.png)
%20%E6%8B%B7%E8%B4%9D-kegh.jpg)

【摘要】人工智能与分子模拟技术结合,成功识别并验证了疱疹病毒入侵细胞所需的单一关键氨基酸,为开发高特异性、低副作用的精准抗病毒药物提供了全新靶点与研发范式。
引言
在与病毒的漫长斗争中,人类药物研发的历程始终伴随着两大核心挑战:效率与精度。传统的药物筛选模式,常被喻为“广撒网”,依赖于对海量化合物库的高通量筛选,其过程不仅耗时漫长、成本高昂,且成功率极低。更重要的是,这种模式下诞生的药物,往往难以避免“脱靶效应”,在攻击病毒的同时,也可能误伤宿主细胞,引发一系列副作用。
近年来,计算科学的崛起,特别是人工智能(AI)与分子动力学模拟的深度融合,正从根本上重塑药物研发的逻辑。我们不再仅仅依赖于物理世界的试错,而是能够在数字孪生的虚拟空间中,以前所未有的精度和速度,洞察生命活动的微观机制。近期,华盛顿州立大学(WSU)团队发表于《Nanoscale》期刊的研究成果,正是这一技术浪潮中的一个标志性事件。他们利用AI,成功从疱疹病毒入侵细胞的复杂分子网络中,精准地“揪出”了一个决定成败的单一氨基酸。这一突破不仅为抗击疱疹病毒带来了新的希望,更重要的是,它揭示了一种全新的、由AI驱动的“精确制导”式药物研发范式,预示着一个更智能、更高效的抗病毒新时代的到来。
🧬 一、 病毒入侵的分子战场:传统研究的困境与挑战
%20拷贝-uwsj.jpg)
要理解WSU这项研究的突破性,我们必须首先深入病毒入侵的微观战场,并审视传统研究方法在此面临的巨大障碍。病毒的生命周期始于一个关键动作——成功进入宿主细胞。这个过程远非简单的物理接触,而是一场精心编排的、涉及多步分子互作的精密“登陆作战”。
1.1 病毒融合蛋白:入侵细胞的“万能钥匙”
病毒自身不具备完整的生命系统,其生存与繁殖完全依赖于宿主细胞。为了将自身的遗传物质(DNA或RNA)送入细胞内部,病毒进化出了一套高效的入侵机制。其中,位于病毒包膜表面的**融合蛋白(Fusion Protein)**扮演了“万能钥匙”的角色。
以本次研究的主角——疱疹病毒为例,其入侵过程大致可分为以下几个步骤:
附着(Attachment):病毒首先通过其表面的糖蛋白与宿主细胞膜上的特定受体结合,像船只停靠码头一样,完成初步定位。
进入(Entry):结合后,一系列构象变化被触发,促使病毒包膜与细胞膜相互靠近。
膜融合(Membrane Fusion):这是最关键的一步。病毒的融合蛋白发生剧烈的结构重排,像一根弹簧被释放,其疏水性的融合肽段会插入宿主细胞膜中,然后通过折叠将两层膜拉近,最终迫使它们融合成一个孔道。
释放(Release):融合孔道形成后,病毒的衣壳(包含遗传物质的核心结构)便可通过该通道进入细胞质,完成入侵。
在这个过程中,融合蛋白的构象变化是驱动膜融合的核心动力。这个蛋白本身是一个复杂的分子机器,由成百上千个氨基酸折叠而成。它的每一个微小动作,都受到其内部以及与外部环境间无数分子间相互作用力的精细调控。
1.2 复杂性壁垒:为何传统方法举步维艰
传统生物学研究在面对融合蛋白这样一个复杂的系统时,遇到了难以逾越的“复杂性壁垒”。
1.2.1 组合爆炸问题
一个典型的融合蛋白可能包含数百个氨基酸残基。这些氨基酸之间通过氢键、盐桥、范德华力等多种方式相互作用,形成一个动态而稳定的三维结构。如果要研究哪个氨基酸或哪对相互作用对融合功能至关重要,理论上需要分析的组合数量是天文数字。例如,仅考虑两两之间的相互作用,一个包含500个氨基酸的蛋白,其潜在的相互作用对就高达 C(500, 2) = 124,750 种。
