检索文本,首先需要将非结构化的文本转化为可计算的数学形式。Embedding模型正是承担这一任务的关键组件。
2.1.1 核心功能
Embedding模型接收任意长度的文本作为输入,输出一个固定长度的高维向量(Vector)。这个向量可以被看作是输入文本在语义空间中的数学坐标。例如,OpenAI的text-embedding-ada-002模型会输出1536维的向量,而社区流行的BGE、E5等模型则常使用768或1024维。2.1.2 关键特性
一个优秀的Embedding模型必须具备语义相似性。即语义上相近的文本,无论其表述方式如何,转换后的向量在空间中的距离也应该相近。反之,语义无关的文本,其向量距离则会很远。
例如,“如何定义C语言的整型变量?”和“C language integer variable declaration”这两句话,虽然用词和语言都不同,但它们的向量会非常接近。这种特性使得机器能够超越关键词匹配,实现真正的语义理解与检索。
2.2 向量数据库:高维空间的“语义索引”
当所有文档片段都被转换为向量后,我们需要一个能够高效存储并检索这些高维数据的系统。这就是向量数据库(Vector Database)的作用。
2.2.1 为何需要专用数据库
传统的数据库(如MySQL)基于精确匹配或范围查询设计,无法高效处理高维向量的相似度计算。在数百万甚至数十亿的向量中进行暴力比对,计算成本是天文数字。2.2.2 核心技术:近似最近邻(ANN)
向量数据库的核心是近似最近邻(Approximate Nearest Neighbor, ANN)算法。它通过构建特殊的数据结构(索引),牺牲极小的精度来换取检索速度的巨大提升。常见的ANN索引算法包括。基于树的方法(如Annoy):将空间递归地划分为子空间。
基于图的方法(如HNSW):构建一个多层的邻近图,从顶层稀疏图开始导航,逐层逼近查询目标。HNSW是目前性能最好、应用最广的算法之一。
基于哈希的方法(如LSH):用哈希函数将相似的向量映射到同一个桶中。
基于量化的方法(如IVF-PQ):先用聚类将向量空间划分为多个区域(IVF),再对每个向量进行压缩(PQ)。
2.2.3 主流产品选型
市面上有多种向量数据库可供选择,它们在部署方式、性能、功能和生态上各有侧重。
三、🛠️ RAG系统全流程解构
%20拷贝.jpg)
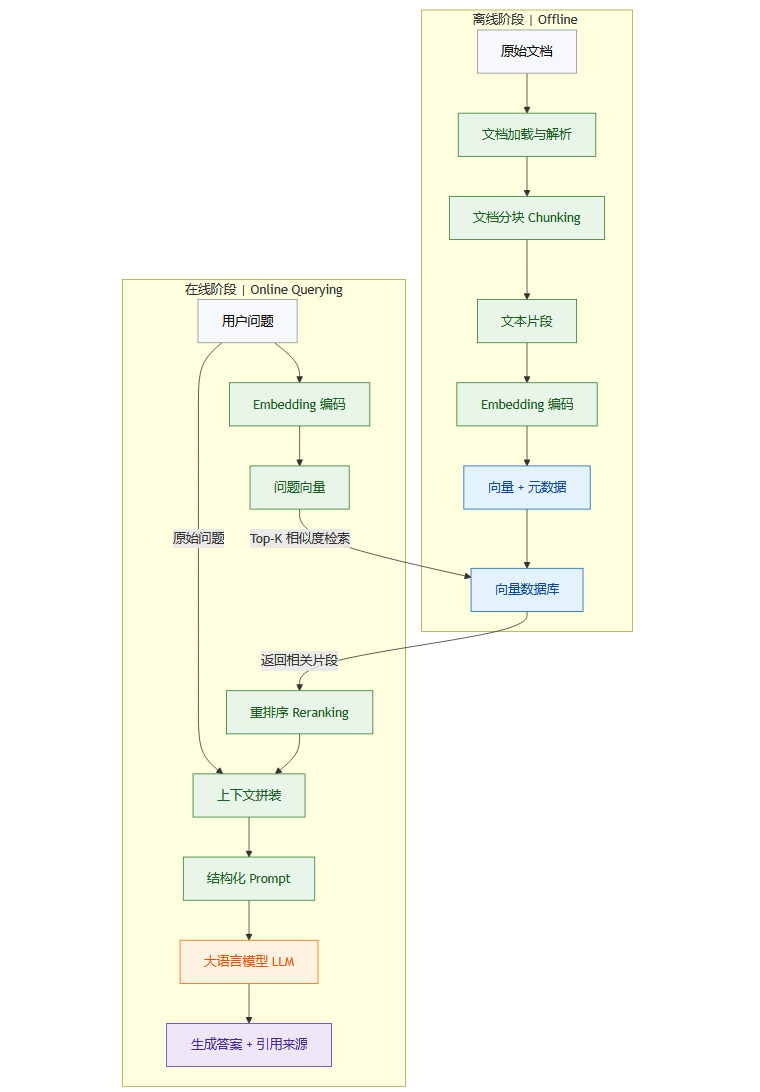
一个完整的RAG系统通常包含两个阶段,离线的知识库构建与在线的实时查询生成。
3.1 离线阶段:知识库的构建与索引
这个阶段是一次性的预处理工作,目标是将原始文档转化为可供快速检索的向量索引。
3.1.1 文档加载与解析(Loading & Parsing)
首先,系统需要从不同的数据源(如PDF、HTML、Markdown、数据库)加载原始文档。然后,对文档内容进行解析,提取纯文本,并保留必要的元数据(如来源、标题、章节、发布日期)。3.1.2 文档分块(Chunking)
由于LLM的上下文窗口有限,且为了实现更精准的检索,长文档必须被切分成更小的片段(Chunk)。分块策略是RAG系统性能的关键之一,直接影响检索质量。固定大小分块:按固定字符数或词元数切分,简单粗暴,但容易切断语义完整的句子或段落。
递归字符分块:按一组分隔符(如
