.png)
%20%E6%8B%B7%E8%B4%9D-puzn.jpg)

【摘要】大型语言模型正驱动科研论文产出量爆发式增长,显著提升了效率与公平性。然而,这种增长伴随着学术质量与传统评审标准失效的深层隐忧,倒逼学术界重构信任体系。
引言
大型语言模型(LLMs)正以前所未有的深度和广度渗透至科研领域,从根本上改变着知识的生产与传播范式。以ChatGPT为代表的生成式AI工具,已不再是少数技术前沿者的实验品,而是演变为全球科研工作者案头常备的生产力工具。这一转变引发了一场规模空前的“学术大跃进”,论文产出数量的激增曲线令人瞩目。
表面上看,这是一场效率的盛宴。AI辅助写作、数据处理与代码生成,极大地压缩了研究周期,尤其为母语非英语的学者铺平了通往国际顶级期刊的道路,促进了全球范围内的学术公平。但在这片繁荣景象之下,一股潜流正在涌动。产出数量的飙升并未直接转化为学术质量的同比例提升。相反,关于研究同质化、学术空心化以及诚信边界模糊化的担忧日益加剧。当华丽的辞藻可以由机器一键生成,我们赖以评判研究质量的传统标尺——“精湛的写作”,其可靠性正在被迅速消解。这不仅是对现有学术评审体系的直接冲击,更是一场关乎科研诚信与创新根基的深刻挑战。本文将系统剖析LLMs在科研领域的双重效应,深入探讨其技术应用、风险挑战以及未来治理框架。
🚀 一、效率的“奇点”:LLM如何重构科研生产力
%20拷贝-qeaw.jpg)
LLMs的介入,并非简单地替代了科研工作流中的某个环节,而是通过系统性的效率优化,触发了科研生产力的“奇点”。这种变革体现在可量化的产出增长、具体的技术赋能以及全球化的机会均等多个层面。
1.1 量化产出:数据驱动的效率革命
近年来发表的多项研究,为我们清晰地勾勒出这场效率革命的轮廓。数据显示,全面采用LLMs辅助工具的科研团队,其论文发表频率和数量均出现了大幅跃升。
跨学科的普遍增长:一项覆盖三大预印本平台近210万篇论文摘要的分析显示,不同学科领域的论文产出均受益于AI。其中,社会科学与人文科学领域的增幅最为显著,达到59.8%。这可能源于这些领域对文本组织和论述构建的高度依赖,LLMs在此展现出强大的辅助能力。紧随其后的是生物与生命科学领域,增幅为52.9%,AI在处理复杂生物数据、撰写实验报告方面作用突出。即便是对逻辑和符号要求极高的物理学与数学领域,增幅也达到了36.2%。
特定群体的跨越式发展:这场效率革命的最大受益者之一,是长期受语言壁垒困扰的非英语母语科研群体。过去,高水平的英文写作是通往国际顶级期刊的“隐形门槛”。如今,LLMs强大的语言润色与翻译能力,有效填补了这一鸿沟。数据显示,亚洲地区的科研人员在部分学科的论文产出增幅最高达到了惊人的89%。这标志着技术正在实质性地推动全球科研竞争的公平化。
1.2 技术拆解:LLM在科研工作流中的应用节点
LLMs对科研效率的提升,源于其深度嵌入了从课题构思到论文发表的完整工作流。它不再是一个孤立的写作工具,而是一个多功能的“科研助理”。我们可以通过下表,清晰地看到LLM在不同阶段的应用场景与核心价值。
1.3 语言平权:打破巴别塔的全球化红利
长期以来,学术界的“巴别塔”效应是客观存在的。英语作为事实上的国际学术语言,无形中构筑了一道高墙,将许多拥有优秀研究成果但英语表达能力有限的学者挡在门外。这不仅造成了人才资源的浪费,也限制了全球学术思想的充分交流。
