.png)


【摘要】将AI推理部署至网络边缘,通过本地化决策闭环,实现毫秒级响应与数据隐私合规,构建支撑实时智能应用的新一代AI基础设施。
引言
集中式云计算,曾是数字时代的基石。如今,它正触及其能力的边界。在工业4.0的精密产线、自动驾驶的瞬时决策、智慧城市的泛在感知等前沿场景中,一个严峻的矛盾日益凸显。应用需要毫秒级的响应速度,而数据往返中心云的物理延迟,往往超过200毫秒。业务要求敏感数据不出本地,而集中式架构却迫使数据长途跋涉,增加了泄露风险。
AI推理负载的规模,预计将远超训练阶段。将全球数十亿用户或设备的实时请求全部汇聚到几个核心数据中心,这在经济上和技术上都难以为继。时延、抖动、隐私、成本,这四座大山共同构成了传统云计算在实时AI时代的瓶颈。
现实的需求,倒逼基础设施进行范式转移。将AI计算能力,特别是推理任务,从遥远的“云端大脑”下沉到靠近数据源和用户的“神经网络末梢”,即网络边缘。这便是分布式边缘推理的核心思想。它并非要颠覆云计算,而是对其进行一次深刻的架构重塑与能力延伸,旨在构建一个能够满足“机器速度”与“隐私合规”双重目标的新一代AI基础设施。
一、🌐 边缘推理的定义与架构范式
_副本.jpg)
1.1 核心定义与理念
分布式边缘推理(Distributed Edge Inference),其本质是在靠近数据源头与用户交互点的位置,部署和运行AI模型。它的核心目标是让感知—推理—决策的链路就地闭环。数据不必再经历漫长的跨地域传输,而是在产生的瞬间或在最近的计算节点上被处理,从而将端到端时延压缩到极致。
这种模式的根本改变在于,它将计算的重心从“数据到计算”转变为“计算到数据”。这不仅是技术路径的调整,更是对AI服务交付模式的重新思考。
1.2 新一代协同架构
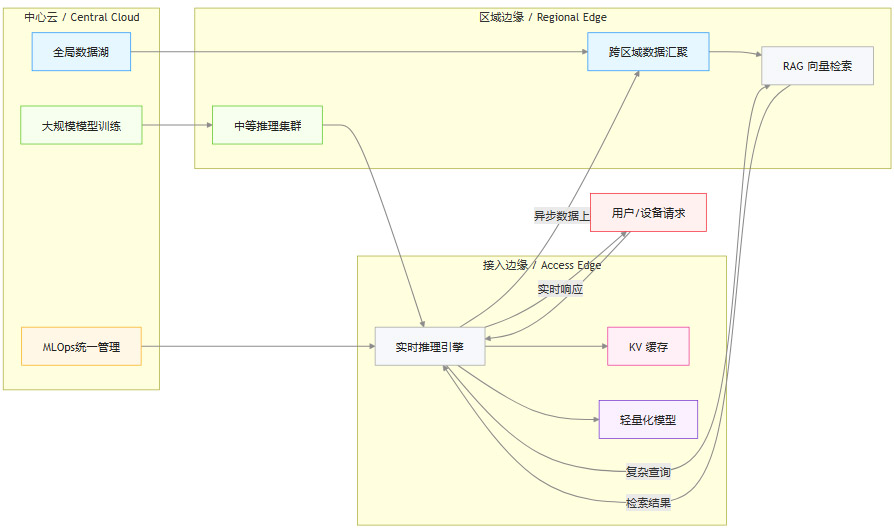
边缘推理并非要完全取代中心云,而是构建一种**“中心云 + 边缘云”**的协同新范式。两者各司其职,形成能力互补的有机整体。
中心云 (Central Cloud):继续扮演“AI工厂”和“大脑”的角色。它负责处理非实时、计算密集型的任务,例如大规模基础模型的离线训练、多源数据的聚合分析、跨区域模型的统一管理与版本控制。
边缘云 (Edge Cloud):作为“前哨站”和“反射弧”,专注于处理对延迟、带宽和隐私高度敏感的任务。它执行实时推理、本地数据预处理、即时响应与决策。
这种协同架构,既利用了中心云强大的训练能力,又发挥了边缘云的低延迟和本地化优势,形成了一套高效、健壮的AI算力体系。
1.3 分层架构解析
一个成熟的分布式边缘推理架构,通常呈现出清晰的三层结构。每一层都有其特定的功能定位和部署资产,共同支撑起从核心到边缘的完整服务链路。
这种分层设计,允许数据和计算任务在最合适的层级被处理。例如,一个复杂的金融反欺诈请求,可能在接入边缘完成初步的特征提取和模型推理,若需更丰富的历史数据,则智能回源至区域边缘进行RAG检索,最终仅将脱敏后的结果异步汇总到中心云用于模型迭代。
二、🚀 实现“机器速度”的关键技术栈
%20拷贝.jpg)
要将理论上的低延迟转化为实际可用的“机器速度”,需要一整套从模型到基础设施的全栈技术支持。这不仅是部署位置的改变,更是对AI工程化能力的全面考验。
