.png)


【摘要】一种名为Social-MAE的多感官AI系统,通过融合分析连续视频帧与音频,在无大量标注数据下自主学习人类情感。该系统在情感识别、笑声检测及性格分析任务中刷新业界记录,为智能教育、医疗等领域开辟了新路径。
引言
人类的情感交流,是一场精心编排的音乐会。我们不仅用语言传递信息,更通过面部表情的起伏、语调的变化,同时演奏着多种“乐器”。当你向朋友分享喜悦时,绽放的笑容与愉悦的声音相互呼应,让情感的表达变得真实可信。但是,让计算机像人类一样,同时理解面部表情和声音信息,一直是科学家们面临的重大挑战。单一模态的情感识别,鲁棒性并不足够。例如,面部表情容易被遮挡,语音也容易受到噪声干扰。因此,利用多通道信息之间的互补性,来提升识别准确率就显得至关重要。
想象一下,如果有一位“超级观察员”,能够同时关注一个人的面部表情和声音变化,并且能准确判断这个人的情绪状态、是否在笑,甚至预测他们的性格特征。这听起来像是科幻电影里的情节。但比利时蒙斯大学和美国南-加州大学的研究团队,却将这个想法变成了现实。
他们联合开发了一个名为Social-MAE的人工智能系统,它就像一个具备超强观察力和理解力的“情感侦探”。这个系统的特别之处在于,它不仅能看懂人的面部表情,还能听懂声音中蕴含的情感信息。更重要的是,它能将这两种信息巧妙地结合起来,形成对人类情感和社交行为的准确判断。
这项研究的核心创新,在于解决了一个长期困扰科学家的问题,那就是如何让人工智能在没有大量标注数据的情况下,自主学习人类的情感表达模式。传统的方法,需要研究人员手工标注大量的音频和视频数据,告诉计算机“这是开心的表情”、“这是悲伤的声音”。这个过程既费时又费力。而Social-MAE采用了一种称为“自监督学习”的巧妙方法,让AI系统像一个好学的学生,通过大量观察真实的人际交流视频,自己总结出情感表达的规律。
这项由比利时蒙斯大学Numediart研究所的Hugo Bohy团队与美国南加州大学创意技术研究所的Mohammad Soleymani教授合作完成的研究,发表于2024年第18届国际自动人脸与手势识别会议(FG)。研究团队也开放了完整的代码和模型,有兴趣的读者可以通过GitHub链接 https://github.com/HuBohy/SocialMAE 访问。
一、📚 AI学会“读人”的秘密武器
%20拷贝.jpg)
1.1 多感官融合与自监督学习的魔力
Social-MAE的工作原理,就像训练一个多才多艺的表演者。这个AI系统基于一种叫做**“掩码自编码器”(Masked Autoencoder, MAE)**的学习方法。你可以把它比作一个高难度的“填空游戏”。MAE是一种为计算机视觉设计的可扩展自监督学习方法,其核心思想是随机遮挡输入图像的大部分区域,然后训练模型来重建这些缺失的像素。
研究团队故意遮挡视频中的部分画面或音频片段,然后让AI系统根据剩余的信息来“猜测”被遮挡的内容。通过无数次这样的练习,AI逐渐掌握了人脸表情与声音之间的对应关系。这个过程就像教孩子认识情绪表达一样。当孩子听到妈妈温柔的声音时,他们会期待看到妈妈慈爱的笑容;当听到爸爸严厉的语调时,他们知道爸爸的表情可能比较严肃。Social-MAE正是通过类似的方式学习这些对应关系,但它的学习能力远超人类,能同时处理成千上万个这样的“情感片段”。
这种自监督学习方法的最大优势在于,它无需大量昂贵的人工标注。通过“填空游戏”式的训练,AI自动掌握了人类情感表达的内在规律,显著降低了数据标注的成本和时间。
1.2 创新的“中期融合”架构
传统的多模态方法通常采用“后期融合”策略。这种策略会分别处理音频和视频信息,最后再简单地将结果合并。这就像两个独立工作的专家,直到最后才交流意见,往往会错过音视频之间那些细微的对应关系。
