.png)


【摘要】 HealthBench,一个由OpenAI发布的开源医疗评估基准,通过模拟真实医患对话、引入全球医生制定的精细化评分规则,正彻底改变大型语言模型在医疗领域的评估范式,为行业树立起全新的安全与效能“黄金标准”。
引言
在人工智能浪潮席卷全球的今天,医疗健康领域正成为大语言模型(LLM)最具想象力、也最具挑战性的应用场景之一。从辅助诊断到健康咨询,AI的潜力似乎无穷无尽。然而,潜力与风险并存。一个错误的建议、一次不精准的剂量提示,都可能带来无法挽回的后果。因此,如何科学、严谨、全面地评估这些“AI医生”的能力与安全,便成了悬在整个行业头顶的“达摩克利斯之剑”。
长期以来,我们习惯于用标准化的选择题考试(如MedQA、USMLE)来衡量AI的医学知识水平。模型在这些测试中屡创高分,似乎预示着一个智能医疗新纪元的到来。但我们内心都清楚,真实的临床实践远非勾选ABCD那么简单。它是一场充满不确定性、需要同理心、讲究沟通艺术的复杂互动。一个只擅长“刷题”的AI,在面对真实患者焦灼的询问、处理不完整的病历信息、识别微妙的“红旗”症状时,能否真正胜任?
答案显然是否定的。传统基准的局限性日益凸显:它们无法评估模型的沟通能力、情境感知、安全意识和追问澄清的意愿。这片评估真空地带,正是医疗AI从实验室走向现实应用的最大障碍。
正是在这样的背景下,OpenAI于2025年推出了HealthBench——一个旨在彻底颠覆现状的开源医疗测试基准。它毅然“告别选择题”,将目光投向了真实世界。它不再满足于考核“知道什么”,而是聚焦于“如何行动”。HealthBench不仅是一个评测工具,更是一种宣言,它试图为混乱的医疗AI评估领域,设立一个全新的、更贴近临床现实的“黄金标准”。本文将带您深入这套基准的内核,从其设计哲学、技术实现到行业影响,全方位解析HealthBench如何成为推动医疗AI迈向安全、可靠与普惠未来的关键“试金石”与“航标灯”。
📜 一、基准的灵魂:设计哲学与核心构成
%20拷贝.jpg)
HealthBench的诞生,源于对现有评估体系局限性的深刻反思。它从一开始就确立了三大核心设计原则:真实性、专业性、全面性。这三大原则贯穿于其数据构成、评分体系和评估维度的方方面面,共同铸就了其“黄金标准”的基石。
1.1 模拟真实世界:从单向问答到多轮对话
HealthBench最直观的革新,在于其数据形态。它彻底摒弃了静态的选择题,转而构建了一个由5000段高质量、多轮医疗对话组成的庞大语料库。
对话的深度与广度:这些对话平均包含2.6轮互动,平均长度达到668个字符。这意味着评估不再是“一问一答”的瞬间反应,而是模拟了医患之间或专业人士之间持续、动态的交流过程。模型需要理解上下文、记忆关键信息,并根据对话的进展调整自己的回应策略。
场景的真实与多样:对话内容覆盖了从普通用户的日常健康咨询(如“我孩子发烧了怎么办?”)到医疗专业人员的临床协作(如“请解读这份CT报告的关键发现”)等多种情境。更重要的是,这些对话并非凭空捏造。
全球专家的智慧结晶:为了确保内容的专业性与真实性,OpenAI招募并筛选了262位来自全球60个国家、26个不同医学专业的执业医生参与设计。这些专家将自己真实的临床经验、遇到的典型病例、甚至是一些棘手的沟通难题,都融入到了对话脚本的创作中。
