.png)


【摘要】大语言模型的隐私风险远超训练数据泄露。本文深度解构了聊天记录、上下文、属性推断与信息聚合这四大被忽视的现实威胁,并提供全栈防御策略。
引言
在技术圈,我们谈论大语言模型(LLM)的隐私安全时,话题几乎总会不自觉地滑向一个经典问题,模型是否会泄露它的训练数据。这个担忧合情合理,毕竟谁也不希望模型的回答里突然蹦出别人的信用卡号或病历。学术界投入了海量资源研究差分隐私、联邦学习等技术,试图为这个“潘多拉魔盒”配上一把足够坚固的锁。
但这种聚焦,可能让我们忽视了房间里真正的大象。
经过对过去十年AI隐私研究的系统性梳理,一个令人不安的现实浮出水面,高达92%的学术精力都倾注在了“训练数据泄露”这个相对单一的靶点上。这就像一支消防队,把全部精力都用来演练如何扑灭厨房里的小火苗,却对整栋大楼里已经燃起的熊熊大火视而不见。
现实世界中,真正的隐私威胁早已演化成一座巨大的冰山。训练数据泄露只是浮在海面上的那一小角,而在幽深的水面之下,潜藏着四个更庞大、更隐蔽、也更具破坏力的威胁。它们分别是聊天记录泄露、上下文泄露、间接属性推断和直接属性聚合。这四大“暗箭”正随着LLM能力的指数级增长,以前所未有的方式威胁着每一个用户,甚至每一个身处数字时代的“旁观者”。
这篇文章的目的,就是要把这座冰山完整地呈现出来。我们将深入解构这四大被长期低估的隐私威胁,剖析其技术根源与现实危害,并最终给出一套从普通用户到架构师都能付诸实践的全栈防御矩阵。是时候把我们的视野从那个被过度放大的小问题上移开,正视LLM时代真正的隐私挑战了。
🛡️ 一、冰山一角:被高估的训练数据泄露风险
%20拷贝.jpg)
我们必须先厘清一个基础事实,训练数据泄露(Training Data Extraction Attacks)是真实存在的。攻击者可以通过精心设计的提示词,诱导模型“回忆”并输出其在训练阶段见过的具体文本片段。但这是否是我们最应该担心的头号威胁?答案可能是否定的。
1.1 预训练阶段的天然“遗忘”机制
现代大模型的预训练过程,本身就具备一定的抗记忆性。这并非刻意设计,而是其训练范式带来的天然副产品。
海量且多样化的数据:预训练数据集通常是万亿(Trillion)级别的Token,来源极其广泛。任何单一的、包含个人信息的数据片段,都像是被扔进太平洋里的一滴水,被高度稀释了。
巨大的批次大小(Batch Size):为了在成千上万的GPU上进行高效的分布式训练,模型一次会处理非常大的数据批次。这使得模型在梯度更新时,更倾向于学习普适的语言规律,而非记住某个具体的样本。
稀疏的训练轮次(Epoch):与传统机器学习模型动辄几十上百轮的训练不同,LLM的预训练通常只在整个数据集上进行极少数轮次,有时甚至不足一轮。这意味着模型“反复背诵”同一个数据点的机会微乎其微。
研究表明,只有在训练数据中重复出现至少四次以上的文本,模型才有可能形成逐字逐句的记忆。这种苛刻的条件,在庞杂的预训练数据中并不常见。
1.2 真正的风险区:微调阶段的记忆放大效应
如果说预训练是通识教育,那么微调(Fine-tuning)就是专业课集训。这恰恰是记忆风险被急剧放大的阶段。
数据集规模小:微调数据集通常规模较小,可能只包含几千到几万个样本。
数据同质性高:数据通常围绕特定任务或领域,内容和格式较为统一。
训练轮次多:为了让模型充分学习特定知识,微调的训练轮次会远多于预训练。
