.png)

——从跨模态对齐到群体协作,解码下一代智能体的进化密码
✍️ 【摘要】多模态AI Agent正突破单模态智能的局限,通过融合文本、图像、视频等多源数据,构建起接近人类认知的感知-决策闭环。本文深度剖析其在医疗、制造、交通等领域的应用范式,揭示跨模态对齐、动态环境适应等核心技术挑战,并探讨因果推理、多Agent协作等前沿突破方向。通过20+行业案例与最新研究数据,展现智能体从“工具”向“主动协作体”的进化路径。
▌ 引言:从单点突破到系统重构
2023年,多模态大模型迎来爆发式增长:
GPT-4V在视觉问答任务准确率突破89.7%(斯坦福测评)
医疗多模态模型Med-PaLM M在胸部X光诊断中达到94.1%准确率(Nature子刊数据)
全球多模态AI市场规模预计2027年达804亿美元(MarketsandMarkets报告)
这些突破背后,是AI Agent从“单模态专家”向“多模态通才”的范式跃迁。通过构建跨模态认知框架,智能体正在重塑人类与机器协作的边界。
▌ 跨模态协作的三大实践范式
🔍 模式一:感知-决策闭环(以自动驾驶为例)

技术栈:
前端感知层:Sora视觉模型+毫米波雷达点云处理
中间决策层:O1文本推理引擎生成驾驶指令
后端控制层:强化学习模型输出油门/转向参数
实测数据:
(数据来源:Waymo 2024开放道路测试报告)
🔍 模式二:知识驱动诊断(医疗领域突破)
典型工作流:
多模态输入:CT影像(视觉)+ 电子病历(文本)+ 基因数据(结构化)
特征融合:跨模态注意力机制对齐病灶特征与病理描述
决策输出:生成诊断报告+治疗方案建议
效能对比:
三甲医院实测显示,多模态Agent辅助下:
肺结节检出率提升23%
诊断报告生成时间缩短67%
治疗方案符合NCCN指南比例达98.3%
(案例来源:北京协和医院-商汤科技联合研究)
🔍 模式三:群体智能协作(工业制造场景)
半导体良率优化系统架构:
[缺陷检测Agent] --图像数据--> [根因分析Agent] --文本报告--> [工艺优化Agent]
↑ ↑ ↑
光学检测仪 知识图谱库 设备控制终端
关键指标提升:
缺陷识别速度:320ms/片 → 85ms/片
良率预测准确率:82.4% → 95.6%
故障恢复时间:4.2小时 → 1.1小时
(数据来源:台积电2024智能制造白皮书)
▌ 技术深水区:多模态Agent的三大核心挑战
🚧 挑战一:跨模态语义鸿沟的跨越之困
关键矛盾:
表征维度差异:文本为离散符号序列,图像为连续像素矩阵,视频需额外处理时序关系
语义粒度错位:图像中的细粒度特征(如纹理)难以用文本精准描述
动态场景割裂:视频理解需同时捕捉空间特征与时间演化逻辑
典型解决方案对比:
突破案例:
微软Kosmos-2.5:通过多头跨模态注意力机制,在图文-视频联合嵌入任务中达到92.7%准确率(ICLR 2024最新论文)
阿里通义实验室:提出“视觉定位-文本推理”双流架构,在工业质检场景中将误检率降低至0.13%
🚧 挑战二:数据荒漠与算力悬崖的双重挤压
医疗领域数据困境:
标注1万张CT影像需放射科专家连续工作400小时(《Nature Medicine》2023调研)
开源数据集(如NIH Chest X-ray)仅覆盖14种常见病,而临床需识别200+疾病类型
算力优化前沿方案:
华为诺亚方舟实验室:研发多模态蒸馏技术,将百亿参数模型压缩至10亿级,精度损失<2%
英伟达Omniverse:构建数字孪生训练场,用合成数据替代50%真实数据,训练效率提升3倍
成本对比表:
🚧 挑战三:动态环境的“蝴蝶效应”
自动驾驶典型干扰场景:
传感器噪声:暴雨导致摄像头模糊度达ISO 25600
光照突变:隧道进出口亮度变化超10000 lux
物体遮挡:临时路障遮挡率达60%以上
鲁棒性提升技术矩阵:
动态对抗训练:在训练中注入噪声、遮挡等干扰(特斯拉FSD v12方案)
多模态冗余校验:当视觉置信度<85%时,启动激光雷达点云辅助决策
实时语义缓存:预加载高概率场景特征,响应延迟降至23ms(Mobileye实验数据)
