.png)


【摘要】微软DELT方法以“数据效能”为核心,通过创新的数据评分、筛选和折叠排序机制,显著提升AI训练效率和性能,开启了AI训练的新范式。本文系统梳理其理论基础、技术实现、实验验证及行业影响,带你全面理解AI训练的“上菜顺序”革命。
引言
在人工智能的世界里,数据一直被视为“燃料”,模型则是“引擎”。过去十年,AI领域的主流叙事几乎都围绕着更大的模型、更复杂的算法和更海量的数据展开。我们见证了GPT、BERT、PaLM等巨型模型的诞生,也目睹了AI训练成本的水涨船高。然而,正当业界沉迷于“更大更强”的军备竞赛时,微软研究院的一项新研究却用一种近乎“返璞归真”的方式,给AI训练带来了革命性的突破。
这项发表于2025年6月的DELT(Data Efficacy for Language model Training)方法,首次系统性地将“数据效能”引入AI训练流程。它像一位经验丰富的厨师长,不仅挑选最优质的食材(数据),更精心安排烹饪顺序(数据排列),让AI模型的学习效果提升高达65%。这不仅是技术上的创新,更是理念上的颠覆。
本文将带你深入剖析DELT的理论基础、技术实现、实验验证及其对AI行业的深远影响。无论你是AI开发者、数据科学家,还是对前沿科技充满好奇的技术爱好者,都能在这篇文章中找到启发和思考。

一、🌟 数据效能:AI训练的“上菜顺序”革命
1.1 传统范式的局限
1.1.1 只重数据量与质量,忽视顺序
在AI训练的传统范式中,研究者们主要关注“用什么数据”——即数据的规模、质量和多样性。数据集越大、越丰富,模型学到的能力就越强,这几乎成了行业共识。为此,业界不惜投入巨资,构建了如Common Crawl、The Pile、C4等超大规模语料库。
但在数据“量”的追逐中,另一个关键问题却被忽视了:数据“序”。绝大多数AI训练流程,都是将数据集随机打乱,然后一股脑地喂给模型。就像让学生在一天内同时学习语文、数学、物理、哲学、烹饪和高等数学,学习效率可想而知。
1.1.2 单周期训练的挑战
现代大模型训练通常只进行一个epoch——每个样本只被模型“看”一次。这意味着,数据的出现顺序对模型的学习路径有着决定性影响。如果顺序混乱,模型可能在还没掌握基础知识时就被迫面对高难度任务,导致学习效率低下甚至“学废”。
1.2 数据效能理念
1.2.1 核心思想
微软研究团队敏锐地捕捉到了这一“盲点”,提出了“数据效能”(Data Efficacy)这一全新概念。它强调:
数据效能关注“如何用数据”,即通过科学的排序和筛选,让模型以最优路径吸收知识,最大化每个样本的学习价值。
数据效能 ≠ 数据效率:前者关注“如何用”,后者关注“用多少”。
1.2.2 人类学习类比
正如一道复杂菜肴需要合理的烹饪顺序,AI模型的训练也需要精心设计的数据排列。数据效能的核心,是通过科学的排序和筛选,让模型以最优路径吸收知识,最大化每个样本的学习价值。
如同烹饪讲究上菜顺序,或教师精心安排课程表,AI模型也需循序渐进地学习,从易到难,避免“认知跳跃”或“学废”。
1.2.3 理论支撑
认知科学和信息论均表明,有序、渐进的知识输入能显著提升学习效率和泛化能力。合理排序让模型“循序渐进”,从易到难,减少“认知跳跃”。
二、🧩 DELT框架:评分-筛选-排序的智能数据编排
%20拷贝-iaxf.jpg)
DELT方法的核心在于“评分-筛选-排序”三步走,像一位厨师长,既挑选食材,又安排烹饪顺序。
2.1 数据评分(LQS):动态评估“教学价值”