当微调数据包含用户提交的个人信息时(例如,用内部客服对话来微调一个客服机器人),模型“记住”这些信息的概率会从预训练阶段的0-5%飙升至60-75%。这才是训练数据泄露风险中,最值得警惕的场景。
我们可以用一个表格来直观对比这两个阶段的记忆风险。
因此,将“训练数据泄露”作为一个笼统的概念来讨论,本身就存在误导性。其主要风险并非来自通用大模型的预训练,而是集中在特定、不规范的微调应用中。过度关注前者,会让我们错失对真正高危场景的监管。
🏹 二、潜藏的巨兽:四大被忽视的隐私“暗箭”
现在,让我们潜入水下,看看冰山主体那四个真正危险的部分。这些威胁与模型如何“记忆”无关,而与模型在现实世界中如何“使用”息息相关。
2.1 暗箭一:聊天记录泄露 (The Silent Collector)
这是最直接、最普遍,也最容易被用户忽略的风险。你与AI的每一次对话,都可能成为一座被永久收藏的数据金矿。
2.1.1 中心化存储的原罪
当前主流的LLM服务,几乎都采用中心化的云端架构。用户输入的每一个提示词和模型生成的每一个回复,都会被完整记录并存储在服务商的服务器上。这种模式带来了前所未有的攻击面。
外部黑客攻击:中心化的数据库是黑客眼中极具吸引力的目标。一次成功的入侵,可能导致数百万用户的私密对话瞬间暴露。
内部工程故障:复杂的系统难免出现Bug。历史上多次发生因平台组件故障、缓存配置错误等原因,导致用户可以看到他人聊天记录的标题、元数据甚至内容的严重事故。
供应链风险:现代云服务高度依赖第三方组件和API。任何一个供应链环节的安全漏洞,都可能成为数据泄露的突破口。
2.1.2 “隐性同意”的陷阱
更隐蔽的风险来自服务商的数据政策。许多平台在用户协议中以模糊的条款,为自己收集和使用用户数据大开方便之门。其中,反馈机制是最大的陷阱。
当你给AI的回答点下“赞”或“踩”时,这个动作在系统后台往往会被标记为“用户主动提供的反馈”。一旦被如此标记,这整段对话就可能绕开你之前设置的“退出数据收集”选项,获得长达数年甚至十年的数据保留权限,并被合法地用于模型再训练。这是一种典型的“暗黑模式”(Dark Pattern),利用用户交互习惯来获取超出预期的授权。
我们可以用一个流程图来展示这个数据流和风险点。
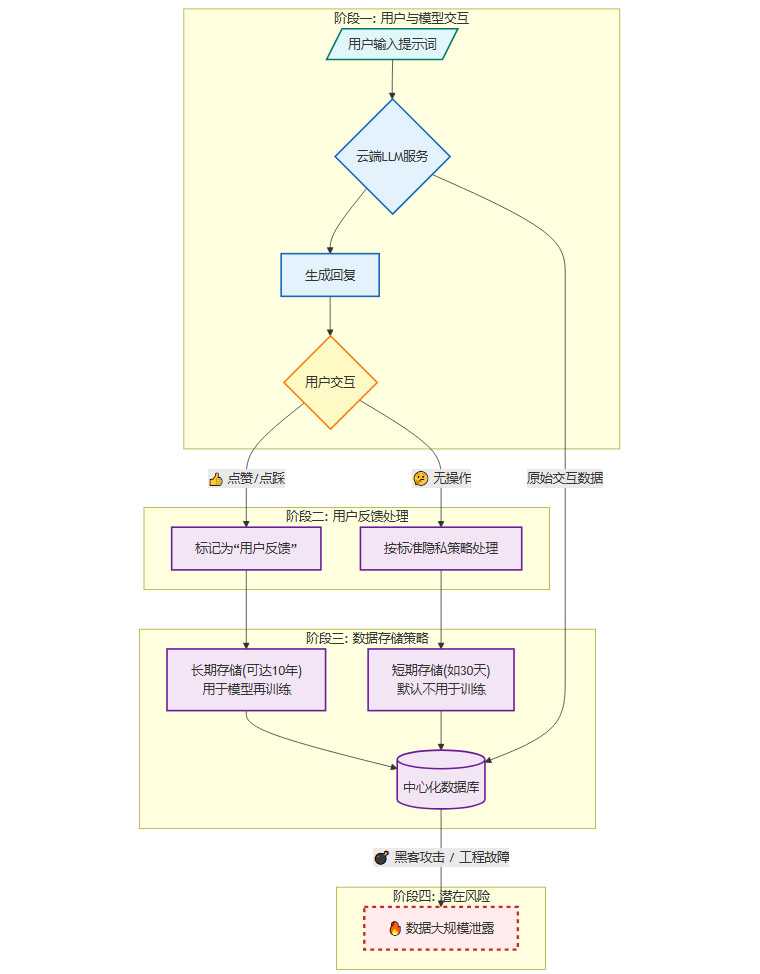
这个流程清晰地揭示了,即使用户本意只是想帮助改进模型,其行为却可能无意中将自己的隐私数据送入了一个长期、高风险的存储池。
2.2 暗箭二:上下文泄露 (Contextual Betrayal)
随着AI从简单的问答工具进化为能够执行复杂任务的智能助手(Agent),一种全新的风险应运而生,我称之为“上下文背叛”。AI助手可能在你不知情的情况下,把你托付给它的秘密,告诉了不该告诉的人或系统。
2.2.1 RAG与工具调用的风险敞口
现代AI助手的能力,很大程度上建立在两大技术之上。
检索增强生成 (RAG):让AI能够实时查询外部知识库(如公司内部文档、个人笔记、电子邮件)来获取信息,生成更准确的回答。
工具调用 (Tool Use):让AI能够调用外部API来执行操作(如发送邮件、创建日程、查询数据库)。
问题在于,当AI为了完成一个任务而检索或调用工具时,它可能会无意中将当前对话上下文中的敏感信息,泄露到它交互的下一个环节。
一个典型的场景:
