.png)


【摘要】一种基于第一性原理与长思维链(LCoT)的知识重构范式,旨在通过可验证的AI推理,构建一个系统化、可追溯的科学知识网络,解决当前知识获取的碎片化与可信度难题。
引言
信息获取的便利性,并未直接带来知识理解的深化。我们正处在一个矛盾的时代,一方面是信息洪流的冲击,另一方面是系统性、高信噪比知识的极度稀缺。传统的搜索引擎擅长索引“结论”,却常常隐去“过程”。维基百科等众包模式,在中文科学领域的内容深度与广度上,长期存在短板。
大语言模型的出现,曾被寄予厚望。它强大的生成能力看似能填补知识空白,但其固有的“幻觉”问题,以及对训练语料中“重结果、轻过程”特性的继承,使其难以成为构建严谨知识体系的可靠基石。知识的价值不仅在于“是什么”,更在于“为什么”以及“如何来”。当推理链条断裂,知识便退化为孤立的信息点,难以验证、传承与创新。
正是在这样的背景下,一个名为SciencePedia的项目进入了我们的视野。它没有选择对现有知识进行修补或转述,而是另辟蹊径,尝试从科学知识的源头——第一性原理出发,利用AI的推理能力,从头构建一个逻辑自洽、可追溯的科学知识宇宙。这不仅是对AI百科全书形态的一次探索,更可能是一场关于知识组织与呈现方式的底层变革。
一、 知识的困境与AI的破局之道
%20拷贝-oslb.jpg)
1.1 信息洪流中的“知识孤岛”现象
当前人类知识的存储与传播形式,无论是教科书、学术论文还是网络百科,都存在一个共性问题,即知识的高度压缩。为了传播效率,大量的中间推导过程、背景假设和跨学科联系被省略。这导致了严重的“知识孤岛”现象。
每个知识点看似独立存在,但其赖以成立的逻辑根基、以及与其他知识点的潜在关联,却变成了难以被搜索引擎发现的“知识暗物质”。这种状态带来三个直接后果。
难验证。无法追溯推理过程,就难以对知识的可靠性进行独立判断。
难理解。缺乏上下文和逻辑脉络,学习者只能死记硬背,无法形成深度认知。
难交叉。知识间的壁垒被加固,阻碍了跨领域的思想碰撞与创新。
1.2 大语言模型的双刃剑
大语言模型(LLM)在内容生成上的表现令人瞩目,但它本质上是一个基于海量语料的概率分布模型。这一特性决定了它的两大核心局限。
幻觉(Hallucination)。当模型在概率空间中找不到最优路径时,便会“创造”事实。对于需要绝对严谨的科学知识领域,这是致命的缺陷。
碎片化(Fragmentation)。LLM继承了训练数据中知识碎片化的特点。它可以流畅地解释一个概念,但当被追问其前置条件或深层逻辑时,往往会给出不一致或错误的回答。它擅长模仿“结论”,却不真正“理解”推理。
因此,直接使用通用大模型生成百科条目,无异于在沙地上建高楼。看似高效,实则根基不稳,无法构成一个可信赖的知识体系。
1.3 SciencePedia的破局思路
SciencePedia团队认识到,问题的根源在于知识的组织方式。要解决上述困境,必须从“整理”知识转向“重构”知识。其核心思路可以概括为两点。
以推理链为基本单元。不再将孤立的“知识点”作为知识库的最小单位,而是将包含完整逻辑推导过程的“思维链”作为核心。