2.1.1 Learnability-Quality Scoring (LQS)
LQS创新性地从“可学性”和“质量”两个维度动态评估每个样本。
可学性:衡量样本难度随模型能力提升的变化,识别哪些样本在不同训练阶段最有价值。
质量:通过梯度一致性分析,判断样本对整体学习目标的贡献,过滤噪声、错误或无关内容。
2.1.2 技术实现
LQS基于模型自身的学习信号,无需人工标注,具备高度自动化和普适性。它通过分析模型在不同训练阶段对同一数据样本的学习难度变化,来判断该样本的可学性。如果一个样本的学习难度随着训练进行而显著降低,说明它具有很高的可学性;反之,如果学习难度始终很高或变化不大,说明这个样本可能不适合当前的学习阶段。
2.1.3 优势
动态性:LQS不仅看“表面质量”,更关注“动态可学性”——即样本在不同训练阶段的价值变化。
目标导向:通过梯度一致性确保每个样本的学习方向与全局目标一致,提升整体学习效果。
无监督:无需人工标注,完全自动化。
适用范围广:能精准捕捉样本的“情境价值”。
2.2 数据筛选:优中选优,净化训练环境
2.2.1 筛选机制
根据LQS分数设定阈值或比例,保留高分样本,剔除低分或潜在有害样本。
筛选比例可根据任务和数据特性调整,兼顾效率与信息多样性。
2.2.2 价值
提升训练效率,减少模型学习到错误信息的风险,隐性提升数据质量。
既提升训练效率,又避免模型学到“坏习惯”。
2.2.3 筛选流程图
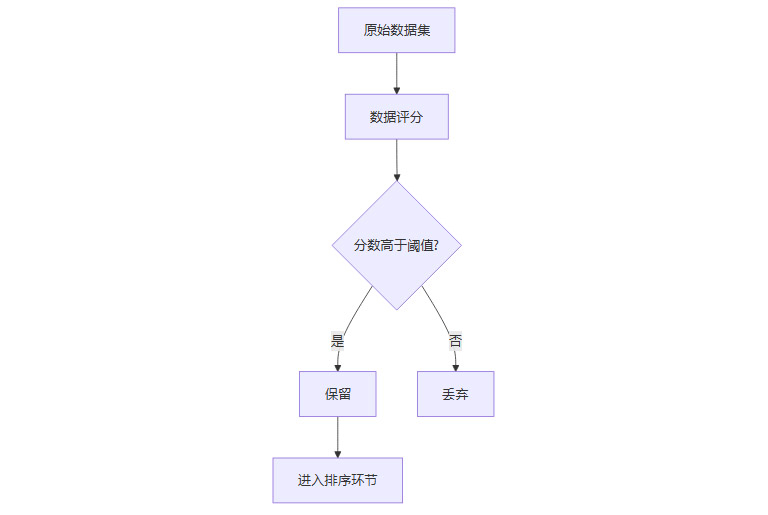
flowchart TD
A[原始数据集] --> B[数据评分]
B --> C{分数高于阈值?}
C -- 是 --> D[保留]
C -- 否 --> E[丢弃]
D --> F[进入排序环节]
2.3 数据排序(折叠排序FO):螺旋式进阶,平衡渐进与多样性
2.3.1 创新点
折叠排序(Folding Ordering, FO)将数据分为多层(通常3层),每层包含从易到难的完整样本序列,交错排列,形成“基础巩固—能力提升—挑战进阶”的学习路径。
2.3.2 优势
防遗忘:模型反复接触不同难度内容,巩固早期知识。
多样性与渐进性平衡:每阶段都包含多样样本,避免过拟合和学习停滞。
适应性强:可根据数据特性调整层数,适配不同任务。
2.3.3 对比传统排序
纯升序易遗忘,随机排序丧失科学性,折叠排序兼顾有序性与多样性,效果最佳。
实验表明,3层折叠效果最佳,兼顾多样性与有序性。
三、📊 实验验证:性能与效率的“临床试验”
%20拷贝-ndfd.jpg)
3.1 全面实验设计
3.1.1 模型规模
覆盖1.6亿到10亿参数的主流模型。
3.1.2 数据规模
10亿到500亿词汇,适应不同训练场景。
3.1.3 任务类型
通用语言理解、数学推理、代码生成等多领域。
3.1.4 对比方法
标准随机排序、仅LQS选择、仅FO排序、完整DELT(LQS+FO)等多种组合。
3.2 主要实验结果
3.2.1 性能提升
在8个权威基准测试上,DELT平均提升1.65个百分点(36.37%→38.02%),某些任务提升高达65%。
3.2.2 数据效率
只需一半数据即可达到传统方法同等效果,训练成本大幅下降。
3.2.3 扩展性与稳定性
不同规模模型、不同领域任务均有效,训练收敛更平滑、稳定,性能波动小。
3.2.4 组件贡献分析
LQS选择和FO排序各自带来显著提升,二者结合效果最佳。
四、🔍 深层机制剖析:DELT为何如此有效?