你向AI助手咨询一个与个人健康相关的敏感问题,对话上下文中包含了你的病症描述。
接着,你让AI助手帮你“给我的医生发邮件,预约下周复诊”。
AI助手在调用邮件API时,为了“更好地”组织邮件内容,可能会将上下文中关于你病症的描述,一并作为邮件正文的一部分发送出去。
这个过程中,用户可能完全没有意识到自己的敏感信息已经被打包发送。随着上下文窗口从几千Token暴增到百万甚至千万级别,这种风险正被指数级放大。AI“记得”的东西越多,它无意中泄露的概率就越大。
2.2.2 缺乏隐私判断力的“耿直”助手
根本问题在于,当前的LLM本身不具备人类社会中那种复杂的、依赖情境的隐私判断力。它无法准确判断哪些信息在当前情境下是私密的,哪些可以分享。它只是一个强大的模式匹配和文本生成引擎。
系统设计者往往将防止隐私泄露的最后一道防线交给了用户,期望用户能时刻监督AI的行为。但这本身就是一个悖论,我们使用AI助手的初衷就是为了节省精力,而不是增加一个需要时刻提防的“实习生”。
2.3 暗箭三:间接属性推断 (Inferential Snooping)
这是最令人细思极恐的威胁之一。即便你没有主动透露任何个人信息,AI也能像一个经验丰富的侦探,从你提供的看似无害的蛛丝马迹中,推断出你的敏感属性。
2.3.1 “AI侦探”的超凡能力
这种能力在2025年4月的一个社交媒体趋势中得到了病毒式传播。用户上传一张看似普通的照片——比如昏暗酒吧的一角,或者随机的街景——然后询问ChatGPT这是哪里。模型竟能以惊人的速度和准确度,识别出具体的地理位置。
这种能力源于模型在海量数据训练中,学会了关联那些人类难以察觉的微小细节。
视觉细节:装修风格、光照角度、窗外植被、一个不起眼的店铺招牌。
文本细节:用词习惯、方言俚语、讨论的话题、行文的逻辑结构。
多模态关联:将你的语音语调与你的文字内容相结合,推断情绪状态或健康状况。
2.3.2 攻击的“民主化”
传统的数据挖掘和用户画像需要专业的技术和昂贵的工具。但LLM的出现,彻底改变了游戏规则。属性推断攻击已经被“民主化”了,任何一个普通人,无需任何技术背景,都可以利用现成的AI服务,对他人的隐私进行挖掘。
想象一下,有人把你社交媒体上的一张自拍、一段评论,扔给AI,然后问:
“这张照片大概是在哪个城市拍的?”
“根据这段文字,推断一下作者的年龄、教育水平和可能的职业。”
“分析一下作者最近的情绪状态。”
AI给出的答案可能不完全准确,但其精度已经足以构成严重的隐私威胁,可被用于网络霸凌、精准诈骗甚至线下骚扰。这种在用户“无感”状态下进行的隐私挖掘,几乎无法防范。
2.4 暗箭四:信息聚合 (Aggregative Profiling)
如果说属性推断是从一个点推测出一个面,那么信息聚合就是将散落在全网的无数个点,拼接成一个完整的、关于你的立体档案。这是LLM带来的终极隐私武器。
2.4.1 深度研究功能的双刃剑
ChatGPT等模型提供的“深度研究”或类似功能,可以自动化地在互联网上搜索、整合、分析关于某个主题的大量信息。这极大地降低了信息聚合的门槛。
过去,要对一个人进行“人肉搜索”,需要耗费大量时间、精力和专业技能,在不同的网站、论坛、社交媒体之间手动跳转、交叉验证。现在,只需要给AI一个指令,“帮我整理一下关于‘张三’的所有公开信息”,AI就能在几分钟内完成过去需要几天才能完成的工作。
它能找到什么?