从第一性原理出发。确保所有知识都建立在坚实的公理基础之上,通过一步步可验证的推理向上构建,形成一个逻辑上盘根错节、紧密相连的知识网络。
这一思路,旨在将AI的角色从一个模糊的“内容创作者”,转变为一个严谨的“逻辑推演者”。
二、 核心架构解析. 第一性原理驱动的知识生成体系
SciencePedia的实现并非依赖单一模型或技术,而是一套精心设计的、由多个智能体协同工作的自动化知识生成流水线。其技术内核是第一性原理与**长思维链(LCoT)**的深度结合。
2.1 理论基石. 第一性原理与还原论
SciencePedia的方法论根基是物理学中经典的第一性原理。简单说,就是把所有知识拆解到最基础、不证自明的公理层面,再一步步向上推演。这种还原论的思路,保证了知识体系的逻辑自洽与可追溯性。
与传统百科依赖人类专家撰写和编辑不同,SciencePedia试图让AI模拟科学研究的真实过程,即从公理和基本定义出发,通过演绎推理构建整个理论大厦。这从根本上改变了知识的生产范式。
2.2 技术实现. LCoT的涌现与应用
长思维链(Long Chain-of-Thought, LCoT)是大语言模型在经过特定训练(如强化学习)后涌现出的一种关键能力。它使得模型不再是简单地输出答案,而是能够生成一个详尽的、多步骤的推理过程。
SciencePedia团队的研究发现,LCoT恰好提供了连接“知识孤岛”的“桥梁”。通过系统性地生成和验证LCoT语料,可以有效弥补人类现有语料库“重结果、轻过程”的缺陷。这些经过校验的LCoT语料,不仅是知识库的主体,也是对抗AI幻觉的有力武器,因为每一步推理都有迹可循。
2.3 自动化构建流程. “苏格拉底问答智能体”
为了系统性地生成LCoT知识库,团队设计了一套自动化流程,其核心是“苏格拉底问答智能体”。这个智能体的工作模式,正如其名,是对知识点进行持续的、刨根问底式的诘问。
其工作流程可以通过以下Mermaid图清晰展示。
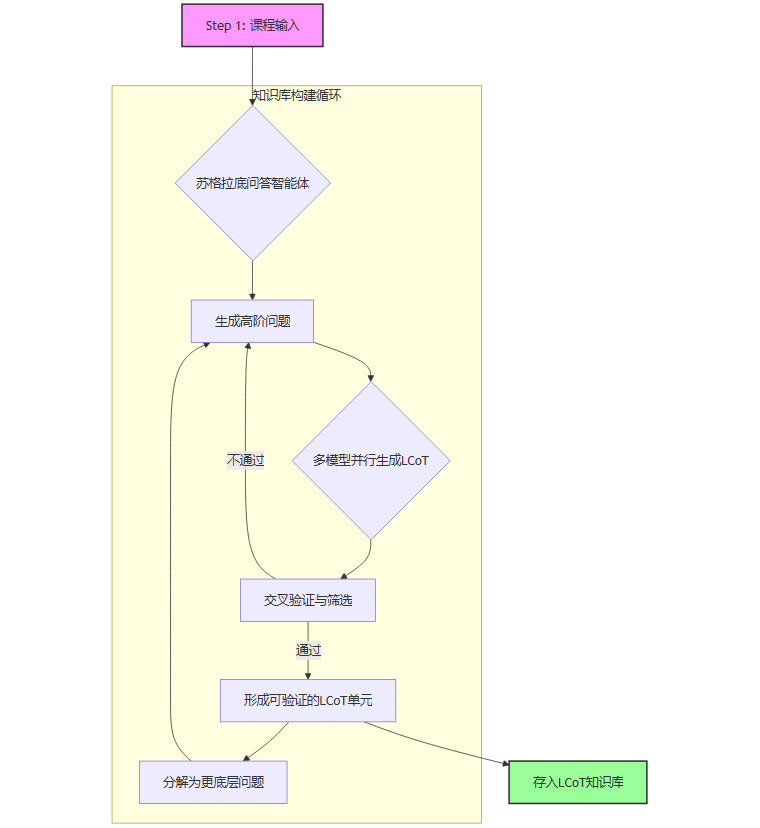
课程输入。流程始于约200门基础学科的核心课程大纲,作为知识探索的起点。
苏格拉底诘问。智能体自动将高层次的知识点(如“麦克斯韦方程组”)分解为一系列更基础的问题(如“什么是电场?”“什么是磁场?”“散度定理是什么?”)。
LCoT并行生成。针对每个问题,系统会调用多个独立的大语言模型,分别生成详细的LCoT推理路径。
交叉验证。系统会严格比对不同模型生成的答案和推理过程。只有那些逻辑一致、结论可相互印证的LCoT才会被采纳。这一步是保证内容质量、抑制模型幻觉的关键。
循环分解。一个被验证的知识点,其推理过程中涉及的更底层的概念,会成为新一轮诘问的对象,如此循环,直至所有知识点都被追溯到最基础的公理或定义。
入库存储。最终,所有经过验证的LCoT单元被存入知识库,形成一个庞大的、相互关联的推理网络。
通过这一自动化流程,SciencePedia生成了覆盖七大学科领域的近300万条高质量的科学推理链。
2.4 质量保障机制
除了自动化的交叉验证,SciencePedia还引入了“AI+人机协同”的双层校验体系。