Social-MAE则采用了更先进的**“中期融合”**策略。它让音频和视频信息在处理过程中就开始“对话”,在特征提取的早期阶段就让两种模态的信息深度交互。这种融合方式极大地提升了情感识别的准确性和鲁棒性,尤其在单一模态受到遮挡或噪声干扰时,表现得尤为突出。
系统的架构设计也体现了这种创新思路。具体来说,模型将不同模态的数据转换到一个统一的特征空间中进行处理,便于后续的比较和交互。
音频处理:音频信息首先被转换为128维的对数梅尔频谱特征,然后被切分成若干个16×16的小块。每个小块随后被线性投射,变成一个768维的特征向量。
视频处理:对于视觉信息,系统会从8个连续的关键帧中提取2×16×16的图像块,同样地,这些图像块也被投射成768维的特征表示。
我们可以用一个表格来清晰地总结这个过程。
这种统一的特征表示,使得不同模态的信息能够在同一个高维空间中进行有效的比较和融合,为深度的跨模态理解奠定了基础。
1.3 捕捉时间的艺术:动态建模
人类的情感表达是一个动态过程,而非静止的画面。一个完整的笑容,包括嘴角上扬、眼部收缩、面颊抬升等一系列连续动作。语调从平缓到激昂,这些变化都承载着丰富的情感信息。
Social-MAE深刻理解这一点。它并非分析一张静态的图片,而是像观看一部微型电影一样,连续处理8个视频帧,从而捕捉表情和语调的动态变化。这一设计使其能精准识别如微笑、皱眉等快速变化的情感信号,其能力远超那些依赖单帧分析的系统。
这种多帧处理能力,使得Social-MAE在理解快速变化的面部表情方面表现出色。人类的表情变化往往非常迅速,比如眨眼间的微笑、瞬间的皱眉。这些细微但重要的变化,很容易被单帧分析方法遗漏。而Social-MAE通过同时分析多个连续帧,就像一个高速摄影师,能够捕捉到这些转瞬即逝的表情细节。
1.4 专注的力量:领域自适应预训练
与许多在通用音视频数据集(如AudioSet)上预训练的模型不同,Social-MAE走了一条更专注的道路。它直接在VoxCeleb2这个大型真实社交场景数据集上进行预训练。这意味着模型从一开始就专注于学习与人类社交行为紧密相关的特征模式。
这种领域特化的训练,让模型在后续的情感识别、笑声检测、性格分析等任务中表现得异常优异。它更适应真实、多元的社交互动环境。事实证明,“术业有专攻”的道理在AI训练中同样适用。专门针对特定应用场景训练的模型,往往能够取得比通用模型更好的效果。
二、🎓 AI的“社交课堂”:VoxCeleb2数据集
2.1 一本包罗万象的“社交百科全书”
为了训练Social-MAE,研究团队选择了VoxCeleb2这个庞大的数据集作为AI的“教科书”。这个数据集是语音识别和说话人验证领域的黄金标准之一。它就像一个包罗万象的社交百科全书,收录了来自全球145个国家、超过6000位说话者的100多万段音视频对话。
这些对话涵盖了不同的语言、口音、种族和年龄群体,为AI提供了一个真实且多元的学习环境。选择VoxCeleb2的重要性不言而喻。正如学习一门语言需要在真实的语言环境中浸泡一样,AI学习人类情感表达也需要接触真实的社交场景。这些视频不是在实验室里精心拍摄的标准化样本,而是来自现实生活的真实记录。它们包含了自然的光照变化、背景噪音,以及人们在真实社交环境中的自然表现。
2.2 严苛的“藏猫猫”训练法
在训练过程中,研究团队采用了一种巧妙且严苛的“藏猫猫”策略。他们会随机遮挡75%的音频和视频内容,只给AI系统展示剩余的25%信息,然后要求它重构出完整的原始内容。
这种高比例的掩码策略,能够有效消除数据中的冗余信息。它迫使模型必须深度理解音频和视频之间的内在联系,去学习高层次的语义信息,而不是简单地记忆表面特征。这个训练过程经历了25个完整的学习周期,就像一个学生反复学习同一本教科书25遍,每一次都能发现新的细节和规律。