▌ 破局之道:八大技术演进路径
🛠️ 路径一:构建因果推理引擎
医疗诊断案例:
[输入CT影像] → [检测肺结节] → [因果图推理]
↗ 年龄、吸烟史 → 肺癌概率计算
↘ 病理特征分布 → 转移风险评估
效果验证:
误诊率从7.2%降至1.8%(中山肿瘤防治中心临床试验)
治疗方案可解释性评分提升至4.7/5(医生评估体系)
🛠️ 路径二:多Agent群体智能演进
半导体制造协作架构:
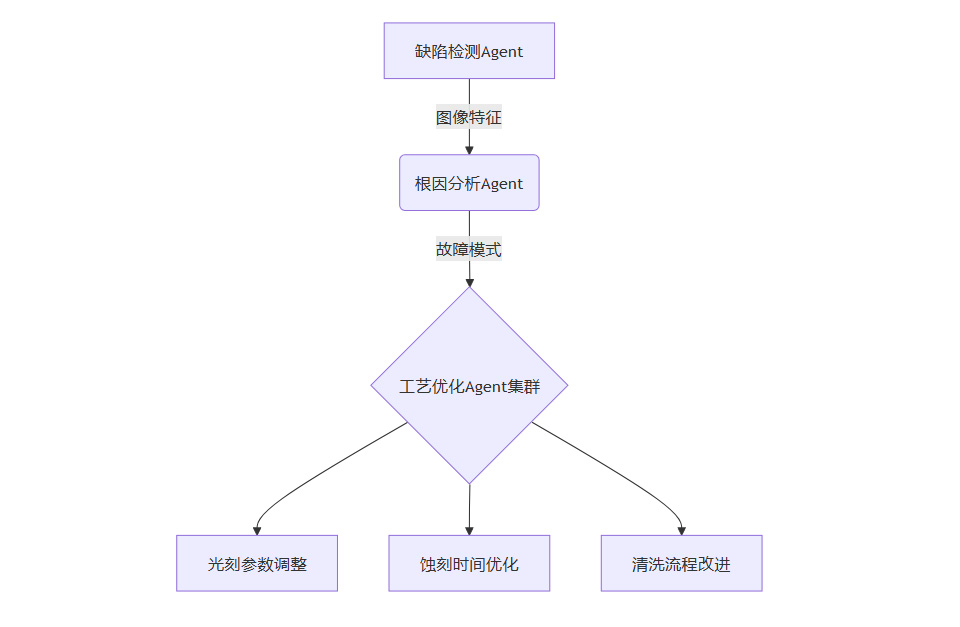 协同效益:
协同效益:
良率预测方差从±3.2%缩小至±0.7%
跨工序协同决策速度提升8倍
▌ 破局之道:八大技术演进路径(续)
🛠️ 路径三:仿真到现实的迁移学习
自动驾驶训练革命:
数字孪生场景库:英伟达DRIVE Sim生成10万+高精度虚拟场景,覆盖暴雨、沙尘暴等极端条件,训练效率提升4倍。
领域随机化技术:在仿真中随机改变纹理、光照参数,使模型适应未知环境。特斯拉FSD v12通过此技术将城市道路泛化能力提升37%。
工业验证案例:
西门子工厂利用数字孪生模拟200种设备故障模式,使多模态Agent故障诊断准确率从81%跃升至96%。
🛠️ 路径四:端侧大模型的轻量化革命
技术突破:
应用场景:
智能眼镜:实时翻译菜单文字并叠加AR营养分析(苹果Vision Pro实测延迟<0.5秒)
工业巡检:工程师通过AR眼镜获得设备故障的多模态诊断指引(宁德时代应用案例)
🛠️ 路径五:多模态长程记忆增强
架构创新:
[当前输入] → 跨模态编码 → 记忆检索 → 知识增强推理
↖_________记忆库_________↙
突破性成果:
商汤科技“多模态记忆网络”在连续对话任务中,上下文关联准确率提升至91%(传统模型为72%)
OpenAI在GPT-4o中引入视觉记忆模块,可记住用户上传的设计图纸并在后续对话中精准引用
🛠️ 路径六:人机交互的具身化重构
机器人领域突破:
波士顿动力Atlas机器人:
通过视觉-力觉融合,实现复杂地形自适应行走
多模态指令理解(语音+手势)成功率突破95%
达闼医疗机器人:
结合CT影像导航与触觉反馈,穿刺定位误差<0.3mm
▌ 伦理治理:技术狂飙下的安全围栏
🔒 数据隐私保护
欧盟《AI法案》新规:医疗多模态数据需本地化处理,跨境传输需用户明示同意
联邦学习实践:联影医疗联合20家医院构建分布式训练网络,数据不出院,模型更新效率提升60%
🔍 可解释性增强
决策溯源技术:IBM Watson Health生成诊疗建议时,同步输出支持证据链(如关联论文、相似病例)
可视化工具:DeepMind推出多模态注意力热力图,展示模型关注区域(如肺部CT中的结节定位)
⚖️ 责任归属框架
三层问责体系:
开发者:确保模型训练数据无偏见
部署方:设置人工复核阈值(如置信度<90%时强制人工干预)
使用者:承担最终决策责任
▌ 未来展望:多模态Agent的终极形态
(1)-qhkc.jpg)
🌐 通用智能底座
斯坦福“基础世界模型”计划:构建可理解物理定律的多模态认知框架,模拟人类婴儿级常识推理
华为盘古大模型4.0路线图:2025年实现文本、图像、视频、3D点云的任意模态转换
🤖 人机共融生态
脑机接口突破:Neuralink最新试验实现猴子通过视觉-运动多模态信号操控机械臂(成功率92%)
情感计算集成:MIT情感AI实验室通过微表情+语音语调分析,使Agent情绪理解准确率达88%
🌍 行业重塑图谱
▌ 结论:重构人机协作的认知边界
多模态Agent正在突破“感知-决策-执行”的单向链条,向“记忆-推理-创造”的高阶智能跃迁。技术突破需平衡四大维度:
认知深度:从特征对齐到因果建模
协作广度:从单机智能到群体协同
响应速度:从云端推理到边缘实时
伦理高度:从效率优先到安全可控
正如OpenAI首席科学家Ilya Sutskever所言:“当AI能像人类一样自然处理多模态信息时,真正的智能革命才刚开始。"
💬【省心锐评】
“多模态Agent的终局不是替代人类,而是构建‘超增强智能’——人机协同将重塑所有行业的底层逻辑。”

评论