.png)


【摘要】开源AI模型在数据分析领域为何屡屡不敌商业巨头?本文深度剖析其根本原因,系统梳理数据分析的本质挑战,揭示战略规划能力的核心地位,并详解高质量数据驱动下的模型优化路径。通过丰富案例、实验数据和方法论,展现开源模型逆袭商业模型的可行性与未来趋势,为AI开发者和数据分析从业者提供全景式参考。
引言
在人工智能的浪潮中,开源模型以其开放、可定制、低成本的优势,成为众多开发者和企业的首选。然而,现实中一个令人困惑的现象却屡屡出现:在数据分析这一关键应用场景下,开源AI模型的表现总是被商业模型如GPT-4、DeepSeek等远远甩在身后。即便开源模型在文本生成、翻译、问答等任务中已能与商业模型一较高下,但一旦涉及到结构化数据分析、复杂推理和自动化报表生成,差距便立刻显现。
这究竟是为什么?难道开源模型的“食材”不如商业模型?还是“厨师”的烹饪思路出了问题?本文将以浙江大学与蚂蚁集团联合实验室的最新研究为基础,结合行业现状与技术趋势,深入剖析开源AI在数据分析领域的短板、挑战与破局之道。我们将从数据分析的本质谈起,逐步揭示影响AI表现的三大核心能力,最终探讨高质量数据与科学训练策略如何助力开源模型逆袭商业巨头。