随着学习的深入,AI系统逐渐从最初的“瞎猜”,发展到能够准确预测被遮挡的内容。这标志着它对人类情感表达规律的理解越来越深刻。
2.3 令人信服的“毕业考试”
训练完成后,研究团队对Social-MAE进行了一场“毕业考试”。他们用从未见过的视频数据来测试系统的重构能力。结果显示,AI能够令人信服地重建出被遮挡的面部区域。
虽然在处理快速变化的面部区域,特别是眼部和嘴部时,仍然存在一些微小的误差,但整体表现已经达到了非常实用的水平。这证明了模型不仅学会了记忆,更学会了基于上下文进行推理和生成。
三、🏆 三场实战考验:AI的社交技能认证
%20拷贝.jpg)
训练完成的Social-MAE随即面临三场重要的实战考验。每一场都测试着它在不同社交场景下的表现能力。这些测试就像是AI系统的“社交技能认证考试”,涵盖了情感理解、行为识别和性格分析等多个维度。
3.1 考验一:情感识别(CREMA-D数据集)
第一场考验发生在CREMA-D情感数据集上。这个数据集包含了91位专业演员表演的7442个情感片段。演员们分别用愤怒、厌恶、恐惧、快乐、悲伤和中性六种情绪,说出12个不同的句子。这就像一个情感表演的“标准化考试”,要求AI准确识别出每一种情绪状态。
结果令人振奋。Social-MAE在这场考试中表现出色,达到了83.7%的综合准确率,超越了之前所有的同类系统,刷新了业界记录。
更重要的是,它在处理数据不平衡的情况下表现稳定。在CREMA-D数据集中,中性情绪的样本有2204个,而悲伤情绪只有763个。这种不平衡很容易导致模型偏向于频繁出现的类别。然而,Social-MAE的微平均F1分数和宏平均F1分数非常接近(分别为83.7%和84.2%)。这表明模型对所有情绪类别都保持了相对均衡的识别能力,真正理解了情绪表达的本质规律,而不是简单地依赖数据量取胜。
3.2 考验二:性格分析(First Impressions数据集)
第二场考验转向了更具挑战性的性格特征分析。测试使用了包含1万个真实对话视频的First Impressions数据集。这些视频平均长度为15秒,需要AI根据短暂的观察,就判断出说话者的五大性格特征(Big Five Personality Traits)。
这就像要求AI成为一个经验丰富的心理学家,仅通过简短的交流就能洞察他人的性格特点。
在这场测试中,Social-MAE达到了90.3%的平均准确率。虽然这个结果略低于某些专门为该任务优化的基准系统,但考虑到Social-MAE的训练时间更短、数据需求更小,这个结果仍然相当出色。
一个有意思的发现是,多帧处理版本的Social-MAE在五个性格维度中的四个都超过了单帧版本。这再次证明了捕捉时间动态信息对于性格分析的重要价值。人的性格并非体现在某一瞬间的表情,而是展现在一段时间内的言行举止之中。
3.3 考验三:笑声与微笑检测(NDC-ME数据集)
第三场考验聚焦于一个非常具体的社交行为,笑声和微笑检测。测试使用了NDC-ME数据集的8352个短片段。这些片段来自真实的道德情感对话,每个片段仅持续1.22秒。这要求AI在极短时间内,识别出说话者是否在微笑或大笑。
这种检测任务看似简单,实际上极具挑战性,因为笑容和笑声的表现形式非常多样化,且持续时间很短。
Social-MAE在这项任务中取得了77.6%的准确率,再次刷新了该任务的最好成绩。特别令人印象深刻的是,多帧视觉处理带来的改善效果在这里最为明显。单模态视觉识别的准确率,从单帧版本的62.9%跃升至多帧版本的72.8%,增幅接近10个百分点。这个显著的提升清楚地证明了研究团队的假设,笑容不是静态的,而是一个动态展开的过程,必须通过时序信息才能准确捕捉。
四、💡 技术创新的三重突破
Social-MAE的成功,源于三个关键的技术创新。每一个都解决了现有方法的重要局限。这些创新就像三把钥匙,分别打开了多模态学习、时间动态建模和领域适应性的技术大门。