你在不同社交平台使用相同ID或邮箱留下的痕迹。
你在技术论坛的提问、在购物网站的评论、在新闻下的留言。
甚至是你网站HTML代码注释里无意中留下的宠物名字(这常被用作安全问题的答案)。
2.4.2 对“旁观者”的无差别攻击
这种威胁最可怕的地方在于,它不仅针对AI服务的直接用户,更对所有在互联网上留下过痕迹的“旁观者”构成威胁。你可能从未使用过任何AI产品,但只要你的信息是公开的,就可能被别有用心的人利用AI进行聚合和画像。
微博的AI搜索功能就曾引发过类似的恐慌。用户发现搜索某个人的ID,AI会返回一份极其详细的个人信息摘要,甚至可能包含了用户设置为“私密”的帖子内容。这实质上是将一个社交平台变成了一个对所有用户开放的、可被AI高效查询的个人数据库。
这四大“暗箭”共同构成了LLM隐私风险的冰山主体。它们比训练数据泄露更普遍、更隐蔽、更难防范,也与我们的日常生活联系更紧密。然而,学术界和公众的注意力,却长期停留在那小小的冰山一角。
🔬 三、根源剖析:为何研究焦点出现结构性错配?
%20拷贝.jpg)
理解了四大“暗箭”的严重性后,一个自然而然的问题是,为什么学术界——这个本应最具前瞻性的群体——会将92%的资源投向一个相对次要的问题?这并非偶然,而是由技术发展的历史惯性、学术评价体系和商业模式共同作用的结果。
3.1 技术发展的路径依赖
AI隐私保护领域的研究,并非始于LLM时代。它早已在机器学习的浪潮中发展出几个成熟且强大的技术分支。
差分隐私 (Differential Privacy):提供一种数学保证,确保从数据集中查询信息时,不会泄露任何单个个体的信息。它天然就是为了解决“从聚合数据中保护个体”的问题。
联邦学习 (Federated Learning):允许在不将原始数据上传到中央服务器的情况下,在用户的本地设备上进行模型训练。其核心目标就是“数据不出本地”。
同态加密 (Homomorphic Encryption) & 安全多方计算 (Secure Multi-Party Computation):允许在加密数据上直接进行计算,从而在整个计算过程中保护数据隐私。
这些技术构成了AI隐私研究的“舒适区”。它们理论基础坚实,有明确的数学定义和安全证明,非常适合发表高质量的学术论文。因此,当LLM出现时,研究人员很自然地将这些成熟的工具应用到新的问题上,而这些工具最直接的应用场景,恰恰就是解决训练数据泄露和推理过程中的输入数据保护问题。
3.2 学术评价体系的“指挥棒”效应
学术界的评价体系,在一定程度上也加剧了这种偏差。
量化指标的偏好:像差分隐私的ε(隐私预算)这样的指标,是可量化的、可比较的。一篇论文如果能将ε值降低0.1,就是一个明确的、可被验证的贡献。
评测基准的缺乏:相比之下,像“上下文泄露”或“属性推断”这类新威胁,很难用一个简单的数学公式来定义。如何量化一次“上下文背叛”的严重程度?如何评估一个模型“推断”能力的强弱?由于缺乏公认的评测基准(Benchmark),相关的研究更难开展,也更难被同行评审所接受。