传统实验方法,如定点突变(Site-directed Mutagenesis),一次只能验证一个或少数几个氨基酸位点的功能。面对数以万计的可能性,逐一进行实验验证无异于“大海捞针”,在时间和成本上都是不现实的。
1.2.2 动态过程的观测难题
膜融合是一个发生在毫秒到秒级时间尺度、纳米级空间尺度的瞬时动态过程。传统的结构生物学技术,如X射线晶体学或冷冻电镜(Cryo-EM),虽然能解析出蛋白质在某个稳定状态下的高分辨率三维结构,但很难捕捉到其在功能执行过程中的连续动态变化。这就好比我们只有一张汽车静止时的照片,却要推断出其发动机内部所有零件在高速运转时的协同工作机制,难度可想而知。
1.3 “广撒网”式药物研发的局限
面对上述困境,传统的抗病毒药物研发,特别是早期筛选阶段,很大程度上依赖于高通量筛选(High-Throughput Screening, HTS)。这种方法将成千上万种小分子化合物与病毒或受感染的细胞进行反应,通过观察是否能抑制病毒活性来寻找潜在的候选药物。
这种“广撒网”的模式存在明显的局限性:
低命中率:绝大多数化合物都是无效的,找到一个有潜力的先导化合物的概率极低。
机制不明:即使找到了一个有效的化合物,其具体作用靶点和分子机制也往往是未知的“黑箱”,需要后续大量实验去阐明。
脱靶效应与副作用:由于筛选过程的盲目性,找到的药物分子可能不仅作用于病毒靶点,还会与人体内其他相似的蛋白相互作用,即脱靶效应。这是导致药物副作用的主要原因。
耐药性问题:如果药物作用的靶点并非病毒生存所必需的、且容易发生变异,病毒很快就会通过突变演化出耐药性,导致药物失效。
正是这些根植于方法论层面的瓶颈,使得抗病毒药物的研发周期漫长且充满不确定性。而WSU的研究,则为我们展示了如何利用计算的力量,精准地绕过这些障碍。
🖥️ 二、 AI驱动的范式革命:从“大海捞针”到“精确制导”
华盛顿州立大学的研究团队所引领的,是一场从实验试错到计算预测的范式革命。他们将人工智能,特别是机器学习,与经典的计算生物学工具——分子动力学模拟相结合,将寻找关键靶点的过程从“大海捞针”转变为“精确制导”的导弹式攻击。
2.1 计算生物学基石:分子动力学模拟
在AI介入之前,我们需要一种方法来“看见”蛋白质的动态行为。分子动力学(Molecular Dynamics, MD)模拟就是实现这一目标的强大工具。
MD模拟的原理基于牛顿力学。它将蛋白质中的每一个原子都视为一个质点,通过计算原子间的相互作用力(由力场函数描述),来求解原子在时间序列上的运动轨迹。简单来说,它能在计算机中生成一部蛋白质活动的“高清分子电影”,让我们能够观察到:
蛋白质的柔性与构象变化。
氨基酸残基之间的瞬时相互作用。
蛋白质与水、离子或其他分子(如药物分子)的相互作用过程。
在WSU的研究中,研究人员首先构建了疱疹病毒融合蛋白的原子级三维模型,然后通过MD模拟,获得了该蛋白在接近并准备与细胞膜融合过程中的大量动态轨迹数据。这些数据包含了数千个氨基酸之间在不同时间点的相互作用信息,构成了一个极其复杂的高维数据集。
2.2 机器学习的角色:在高维数据中发现模式
MD模拟产生了海量数据,但数据本身并不能直接告诉我们哪个氨基酸最重要。这时,**机器学习(Machine Learning, ML)**便登上了舞台。它的核心任务是在这些看似杂乱无章的高维数据中,发现隐藏的、与特定功能(此处指膜融合)相关的关键模式。