4.1 突破一:从“事后诸葛”到“同步协作”的多模态融合
如前所述,Social-MAE采用的“中期融合”策略,是其核心优势之一。我们可以用一个流程图来更清晰地理解它与传统方法的区别。
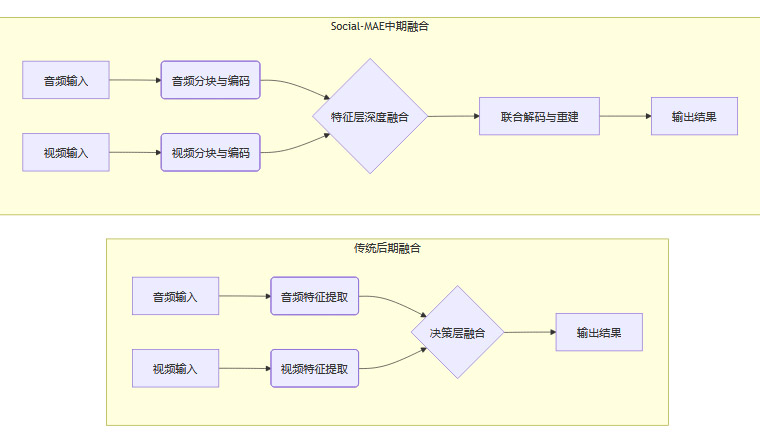
这个流程图清晰地显示,后期融合更像是两个独立的流水线最后汇合,而中期融合则是在加工的早期阶段就将原材料混合在一起,共同塑造最终的产品。这种“同步协作”的方式,能够更好地捕捉两种模态之间复杂的交互关系。
4.2 突破二:从“照片”到“电影”的时间动态建模
人类的情感表达具有明显的时间特性。许多现有系统只分析单个静态帧,就像试图通过一张照片去理解一部电影的情节一样,难免会遗漏重要的信息。
Social-MAE通过同时处理8个视频帧,实现了从“照片”到“电影”的跨越。它能够捕捉到情感在时间维度上的演化过程。这个突破对于理解那些转瞬即逝或逐渐展开的情感至关重要,比如一个从矜持到灿烂的微笑,或是一次从平静到愤怒的语调变化。
4.3 突破三:从“通才”到“专才”的领域自适应预训练
大多数现有的音视频模型,都是在通用数据集上预训练的。这些数据集虽然规模庞大,但内容包罗万象,从动物叫声到乐器演奏,与人类社交行为的特定需求存在领域差异。这就好比让一个学习了《百科全书》的学生,去参加一场专业的心理学考试。
Social-MAE则不同,它直接在VoxCeleb2这个社交“专科”数据集上进行预训练。这使得模型从一开始就专注于学习与人类社交行为相关的特征模式,成为一个名副其实的“社交行为分析专家”。在所有三个下游任务的测试中,Social-MAE都显著超越了在通用数据集上预训练的基线模型,有力地证明了这种“专才”策略的有效性。
五、🔬 严谨的实验设计
%20拷贝.jpg)
在人工智能研究领域,一个出色的模型固然重要,但一个严谨、科学的实验设计更是其价值的试金石。它确保了研究结论的可靠性,排除了偶然因素,并清晰地揭示了性能提升的真正来源。Social-MAE的研究团队在这一点上,展现了卓越的科学素养和巧妙的对比策略。他们的实验设计,不仅仅是为了证明模型“有效”,更是为了回答一个更深层次的问题,“为什么有效”。
5.1 对照的艺术:精准剥离性能增益的来源
评估一个新模型时,最常见的做法是将其与现有的最佳方法(State-of-the-Art, SOTA)进行比较。Social-MAE确实这样做了,并且在多个任务上取得了领先。但研究团队并未止步于此。他们深知,一个全新的架构融合了多种创新,如果只进行外部比较,很难说清究竟是哪个部分贡献了最大的力量。
为了解决这个问题,他们精心设计了一组消融实验(Ablation Study)。这是一种在科学研究中至关重要的验证方法。你可以把它想象成检修一辆高性能赛车。工程师不会只看它跑得多快,而是会尝试拆掉涡轮增压器、换上普通轮胎,来分别测试每个部件对整体速度的贡献。
研究团队的“赛车”就是Social-MAE,而他们拆解对比的参照物,就是一个特意训练的对照版本——CAV-MAE。
CAV-MAE:这个模型是Social-MAE的基础架构,但它在训练和测试时,只处理单个视频帧,而不是连续的8帧。
训练设置:除了帧数不同,CAV-MAE的训练设置,包括使用的数据集、训练周期等,都与Social-MAE完全相同。
这种设计堪称精妙。通过将Social-MAE与CAV-MAE进行直接对比,研究人员能够像外科手术一样,精准地剥离出由**“多帧时间动态建模”**所带来的性能增益。
实验结果清晰地印证了多帧处理的巨大价值。
在笑声检测任务中,这个优势体现得淋漓尽-致。单模态视觉识别的准确率,从单帧版本的62.9%戏剧性地跃升至多帧版本的72.8%。这接近10个百分点的巨大增幅,无可辩驳地证明了捕捉表情的动态过程,对于识别笑容这种短暂而连续的行为是多么关键。