AI层面。多模型、多轮次的生成与验证,确保了规模化生产的初步可靠性。
专家层面。项目团队联合了来自中国科学院、深势科技、兰州大学、北京大学等多家顶尖科研机构的专家学者,组建“SciencePedia社区委员会”,对AI生成的核心内容进行持续的专业校验与修订。
这种双层保障机制,试图在AI的生成效率与人类专家的严谨性之间找到一个平衡点,确保知识库的规模与质量同步增长。
三、 功能与应用. 从知识查询到创新发现
%20拷贝-oyym.jpg)
在庞大的LCoT知识库之上,SciencePedia构建了面向用户的应用层。其核心功能不再是简单的“搜索-呈现”,而是“探索-启发”。
3.1 逆向知识搜索引擎(Brainstorm)
这是SciencePedia最具颠覆性的功能。传统的搜索引擎是“正向”的,输入关键词,返回包含该词条的文档。而Brainstorm引擎实现了“逆向知识搜索”。
3.1.1 工作原理
用户输入一个科学概念(例如,“瑞利散射”),Brainstorm引擎会检索整个LCoT知识库,返回所有以“瑞利散射”为推理终点的思维链。
这意味着,用户不仅能看到“瑞利散射”是什么,还能看到。
它的来源。推导出它需要哪些前置知识(如电磁波理论、偶极子辐射等)。
它的应用。在哪些不同的学科领域中,它会作为关键一步出现(如解释“天空为什么是蓝色的”、光纤通信中的损耗分析等)。
3.1.2 应用场景
逆向搜索开辟了全新的应用场景。
深度学习。学生可以沿着推理路径追根溯源,真正理解一个公式或定理的来龙去脉,而不是停留在表面。
科学研究。科研工作者可以快速发现一个理论或工具在其他领域的潜在应用,激发跨学科创新的灵感。例如,一个研究凝聚态物理的学者,可能会发现他所用的某个数学工具,在计算金融领域也有着相似的逻辑结构。
知识溯源。在需要进行事实核查或学术考证时,可追溯的推理链提供了强有力的证据支持。
3.2 柏拉图写作智能体(Plato)
为了让高深的科学知识能够被更广泛的受众理解,团队还开发了“柏拉图写作智能体”。
3.2.1 “费曼风格”的科普转化
该智能体的任务,是将Brainstorm引擎找到的、充满专业术语的抽象推理链,自动改写为通俗易懂、贴近生活的科普文章。其写作风格被设定为费曼风格,即用最简单的语言解释最复杂的概念。
3.2.2 内容生成与幻觉抑制
与直接让大模型进行科普创作不同,“柏拉图”的写作严格受限于底层LCoT知识库的内容。它更像一个高水平的“翻译”和“组织者”,而不是一个自由的“创作者”。这种**“带着镣铐跳舞”**的模式,使其在保证文章生动可读的同时,极大地提升了知识点密度和事实准确性,有效避免了天马行空的AI幻觉。
3.3 知识库规模与覆盖范围
截至目前,SciencePedia已初具规模。
学科覆盖。涵盖数学、物理、化学、生物、工程、计算科学与天文七大基础科学领域。
条目数量。包含约20万个细粒度的知识条目。
推理网络。已构建300万条科学推理思维链。
配套资源。提供了超过10万道练习题,帮助用户巩固学习。
语言支持。初步实现了中英双语内容的均衡覆盖,这对长期缺乏高质量内容的中文科学社区尤为重要。