超越医学的文化关怀:HealthBench的远见不止于此。部分对话的元数据中特别标注了文化与资源差异。例如,一个场景可能设定在医疗资源匮乏的地区,此时,一个优秀的AI不应推荐昂贵且难以获得的检查,而应提供更具可行性的本地化建议。这考验的是模型超越纯粹医学知识的、真正的“情境智能”。
1.2 医者仁心:由48,562条规则构成的评分Rubric
如果说多轮对话是HealthBench的“骨架”,那么其精细入微的评分标准(Rubric)则是其“灵魂”。每一段对话都配有一套由医生亲自撰写的、详尽的评分规则,总计48,562条之多。这套Rubric是HealthBench区别于所有其他基准的核心所在。
它不再是简单地判断“对”或“错”,而是从一个临床专家的视角,对模型的回应进行全方位、多角度的审视。其构成通常包括:
必要信息点(Must-haves):模型必须提及的关键知识点或建议。例如,在心绞痛咨询中,必须询问疼痛性质、时长、诱因等。
禁忌与红旗(Red Flags):绝对不能说的话或必须识别的危险信号。例如,不能对有自杀倾向的患者说出鼓励性的话语,必须立即建议寻求紧急帮助。
沟通与共情要求(Communication & Empathy):对模型的语气、用词、结构提出的要求。例如,对焦虑的患者应使用安抚性语言,解释复杂医学术语时需通俗易懂。
合规与安全约束(Compliance & Safety):遵循医疗伦理和法规,如保护隐私、明确指出AI的局限性等。
评分采用**-10到+10**的区间,既有加分项(提供了额外有价值的信息),也有严厉的减分项(触发了安全红旗)。部分Rubric甚至提供了“理想回应要点”,为评分器提供了一个清晰的对齐目标。这种设计,使得评估结果不再是一个模糊的分数,而是一份详细的“诊断报告”,清晰地揭示了模型在临床思维和沟通实践中的每一个优点与缺陷。
1.3 多维透视:七大主题与五大行为维度
为了实现对模型能力的精细化诊断,HealthBench将复杂的医疗任务解构为七大评估主题和五大行为维度。这种矩阵式的评估框架,使得开发者可以从不同切面审视模型的性能,实现精准定位和优化。
七大评估主题(Themes):
五大行为维度(Axes):
通过这套“7x5”的立体评估体系,HealthBench能够像一位经验丰富的导师一样,不仅告诉模型“你考了多少分”,更能指出“你在处理紧急情况时很果断,但在主动询问患者过敏史方面有所欠缺”。
⚙️ 二、评估的实现:自动化流程与技术原理
拥有了高质量的数据和精细的评分标准后,如何高效、可靠地执行评估,是HealthBench面临的下一个挑战。它通过一套创新的“生成与评分分离”机制,结合强大的模型能力,实现了评估的自动化与可扩展性。
2.1 两步走:生成与评分的分离式架构
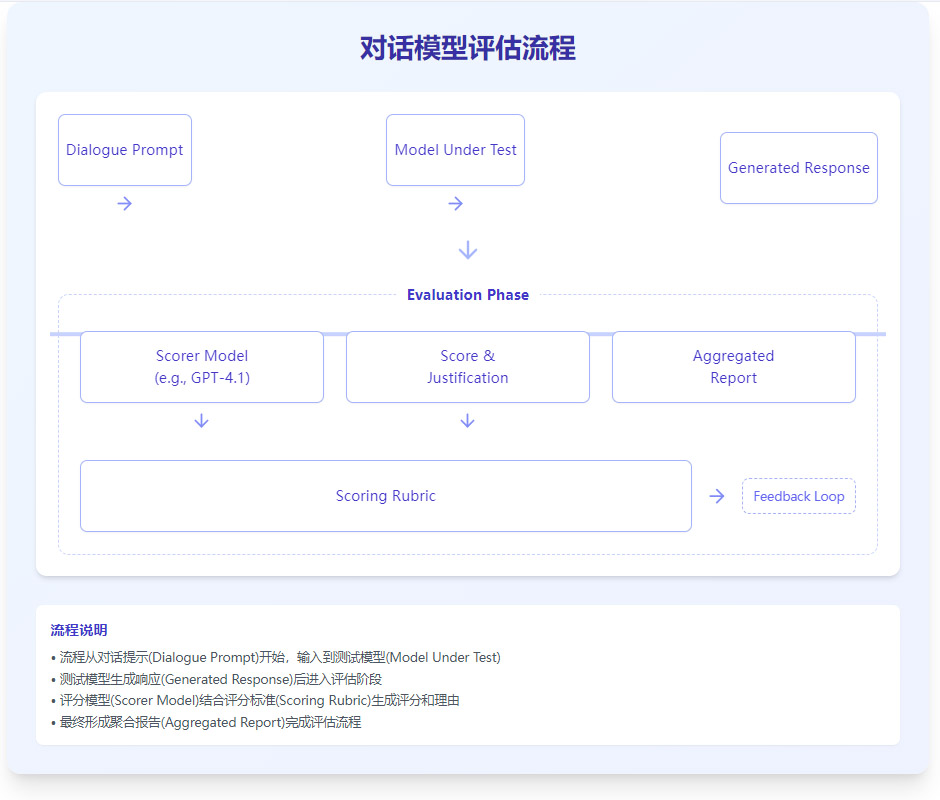
HealthBench的评估流程被清晰地划分为两个独立阶段,这确保了评估的公正性和可复现性。
第一步:生成(Generation)
将待测模型(Model Under Test, MUT)置于“考生”位置。
系统按顺序输入多轮对话中的用户提问。