在性格分析任务中,多帧版本的Social-MAE在五个性格维度中的四个都超过了单帧版本。这说明,一个人的性格特质,更多地体现在一段时间内的连续行为模式中,而不是孤立的某个瞬间。
这种严谨的对照实验,让“时间动态建模”的有效性不再是一个模糊的推论,而是一个由坚实数据支撑的科学结论。它准确地告诉我们,Social-MAE的强大,很大程度上源于它学会了像看“电影”一样去理解人类,而不是像看“照片”那样。
5.2 标尺的选择:超越准确率的深度评估
评价模型性能的另一个关键,在于选择正确的“标尺”,也就是评估指标。在不同的任务中,简单的分类准确率(Accuracy)往往会掩盖问题的真相。研究团队根据每个任务的特性,选择了最能反映模型真实能力的评估指标。
5.2.1 情感识别中的平衡之术:F1分数的深意
在CREMA-D情感识别任务中,一个显著的挑战是数据不平衡。例如,“中性”情绪的样本数量远多于“悲伤”情绪。如果只看总体准确率,一个只会“猜”中性情绪的“懒惰”模型,也能得到一个看似不错的分数。
为了避免这种陷阱,研究团队采用了F1分数作为主要评估指标,并且同时考察了微平均F1(Micro-F1)和宏平均F1(Macro-F1)。
微平均F1:它将所有类别的预测结果汇总在一起计算,因此更容易受到样本量大的类别的影响。
宏平均F1:它会分别为每个类别计算F1分数,然后取算术平均值。这意味着,无论样本多少,每个类别都具有同等的权重。
Social-MAE的微平均F1分数为83.7%,宏平均F1分数为84.2%。这两个数值非常接近,这是一个极其重要的信号。它表明,Social-MAE并不仅仅擅长识别样本多的情绪,它在识别“悲伤”、“恐惧”这类稀有情绪时,同样表现出色。模型学会了对所有情绪类别的均衡表示,这对于需要关注少数但关键情绪的应用场景(如心理健康监测)来说,价值非凡。
5.2.2 性格分析中的精度衡量:平均绝对误差(MAE)
对于性格分析这类任务,其输出不是一个非黑即白的分类(比如“是外向”或“不是外向”),而是一个连续的分数值。在这种情况下,使用分类准确率是不合适的。
因此,研究团队明智地选择了平均绝对误差(Mean Absolute Error, MAE)作为评估指标。MAE衡量的是模型预测值与真实值之间差值的绝对值的平均数。这个指标能更精确地反映模型预测的偏离程度。MAE值越低,说明模型的预测越接近真实情况。
实验结果显示,Social-MAE在五个性格维度上的表现都相对均衡,没有出现某个维度预测得特别准,而另一个维度错得离谱的情况。这说明模型学到的是对人类性格的全面、整体的表示,而不是对某个单一特质的片面理解。
通过这些精心选择的实验设计和评估指标,Social-MAE的研究不仅展示了一个强大的模型,更提供了一套令人信服的、可复现的科学证据。它让每一个结论都立得住脚,为后续的研究者和开发者铺平了一条坚实的道路。
六、🚀 从实验室到现实世界的广阔前景
Social-MAE的成功,不仅仅是一个技术上的突破。更重要的是,它为多个现实应用领域开启了新的可能性。这些应用前景就像已经种下的种子,未来可能在多个领域开花结果,深刻改变我们与技术互动的方式。
智能教育
Social-MAE可以发展成为智能的学习伴侣。系统能够通过观察学生的面部表情和声音变化,实时判断他们的学习状态,是专注投入、感到困惑,还是已经厌烦疲倦。基于这些信息,智能教学系统可以自动调整教学节奏、改变解释方式,或者建议适当的休息时间。这种个性化的教学反馈机制,将大大提升学习效率。医疗健康
这个领域同样充满潜力。Social-MAE可以协助医生进行心理健康评估,通过分析患者在面谈过程中的情绪表达模式,辅助诊断抑郁症、焦虑症等心理疾病。对于自闭症谱系障碍的儿童,系统可以帮助家长和治疗师更好地理解孩子的情绪状态,提供更精准的干预建议。人机交互