\n\n,\n, )递归切分,试图在段落、句子等自然边界上分割,是目前较通用的策略。语义分块:利用语言模型或特定算法,根据语义的连贯性来决定切分点。例如,计算相邻句子间的Embedding余弦相似度,在相似度突变的地方进行切分。这种方法效果更好,但计算成本更高。
结构化分块:针对Markdown或HTML等半结构化文档,可以依据标题层级(H1, H2...)进行分块,能更好地保留文档的层次结构。
3.1.3 Embedding编码与存储
对每个分块后的文本片段,调用选定的Embedding模型将其转换为向量。随后,将“文本片段、向量、元数据”三元组存入向量数据库。数据库会基于这些向量构建ANN索引,以备后续查询。
3.2 在线阶段:实时检索与生成
当用户发起查询时,系统会实时执行以下流程。
3.2.1 问题向量化(Query Vectorization)
使用与离线阶段完全相同的Embedding模型,将用户的查询问题也转换为一个向量。3.2.2 相似度检索(Retrieval)
将问题向量提交给向量数据库,执行相似度搜索。数据库会返回与问题向量“距离”最近的Top-K个文本片段及其元数据。这里的“距离”通常使用余弦相似度或欧氏距离来衡量。3.2.3 上下文拼装与重排(Context Assembly & Reranking)
检索到的Top-K个片段是候选上下文。为了提升最终效果,通常会增加一个**重排(Reranking)**步骤。重排器(通常是一个小型的交叉编码器模型)会对“问题”和每个“候选片段”进行打分,选出真正最相关的片段。
随后,将筛选后的片段与原始问题一起,按照预设的模板拼装成一个结构化的Prompt。这个Prompt会明确指示LLM,要求它仅基于提供的上下文来回答问题。3.2.4 答案生成与溯源(Generation & Citation)
最后,将构建好的Prompt提交给LLM。LLM会基于给定的上下文信息,生成一个自然、流畅且忠于事实的答案。同时,系统可以从上下文中提取元数据,为答案附上来源链接或页码,实现答案的可追溯。
3.3 流程图可视化
下面使用Mermaid流程图来展示RAG的完整工作流。
四、⚖️ 优势、局限与系统性挑战
RAG并非一个即插即用的银弹,它在带来显著优势的同时,也引入了新的工程复杂性和系统性挑战。
4.1 RAG的核心优势
准确性提升:答案基于外部可信知识,事实性显著优于纯粹的模型生成。
幻觉抑制:为生成过程提供了事实约束,有效降低了模型“自由发挥”的概率。
知识动态更新:知识库的更新成本远低于模型微调或重训,时效性强。
可解释性与信任:答案可溯源至具体文档片段,增强了用户信任。
领域适配性:通过定制知识库,可快速将通用模型适配到专业领域。
4.2 核心局限与工程挑战
一个生产级的RAG系统,需要在检索和生成两个环节应对诸多挑战。
4.2.1 分块策略的“局部性”陷阱
问题描述:无论分块策略多么精妙,都存在切断上下文的风险。一个完整的逻辑链条、一个指代关系(如“他”指代前文的“张三”),可能被分割到不同的块中。这会导致检索时,只召回了部分信息,使得LLM无法进行完整的推理。
改进方向:滑窗重叠(Sliding Window Overlap):让相邻的块之间有部分内容重叠,增加上下文连续性。
父子块级联(Parent Document Retriever):将文档分为大块(父)和小块(子)。检索时先在小块中找到最相关的,然后返回其所属的整个大块给LLM,兼顾了检索精度和上下文完整性。
指代消解(Coreference Resolution):在预处理阶段,使用NLP模型将文中的代词(我、他、它)替换为具体的实体。