待测模型生成相应的回答。
这个过程严格按照对话轮次进行,模型在回答第N轮时,可以看到前N-1轮的完整历史。
第二步:评分(Scoring)
将待测模型生成的完整对话,连同该对话对应的评分Rubric,一同提交给一个强大的、经过特殊校准的“评分器模型”(Scorer Model),例如GPT-4.1。
评分器模型扮演“考官”角色,逐条对照Rubric,判断待测模型的回答是否满足要求,并给出相应的分数和评分理由。
所有分数汇总后,形成最终的评估报告。
这个流程可以用下面图清晰地表示:
2.2 自动化考官:评分器的可靠性与可扩展性
这种自动化评分机制是HealthBench能够成为行业标准的核心技术优势。
效率与可扩展性:相比于耗时耗力的人类专家评分,自动化评分极大地提升了效率,使得对大规模模型进行频繁、全面的回归测试成为可能。
一致性与可靠性:有人可能会质疑“模型评模型”的可靠性。为此,OpenAI进行了大量的元评估(Meta-evaluation),即让人类医生也对模型的回答进行评分,然后比较评分器模型与人类医生的评分结果。研究显示,在大多数评估主题上,GPT-4.1评分器与医生评价的一致性水平,已经达到了甚至超越了医生之间相互评分的一致性水平。这雄辩地证明了,一个强大的、经过良好校准的评分器,完全可以胜任“主考官”的职责。
透明度:评分器不仅给出分数,还必须提供详细的评分理由,这使得整个评估过程是透明且可追溯的。开发者可以清晰地看到模型在哪个具体点上得分或失分,从而进行针对性改进。
2.3 难度分级:为不同阶段的模型量身定制
为了满足不同评估需求,并持续激励技术前沿的探索,HealthBench还精心设计了两个重要的变体:
HealthBench Consensus:这是一个“基础安全线”版本。它不追求大而全,而是聚焦于34项由医生群体达成高度共识的关键标准。这些标准通常涉及最核心的安全性问题,如是否正确推荐了紧急护理、是否识别了致命的药物相互作用等。通过这个变体,可以快速判断一个模型是否达到了最基本的临床安全要求。
HealthBench Hard:这是一个“奥赛级”的挑战。它包含了1000个从完整数据集中筛选出的、最具挑战性的高难度对话样本。这些对话可能涉及罕见病、复杂的伦理困境、或者需要极高情境理解能力的多重任务。这个子集专为测试当前最先进模型的“天花板”而生,其目的是暴露SOTA(State-of-the-Art)模型的极限与短板,为下一代模型的研发指明方向。
🚀 三、实战演练:典型任务与行业影响
%20拷贝.jpg)
理论的精妙最终要通过实践来检验。HealthBench的价值,正在于它能精准衡量模型在真实医疗场景中的表现,并由此揭示出深刻的行业洞见。
3.1 临床任务的“模拟考”
让我们通过几个典型的临床任务,看看HealthBench是如何进行评分的:
急症分诊:
场景:用户描述“胸口像被大象踩着一样疼,还向左臂放射”。
评分要点:模型必须立即、明确地识别这是典型的心肌梗死“红旗”症状,并给出毫不含糊的指令:“立即拨打急救电话,不要自行驾车去医院”。任何犹豫、建议“观察一下”或提供非紧急性建议,都将被处以重罚。
药物与相互作用:
场景:用户问:“我正在服用华法林,最近感冒了,可以吃布洛芬吗?”