Social-MAE将推动更加自然和智能的交互界面发展。未来的智能助手,将不再只是执行指令的工具,而是能够感知用户情绪、适应交流风格的伙伴。当用户感到沮丧时,系统会调整回应的语调,变得更加温和;当用户显得急躁时,系统会提供更简洁直接的回复。客户服务
客户服务行业也将受益于这项技术。智能客服系统可以实时监测客户的情绪变化,在客户表现出不满或愤怒的早期信号时,及时调整服务策略或将对话转接给人工客服。这种情绪感知能力,将显著提升客户满意度,减少服务冲突的发生。内容创作与娱乐
在内容创作和娱乐产业,Social-MAE可以用于自动化的内容审核和推荐。系统能够理解视频内容中人物的情绪表达,为内容打上更精确的标签,从而实现更智能的个性化推荐。对于视频创作者来说,系统还可以提供关于情感表达效果的即时反馈,帮助他们优化表演和制作质量。
七、🚧 面临的挑战与未来方向
%20拷贝.jpg)
尽管Social-MAE取得了显著的成果,但研究团队也坦诚地指出了当前技术的局限性。这些局限为未来的研究方向指明了道路。正如任何突破性技术都需要不断完善一样,Social-MAE也面临着一些需要解决的挑战。
7.1 文化与个体差异的挑战
虽然VoxCeleb2数据集已经包含了来自145个国家的说话者,但不同文化背景下的情感表达方式,仍然存在细微的差别。一个在西方文化中被认为是友好的微笑,在某些东方文化中可能被解读为礼貌但疏远。模型需要进一步优化,以适应这种全球范围内的文化多样性。
7.2 极端与边界案例的处理
在重构测试中,系统在处理快速变化的面部区域,特别是眼部和嘴部时,仍存在一定的误差。这些区域恰恰是情感表达最关键的部位,任何细微的错误都可能影响最终的判断准确性。提升对这些细微情感信号的捕捉能力,是未来需要攻克的难关。
7.3 计算效率与可解释性
多帧多模态处理对计算资源的要求相对较高。要在移动设备或边缘计算环境中部署这样的系统,需要进行进一步的模型压缩和优化工作。
另一个重要的发展方向是增强模型的可解释性。目前的Social-MAE虽然能够准确识别情感和行为,但其内部决策过程对人类来说,仍然是一个“黑盒”。研究团队正在开发可视化工具,让用户能够理解模型是基于哪些线索做出判断的。这对于医疗、教育等对可靠性要求较高的应用场景,尤为重要。
7.4 未来的发展蓝图
研究团队已经开始规划未来的改进方向。
扩大数据多样性:计划扩大训练数据的规模和多样性,特别是增加更多非英语语言和不同文化背景的样本。
探索高效架构:探索更高效的网络架构,希望在保持性能的同时,降低计算开销,实现轻量化、实时化部署。
深化可解释性研究:持续深化模型可解释性研究,提升用户对模型决策的理解和信任。
总结
Social-MAE的出现,标志着多模态情感识别技术迈入了一个新的时代,一个更接近“读心术”的时代。它的多模态融合、动态建模和领域自适应三大创新,不仅推动了学术前沿,也为教育、医疗、人机交互等行业带来了切实可行的智能化解决方案。
说到底,Social-MAE代表了人工智能在理解人类情感和社交行为方面的一个重要里程碑。这项研究不仅在技术层面取得了突破,更重要的是,它为人工智能与人类的和谐共处开辟了新的可能性。未来,随着技术的持续完善和应用场景的扩展,我们有理由期待一个更加智能、更加人性化的数字世界。
研究团队已经开源了他们的代码和模型权重。这意味着全球的研究者和开发者,都可以在此基础上进一步创新。正如一句古话所说,“一花独放不是春,百花齐放春满园”。只有通过开放合作,这项技术才能真正实现其改变世界的潜力,推动AI与人类社会的深度融合。
📢💻 【省心锐评】
Social-MAE的突破,在于它不再满足于“看图说话”,而是学会了“察言观色”。它将AI对人的理解从静态快照推向了动态连续剧,这才是通往真正情感智能的关键一步。

评论