跨学科的壁垒:四大“暗箭”所涉及的问题,早已超越了纯粹的算法范畴。它们与人机交互(HCI)、系统安全、法律合规甚至社会学紧密相关。而传统的计算机科学会议,往往更偏好纯技术性的创新,跨学科的研究常常面临“两边不讨好”的尴尬境地。
3.3 商业模式与现实反馈的缺口
最后,主流的商业模式也起到了推波助澜的作用。
数据驱动的商业闭环:大型科技公司构建LLM服务的商业模式,本质上是数据驱动的。收集用户数据不仅用于改进模型,也用于理解用户行为、优化产品体验。这种中心化的、海量数据采集的模式,与联邦学习等去中心化方案在根本上是冲突的。
合规的滞后性:法律和政策的制定,总是滞后于技术的发展。对于“隐性同意”、“反馈留存”等擦边球行为,监管机构需要很长时间才能形成明确的界定和规范。在此之前,平台方有足够的动力维持现状。
用户反馈的沉默:对于上下文泄露或属性推断这类隐蔽的伤害,用户往往难以察觉,更不用说向平台方提供明确的反馈。缺乏来自现实世界的强烈信号,使得这些问题在平台的优先级排序中,远低于那些会直接导致用户流失的功能性Bug。
这三股力量共同作用,形成了一个强大的“惯性场”,将绝大多数研究资源和行业注意力都牢牢地锁定在了冰山的那一角,而忽略了水下真正汹涌的暗流。
🛠️ 四、全栈防御:从用户到架构师的实践指南
%20拷贝.jpg)
认识到问题的严重性,并不足以解决问题。我们需要一套切实可行的、覆盖从终端用户到系统架构师的全栈防御策略。这套策略的核心思想是分层防御、纵深部署。
4.1 普通用户的“数字护身符”
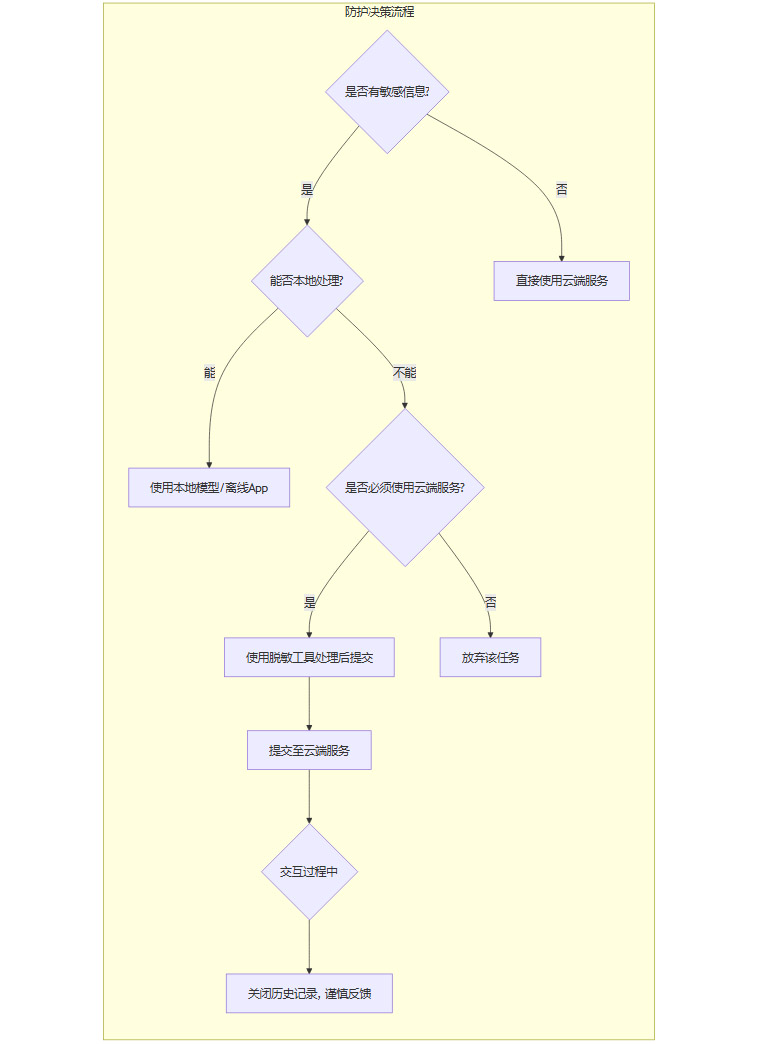
作为普通用户,我们虽然无法改变平台的底层架构,但可以通过改变自己的使用习惯和借助工具,为自己构建第一道防线。
4.1.1 本地优先,从源头阻断数据上传
这是最彻底的隐私保护方式。
部署本地模型:利用Ollama、LM Studio等工具,在个人电脑上部署开源的LLM(如Llama 3, Mistral)。对于处理不涉及联网搜索的敏感文档、个人笔记等任务,本地模型是最佳选择。
使用设备端推理:现代智能手机的NPU(神经网络处理单元)已经足够强大,可以流畅运行7B(70亿参数)级别的模型。优先选择那些提供纯离线模式的AI应用。
4.1.2 输入前脱敏,给数据穿上“防弹衣”
当你必须使用云端服务时,确保上传的数据是“干净”的。
使用浏览器插件:安装像Rescriber这样的浏览器扩展。它可以在你的文本发送给ChatGPT等服务之前,利用本地运行的小模型,自动检测并匿名化其中的个人身份信息(PII),如姓名、电话、地址等。
手动审查:养成在点击“发送”前,快速重读一遍提示词的习惯,检查是否包含了不必要的个人信息。
4.1.3 谨慎交互,关闭“隐性同意”的后门
关闭历史记录和训练选项:在AI服务的设置中,找到并关闭“聊天历史与训练”(Chat History & Training)或类似选项。这会阻止平台将你的对话用于模型改进。
避免使用反馈功能:尽量不要使用“点赞/点踩”功能。如果你确实想提供反馈,请意识到这可能会让你的对话被长期保留。
账号隔离:避免使用包含真实身份信息的手机号、主邮箱或常用社交账户注册AI服务。使用独立的、匿名的账号体系,可以有效降低信息被聚合画像的风险。
