.png)
%20%E6%8B%B7%E8%B4%9D-bsii.jpg)

【摘要】2025年,AI产业竞争已从单点模型能力转向全栈系统工程。算力基建化、推理成本主导、Agent范式重塑入口,共同定义了智能技术从工具向共生伙伴演进的历史性拐点。
引言
2025年无疑是人工智能发展史上的一个重要分水岭。我们正在亲历一场深刻的范式转移,AI的角色正从一个高效的“智能工具”演变为与经济、科研乃至人类生活深度融合的“共生伙伴”。这一轮变革的驱动力不再局限于单一模型的参数竞赛,而是源自一场覆盖“算力—芯片—模型—应用—生态”的全栈系统性革命。
过去,行业的目光聚焦于模型本身的能力边界。现在,竞争的主战场已经转移。算力基础设施的战略布局、AI原生芯片的设计与替代、模型架构在规模与效率间的权衡、推理成本的经济学考量、Agent作为新交互范式的崛起,以及开源生态与国家战略的协同共振,共同构成了当前AI发展的宏大叙事。本文将系统性解码驱动这场变革的十大核心趋势,剖析其背后的技术逻辑与产业影响。
🌀 一、算力“基建化”:智能时代的“新电力网”
%20拷贝-wpij.jpg)
算力正在经历一场身份的重塑。它不再是传统意义上的IT资源,而是演进为一种类似于电力、水网的社会级基础能力。这种“基建化”趋势的核心载体,便是从分散式机房向集中式、超大规模“算力工厂”的转变。
1.1 数据中心向“算力工厂”的形态演进
AI大模型的训练与推理任务,对计算、存储和网络资源提出了前所未有的需求。传统的通用数据中心在架构、功耗和互联带宽上均已无法满足。作为应对,**超大规模数据中心(Hyperscale Data Center)**应运而生,其核心特征已不再是服务器托管,而是成为一个高度集成的算力生产与调度系统。
这种转变意味着数据中心的建设与运营,已经从IT工程问题上升为涉及能源、材料、网络与系统软件的复杂工程挑战。
1.2 全球资本的“军备竞赛”
算力基础设施的战略价值,直接催生了全球范围内的资本密集投入。这不仅是企业间的竞争,更带有国家战略博弈的色彩。
超级项目密集落地:微软与OpenAI联合规划的**Stargate“星际之门”**项目,预计投资超1000亿美元,旨在构建支撑下一代AI模型的超级计算机。Google的AI枢纽、亚马逊的新建云区域等项目,投资规模均在数百亿美元级别。这些投资的本质,是在为未来5-10年的AI主导权构建物理护城河。
主权算力与区域枢纽兴起:数据主权与产业安全考量,推动各国加速建设自主可控的算力基础设施。德国、西班牙正分别竞逐欧洲与南欧的算力枢纽地位。沙特阿拉伯、肯尼亚等国家则利用其能源或地理优势,布局区域性的云与数字中心,新兴市场成为算力地缘格局中的新变量。
1.3 全国一体化算力网络的战略布局
我国已将算力基础设施建设提升至国家战略高度,其核心举措是构建全国一体化算力网络。
“东数西算”工程:该工程旨在解决我国东西部地区算力供需与资源禀赋的结构性错配问题。通过构建国家算力枢纽节点,将东部密集的算力需求,引导至西部可再生能源丰富、土地与气候条件适宜的地区进行处理。这不仅是算力资源的优化配置,更是能源结构与数字经济的深度联动。