4.2.2 检索阶段的系统性难题
检索的质量直接决定了RAG系统的上限。所谓“垃圾进,垃圾出”,如果检索环节返回了不相关或有误导性的信息,LLM再强大也无能为力。低相关性召回:用户的提问方式千变万化,有时非常口语化或模糊。单纯的语义相似度可能无法捕捉到用户的真实意图。
召回不全:答案可能分散在多个文档片段中,但Top-K的限制可能只召回了其中一部分。
“大海捞针”与“中间迷失”:当知识库非常庞大时,精准召回的难度剧增。同时研究表明,LLM在处理长上下文时,对开头和结尾的信息关注度更高,中间部分的信息容易被“忽略”。
工程解法:混合检索(Hybrid Search):结合关键词检索(如BM25)和向量检索。关键词检索能保证字面匹配的精确性,向量检索负责语义匹配的泛化性,两者互补。
查询重写/转换(Query Rewriting/Transformation):利用LLM对用户的原始问题进行改写、扩展或分解。例如,将一个复杂问题分解为多个子问题分别检索(Multi-Query),或让LLM先猜测一个可能的答案再用这个答案去检索相关文档(HyDE)。
交叉编码器重排序(Cross-Encoder Reranking):在召回(Recall)阶段后,使用计算更精细但更慢的交叉编码器模型,对候选片段进行重新排序,选出真正最相关的片段。
4.2.3 生成阶段的忠实度挑战
即使检索到了正确的信息,生成环节也可能出问题。过度依赖或曲解证据:LLM可能只利用了上下文中的一小部分信息,或者错误地解读了上下文的含义。
上下文冲突:如果检索到的多个片段信息存在矛盾,LLM可能会感到困惑,导致生成不一致或拒绝回答。
格式与忠实度的权衡:有时为了生成更流畅自然的回答,LLM可能会在不经意间“润色”或“补充”一些上下文中没有的信息,破坏了答案的忠实度。
工程解法:精细化的Prompt工程:在Prompt中设置严格的约束,如“你必须只使用提供的上下文回答问题,如果信息不足,请明确说明”。
上下文压缩(Context Compression):在将上下文送给LLM前,先过滤掉与问题无关的冗余句子,减少噪声干扰。
结构化索引与多路验证:对知识库进行更深度的结构化处理(如构建知识图谱),或设计多路检索验证机制,确保信息的准确性。
4.2.4 RAG的适用边界
RAG不是万能药。它强依赖于知识库的质量。如果知识库本身存在错误,RAG只会“有据可依地犯错”。此外,对于需要复杂逻辑推理、数学计算或代码生成的任务,单纯依赖检索外部文本片段的效果有限。对于表格、图片等多模态数据的处理,传统的RAG也显得力不从心。
五、🚀 落地实践与系统优化
%20拷贝.jpg)
将RAG从理论原型转化为稳定可靠的生产系统,需要在一系列工程细节上进行精细打磨。
5.1 数据源与知识库质量
数据质量是RAG系统的基石。在项目启动之初,就应建立严格的数据治理流程。
5.1.1 数据清理与预处理
格式统一:将不同来源(PDF, DOCX, HTML)的文档统一解析为纯文本或Markdown格式。
去重与去噪:去除重复文档和无意义内容(如广告、导航栏、页眉页脚)。
时效性标注:为每份文档或片段打上时间戳,便于后续进行时效性过滤。
来源可追溯:确保每个片段都能链接回其原始文档的具体位置,这是实现答案溯源的前提。
5.1.2 敏感场景的特殊考量
在医疗、金融、政企等对数据安全和合规性要求极高的领域,必须采取额外措施。本地化部署:所有组件(Embedding模型、LLM、向量数据库)都应在私有化环境中部署,避免数据出域。