研究团队设计了一套精巧的算法流程:
特征工程(Feature Engineering):首先,需要将MD模拟产生的原始物理数据(如原子坐标、速度、作用力)转化为机器学习模型可以理解的“特征”。在本项目中,核心特征是氨基酸残基对之间的相互作用强度。他们可能计算了不同氨基酸对之间在模拟过程中的平均距离、形成氢键或盐桥的频率等指标。
模型训练(Model Training):接下来,他们运用机器学习算法(如随机森林、支持向量机或更复杂的图神经网络)来分析这些特征。模型的任务是学习并区分哪些氨基酸相互作用是普遍存在的、背景性的,而哪些是与融合蛋白功能性构象变化强相关的。
重要性排序(Feature Importance Ranking):训练完成后,模型可以输出一个“特征重要性”列表。这个列表会告诉研究人员,在成千上万对氨基酸相互作用中,哪些对预测融合蛋白的正确功能状态贡献最大。排名最高的,就是最有可能的关键相互作用。
通过这一流程,AI模型成功地将研究人员的注意力从一个包含数千个变量的复杂系统,聚焦到了一个或极少数几个最关键的分子互动上。
2.3 WSU研究的技术路径拆解
我们可以将WSU团队的整个技术工作流,用一个简化的流程图来表示,这清晰地展示了计算与实验如何协同工作,最终实现突破。
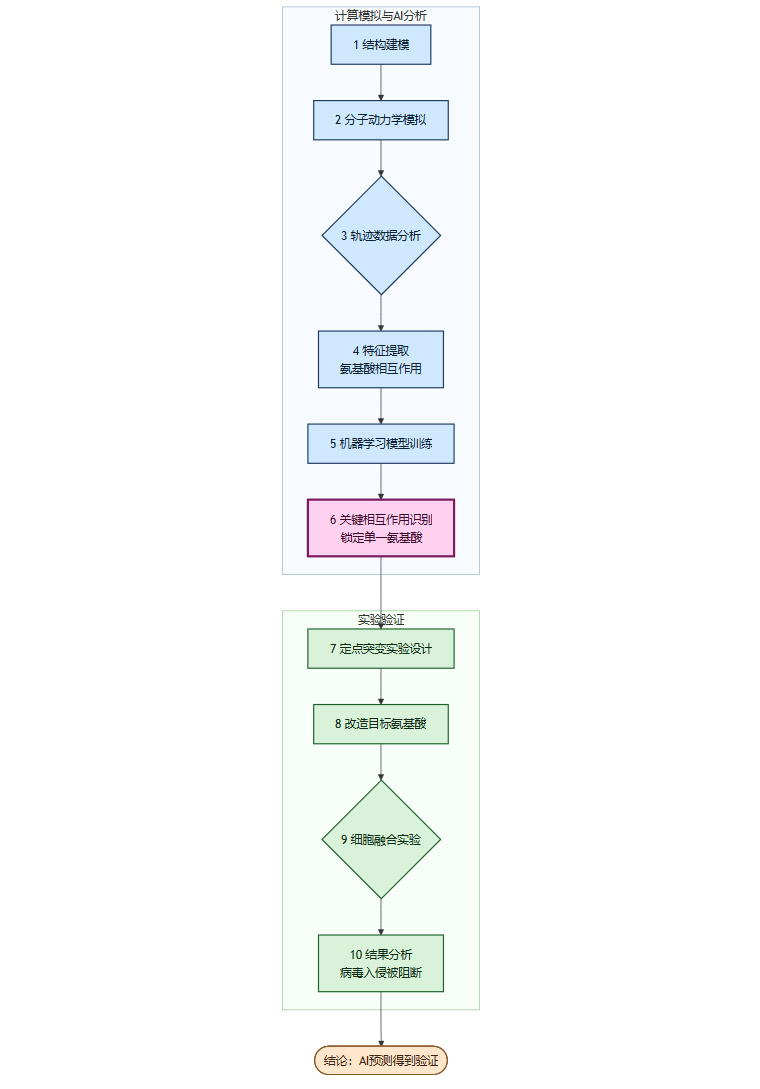
这个流程的核心价值在于计算预测指导实验验证。AI分析(步骤1-6)极大地缩小了搜索范围,使得实验验证(步骤7-10)的目标明确、效率极高。
2.4 关键氨基酸:锁定病毒的“阿喀琉斯之踵”
最终,AI模型给出了一个惊人但清晰的答案:在融合蛋白数千种潜在的分子互动中,存在一个起决定性作用的单一氨基酸。它的某个特定相互作用,就像一个结构上的“锁销”,一旦被破坏,整个融合机器就无法正常运转。
为了验证这个由AI“钦点”的预测,由兽医微生物学与病理学系的Anthony Nicola领导的实验团队接过了接力棒。他们利用基因工程技术,对该关键氨基酸进行了定向改造(例如,将其替换为另一种性质不同的氨基酸)。
实验结果与AI的预测完美契合。经过改造后,病毒的融合蛋白丧失了与细胞膜融合的能力,病毒入侵过程被有效阻断。这个从计算到实验的闭环,强有力地证明了AI不仅能理解复杂的生物过程,更能从中做出准确、可验证的预测。这一发现,相当于找到了病毒融合蛋白的“阿喀琉斯之踵”——一个微小但致命的弱点。
🎯 三、 精准靶向策略的深远影响与技术优势
%20拷贝-gosb.jpg)
锁定这个单一关键氨基酸,其意义远不止是为疱疹病毒找到了一个新的潜在靶点。它更深远的价值在于,开创并验证了一种全新的、基于精准靶向的抗病毒药物开发策略。这种策略与传统方法相比,在多个维度上都展现出巨大的技术优势。
3.1 药物设计新思路:从“阻断复制”到“拒之门外”
许多经典的抗病毒药物,如治疗疱疹病毒的阿昔洛韦(Acyclovir),其作用机制是抑制病毒进入细胞后的DNA复制过程。这类药物被称为病毒DNA聚合酶抑制剂。它们在病毒已经成功入侵并开始“建厂生产”后才介入干预。
而WSU研究启发的策略,则是将防线前移至病毒生命周期的最开端——入侵阶段。通过靶向融合蛋白的关键氨基酸,我们可以在病毒进入细胞之前就将其“拒之门外”。这种“预防式”阻断具有显而易见的优势:
根源性阻断:从源头上阻止感染的发生,避免了病毒遗传物质进入细胞后可能引发的细胞损伤和免疫反应。