“天地一体化”算网探索:面向未来,我国正在布局更为前沿的算力形态。例如,由北航牵头的“天算星座”与浙江之江实验室规划的“三体计算星座”,目标是构建**“太空超级计算机”**。通过在轨的异构AI平台,实现云边协同与即时响应,为遥感、通信、灾害预警等提供全新的算力解决方案。“星溪02-S21”异构AI平台已完成在轨验证,标志着这一构想正逐步走向现实。
🌀 二、芯片AI原生化与国产替代加速
随着AI应用成为主流,芯片设计的底层逻辑正发生根本性转变,从服务通用计算全面转向为AI任务原生设计。同时,全球供应链格局的变化也为国产芯片生态的成熟创造了窗口期。
2.1 芯片架构的AI原生转向
AI任务,特别是深度学习,其计算负载以大规模并行、高密度的矩阵运算为主。这决定了不同类型芯片在AI工作流中的角色分工。
GPU(图形处理器):凭借其强大的并行计算能力,GPU在AI训练领域占据绝对主导地位。但其高昂的价格与稀缺性,也倒逼行业寻找更具性价比的替代方案。
NPU(神经网络处理单元):NPU是为AI推理任务设计的专用处理器。它已成为智能手机、AI PC、物联网设备的标配,能够在终端设备上实现低功耗、低延迟的本地AI计算。
ASIC/FPGA(专用/可编程芯片):这两类芯片为特定AI应用场景提供定制化算力,能够在能效比和性能上实现极致优化,在特定推理任务中增长迅速。
CPU(中央处理器):CPU的角色也在转型。通过集成AI加速指令集(如AVX-512 VNNI),CPU能够更高效地协助GPU处理数据预处理、模型调度等任务,在异构计算体系中扮演重要角色。
2.2 国产AI芯片生态的闭环与突破
面对外部技术限制,我国AI芯片产业正加速形成自主可控的完整生态。这一生态的核心是实现**“国产模型 + 国产芯片 + 国产SDK”**的全栈协同。
标志性进展在于,国内已成功基于该闭环方案,完成了千亿级参数大模型的训练验证。这表明我国已具备不依赖国外核心技术的超大规模AI模型研发与部署能力。DeepSeek等模型针对华为昇腾芯片的深度优化,以及国内企业自主并行计算SDK的开发,都是这一趋势的具体体现。
在市场格局上,以华为、寒武纪、海光为代表的国内企业,正全力攻坚高性能AI芯片。虽然英伟达在全球市场仍占主导,但国产替代方案的市场份额正稳步提升。完善的软件生态,包括编译器、并行计算框架、算子库和AI开发平台,成为发挥硬件性能、降低用户迁移门槛的关键。
🌀 三、模型架构创新:平衡“规模”与“效率”
%20拷贝-yrok.jpg)
在算力与数据成本持续高企的背景下,预训练水平的高低直接决定了大模型厂商的梯队划分。而架构创新,则成为突破“规模定律”与“效率瓶颈”这对核心矛盾的关键路径。
3.1 MoE成为主流架构选择
业界对“规模定律”(Scaling Law)的信仰并未动摇,即更大的模型通常意味着更强的能力。但无限制地增加模型参数,会导致训练与推理成本呈指数级增长,很快触及经济效益的边界。
混合专家模型(Mixture of Experts, MoE)架构成为破解这一难题的主流方案。其核心思想是“大参数,小激活”。一个MoE模型由多个“专家”子网络和一个“门控”网络组成。在处理每个输入时,门控网络会动态选择激活一小部分最相关的专家来参与计算。