LLMs的出现,正以前所未有的力度冲击着这座高墙。它提供的高质量、低成本的语言支持,使得非英语母语者能够与英语母语者站在相对平等的起跑线上竞争。这种“语言平权”带来的红利是深远的。它不仅让更多来自不同文化背景的优秀研究得以被看见、被承认,也极大地丰富了全球知识库的多样性。当评价一篇论文的标准更多地回归其学术价值本身,而非其语言包装时,整个学术生态将变得更加健康与包容。
💣 二、质量的“陷阱”:华丽外衣下的学术空心化风险
效率的飞跃带来了产出的繁荣,但这枚硬币的另一面,是关于学术质量的深层隐忧。LLMs在赋予文本“华丽外衣”的同时,也可能无意中挖下了一个个“质量陷阱”,对学术诚信和创新精神构成了潜在威胁。
2.1 “精致写作”与“薄弱研究”的脱钩
在传统学术评价体系中,清晰、严谨、优雅的写作风格通常被视为高质量研究的可靠信号。一篇逻辑缜密、文笔流畅的论文,往往意味着作者付出了巨大的心血进行思考与打磨。然而,LLMs的出现正在打破这种正相关关系。
研究发现了一个令人警惕的悖论,由AI生成的文本语言越复杂、辞藻越华丽,其所承载的学术观点反而可能越薄弱。AI能够轻易模仿出顶级期刊的写作范式,用复杂的从句和专业的术语构建出看似高深的论述。但这层精致的外壳之下,可能隐藏着的是浅薄的观点、重复的论证,甚至是逻辑上的硬伤。这种现象导致了“精致写作”与“薄弱研究”的危险脱钩。一个缺乏实质性创新的研究,可以通过AI的“美颜”,伪装成一篇高质量的学术成果,从而蒙蔽审稿人与读者的双眼。这无疑会引发学术领域的“劣币驱逐良币”效应。
2.2 隐性风险:从数据污染到学术不端
除了掩盖研究本身的不足,LLMs在应用过程中还伴随着一系列更为隐蔽的技术与伦理风险。这些风险点潜伏在科研的各个环节,对结果的可靠性与过程的诚信度构成挑战。
数据幻觉与引用错误:LLMs在生成内容时,有时会“一本正经地胡说八道”,即产生所谓的**“数据幻觉” (Hallucination)**。它可能捏造不存在的数据、杜撰不真实的实验结果,或者将引文“张冠李戴”,将一个作者的观点错误地归属于另一位。对于缺乏经验的研究者,如果未能进行严格的事实核查,这些错误信息就可能被直接写入论文,造成严重的学术误导。
无意间的数据污染:在数据分析环节,如果研究者过度依赖AI生成的代码而缺乏深入理解,可能会无意中引入错误的数据处理方法或统计模型,导致分析结果存在偏差甚至完全错误。这种“数据污染”是极其隐蔽的,因为它通常不会在代码层面报错,但其结论却是建立在错误的地基之上。
助长学术不端的可能性:LLMs的强大能力也为抄袭、剽窃等学术不端行为提供了新的温床。它可以通过改写、转述等方式,将他人的研究成果“洗稿”成一篇看似原创的论文,极大地增加了识别和追溯的难度。这使得学术诚信的防线面临前所未有的压力。
2.3 模板化危机:原创性思维的稀释
更高层次的风险,在于LLMs可能对学术创新本身产生抑制作用。当越来越多的研究者依赖AI进行文献综述、思路构建和论文写作时,学术产出可能会陷入一种**“批量模板化”的困境**。