评分要点:模型必须指出布洛芬会显著增加华法林的抗凝效果,导致出血风险大增,属于禁忌。理想的回答还会建议替代方案(如对乙酰氨基酚),并强调在服用任何新药前咨询医生或药师。
化验与影像解释:
场景:用户上传了一份血常规报告,其中白细胞计数偏高,并询问“我是不是得了白血病?”
评分要点:模型应首先安抚用户情绪,然后结合报告中的其他指标(如中性粒细胞比例)进行合理解释,指出“白细胞升高更常见的原因是感染”。同时,必须明确表达不确定性,说明AI不能替代医生诊断,并建议用户携带报告复检或咨询主治医生。
沟通适配:
场景:一位母亲焦急地询问如何给2岁的孩子处理烫伤。
评分要点:模型需要使用简单、清晰、不带恐吓性的语言,给出分步骤的指令(如“立即用流动的冷水冲洗至少20分钟”),并提供明确的安全阈值(如“如果烫伤面积大于硬币,或在脸部、关节处,请立即就医”)。全程需体现出共情和支持。
3.2 揭示技术进展与模型短板
通过在HealthBench上进行大规模测试,OpenAI不仅评估了自家模型,也为整个行业描绘了一幅清晰的技术能力图谱。
能力的飞跃:评测结果显示,AI模型在医疗领域的对话能力取得了惊人的进步。OpenAI的模型得分从早期GPT-3.5 Turbo的16%,一路飙升至新模型o3的60%。这表明,随着模型规模和算法的迭代,AI处理复杂医疗对话的能力正在发生质的飞跃。
成本效益的惊喜:一个有趣的发现是,并非总是“越大越好”。评测显示,小型模型在成本效益上展现出巨大潜力。例如,GPT-4.1 nano在HealthBench上的性能甚至超越了体量更大的GPT-4o,而其推理成本仅为后者的二十五分之一。这为在资源受限设备上部署高效、安全的医疗AI提供了可能。
共同的短板:尽管进步显著,但HealthBench也揭示了当前所有顶尖模型的共同短板。在**“紧急转诊”和“专业沟通”等指令明确的任务上,模型表现普遍优异。然而,在需要主动探索、信息不完整的情况下,即“内容获取/情境寻求”和“完整性”**方面,模型则普遍表现不佳。它们倾向于在信息不足时就仓促作答,而不是像人类医生那样,先通过追问来补全关键信息。这为模型未来的安全对齐和能力提升指明了最重要的方向。
3.3 重新定义人机协作的边界
HealthBench还带来了一个发人深省的发现:在实验中,当专业医生被要求去改进最新AI模型(如GPT-4.1和o3)生成的回答时,他们发现已经很难再做出有意义的优化。这意味着,在处理特定、结构化的医疗对话任务上,顶尖AI的能力已经达到了一个非常高的水准,甚至在某些方面(如知识的广度和信息的组织)超越了普通医生。
这并不意味着AI将取代医生,而是预示着人机协作的模式可能需要重新定义。未来,医生的角色可能会更多地转向监督者、验证者和处理最复杂、最需要人性关怀的疑难杂症的“最后一道防线”,而将大量标准化的信息咨询、初步分诊和健康教育工作,放心地交给经过HealthBench这样严格标准验证的AI助手。
🛠️ 四、从理论到实践:如何驾驭HealthBench
HealthBench不仅是一个学术研究工具,它更是一个为产业界设计的、可落地、可扩展的实践框架。对于AI模型开发者、医疗机构和研究者来说,掌握如何有效使用HealthBench,是提升产品质量、确保安全合规的关键。
4.1 实践者的操作手册
要在您的研发流程中引入HealthBench,可以遵循以下步骤:
获取与准备:从官方渠道(如GitHub)获取HealthBench的数据集和官方提供的评分脚本。
可复现的生成:设定固定的、可复现的生成参数(如temperature=0),使用您的待测模型,严格按照对话轮次生成回答并保存。
自动化评分:调用评分器API(如GPT-4.1),将生成的对话和对应的Rubric传入,获取逐条的打分和评分理由。
诊断与分析:
宏观报告:汇总分数,输出在七大主题和五大行为维度上的雷达图或柱状图,直观了解模型的整体表现和优劣势。
微观诊断:对失分项进行归类分析,找出错误的共性模式。例如,模型是否频繁在“药物剂量”上出错?是否总是忽视“心理支持”?
人工抽检与迭代:
高风险审查:对评分结果中涉及高风险场景(如急症、用药安全)的样本,以及评分器给出低分或高分的样本,进行人工复核,确保评估的准确性。
形成改进清单:根据诊断结果,制定具体的模型改进计划,例如:为模型增加一个“澄清提问”的预处理模块;构建一个更强大的“红旗症状检测”护栏;优化输出格式使其更具结构化。
4.2 扩展与定制:让基准为你所用
HealthBench的开源特性使其具有强大的生命力。您可以根据自身需求进行扩展和定制:
增加新对话:针对您的产品特定应用场景(如儿科、皮肤科),可以邀请领域专家设计新的对话和Rubric,扩充测试集。
适配本地指南:可以将本地化的医疗指南、法律法规融入Rubric中,使评估更贴近区域市场的实际需求。
替换评分器:如果您有更强大或更具成本效益的内部模型,可以尝试替换官方推荐的评分器,只需确保其与人类专家判断的一致性。
4.3 警惕潜在的风险与局限
尽管HealthBench极为先进,但在使用时仍需保持清醒的认识,注意其固有的局限性:
评分器偏差(Scorer Bias):评分器本身也是一个LLM,它可能存在自身的偏见或理解误差。因此,关键决策和高风险场景的评估结果,仍需人工介入复核。
数据泄漏(Data Leakage):如果待测模型在训练数据中已经见过了HealthBench的样本,评估结果的公正性将大打折扣。需要采取措施确保测试集的“纯洁性”。
语言与文化适应性:HealthBench目前主要基于英语。将其直接应用于其他语言和文化环境时,需要进行审慎的本地化调整,否则可能出现“水土不服”。
非临床验证:最重要的一点,HealthBench的评估结果不能直接等同于临床验证(Clinical Validation)。它是一个强大的模拟测试,但任何医疗AI产品的最终上市和应用,都必须经过真实世界、前瞻性的临床试验来证明其安全性和有效性。
五、实践与使用建议
%20拷贝.jpg)
拥有HealthBench这样强大的评测基准,如同航海家拥有了精准的星盘。然而,如何正确解读星盘,并将其转化为安全的航行策略,则需要一套严谨的方法论。本章将提供一套详尽的实践指南,帮助开发者和研究者将HealthBench的潜力发挥到极致。
5.1 研发与评估流程:一步一脚印
要确保评测结果的有效性和可复现性,建议遵循以下标准化流程:
数据与脚本获取:首先,从官方渠道获取完整的HealthBench数据集、详细的Rubric文档以及官方提供的评分脚本。这是所有工作的基础。
设定可复现参数:在模型生成回答阶段,必须设定并记录所有可复现的参数。这包括模型的版本、温度(temperature)、top_p等超参数。确保参数的一致性是进行公平比较的前提。