权限分级:知识库需要与企业的访问控制系统(ACL)集成。在检索时,必须根据用户的身份过滤掉其无权访问的文档片段。
5.2 核心组件选型与调优
5.2.1 Embedding模型选型
选择哪个Embedding模型对检索效果至关重要。需要根据具体场景的语言、领域和性能要求来决定。通用模型:OpenAI的
text-embedding-3-small/large、Google的text-embedding-004等,性能强大,但通常需要API调用。开源模型:社区有大量优秀的开源模型,如BGE (BAAI General Embedding)、E5 (Embedding for Everything) 系列。它们可以在本地部署,并且在特定任务上通过微调可以达到甚至超越商业模型的效果。
选型基准:可以参考MTEB (Massive Text Embedding Benchmark) 等公开评测榜单,结合自身业务数据进行小范围测试,选择最合适的模型。
5.2.2 向量数据库索引优化
向量数据库的索引参数需要在检索速度、精度和内存占用之间做出权衡。HNSW索引参数:
M(每个节点的最大连接数)和ef_construction(构建索引时的搜索范围)是关键。M越大,图越复杂,精度越高但内存占用和构建时间也越长。ef_construction越大,索引质量越高。查询时参数:查询时的
ef(搜索范围)直接影响检索精度和延迟。ef越大,结果越准,但速度越慢。需要通过压测找到最佳平衡点。
5.3 检索与生成策略的进阶优化
5.3.1 检索策略的组合拳
单一的检索策略往往难以应对复杂的现实场景。生产系统通常会采用多路召回、融合排序的复杂策略。多路召回:同时使用向量检索、关键词检索(BM25)、甚至知识图谱查询等多种方式进行召回,然后将各路结果合并。
融合排序(Fusion & Reranking):使用Reciprocal Rank Fusion (RRF) 等算法对多路召回的结果进行初步融合,再用交叉编码器模型进行精排。
5.3.2 生成环节的可控性与可解释性
Prompt模板化与约束:设计精细的Prompt模板,不仅包含问题和上下文,还应包含明确的指令,如角色扮演、回答风格、信息不足时的处理方式等。
Fact-Checking机制:对于高风险场景,可以在LLM生成答案后,再引入一个独立的验证步骤。例如,让另一个LLM或规则系统检查生成的答案是否与原始上下文完全一致(Faithfulness)。
人工审核闭环:建立用户反馈机制和人工审核后台。对于系统无法很好回答的问题或用户标记为错误的结果,由人工专家进行修正,并将这些高质量的问答对(Q&A pairs)反哺到知识库或用于模型微调。
5.4 评估体系的建立
一个没有评估体系的RAG系统是无法持续迭代优化的。评估需要分离检索和生成两个环节。
5.4.1 检索环节评估指标
Context Precision (上下文精确率):返回的Top-K个片段中,有多少是与问题真正相关的。
Context Recall (上下文召回率):所有相关的片段中,有多少被成功召回了。
评估方法:通常需要人工构建一个评测集,包含一系列问题和它们对应的“黄金”文档片段。
5.4.2 生成环节评估指标
Faithfulness (忠实度):生成的答案是否完全基于提供的上下文,没有捏造成分。
Answer Relevance (答案相关性):生成的答案是否直接、准确地回答了用户的问题。