2.1 模型工程与轻量化
将庞大的AI模型高效运行在资源相对受限的边缘节点,模型自身的优化是第一步。这需要一系列模型工程技术来平衡精度与性能。
模型蒸馏 (Distillation):用一个训练好的、复杂的大模型(教师模型)来指导一个小模型(学生模型)进行学习。学生模型能够以更小的参数量和计算量,逼近教师模型的性能。
模型量化 (Quantization):将模型参数的数据类型从高精度的浮点数(如FP32)转换为低精度的定点数(如INT8)或更低的浮点数(如FP8)。这能显著减小模型体积,降低内存占用,并利用硬件的低精度计算单元加速推理。
模型剪枝 (Pruning):识别并移除模型中冗余或不重要的参数(权重)或结构(如整个神经元或通道),在可接受的精度损失范围内,大幅削减模型的计算复杂度。
架构搜索 (NAS):通过自动化算法,针对特定边缘硬件的约束(如计算能力、内存大小),设计出最优的模型网络结构。
2.2 推理加速技术
在模型优化的基础上,推理过程本身也需要通过特定技术进行加速,以进一步压榨时延。
KV缓存 (Key-Value Cache):在生成式AI(如大语言模型)的自回归解码过程中,将已经计算过的键(Key)和值(Value)缓存起来,避免在生成每个新Token时重复计算,从而大幅提升生成速度。
流式解码 (Streaming Decoding):模型不必等整个序列生成完毕再返回结果,而是在生成每个Token或一小段文本后,就立刻将其流式传输给客户端。这极大地降低了用户的“感知延迟”(Time to First Token)。
推测解码 (Speculative Decoding):使用一个小的、速度快的草稿模型来快速生成一个候选序列(草稿),然后用大的、准确的目标模型一次性并行验证这个草稿。如果验证通过,就接受整个草稿,从而用一次大模型的前向传播,完成了多次小模型的生成步骤,实现加速。
2.3 边缘数据与RAG
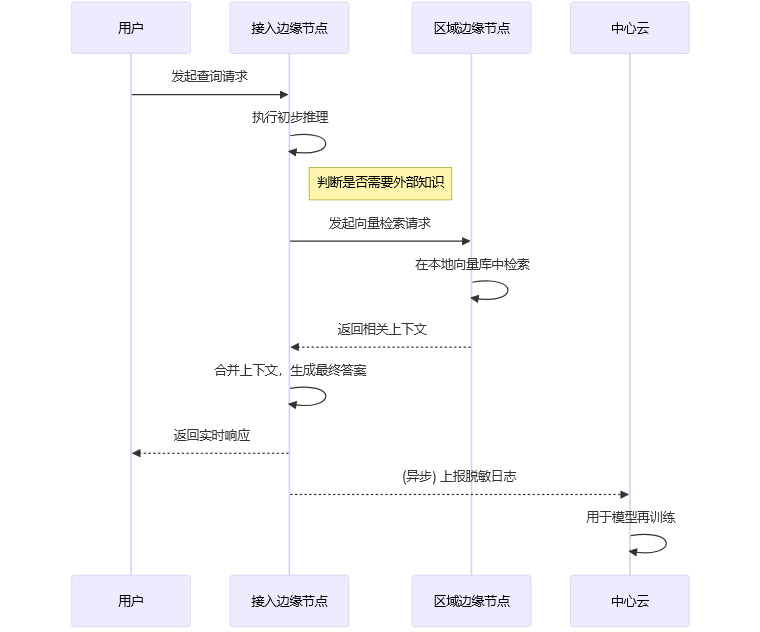
检索增强生成(RAG)是提升模型回答准确性和时效性的关键技术。在边缘架构下,RAG的实现方式也发生了变化,核心思想是让检索发生在离用户最近的地方。
向量索引下沉:将知识库的向量索引和特征库,从中心云下沉部署到区域边缘甚至接入边缘节点。
近端检索合并:当用户请求需要外部知识时,推理引擎直接在本地或最近的区域节点进行向量检索,获取相关上下文。
隐私数据不出域:原始的、敏感的文档或数据可以保留在企业本地,只将其生成的向量索引部署到边缘。这样,整个RAG过程都无需将原始敏感数据传输到公网,保障了数据主权与隐私合规。
异步汇总训练:只有经过脱敏和聚合的查询日志、检索结果等信息,才会被异步发送回中心云,用于模型的持续优化和再训练。
三、🛡️ 智能路由与全栈治理
分布式环境的复杂性远超单体数据中心。要让数千个边缘节点协同工作,一套强大的智能路由与全栈治理体系必不可少。
3.1 智能路由与服务编排
当一个请求到达时,系统必须决定由哪个节点、哪个模型来处理。这就是智能路由的核心。