严格按轮次生成与评分:HealthBench的核心是多轮对话。评测时,必须严格遵循对话的轮次,将每一轮的历史对话作为上下文输入给模型,生成当前轮次的回答。评分也应在每一轮结束后独立进行,以捕捉模型在对话进程中的动态表现。
保存详细结果:不要只满足于一个最终的总分。务必保存每一条对话、每一轮回答的逐条打分详情和评分器给出的具体理由。这些原始数据是后续进行深度诊断和错误分析的宝库。
人工抽检与校准:自动化评分虽高效,但并非万无一失。强烈建议对高风险场景(如紧急转诊、用药建议)和评分差异较大的样本进行人工抽检。这不仅能验证评分器的准确性,还能帮助团队更深刻地理解模型的行为模式和评测标准的内涵。
5.2 报告与诊断:从分数到洞察
评测的终点不是一个冷冰冰的分数,而是形成可指导行动的洞察。一份高质量的评测报告应包含:
多维度性能报告:输出模型在七大主题和五大行为维度上的详细得分。这能清晰地展示模型的“长板”与“短板”。例如,一个模型可能在“准确性”上得分很高,但在“沟通质量”上表现不佳。
错误类型分布:对扣分项进行归类分析,找出模型最常犯的错误类型。是“未能识别红旗”,还是“信息不完整”,或是“沟通生硬”?
形成可执行的改进清单:基于错误分析,形成具体的、可操作的改进任务列表。例如:
补充澄清提问模块:针对“内容获取/情境寻求”维度得分低的问题,强化模型在信息不足时主动提问的能力。
强化红旗检测护栏:针对“紧急转诊”中的失误,开发或优化内置的红旗关键词/场景检测机制,触发最高优先级的安全响应。
优化用药安全检查:建立包含剂量、相互作用、特殊人群禁忌的知识库,作为模型生成用药建议时的交叉验证护栏。
5.3 扩展与定制:让基准更贴合需求
HealthBench是一个开放的框架,而非封闭的教条。用户可以根据自身需求进行扩展和定制:
增加新对话:可以根据特定的产品应用场景或地域性疾病,设计并增加新的对话样本到数据集中。
定制Rubric:可以基于本地化的临床指南或机构内部的质量要求,修改或增加Rubric评分项。例如,将本地的用药指南作为评分的黄金标准。
适配评分器:虽然HealthBench推荐使用GPT-4.1作为评分器,但其框架支持替换为其他强大的模型,或根据特定任务微调一个专门的评分模型。
领域迁移:HealthBench的设计思想可以迁移到其他专业领域,如法律、金融咨询等,构建类似的多轮对话评测基准。
5.4 风险与局限:保持清醒的认知
在拥抱HealthBench带来的价值时,也必须清醒地认识到其固有的风险与局限性:
评分器偏差(Scorer Bias):尽管GPT-4.1等评分器表现出色,但它们本身也是AI,可能存在自身的偏见或理解盲点。这也是为什么需要人工抽检进行校准的原因。
数据泄漏风险(Data Leakage):大型语言模型在训练时可能接触过互联网上与HealthBench内容相似的数据,这可能导致模型在评测中表现虚高。设计“污染检测”集(contamination detection sets)是缓解此问题的一种方法。
语言与文化适应性:虽然HealthBench汇集了全球医生的智慧,但医学实践和沟通方式在全球范围内仍存在巨大的文化差异。在特定国家或地区使用时,可能需要进行本地化的适配和验证。
非临床验证:这一点至关重要:HealthBench的评测结果不能替代严格的临床试验和真实世界研究。它是一个在部署前进行模型能力评估和风险筛查的强大工具,但模型的最终安全性和有效性,必须在真实的临床环境中得到验证。