评估方法:由于答案是自然语言,评估难度较大。除了人工评估,也可以借助LLM本身来进行打分(LLM-as-a-Judge)。
5.4.3 端到端评估与监控
在生产环境中,需要持续监控系统的业务指标,如答案采纳率、用户满意度、无答案率等,并结合A/B测试不断迭代优化分块、检索、生成等各个环节的策略。
六、🔭 前沿趋势与演进方向
RAG技术仍在快速演进,社区和学界正在探索更先进的架构来克服其固有局限。
6.1 自适应与纠错RAG
Self-Corrective RAG (CRAG):这是一种带有反思和修正机制的RAG。系统会先对检索到的文档进行评估,如果判断相关性不足或存在矛盾,会触发新一轮的查询(如Web搜索)来补充或修正信息,然后再进行生成。
Adaptive RAG:系统会先判断用户的问题是否需要检索。对于常识性问题,直接由LLM回答;对于知识密集型问题,才启动RAG流程。这可以有效降低简单查询的延迟。
6.2 RAG与微调的融合 (Finetune-RAG)
RAG和微调并非互斥关系,而是可以相互促进。
用RAG数据微调模型:将生产环境中经过验证的高质量“问题-上下文-答案”三元组,用于微调Embedding模型或LLM本身。微调Embedding模型可以使其更适应特定领域的语义空间,提升检索精度。微调LLM则可以教会模型更好地理解和利用上下文。
RA-DIT (Retrieval-Augmented Dual Instruction Tuning):一种更先进的微调范式,同时训练模型在有上下文和无上下文两种情况下的生成能力,使其在RAG流程中表现更好。
6.3 结构化知识的引入:GraphRAG
为了克服RAG缺乏全局视角的局限,研究者开始将知识图谱(Knowledge Graph)与RAG结合。
GraphRAG:在预处理阶段,不仅提取文本片段,还利用LLM从文档中提取实体和关系,构建一个局部的知识图谱。当用户提问时,系统不仅进行向量检索,还在图谱上进行推理,从而能够回答需要整合多个信息点、理解复杂关系的统计或聚合类问题。
6.4 多模态RAG
随着多模态大模型的发展,RAG的应用范围也从纯文本扩展到包含图片、表格、音视频的复杂文档。
挑战:如何对非文本内容进行有效的分块、Embedding和检索是核心难题。
解决方案:使用多模态Embedding模型(如CLIP)将不同模态的信息映射到统一的向量空间。对于表格,可以将其序列化为文本或使用专门的表格问答模型进行处理。
结论
RAG作为一种工程思想,其核心在于通过外部知识源为大语言模型的生成过程提供事实依据,从而在不改变模型本身的情况下,系统性地提升了AI应用的可靠性、时效性和可解释性。它并非单一技术,而是涵盖数据处理、信息检索、自然语言生成和系统工程的综合性解决方案。
要构建一个成功的RAG系统,团队必须超越对单一组件的关注,建立起一个覆盖高质量数据、精准检索、可控生成、全面评估的体系化工程。从分块策略的选择,到混合检索的实现,再到与微调、知识图谱等前沿技术的结合,RAG的实践路径充满了细节与权衡。
掌握RAG,意味着我们不再仅仅是LLM的使用者,而是能够为其构建可信、可控“事实引擎”的架构师。这正是让大模型从一个“博学的聊天者”转变为一个“精确的助手”的关键所在。
📢💻 【省心锐评】
RAG的本质,是用确定性的工程手段,去约束和引导大模型不确定性的生成能力。它将知识的维护成本从模型端转移到了数据端,是当前实现企业级AI应用可靠性的最优解。

评论