上下文感知路由:路由决策不仅基于用户的地理位置(就近原则),还应考虑请求的具体内容、任务类型、当前各节点的负载情况、模型的版本等多种上下文信息。例如,一个通用的聊天请求可以由任何节点处理,而一个涉及特定领域知识的请求,则需要被路由到部署了相应微调模型的节点。
多模型网关:在边缘提供一个统一的API网关,后端可以接入多个不同的AI模型(无论是开源的、商业的还是自研的)。网关负责根据策略进行请求分发,支持A/B测试、灰度发布和蓝绿部署,方便模型的迭代与验证。
SLO驱动的弹性伸缩:基于预设的服务等级目标(SLO),如P99延迟、错误率等,对边缘的推理服务进行自动化的扩缩容。当监控到某个区域的延迟即将超出阈值时,编排系统会自动在该区域调度更多的推理实例。
3.2 安全与合规体系
将计算推向边缘,也意味着攻击面在扩大。因此,必须构建一个贯穿始终的、纵深的安全防护体系。
3.3 从MLOps到Edge AIOps
传统的MLOps流程主要围绕中心化的模型开发和部署。当AI走向分布式边缘时,运维的复杂性呈指数级增长,催生了Edge AIOps这一新领域。
Edge AIOps在MLOps的基础上,额外关注以下挑战:
异构环境管理:边缘节点硬件配置、网络环境千差万别。Edge AIOps需要能够管理和调度在不同硬件(GPU、CPU、NPU)上运行的模型版本。
分布式模型部署:需要支持对全球数千个节点进行模型的灰度发布、版本控制和一键回滚,并确保部署过程的原子性和一致性。
端到端可观测性:建立覆盖所有边缘节点的统一监控体系,采集**日志(Logging)、指标(Metrics)和追踪(Tracing)**数据,实时掌握全局服务的健康状况。
数据漂移监控:持续监控边缘节点输入数据的分布变化。一旦检测到数据漂移,系统可以自动告警,或触发模型的重新训练与更新。
策略化降级:在网络中断或节点故障等异常情况下,系统应具备自动降级能力。例如,从调用边缘模型降级为调用本地缓存,或切换到功能简化的备用模型,以保障核心服务的可用性。
四、📈 成本效益与性能量化
采用分布式边缘推理架构,不仅是为了追求极致性能,同样也是出于对总体拥有成本(TCO)的精细考量。
4.1 性能指标与目标
衡量边缘推理性能,不能只看平均延迟,而应关注一系列更严苛的指标,以确保用户体验的一致性和可靠性。
高百分位延迟 (P95/P99 Latency):代表了95%或99%的请求能够在该时间内完成。这是衡量系统在负载压力下表现稳定性的关键指标。对于“机器速度”级应用,P95延迟通常需要控制在50-100毫秒以内。
抖动 (Jitter):延迟的变化程度。对于实时音视频、AR/VR等交互应用,低抖动比低平均延迟更为重要。
吞吐量 (Throughput):单位时间内系统能够处理的请求数或生成的Token数。
可用性 (Availability):系统能够正常提供服务的时间比例,通常以“几个九”来衡量(如99.99%的“四九”或99.999%的“五九”)。
断网降级策略:明确在网络连接中断时,本地应用的行为模式。是完全失效,还是能够基于本地缓存或简化模型提供降级服务。
实践证明,通过将推理部署在边缘,响应速度可获得6-10倍的提升,P95延迟最高可降低5倍。
4.2 成本模型与TCO优化
边缘推理改变了传统的成本结构。虽然增加了边缘节点的硬件和运维投入,但它在其他方面带来了显著的成本节约。