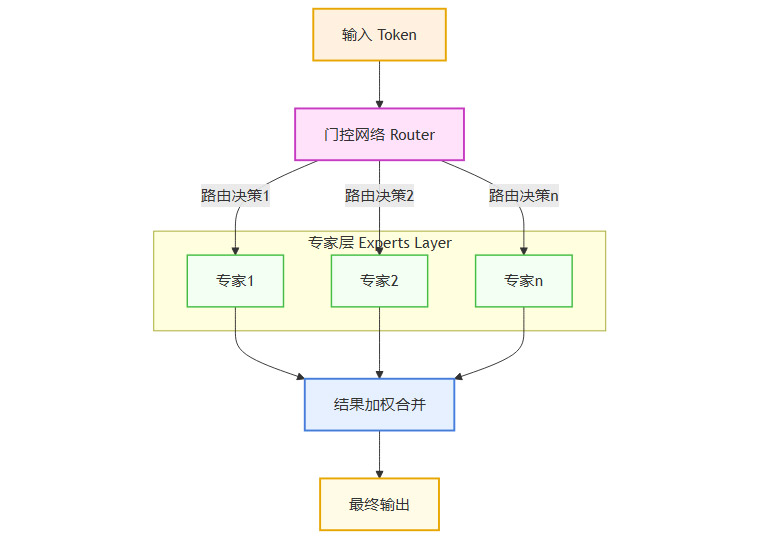
这种机制使得模型可以在不显著增加单次推理计算成本的前提下,大幅扩展总参数量与知识容量。国内顶尖模型,如阿里的Qwen3、华为的盘古Ultra、智谱的GLM-4.6以及月之暗面的Kimi K2,均普遍采用了MoE或其变体架构,并取得了与同等计算成本的密集模型相媲美甚至更优的性能。
3.2 超越Transformer的探索
Transformer架构的自注意力机制是其成功的关键,但其固有的O(n²)二次方计算复杂度(n为序列长度)成为处理长上下文的瓶颈。业界正积极探索更高效的替代方案。
线性注意力(Linear Attention):通过数学变换,将计算复杂度从O(n²)降低至O(n),为处理极长序列提供了可能。
稀疏注意力(Sparse Attention):其核心假设是,一个token只需关注序列中的少数几个关键token。通过预设或学习到的稀疏模式,仅计算部分关键token对之间的注意力,从而大幅降低计算量和内存消耗。面壁智能的MiniCPM-Llama3-V 2.5原生支持高达95%的稀疏度,是一个典型的成功实践。
3.3 训练技术的持续演进
除了架构本身,训练方法也在不断进化,以提升模型对齐人类意图的能力和部署效率。
模型蒸馏(Model Distillation):通过一个强大的“教师模型”向一个轻量的“学生模型”传递知识。这种方法能够在保持核心能力的同时,大幅压缩模型体积,使其能够部署在资源受限的端侧设备上,满足低延迟、高隐私的应用需求。
强化学习(Reinforcement Learning):**RLHF(人类反馈强化学习)**已成为训练对话式AI的标准流程。在此基础上,RLVR(可验证奖励强化学习)、RLMT(模型奖励思维强化学习)等新技术不断涌现,旨在解决奖励模型偏差、提升模型在复杂任务中的规划与推理能力。
🌀 四、推理成为主战场:“训得起”到“用得快、答得准”
如果说过去两年AI领域的焦点是模型的“训练”,那么2025年的主战场已明确无误地转向了“推理”。随着大模型从技术演示走向规模化商业应用,推理的成本、延迟、吞吐量和准确性,共同构成了AI服务能否落地的生命线。
4.1 “推理时间”延长与自适应计算
传统观念追求AI的即时响应。但新趋势表明,对于复杂问题,用户愿意接受更长的“思考时间”以换取更高质量的回答。这催生了新的推理模式。
自适应推理:模型能够根据任务的复杂度,动态调整所需的计算资源和推理步长。简单问题快速响应,复杂问题则调用更多专家、进行多轮内部思考或执行更长的思维链(Chain-of-Thought)。
多路径推理:模型不再局限于单一的线性推理路径,而是可以探索多种解决方案,并从中选择最优的一个。这极大地增强了模型解决开放性问题和创造性任务的能力。
4.2 硬件加速与边缘计算的协同
推理需求的爆发,直接驱动了专用硬件和边缘计算技术的突破。
专用推理芯片:除了通用的GPU,FPGA、ASIC等专用AI芯片被广泛应用于特定推理任务,如推荐系统、计算机视觉等,以实现极致的能效比。
边缘计算与推理加速:在自动驾驶、工业质检等对延迟极度敏感的场景,将推理任务下沉到边缘侧设备成为必然选择。专用的边缘AI芯片与优化的推理框架(如TensorRT, ONNX Runtime)相结合,能够在不依赖云端的情况下,实现高速响应。