降低病毒载量:有效阻止新病毒颗粒感染更多细胞,从而更快地控制病情发展。
潜在的广谱性:许多不同种类的包膜病毒(如流感病毒、HIV等)都依赖类似的融合蛋白机制入侵细胞。虽然具体的关键氨基酸不同,但这种“靶向融合”的策略本身具有很好的泛化潜力。
3.2 提升药物特异性与安全性
传统药物的副作用,根源在于其特异性不足。药物分子在杀死病毒的同时,也可能作用于人体内结构或功能相似的蛋白,造成“误伤”。
而靶向这个由AI识别出的单一氨基酸,则有望开发出高度特异性的药物。原因在于:
靶点独特性:这个关键氨基酸所在的微环境(即其周围的氨基酸序列和空间结构)在病毒融合蛋白中是高度特异的,在人体蛋白中很难找到完全相同的结构。
作用机制精准:药物设计的目的不再是宽泛地抑制某个酶的活性,而是精准地干扰一个特定的分子间相互作用。
这种“外科手术刀”式的精准打击,可以最大限度地减少对宿主细胞正常生理活动的干扰,从而显著降低药物的副作用,提升患者的用药安全性和耐受性。
3.3 应对耐药性挑战的潜在潜力
病毒耐药性是抗病毒治疗面临的永恒挑战。病毒在复制过程中会不断发生基因突变,如果药物作用的靶点发生了改变,药物就可能失效。
靶向融合蛋白的功能性关键位点,可能为应对耐药性提供新的思路。
功能约束:AI识别出的这个氨基酸之所以关键,是因为它对维持融合蛋白的核心结构和功能至关重要。这意味着,病毒如果想通过突变这个位点来逃避药物,很可能同时也会严重损害自身的入侵能力,付出巨大的“适应性代价”。这种功能上的强约束,会降低有效耐药突变出现的频率。
靶点专一:由于攻击点专一,未来药物或许能减少耐药性形成的机会。当然,这并非绝对,病毒仍可能通过其他间接方式产生耐药。因此,对耐药性的监控和评估仍然是药物开发中必不可少的环节,但新策略无疑提供了一个更有利的起点。
3.4 加速研发流程与降低成本
AI驱动的靶点发现模式,对整个药物研发流程的效率和成本带来了革命性的提升。我们可以通过一个简化的表格来对比传统模式与AI驱动新模式的差异。
总而言之,AI的介入,将药物研发从一个依赖大规模试错的劳动密集型产业,转变为一个由数据和算法驱动的知识密集型产业,其核心价值在于用计算的确定性去替代实验的不确定性。
🔬 四、 从实验室到临床:现实挑战与未来展望
%20拷贝-cxwm.jpg)
尽管华盛顿州立大学的这项研究取得了里程碑式的进展,但我们必须清醒地认识到,从一项基础研究的突破到一个能够真正应用于患者的药物,中间还有一条漫长且充满挑战的道路。同时,这项研究所展示的技术潜力,也为未来的发展描绘了广阔的图景。
4.1 技术验证的漫漫长路
目前的研究成果主要停留在机制揭示和细胞层面的实验验证。要将其转化为临床应用,至少还需要跨越以下几个关键阶段:
药物分子设计与发现:当前只是找到了靶点,下一步需要设计或筛选出能够特异性结合该靶点并有效抑制其功能的小分子或生物制剂(如单克隆抗体)。
临床前研究(Pre-clinical Studies):在动物模型(如小鼠、非人灵长类)中验证候选药物的有效性(Efficacy)和安全性(Safety)。这包括药代动力学(PK/PD)、毒理学等一系列研究。
临床试验(Clinical Trials):在人体上进行I、II、III期临床试验,以评估药物在人体中的安全性、有效剂量、疗效和副作用。这是一个耗时最长(通常需要数年)且投入最大的阶段。
审批与上市(Regulatory Approval):通过所有临床试验后,还需向药品监管机构(如FDA、NMPA)提交申请,获批后才能上市销售。