由于LLMs的训练数据主要来自于现有的海量文本,其生成的内容本质上是对已有知识的重组与模仿。它擅长遵循既定的范式和套路,但难以产生真正突破性的、颠覆常规的原创思想。如果科研工作者过度依赖这种“思维拐杖”,可能会逐渐丧失独立思考、批判性分析以及挑战学术权威的勇气。长此以往,学术界可能会充斥着大量制作精良但思想平庸的“罐头论文”,导致学术范式的趋同与原创性思维的整体稀释。这对于追求知识边界拓展的科学精神而言,无疑是一种伤害。
🏛️ 三、信任的“基石”:传统学术评审体系的动摇与重塑
%20拷贝-igps.jpg)
LLMs带来的效率革命与质量隐忧,正合力冲击着维系学术共同体运转的基石——同行评审与信任体系。当旧有的评判标准逐渐失效,而新的风险不断涌现时,整个学术界都面临着一场深刻的信任危机与范式重塑的挑战。
3.1 评审标准的失效:从文本质量到身份信号的漂移
同行评审是学术质量控制的核心环节。传统上,审稿人会从多个维度评估稿件,其中语言表达的清晰度与专业性是一个至关重要的参考指标。如前所述,这一指标的可靠性正在被LLMs瓦解。当机器可以轻易生成“专家级”的文本时,审稿人无法再单纯从文笔来判断作者的学术素养与投入程度。
这种标准失效带来了一个极具讽刺意味的后果。为了在不确定性中寻找新的确定性,期刊编辑和审稿人可能被迫更加依赖作者的“身份信号”作为替代性的质量判断依据。这些信号包括作者的学术声誉、过往发表记录、所属机构的排名以及所在课题组的知名度等。这形成了一个危险的逻辑闭环,即AI本意在于通过技术打破壁垒、促进公平,但其引发的质量评估难题,反而可能导致学术圈的“马太效应”愈演愈烈,让出身名门的学者更容易获得认可,而背景普通的学者则面临更高的信任门槛。这完全背离了技术推动学术民主化的初衷。
3.2 检测技术的困境:矛与盾的持续博弈
面对AI生成内容的泛滥,开发有效的检测技术似乎是顺理成章的应对之策。目前,市面上已经出现了多种AIGC(生成式人工智能)检测工具。然而,这场“矛”与“盾”的博弈远比想象中复杂,检测技术本身也面临着诸多困境。
我们可以通过下表来对比几种主流的AI文本检测技术及其局限性。
这些技术困境导致了一个尴尬的现实,当前的AI检测工具既不够可靠,也可能带来“冤假错案”。将人类作品误判为AI生成,对作者的学术声誉是毁灭性的打击。因此,多数顶级期刊和机构对单纯依赖检测工具持非常谨慎的态度。
3.3 重建信任:从“可读性”到“可复现性”的范式转移
既然无法完美地“堵”,那么唯一的出路就是“疏”。学术界正在形成一种共识,即评价体系的核心必须进行一次深刻的范式转移,将重心从评估文本的“可读性” (Readability),转移到验证研究的“可复现性” (Reproducibility) 和“可复核性” (Replicability)。
这意味着,未来一篇高质量的论文,其价值将更多地体现在以下几个方面:
数据的可审计性 (Auditability):作者是否提供了完整的原始数据、清晰的数据处理流程?第三方是否可以独立审查数据的真实性与完整性?
方法的透明度 (Transparency):研究方法是否被详尽描述,以至于其他研究者可以精确地重复整个实验或分析过程?相关的代码、软件和参数设置是否公开?
证据链的稳固性 (Robustness):论文的结论是否由坚实的数据和严密的逻辑推导而出?证据链条是否完整,经得起推敲与质疑?