4.1 认知科学模拟
DELT模拟人类“螺旋式学习”,从基础到复杂,反复巩固,提升泛化能力。人类学习遵循“从易到难、螺旋递进”,AI模型同样受益于有序、渐进的知识输入。
4.2 信息流优化
在单周期训练的信息瓶颈下,DELT最大化每个训练步的信息价值转化率。DELT优化了信息传递效率,在有限训练时间内,最大化每个样本的学习价值。
4.3 动态价值匹配
LQS能动态识别样本在不同阶段的最佳使用时机,解决传统静态评分的局限。不同样本在不同阶段价值不同,LQS能动态识别“启蒙教材”“进阶教程”“特殊知识点”。
4.4 平衡渐进与多样性
折叠排序在渐进性、多样性和抗遗忘性之间达到最佳平衡,提升模型鲁棒性。渐进性保证学习路径科学,多样性防止过拟合、提升泛化,随机性避免结构化带来的僵化。
4.5 梯度一致性驱动
LQS通过梯度一致性确保每个样本的学习方向与全局目标一致,提升整体学习效果。基于梯度一致性分析,观察模型在学习每个样本时的“努力方向”与整体目标的吻合度。
五、🚀 应用前景与行业影响
%20拷贝-ollb.jpg)
5.1 降本增效
DELT显著降低AI训练的经济和时间成本,尤其适合资源有限的中小企业和专业领域。无须增加硬件或数据量,提升性能。
5.2 绿色AI
提升训练效率,减少能耗和碳排放,推动可持续发展。AI训练消耗大量电力,DELT通过提高训练效率,能够在达到相同性能目标的情况下减少能源消耗。
5.3 研究与教育启发
数据组织成为AI训练新热点,启发个性化教育系统和自适应学习路径设计。DELT的理念与人类学习规律高度契合,这为开发更智能的教育系统提供了启发。
5.4 开源与普及
DELT已开源,开发者可免费集成,加速技术普及和创新。任何研究者和开发者都可以免费使用这种方法来改进自己的AI项目。
5.5 挑战与未来方向
评分计算复杂度需进一步优化。
不同行业和极端专业领域需定制化策略。
多模态、跨任务扩展和理论基础深化值得探索。
结论
微软DELT方法以“数据效能”为核心,通过创新的评分、筛选和折叠排序机制,彻底颠覆了AI训练中“数据随机排列”的传统做法。它以近乎“免费”的方式,实现了显著的性能和效率提升,为AI行业带来了降本增效的新范式。DELT不仅有坚实的理论基础和广泛的实验验证,更为AI训练方法论打开了全新视角。未来,随着更多研究者和开发者的加入,数据效能理念有望成为AI训练的“新常态”,推动人工智能迈向更高效、更智能、更可持续的发展阶段。
📢💻 【省心锐评】
“DELT让AI训练像烹饪一样讲究顺序,细节决定成败,行业必将掀起新一轮数据组织革命。“

评论