下面是一个普通用户可以遵循的决策流程图。
4.2 开发与运维团队的架构级防御
作为系统的构建者,开发者和架构师肩负着更重要的责任。我们需要在系统设计的每一个环节,都融入隐私保护的考量。
4.2.1 上下文与权限的精细化管控
这是防御“上下文背叛”的核心。
最小上下文原则:为AI Agent的每一次工具调用或RAG检索,都创建一个独立的、临时的、仅包含完成当前任务所必需信息的上下文。避免将整个对话历史作为“背景知识”传递给下游工具。
敏感数据分区与屏蔽:在系统层面,通过正则表达式、命名实体识别(NER)等技术,自动识别和屏蔽PII。在RAG场景中,对敏感文档建立独立的索引,并设置严格的访问权限。
权限最小化:为AI Agent调用的每一个API都配置最小必要权限。例如,一个只需要“读取日历”的Agent,绝不能给予它“写入”或“删除”的权限。
4.2.2 混合推理架构的落地
平衡隐私与性能的最佳实践,是采用本地-云混合推理架构。
本地预处理/脱敏:在客户端(浏览器或App)集成一个小型本地模型,负责处理所有涉及用户隐私的预处理任务,如意图识别、实体提取、数据脱敏。
云端通用能力:将脱敏后的、不含隐私的通用计算任务,发送到云端强大的LLM进行处理。
安全数据传输:在本地与云端之间的数据传输过程中,可以引入差分隐私中的噪声注入机制,或使用加密技术,进一步降低数据被识别的风险。
4.2.3 运维与合规的兜底保障
审计与日志:建立完善的审计日志,记录每一次数据访问和AI Agent的决策路径,以便在出现问题时进行溯源。日志本身也需要进行脱敏和加密存储。
数据生命周期管理:制定严格的数据保留策略,对用户数据设置最短必要的保留期限,并确保到期后能被物理删除。
供应链安全:对引入的第三方库、API和服务进行严格的安全审查和权限控制,并设计熔断和降级机制,防止因单一组件的漏洞导致整个系统的隐私防线崩溃。
结论
大语言模型的隐私挑战,已经远远超出了“模型是否会记住训练数据”这个经典命题。它已经演变成一个围绕数据采集、模型使用、用户行为和平台工程四个维度的复杂系统性问题。
我们当前面临的结构性矛盾是,学术界的研究焦点与产业界的现实风险之间,存在着一条巨大的鸿沟。当绝大多数顶尖头脑还在优化差分隐私的ε值时,真正的隐私“暗箭”——聊天记录泄露、上下文背叛、属性推断和信息聚合——正在现实世界中大规模地发生。
要应对这场挑战,单靠某一项技术的突破是远远不够的。它需要一场自下而上的、全方位的变革。
对于用户,我们需要提升数字素养,掌握基本的“数字护身符”,主动管理自己的隐私边界。
对于开发者和架构师,我们需要将“隐私设计”(Privacy by Design)的理念,融入到系统架构的每一个毛细血管中。
对于平台方和政策制定者,则需要拿出更大的勇气和智慧,填补法律与伦理的空白,对“隐性同意”等不公平做法进行严格监管,并推动建立更透明、更负责任的AI生态。
冰山已经撞了上来。现在,是时候看清它的全貌,并开始构建我们真正的“诺亚方舟”了。
📢💻 【省心锐评】
LLM隐私的核心战场已转移。别再只盯着训练数据,真正的风险在于日常使用的四大“暗箭”:聊天记录、上下文、推断和聚合。全栈防御,刻不容缓。

评论