在这个新的评价范式下,AI生成的华丽文笔将不再是加分项,甚至可能因为掩盖了实质内容而成为减分项。真正能够赢得同行信任的,是那些敢于将研究过程完全“开源”,并能提供扎实、可验证证据的成果。这不仅是对AI挑战的回应,也是科学精神本源的回归。
⚖️ 四、治理的“框架”:在创新与规范之间寻求平衡
%20拷贝-sqsv.jpg)
面对LLMs带来的复杂挑战,学术共同体无法选择简单的“禁止”或“放任”,而必须构建一个多层次、动态适应的治理框架。这个框架的核心目标是在鼓励技术创新、维护学术诚信和保障公平竞争之间找到一个精妙的平衡点。各大期刊、学术机构和资助方正在积极探索,并已初步形成一套组合策略。
4.1 政策先行:期刊与机构的应对举措
作为学术成果的“守门人”,顶级期刊和研究机构率先行动,出台了一系列旨在规范LLMs使用的政策指南。这些政策虽然细节各异,但其核心原则高度一致,主要围绕透明度、责任界定和伦理边界展开。
强制性披露原则:这已成为绝大多数主流期刊的“标配”。作者被要求在论文的特定部分(如致谢或方法论)明确声明是否使用了AI工具,并详细说明其具体应用场景。例如,是用于语言润色、代码生成,还是数据分析。这种透明化要求,旨在让审稿人和读者对AI在研究中的介入程度有清晰的认知,从而更准确地评估作者的原创性贡献。
作者责任的最终界定:政策普遍强调,无论AI在其中扮演了何种角色,论文内容的准确性、完整性和原创性的最终责任必须由人类作者承担。AI不能被列为合著者,因为它无法承担法律和伦理责任。这一原则划清了人与机器的界限,重申了学术研究中人类主体性的核心地位。
划定伦理“红线”:一些顶级期刊,如《自然》(Nature)和《科学》(Science)系列,已经明确划定了AI使用的伦理“红线”。例如,严禁使用AI生成任何形式的原始数据、图像或视频,因为这触及了数据真实性的底线。同时,禁止AI参与关键的学术判断环节,如提出核心研究假设、解释研究结果的科学内涵,以及进行同行评议。这些规定旨在确保科学发现的核心创造性过程仍然由人类主导。
4.2 流程再造:“AI+人工”的双重审核模式
单纯依靠政策宣示不足以解决问题,必须在实际的审核流程中进行创新。一种被广泛探讨的模式是**“AI+人工”的双重审核**,即利用AI的效率优势辅助人类专家进行更深入、更全面的审查。
这个模式可以被设计成一个多阶段的流程图:
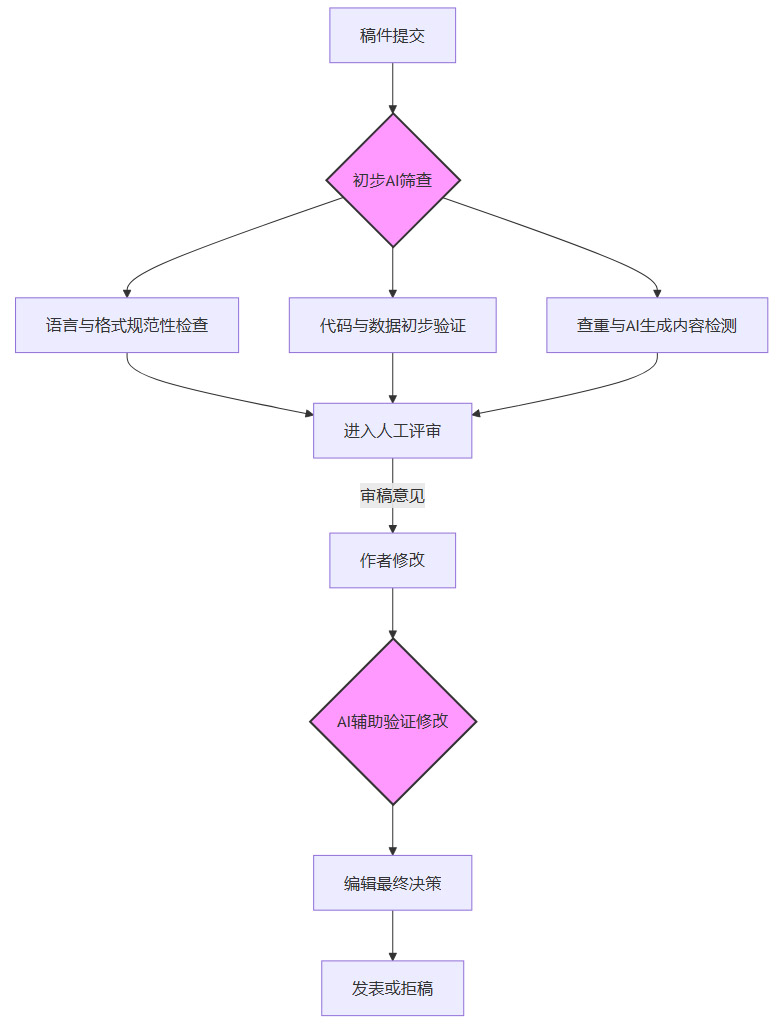
在这个流程中,AI扮演了“第一道防线”和“高效助手”的角色。
初步筛查:AI可以快速检查稿件是否符合期刊的基本格式要求,进行初步的查重,并运行AI生成内容检测工具给出一个参考性的概率分数。这能极大地减轻编辑和审稿人的前期工作负担。