一、数据分析的本质挑战:AI为何难以胜任?
1.1 数据分析的复杂性:远超文本任务的“脑力活”
数据分析并非简单的问答或翻译任务,而是一项高度复杂的认知活动。它要求AI模型不仅要理解结构化数据,还要能够根据分析目标制定合理的策略,并通过编写代码实现自动化处理。整个过程如同组装一台精密机器,每个环节都需严丝合缝,任何一处疏漏都可能导致全盘皆输。
1.1.1 任务流程拆解
以“奥巴马实际获得的选举人票数和民调预测的差距”为例,AI需要完成如下步骤:
理解问题意图,识别涉及的数据文件
检索并解析相关CSV文件
编写代码读取数据,筛选最新民调
计算平均值,比较实际结果与预测
输出分析报告
这个流程不仅考验AI的“阅读理解”,更考验其“动手能力”和“全局规划”。如同侦探破案,既要抽丝剥茧,又要步步为营。
1.1.2 形式化表达
研究团队将数据分析任务形式化为如下函数:
AI模型扮演“厨师”角色,需根据“食材”(数据)、“顾客需求”(目标)和“厨具”(工具)烹制出一道“佳肴”(分析结果)。
1.2 数据集构建:高质量样本的筛选之道
为系统研究AI在数据分析中的表现,团队构建了一个覆盖多领域、多难度的高质量数据集。其流程如下:
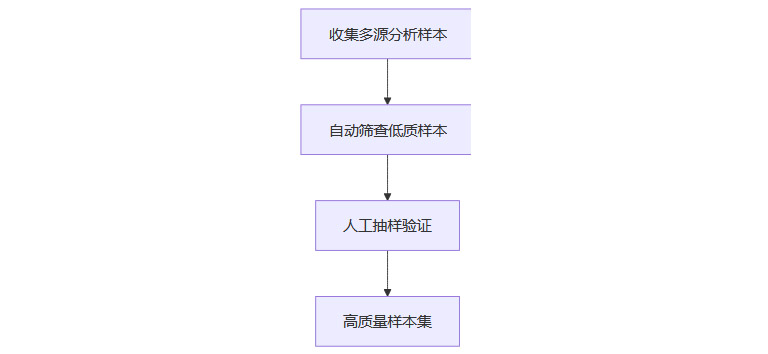
最终,团队从6443个原始样本中筛选出5613个高质量实例,涵盖从简单查询到复杂统计分析的多种场景。这一数据集为后续实验提供了坚实基础。
1.3 数据分析的三大核心能力
数据分析任务对AI提出了三项核心能力要求:
数据理解能力:能否准确读懂数据结构、字段含义及其与分析目标的关系。
代码生成能力:能否编写高效、正确的代码实现数据处理与分析。
战略规划能力:能否制定合理的分析流程,统筹全局,分步推进。
这三者如同组装机器的“说明书理解”、“工具使用”与“流程设计”,缺一不可。
二、三大核心能力深度剖析:谁才是决定胜负的关键?
%20拷贝.jpg)
2.1 数据理解能力:信息越多越好吗?
2.1.1 信息补充的边际效应
实验发现,在简单任务中,向AI提供更详细的表格信息确实能略微提升表现,但提升幅度有限。对于复杂任务,反而可能因信息过载导致性能下降。这一现象表明,AI在数据理解上已具备一定能力,但过多无关信息会分散注意力,影响推理效率。
2.1.2 干扰项测试
团队通过在数据中加入无关表格,测试AI的筛选能力。结果显示,大多数模型能较好地过滤干扰,说明其数据筛选机制已较为健全。
2.2 代码生成能力:专业“码农”未必更强
2.2.1 通用模型VS代码专家
对比通用大模型与专门优化的代码模型,结果令人意外:代码专家并未在数据分析任务中展现明显优势。进一步分析发现,绝大多数错误并非源于代码本身,而是由于分析流程设计不当或推理链条断裂。
2.2.2 错误类型分布
这说明,数据分析的难点并不在于“怎么写代码”,而在于“写什么代码、如何组织流程”。
2.3 战略规划能力:AI的“大局观”决定成败
2.3.1 交互轮次与推理链长度
实验表明,4-5轮的中等长度交互最有利于AI完成任务。过短易遗漏关键步骤,过长则易陷入细节泥潭。推理链亦然,简洁明了的思路往往优于冗长复杂的分析。
2.3.2 任务难度与训练效果
将任务按难度分为简单、中等、困难三类,发现中等难度任务最能提升AI整体能力。这印证了“适度挑战”原则:过易无成长,过难则挫败。
2.3.3 问题多样性VS质量
多样性虽重要,但高质量、典型性更关键。精挑细选的“典型题”比海量“杂题”更能锻炼AI的核心能力。
三、破解之道:高质量数据驱动下的开源模型逆袭
%20拷贝-dlqt.jpg)
3.1 三步法打造“精品数据餐”
基于上述发现,研究团队提出了一套系统性优化方案,核心理念是“以质取胜”:
3.1.1 多样化答案生成
为每个问题生成多种解法,丰富AI的思维路径,避免单一模板化。
3.1.2 精准筛选中等难度与中等长度对话
聚焦最能锻炼AI能力的“黄金区间”,既有挑战性又不至于超纲。
3.1.3 推理增强:为每个样本添加简洁推理总结
提炼核心思路,帮助AI抓住问题本质,提升全局规划与推理能力。
3.2 精品数据集构建与评测
最终,团队构建了2800个高质量实例的精品数据集。虽然数量不大,但每个样本都经过精心设计与优化,远超普通训练数据。
3.2.1 评测基准
DiscoveryBench:264个真实领域分析任务
QRData:411个统计与因果分析问题
3.2.2 性能提升一览
14B模型的表现已可媲美甚至超越GPT-4等商业模型,充分证明了高质量数据与科学训练策略的巨大威力。
四、行业影响与未来展望:开源模型的春天来了吗?
%20拷贝-uoiw.jpg)
4.1 开源模型的现实意义
成本优势:无需高昂订阅费,适合中小企业与个人开发者
可定制性:可根据特定业务场景深度优化
数据安全:本地部署,敏感数据不出企业
4.2 持续优化的挑战
规模递减效应:模型参数增大后,性能提升趋于平缓,需针对大模型设计更优筛选策略
现实任务多样性:精品数据集虽优,但覆盖面有限,需持续扩展样本类型与领域
自动化与强化学习:未来可引入RL等技术,自动筛选与生成高质量训练样本
4.3 未来趋势展望
高质量数据驱动:数据质量将成为AI能力提升的核心驱动力
战略规划能力强化:AI模型将更注重全局推理与流程设计能力
开源生态繁荣:更多企业与开发者将参与开源模型优化,推动AI民主化
结论
开源AI模型在数据分析领域的短板,并非源于“食材”不佳,而是“厨师”的战略规划能力尚未成熟。数据分析任务的复杂性,要求AI不仅要能读懂数据、写出代码,更要有全局统筹与分步推进的“大局观”。浙江大学与蚂蚁集团的研究以高质量数据和科学训练策略为突破口,显著提升了开源模型的分析能力,甚至让14B模型在部分任务上超越了商业巨头。这一成果不仅为AI开发者提供了切实可行的优化路径,也为行业指明了“以质取胜”的未来方向。随着高质量数据集和先进训练方法的不断涌现,开源模型有望在数据分析领域迎来属于自己的春天。
📢💻 【省心锐评】
“开源AI的逆袭证明,策略比资源更关键!高质量数据和科学训练,能让小模型也能挑战巨头,AI普惠化未来可期!”

评论