优化的核心KPI也随之转变,从单纯关注计算成本,转向更综合的能效指标:
每百万Token成本:衡量处理单位语言任务的综合成本。
每请求时延:直接关联用户体验和业务机会。
能耗/Token:反映了计算的能源效率,是绿色计算的重要指标。
综合来看,边缘就地推理可将处理每百万Token的基础设施成本降低40-60%,实现了性能与成本的双赢。
五、🌍 典型应用场景与落地路径
%20拷贝.jpg)
分布式边缘推理并非遥不可及的未来技术,它已经在众多对实时性、隐私性要求严苛的行业中找到了具体的应用场景,并形成了一套可供参考的落地方法论。
5.1 典型应用场景剖析
5.2 实践落地路径
将边缘推理从概念引入到生产环境,需要一个系统性的、分阶段的实施过程。这不仅是技术部署,更是对业务流程和组织能力的重塑。
阶段一:评估与规划 (Assessment & Planning)
工作负载画像:首先要识别出哪些业务场景或应用模块是延迟敏感、数据敏感或带宽密集型的。分析其数据流、QPS、延迟要求等关键特征。
延迟预算(Latency Budget):为每个识别出的场景设定明确的端到端延迟目标(SLO),例如“99%的交易风控需在80ms内完成”。这是后续架构设计和技术选型的核心依据。
边缘拓扑评估:评估自身业务的用户地理分布,选择能够提供相应边缘节点覆盖的云服务商或自建边缘基础设施。绘制数据拓扑图,明确数据在何处产生、在何处处理。
阶段二:概念验证 (PoC - Proof of Concept)
小范围试点:选择一个代表性强、但风险可控的场景进行小范围PoC测试。例如,先在一个城市或一个工厂内部署边缘推理节点。
SLO验证:在真实或模拟的负载下,严格测试PoC环境是否能达到预设的SLO。收集详尽的性能数据,包括P95/P99延迟、吞吐量、资源利用率等。
技术栈选型:基于PoC的结果,最终确定模型优化方案、推理框架、硬件选型和运维工具链。
阶段三:分阶段部署与迭代 (Phased Rollout & Iteration)
灰度发布:不要试图一步到位。采用灰度发布策略,先将一小部分流量(如5%)切换到新的边缘推理架构上。
成本与性能复盘:在灰度期间,密切监控新架构的实际性能表现和成本开销,与旧架构进行对比。验证TCO模型是否准确,并根据实际情况进行调整。
逐步扩量:在确认系统稳定、效益符合预期后,逐步扩大流量比例,最终完成全量切换。
阶段四:规模化运营与治理 (Scale & Governance)
建立Edge AIOps体系:部署自动化的监控、告警、部署和回滚系统,提升大规模边缘节点的运维效率。
合规审计:定期进行安全和数据合规审计,确保边缘架构的运行始终符合相关法律法规的要求。
持续优化:将边缘推理视为一个持续演进的系统。根据业务发展,不断引入新的模型、优化路由策略、扩展节点覆盖,保持其技术领先性。
六、⚖️ 风险权衡与未来趋势
尽管分布式边缘推理前景广阔,但在实践中也面临着一系列独特的挑战。同时,技术本身也在不断演进,预示着未来的发展方向。
6.1 风险与权衡
部署边缘推理,意味着需要直面分布式系统固有的复杂性。