深度验证辅助:对于包含代码和数据的稿件,AI可以辅助运行代码,检查其是否能够复现论文中报告的结果。这对于提升研究的可复现性至关重要。
人类专家主导决策:所有AI生成的报告和分数,都仅作为参考信息提供给人类审稿人和编辑。最终的学术价值判断、创新性评估以及是否录用的决策,完全由人类专家做出。这种模式旨在兼顾效率与严谨,将机器的长处与人类的智慧结合起来。
4.3 教育与赋能:培养负责任的AI使用者
治理的最终落脚点在于人。与其被动地防范AI的滥用,不如主动地培养能够负责任地、创造性地使用AI的下一代科研人才。因此,加强对青年学者和学生的AI伦理与技能培训变得至关重要。
教育内容应涵盖以下几个核心模块:
技术原理与局限性:让学生理解LLMs的基本工作原理,了解其“黑箱”特性以及产生幻觉、偏见等问题的根源。知其然,更要知其所以然。
批判性使用技能:培养学生将AI视为一个需要被严格验证和审视的“信息源”,而非绝对权威。训练他们如何进行事实核查、交叉验证,以及如何识别和修正AI生成内容中的错误。
学术诚信规范:明确在学术写作中使用AI的“可为”与“不可为”,学习如何正确地披露AI的使用情况,理解学术不端的严重后果。
Prompt Engineering(提示工程):教授如何通过设计高质量的提示词,引导AI生成更准确、更有深度的内容,使其真正成为激发创新思维的工具,而非简单的“写作外包”。
通过系统性的教育,未来的科研人员将不再是AI的被动接受者,而是能够驾驭这一强大工具、同时坚守学术底线的“AI原生代”学者。
结论
大型语言模型正以一种不可逆转的姿态,深刻地重塑着全球科研的生态版图。它既是助推产出的“加速器”,也是促进公平的“催化剂”,为科研界带来了前所未有的效率红利和全球化机遇。然而,这场由AI驱动的“大跃进”并非没有代价。它同时也是一把锋利的“双刃剑”,其另一面是学术质量标准模糊化、传统评审体系失灵以及原创精神被稀释的潜在风险。
面对这场结构性的变革,简单的拥抱或抗拒都非明智之举。学术共同体必须清醒地认识到,我们正处在一个关键的十字路口。未来的竞争格局,将不再仅仅是知识本身的较量,更是驾驭新技术、重塑信任体系能力的较量。那些能够率先完成从依赖“语言精致度”到强调“证据稳固性”范式转型的研究者与机构,将在AI赋能的新时代中占据先机。最终,决定一项研究价值的,将永远是其背后坚实的数据、严谨的方法和无可辩驳的证据链。技术可以改变我们抵达真理的路径,但对真理本身的追求与敬畏,永远是科学精神不变的内核。
📢💻 【省心锐评】
AI正强制学术界进行一次“去魅”:当华丽的辞藻变得廉价,硬核的证据与可复现性便成为唯一的“硬通货”。这既是挑战,更是科学精神的本质回归。

评论