4.3 推理框架的架构革新
为了在有限的预算内提供更强的推理能力,推理系统本身也在进行深刻的架构革新。
MoE架构的推理优化:虽然MoE模型总参数量巨大,但每次推理仅激活少量专家,这为推理侧的负载均衡和资源调度带来了新的挑战与优化空间。
Token压缩技术:例如,在多模态场景中,利用OCR技术将图片中的大量文本信息表征为极少数的“视觉token”,可以大幅降低后续处理的计算成本。
增量学习:让模型能够在部署后,从与环境的持续交互中学习和优化,而不是完全依赖于固定的离线训练数据。这使得模型能够适应动态变化的环境,持续提升性能。
🌀 五、具身智能:信息AI与物理AI的双线并进
%20拷贝-edjj.jpg)
当前AI的发展呈现出一种显著的双轨格局:信息AI(处理文本、图像等数字信息)正处于大规模应用爆发期,而物理AI(与物理世界交互)则处于关键的技术研发突破期。具身智能(Embodied AI)正是这两条轨迹的交汇点,是AI从数字世界走向物理世界的终极体现。
5.1 从“身体”构建转向“大脑”突破
过去,机器人领域的发展重心长期在于“身体”的构建,即机械结构、传感器和驱动系统的硬件创新。如今,随着大模型技术的成熟,发展的瓶颈已转向“大脑”的突破。具身智能的核心挑战,在于让智能体具备对物理世界的深刻理解与交互能力。
这要求智能体必须掌握物理常识,例如重力、摩擦力、物体恒存性、因果关系等。它需要在动态、非结构化的真实环境中,完成从感知、决策到行动的完整闭环。
5.2 两大核心技术路线
为了构建具身智能的“大脑”,业界正沿着两条主要技术路线进行探索。
世界模型(World Models):
世界模型旨在让AI在内部构建一个关于物理世界如何运作的模拟器。通过学习海量数据(尤其是视频),模型能够预测一个行为将导致物理世界发生怎样的变化。例如,视频生成模型可以预测一个球被推下斜坡后的运动轨迹。结合物理引擎,世界模型能够增强AI的物理常识和长时程规划能力。VLA(Vision-Language-Action)框架:
VLA是一个统一的多模态框架,它将视觉感知(Vision)、自然语言指令(Language)和机器人动作(Action)映射到一个共同的表示空间。这使得机器人能够理解并执行“把桌上的红苹果放到篮子里”这类复杂的、带有语义的指令。它将大语言模型的推理能力与机器人的物理执行能力连接起来。
5.3 开源生态与产业化进程
具身智能的发展离不开开源生态的推动。
开源框架与模型:Physical Intelligence团队的兀系列模型采用流匹配技术,在动作生成的平滑度和多任务泛化上表现出色。OpenVLA基于成熟的Llama 2构建,降低了微调和部署的门槛。宇树科技的Unitree RL Gym则为人形机器人的行走训练提供了重要的开源参考。
高质量数据集建设:获取规模化的、与物理世界交互的数据是训练具身智能的关键。远程遥控操作、动作捕捉设备、仿真环境生成等多种数据采集方式,共同保障了训练数据的质量与多样性。