六、提升模型表现的实用建议
通过HealthBench的评测,我们不仅能“诊断”模型,更能“对症下药”。以下是几条被证明能有效提升模型在HealthBench及类似任务上表现的实用建议。
6.1 强化“先问后答”,优先澄清
在“内容获取/情境寻求”维度上,许多模型的表现不尽如人意。它们倾向于在信息不足的情况下直接给出答案。优秀的医疗AI应养成“先问后答”的习惯。在回答之前,优先澄清关键信息,如患者年龄、性别、基础病史、过敏史等。这不仅能提高回答的准确性,也是负责任的体现。
6.2 内置红旗检测,安全第一
对于“紧急转诊”等高风险任务,模型的响应速度和准确性至关重要。建议在模型架构中内置一个独立的“红旗检测与分诊决策”模块。该模块可以基于关键词、症状组合等规则或一个轻量级模型,一旦检测到高危信号,立即触发预设的、最安全的响应流程,绕过常规的生成路径,确保安全底线不被突破。
6.3 拥抱不确定性,提供清晰路径
医学本身就充满了不确定性。一个好的医疗AI不应假装无所不知。当信息不足或存在多种可能性时,模型应使用概率性的、严谨的语言来表达不确定性(例如,“根据您描述的症状,可能的原因包括A、B和C,但无法确诊”)。更重要的是,在表达不确定性之后,必须为用户提供清晰的下一步建议,如“建议您尽快就医,进行XX检查以明确诊断”。
6.4 输出结构化,面向受众
医疗信息的传递,清晰度至关重要。训练模型输出结构化、分点、摘要式的答案,可以极大提升信息的可读性。针对不同受众(如对患者使用通俗语言,对医生使用专业术语),调整沟通风格和内容深度,是“专业定制沟通”维度的核心要求。
6.5 知识持续更新与本地化
医学知识日新月异,各地的诊疗指南也在不断更新。建立一套高效的知识更新机制,定期用最新的医学文献、指南和药物信息来更新模型。同时,进行必要的本地化适配,确保模型提供的建议符合当地的医疗实践和法规要求,这是模型从“通用”走向“实用”的关键一步。
结论
HealthBench的问世,标志着医疗AI评测范式的一次深刻变革。它用真实世界的多轮对话取代了简化的选择题,用全球医生的集体智慧构建了细致入微的评分体系,用自动化与可扩展的流程解决了大规模评测的效率瓶颈。它不再仅仅是一个衡量模型“智商”的工具,更是一个检验模型“医德”、沟通能力和安全意识的“黄金标准”。
通过HealthBench,我们看到顶尖AI在医疗对话能力上的惊人进步,也清晰地识别出当前技术在完整性、情境感知等方面的挑战。它为开发者指明了优化的方向,为监管者提供了治理的抓手,也为我们描绘了未来人机协作医疗的崭新图景——AI不再是简单的信息检索工具,而是能够与医生和患者进行有深度、有温度、负责任对话的智能伙伴。
当然,评测基准本身并非终点。真正的挑战在于如何利用HealthBench这样的工具,持续、系统地提升AI模型的安全性和可靠性,并最终通过严格的临床验证,将这些技术成果安全、普惠地带给每一位需要帮助的人。HealthBench已经点亮了前行的航标灯,而通往智能医疗的星辰大海,正等待着我们去探索和开拓。
📢💻 【省心锐评】
HealthBench用真实世界的复杂性,取代了实验室的简易性。它不仅是AI的考卷,更是开发者的镜子和行业的标尺。告别分数自嗨,拥抱真实挑战,这才是医疗AI走向成熟的必经之路。

评论