异构性与不确定性:边缘环境远非标准化。硬件(不同型号的GPU、CPU)、操作系统、网络状况(带宽、稳定性)都存在巨大差异。这要求模型和应用具备极强的环境适应性和鲁棒性。
一致性挑战:如何在数千个节点间保证模型版本、配置和向量索引的一致性,是一个巨大的工程挑战。更新过程中的短暂不一致,可能会导致服务行为异常。
缓存与数据新鲜度:边缘节点大量使用缓存来提升性能,但这带来了数据新鲜度的问题。需要在“极致性能”和“数据最新”之间做出权衡,并设计合理的缓存失效和更新策略。
跨域编排的复杂性:调度一个跨越多个云厂商、多个地理区域的复杂AI工作流,其编排和故障排查的难度远高于单一数据中心。
容错设计:必须预先设计好应对各种故障的预案。例如,当边缘节点与中心失联时,应有断点续传、离线任务队列、本地回退逻辑(如切换到功能简化的本地模型)等机制,确保服务的韧性。
6.2 未来技术趋势
分布式边缘推理的技术版图仍在快速扩张,未来几年,我们可以预见到以下几个重要趋势。
多智能体协同决策:未来,不再是单个AI模型在边缘运行,而是多个具备不同能力的AI智能体(Agent)在边缘节点上进行实时的信息交换、协商与协同决策。例如,在智慧交通中,代表不同车辆和交通信号灯的智能体在边缘进行“谈判”,动态优化路口通行效率。
隐私计算的深度融合:联邦学习(Federated Learning)、安全多方计算(SMC)等隐私计算技术将与边缘推理深度结合。模型训练和推理过程可以在不暴露原始数据的情况下完成,进一步强化隐私保护。
异构算力统一调度:随着DPU、NPU等专用芯片的普及,边缘节点的算力将更加异构。未来的调度系统需要能够智能地感知不同硬件的特性,将AI任务中最合适的子任务(如数据预处理、模型推理、网络处理)分别调度到CPU、GPU、DPU上执行,实现硬件资源的极致利用。
与5G/6G网络的协同:5G/6G网络提供的超低延迟、高带宽和网络切片能力,将为边缘推理提供理想的网络基础。网络切片可以为特定的AI应用(如远程手术)保障专用的网络资源,实现端到端的服务质量(QoS)保证。
“后训练”时代的定制化:随着基础大模型的能力趋于饱和,竞争的焦点将转向“后训练”阶段。企业将越来越需要在边缘,利用自己的私有数据对基础模型进行快速、低成本的微调(Fine-tuning),生成高度定制化的边缘模型,这构成了企业的核心AI竞争力。
结论
将AI推理搬到网络边缘,不是一次简单的技术升级,而是一场深刻的基础设施革命。它直面了集中式云计算在实时智能时代的核心痛点——延迟、隐私与成本。通过构建“中心云+边缘云”的协同新范式,并辅以模型工程、智能路由、Edge AIOps等一系列技术创新,分布式边缘推理正在为自动驾驶、智能制造、实时交互等前沿应用铺平道路。
当然,通往这个目标的路径并非坦途,它要求我们必须驾驭分布式系统固有的复杂性,并在性能、成本、安全之间做出精妙的权衡。但趋势已经明确,随着AI与物理世界的融合日益加深,计算必然会流向数据产生的地方。分布式边缘推理,正是承载这一历史进程的新一代基础设施,它将最终决定AI技术能否真正转化为无处不在、即时响应的现实生产力。
📢💻 【省心锐评】
边缘推理不是要干掉云,而是给云装上了“神经末梢”。它把AI的反应弧从“秒级”拉到“毫秒级”,让智能真正贴近现实。这是从“能用”到“好用”的关键一步。

评论