研究团队也明确表示,他们后续的工作将继续利用AI和分子模拟,深入评估不同的小分子修饰对融合蛋白长期结构与功能的影响,为药物设计提供更精细的指导,以提升临床转化的可能性。
4.2 AI模型的泛化与可解释性
对于技术人员而言,我们更关心这项技术本身的健壮性和扩展性。
模型的泛化能力(Generalization):这个为疱疹病毒开发的AI分析框架,能否成功应用于其他病毒,如流感病毒、HIV、甚至未来的新型冠状病毒?这需要验证该方法论在不同蛋白质系统中的普适性。理论上,只要病毒依赖类似的融合蛋白机制,该方法就是可行的,但可能需要针对不同蛋白的特点对算法进行调整。
AI的可解释性(Explainability, XAI):当前的机器学习模型,特别是深度学习模型,有时像一个“黑箱”,我们知道它给出了正确答案,但不知道它是如何做出决策的。在事关人类健康的药物研发领域,可解释性至关重要。我们需要理解AI为什么认为这个氨基酸是关键的,其背后的物理化学原理是什么。这不仅能增强我们对预测结果的信心,还能启发我们发现新的生物学机制。发展可解释AI技术,将是该领域未来的一个重要方向。
4.3 数据质量与算力需求
这种尖端研究的成功,离不开两个基础支撑:高质量的数据和强大的计算能力。
数据是燃料:AI模型的性能高度依赖于输入数据的质量。在本研究中,高质量的蛋白质三维结构数据(通常来自冷冻电镜等先进技术)是所有计算的起点。未来,结构生物学数据库的不断丰富,将为AI提供更多可供分析的“原料”。
算力是引擎:分子动力学模拟和大规模机器学习模型训练,都需要巨大的计算资源,通常依赖于高性能计算(HPC)集群或专用的GPU服务器。算力的发展,将直接决定我们能够模拟的系统尺度和分析的数据深度。
4.4 AI辅助药物设计的未来图景
展望未来,AI在药物设计领域的应用将远不止于靶点发现。一个完整的AI辅助药物设计(AIDD)平台正在形成,它将覆盖从靶点识别到临床试验的全链条:
靶点发现:如本次研究所示,精准识别新的药物靶点。
分子生成:利用生成式AI模型(如GANs、VAEs),从头设计具有理想性质的全新药物分子结构。
性质预测:利用AI模型快速预测分子的物理化学性质、药代动力学性质(ADMET)和毒性,提前淘汰不良候选者。
合成路线规划:利用AI规划最高效、最低成本的化学合成路线。
临床试验优化:利用AI分析临床数据,精准筛选最适合入组的患者,甚至预测试验结果,优化试验设计。
AI正在成为继实验科学、理论科学之后的“第三种科学范式”——计算科学——在生命科学领域的集中体现。
结论
华盛顿州立大学的这项研究,不仅仅是一次成功的科学实验,它更像是一次宣言。它宣告了在人工智能的加持下,我们洞察和干预生命过程的能力已经提升到了一个新的维度。通过将复杂的生物学问题转化为一个可计算、可预测的数学模型,研究人员成功地在病毒的“入侵代码”中找到了一个关键的“逻辑漏洞”。
这一成果为我们描绘了未来抗病毒药物研发的清晰蓝图:以数据为基础,以计算为工具,以精准为目标。它代表了从“经验试错”到“智能设计”的根本性转变。尽管从今天的实验室突破到明天的临床药物,依然道阻且长,但方向已经明确。AI驱动的药物研发新范式,必将深刻改变我们对抗疾病的方式,为守护人类健康提供前所未有的强大武器。
📢💻 【省心锐评】
AI正从“识别模式”进化为“洞察机制”。此次突破的核心价值,是用算力穿透了生物复杂性的迷雾,将药物研发从概率游戏转变为一门更精确的工程科学,其范式意义远超靶点本身。

评论