其线上应用“玻尔科学百科”已经开放体验,直观地展示了其系统化的知识结构。
四、 对比分析. SciencePedia vs. Grokipedia & 维基百科
要理解SciencePedia的独特性,有必要将其与马斯克推出的Grokipedia以及传统的维基百科进行对比。
通过对比可以看出,三者并非简单的替代关系,而是定位在不同生态位的知识产品。维基百科是人类知识的“最大公约数”,Grokipedia是AI时代信息摘要的“快速通道”,而SciencePedia则致力于成为科学知识的“逻辑骨架”和“推理引擎”。
五、 人机协同的未来. 构建开放的知识生态
%20拷贝-aqyv.jpg)
SciencePedia目前的工作,更像是培育了一颗“系统化客观知识体系的种子”。其长远发展,离不开一个开放、协作的生态。
5.1 “AI生成+专家校验”的双层模式
纯AI生成无法保证绝对的正确性,纯人工编辑又面临效率和覆盖度的瓶颈。SciencePedia探索的“AI负责规模化生成,专家负责精准校验”的人机协同模式,可能是未来高质量知识库构建的可行路径。AI为专家提供了高质量的“草稿”和“素材”,专家则为AI的工作设定了“护栏”和“天花板”。
5.2 从工具到平台. 开放社区的构想
项目团队的未来重心将转向开放的社区共建。
开放API/协议。计划推出上下文协议(MCP, Model Context Protocol)服务,允许开发者基于其LCoT知识库创作科普文章、科幻小说,甚至开发新的教育应用。
全球专家协作。希望与全球的专家学者共同组建社区委员会,持续扩展知识库的学科范围(如历史、经济、医药等),并协力开发在线课程、交互式学习工具等。
5.3 潜在挑战与发展路径
未来的发展也面临挑战。
处理争议性知识。当进入人文社科领域,如何处理不同学派、不同观点的争议性知识,将是对其方法论的重大考验。
维持社区活跃度。如何激励全球专家持续贡献,构建一个良性循环的社区生态,是所有开放项目的共同难题。
商业模式探索。如何在保持开放性和公益性的同时,找到可持续的商业模式,支撑其长期发展。
结论
SciencePedia项目向我们展示了一种应对信息时代知识挑战的新范式。它没有停留在对现有信息的浅层处理,而是回归知识的本源,利用AI的推理能力,试图重构一个逻辑严密、可供探索的科学知识体系。
从“知识点”到“推理链”,从“正向搜索”到“逆向探索”,它不仅为科学研究、教育和跨学科创新提供了一种强大的新工具,也为我们思考“AI for Science”的未来方向提供了重要启示。横向解决不同领域的通用问题,构建知识的基础设施,或许正是大模型时代赋予我们的新机遇。
这项工作目前只是一个起点,但它所代表的方向——追求知识的可验证性、系统性和深度关联性——无疑为我们在被海量信息淹没的时代,重新找到对客观知识的深度理解,提供了一种极具潜力的可能性。
📢💻 【省心锐评】
SciencePedia的核心不是AI“写”百科,而是AI“推演”知识。它用第一性原理对抗模型幻觉,用推理链对抗知识碎片化,这才是构建下一代知识基础设施该有的样子。

评论