在产业化方面,人形机器人正从实验室走向商业应用。在工业场景,它们已开始执行重复性、危险性或高精度的任务,并获得了小规模商业订单。在家庭场景,各类原型产品也持续涌现,预示着一个巨大的潜在市场。
🌀 六、AI Agent范式变革:行动闭环与流量再塑
如果说大型语言模型是AI的“大脑”,那么AI Agent就是拥有了“手脚”和自主决策能力的完整智能体。Agent正成为继LLM之后,又一个足以引发范式革命的技术浪潮。
6.1 从“对话工具”到“任务执行者”
传统的对话式AI主要扮演信息查询和内容生成的角色。而一个成熟的AI Agent,则具备感知-规划-决策-执行的完整闭环能力。
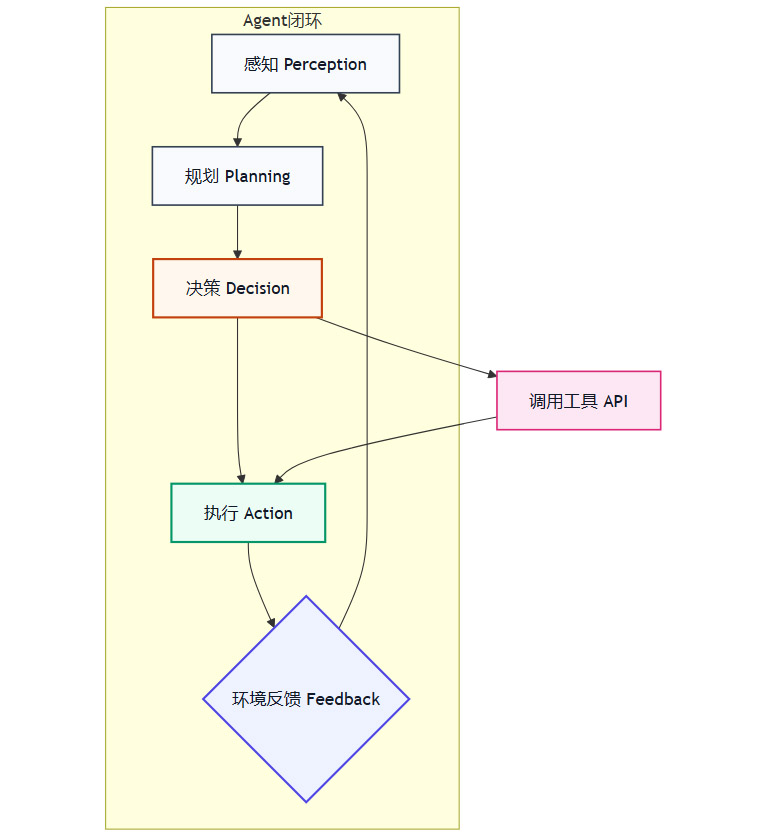
这意味着Agent不仅能“说”,更能“做”。它可以通过调用API、操作软件、访问数据库等方式,自主地完成用户下达的复杂任务,例如“帮我预订下周三去上海的机票和酒店,预算2000元以内,选择评分最高的”。
6.2 开发门槛降低与生态成熟
Agent应用的爆发,得益于开发门槛的大幅降低。
AI Coding技术:开发者可以通过自然语言描述,快速生成Agent所需的功能代码,从而将精力集中在核心的业务逻辑设计上。
主流Agent框架:一系列成熟的开源框架为不同场景提供了解决方案。LangGraph支持构建有状态、可循环的复杂工作流;AutoGen以多智能体对话驱动,代码生成能力突出;Dify和Coze等平台则提供了低代码甚至零代码的可视化界面,让非技术人员也能构建Agent。
6.3 入口与分发逻辑的根本性变革
Agent的普及将从根本上重塑用户与数字世界的交互方式,引发流量入口的革命。
从“人找服务”到“服务找人”:当前,用户需要打开不同的App来完成不同任务。在Agent范式下,用户只需通过自然语言下达一个总指令,Agent便会自主编排和调用后台的各种服务来完成任务。对话成为唯一的、核心的交互入口。
超级Agent的崛起:传统的App和网站,其功能可能被一个个专业化的Agent所替代。操作系统、浏览器、企业协同平台等,都有可能进化为**“超级Agent”**,成为用户与所有数字服务交互的统一入口和编排层。这为大型技术企业和初创公司都带来了全新的战略机遇与挑战。
🌀 七、多模态AI引领生产力跃迁
%20拷贝-cgnx.jpg)
多模态技术正成为AI应用落地的核心支撑。它让AI能够像人一样,综合处理文本、图像、音频、视频等多种信息,并在视频、3D和代码这三个领域率先展现出颠覆性的生产力变革。
7.1 视频生成:通用与垂直双线并进
视频生成技术正沿着两条主线快速发展。
通用视频大模型:以Sora、Gen-4.5、Pika等为代表,追求从文本描述直接生成高质量、长时程、逻辑连贯的视频。它们的目标是提升分辨率、物理真实性和内容可控性,挑战电影级的视觉效果。
行业垂直优化:以国内的可灵、Vidu等为代表,更聚焦于影视制作、广告营销等具体行业流程。它们能够快速生成预览片段(Pre-vis)、视觉特效、动画分镜等,大幅提升创作效率、降低制作成本。
7.2 3D生成:重塑数字内容工作流
传统的3D内容创作流程冗长且碎片化,涉及建模、雕塑、贴图、绑定、动画等多个环节,对专业技能要求极高。AI驱动的3D生成技术,正将这些环节统一起来。
用户只需通过文本或图像输入,AI即可一次性生成包含结构、细节和纹理的3D模型乃至完整场景。这极大地降低了游戏、影视、元宇宙、工业设计等领域的内容创作门槛,推动3D内容生产走向大众化和高效化。
7.3 代码生成:从“提效工具”到“开发范式”
AI代码生成工具已经跨越了生产力门槛,成为开发者的必备伴侣。一种名为**“Vibe Coding”(氛围编程)**的新趋势正在流行。
开发者不再需要逐行编写精确的代码,而是通过自然语言描述编程的意图、氛围或期望的功能,AI即可生成代码片段甚至搭建完整的项目框架。多模态能力的加入,使得AI可以基于UI设计图、产品需求文档等多种输入来生成代码。AI代码生成不仅实现了“降本增效”,更在推动“价值创造”与“能力升维”,让非专业人士也能参与到软件开发中来。
🌀 八、AI硬件百端齐放:终端设备全面“焕脑”
AI正在加速硬件设备的智能化浪潮,PC、手机、汽车、眼镜、玩具等各类终端,都在经历一场由AI驱动的“焕脑”革命。其核心是端侧AI的普及。
8.1 AI PC迎来规模化拐点
2025年是AI PC的规模化元年。英特尔、AMD、高通、苹果等主流芯片厂商,均已发布内置专用NPU的新一代处理器。PC制造商也密集推出了相关产品。
AI PC的核心价值在于,它能够在本地高效运行AI应用,无需完全依赖云端算力。这带来了三大优势:
低延迟:响应速度更快,体验更流畅。
高隐私:用户数据保留在本地,无需上传云端,保障了隐私安全。
个性化:AI可以基于本地的用户数据和使用习惯,提供更贴合个人需求的定制化服务。
8.2 可穿戴设备与新硬件形态
AI正在催生形态各异的新硬件。
智能眼镜:可以实现实时翻译、物体识别、信息提示等功能,成为现实世界的“信息增强层”。
智能耳机:能够提供会议实时记录与摘要、同声传译等功能。
AI玩具:传统的玩具升级为能够进行自然语言对话、讲故事、个性化教育的智能伙伴。
这些设备将AI无缝地融入日常生活,成为人类的“第二大脑”。
8.3 软硬件协同与生态构建
端侧AI的体验上限,取决于软硬件的深度协同。新一代处理器集成的更强NPU提供了算力保障,而操作系统、模型压缩与蒸馏技术、端侧推理引擎的优化,则共同构建了一个完整的端侧AI生态,持续推动应用创新。
🌀 九、AI4S加速科学研究与AGI进程
%20拷贝-ihzb.jpg)
AI for Science(AI4S)正成为加速通用人工智能(AGI)实现的关键力量。AI在数学、物理、化学、生物等基础学科中展现出的能力,已开始触及人类博士的水平,并全面重塑科学研究的全流程。
9.1 在各基础学科的突破性应用
医疗健康:阿里达摩院的GRAPE模型,通过分析非增强CT扫描,能将早期胃癌的检出率提升24.5%。腾讯的DeepGEM病理大模型,对肺癌驱动基因突变的预测精准度高达99%,为个性化治疗提供了重要依据。
材料科学与化学:MIT的CRESt平台通过分析海量数据预测新材料的性质。中国科学技术大学的ChemAgents AI化学家,在90天内自主完成了3500次实验,发现了一种性能提升9.3倍的新型催化剂。
生物学:上海AI实验室的“丰登・基因科学家”系统,在水稻和玉米中自主发现了数十个未知基因的功能,并已获得田间验证。
9.2 “Agentic Science”理念的兴起
AI在科学研究中的角色,正从一个被动的“智能助手”,转向一个能够自主执行完整科研闭环的**“AI科学家”**。这就是“Agentic Science”的核心理念。
这类AI系统具备综合能力:
感知与理解多模态科学数据(论文、图表、实验数据)。
推理与规划科学假设与验证步骤。
调用工具执行任务(操作实验设备、运行仿真软件)。
学习与记忆,根据实验结果迭代优化。
协作与沟通,与人类科学家或其他AI代理进行交流。
“Agentic Science”为实验科学、理论科学、计算科学和数据密集型科学都带来了全新的发展范式。
🌀 十、开源生态崛起:“中国时间”与AGI国家战略
开源是技术民主化和创新加速的核心引擎。在这一轮AI浪潮中,中国正从开源生态的积极参与者,成长为重要的领导者。同时,AGI的发展也已上升至我国国家战略的核心层面。
10.1 中国开源力量的全球影响力
中国的顶尖科研机构与科技企业,正引领全球开源模型的发布。
强大的技术吸引力:DeepSeek系列模型发布后,迅速吸引了全球超1亿用户,展现了其强大的技术实力和社区活力。
成为事实上的基座模型:阿里的Qwen系列、智谱的GLM系列,凭借其优异的性能和开放的协议,已成为全球大量企业和研究机构进行模型微调与应用开发的首选基座之一。
亮眼的下载量数据:在Hugging Face等平台上,来自中国的模型(如BAAI、Alibaba、DeepSeek等)总下载量已达数十亿次,这直接反映了其在全球开发者社区中的普及程度和影响力。
10.2 AGI上升为国家战略
我国已将推动AGI发展作为国家战略的核心目标之一。这不仅是技术层面的追求,更旨在推动AI技术在整个社会经济体系中的广泛扩散和应用,构建一个开放、协作、自主可控的AI生态系统。
华为、阿里、腾讯、百度等科技巨头,正从过去的应用导向,转向软硬件全栈自研的深度布局。以DeepSeek为代表的初创公司,则明确以实现AGI为长期目标,并获得了国家级科研与基础设施机构的支持。
截至2025年,我国总算力规模预计超过300 EFLOPS,其中智能算力占比达到35%。这为繁荣的开源生态和长远的AGI探索,提供了坚实的算力底座。
结论
2025年的AI产业,已经清晰地展现出从“点突破”到“系统工程”的深刻转变。算力的基建化、芯片的原生化、模型的效率化、推理的经济化、Agent的范式化,以及多模态、端侧硬件、AI4S和开源生态的协同爆发,共同勾勒出一幅全栈、协同、深度融合的产业全景图。
在这场全球性的技术竞赛中,中国凭借在算力基础、芯片自研、模型创新和开源生态等多个维度的里程碑式进展,正在参与并重塑全球AI的发展格局。对于身处其中的企业、科研机构和每一位技术从业者而言,这既是挑战,更是前所未有的发展机遇。通用人工智能(AGI)正在从一个遥远的科幻愿景,逐步演变为一个可以规划、可以投入、可以期待的产业真实选项。智能社会的基础设施,已然铺设。
📢💻 【省心锐评】
2025年AI的核心议题已非“模型能做什么”,而是“如何以可控成本、在全场景规模化部署”。竞争的本质,是围绕算力、推理效率和Agent生态的系统工程能力之争。

评论