.png)


【摘要】Easy Dataset由北航团队开发,是一款面向AI训练数据集自动化生成的开源工具。它以多格式文档解析、角色驱动问答生成和极致易用性为核心,极大降低了AI定制化训练门槛,推动AI技术普及和行业落地。
引言
人工智能的浪潮正席卷全球,通用大模型如ChatGPT、Claude等已成为技术创新的代名词。然而,AI的“通才”属性并不能完全满足各行各业对专业化智能的渴望。正如一位博学的医生在面对罕见疑难杂症时,仍需依赖专科医生的深厚积累,AI模型在专业领域的表现同样受限于其训练数据的广度与深度。高质量、领域定制的数据集成为AI进化为“专家”的关键。
但现实是,专业数据的获取与整理极为繁琐。无论是医学、金融、法律还是工程,原始文档往往格式多样、内容复杂,人工标注耗时耗力,且对技术门槛要求极高。如何让非技术背景的领域专家也能参与到AI训练数据的生产中?如何让数据的生产像流水线一样高效、标准、可控?Easy Dataset的诞生,正是对这一时代命题的有力回应。
本文将全面剖析Easy Dataset的技术创新、应用流程、实验成效与生态影响,结合行业视角,探讨其对AI数据生产范式的深远变革。
一、Easy Dataset的技术基石与创新突破
%20拷贝-nfrk.jpg)
1.1 多格式文档智能解析:让数据入口无障碍
1.1.1 支持主流文档格式,适应复杂现实
Easy Dataset的首要创新,是对多种主流文档格式的原生支持。无论是PDF、Word(DOCX)、Markdown还是TXT,用户均可直接上传,系统自动完成解析与内容提取。对于结构简单的文本或Markdown,系统采用“保护式”解析,最大程度保留原有语义结构,避免信息丢失。
1.1.2 复杂PDF的智能适配
PDF格式因其排版灵活、内容丰富,成为专业文档的主流载体,但也带来了极大的解析挑战。Easy Dataset内置多种解析策略:
基础解析:适用于纯文本PDF,快速提取文字内容。
MinerU API:针对包含表格、图片、复杂布局的PDF,进行布局分析,分离文本与视觉区域。
视觉模型解析:对图片、图表等非文本区域,调用视觉语言模型进行内容理解,实现“图文并茂”的信息还原。
这种多策略融合,确保无论是学术论文、财报、技术手册还是专利文档,均能实现高质量的信息提取。
1.1.3 Word文档的结构优化
Word文档虽然表面整齐,内部结构却常常混乱。Easy Dataset通过集成Mammoth工具,将Word内容转为结构清晰的Markdown格式,既保留语义层次,又去除冗余格式噪音,为后续处理打下坚实基础。
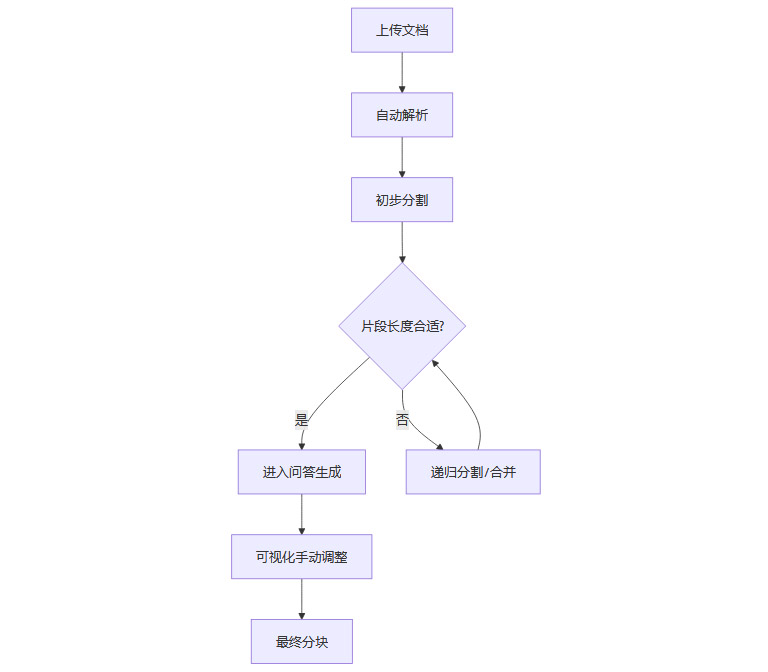
1.2 智能文本分割与可视化调整:让数据颗粒度恰到好处
1.2.1 混合分块策略,兼顾自动与人工
文档解析后,如何将长篇内容切分为适合AI处理的片段?Easy Dataset采用“混合分块”策略:
自动分割:基于行分隔符、用户自定义分隔符,递归切分长段落,确保每块长度适中。
智能合并:对过短片段,系统自动合并,保证语义完整。
可视化调整:用户可在图形界面中手动微调分块结果,实现自动化与人工控制的平衡。
这种设计既提升了处理效率,又保留了对关键语义单元的把控权。
1.2.2 分块流程图
1.3 自动化问答生成与角色驱动创新:让数据多样且高质
1.3.1 高质量问答生成
Easy Dataset集成主流大模型(如GPT、DeepSeek、Qwen等),自动从每个文本片段生成问题与答案。系统支持自定义系统提示词,灵活控制问答风格、深度与目标受众。
1.3.2 角色扮演机制:数据多样性的引擎
角色驱动是Easy Dataset的独特亮点。系统自动为每份文档生成“类型-受众”组合,如“初学者-激励性内容”、“专家-深度讨论”等。每种组合对应不同的提问视角和答案风格,极大丰富了数据集的多样性和覆盖面。
1.3.3 答案一致性与防幻觉
在答案生成环节,系统将问题与源文本一同输入大模型,形成“封闭知识环境”,有效避免AI“幻觉”,确保答案与原文高度一致。
1.3.4 知识增强与推理链
对于需要推理的任务,Easy Dataset支持生成带有中间推理步骤的答案(COT),提升数据的可解释性和后续模型的可追溯性。
1.4 灵活编辑与人工审核:质量与效率兼得
1.4.1 全流程可编辑
无论是分块、问题还是答案,用户均可在流程任意阶段手动优化,确保数据集质量。
1.4.2 自动与人工结合
系统支持自动优化与人工审核并行,既保证了高效批量处理,又能针对关键数据进行精细把控。
1.5 多格式导出与主流兼容:让数据流转无缝衔接
1.5.1 标准化输出
Easy Dataset支持导出为Alpaca、ShareGPT等主流数据集格式,文件类型涵盖JSON、JSONL、CSV等,便于对接LLaMA Factory、Unsloth等微调框架。
1.5.2 自定义模板
用户可自定义导出字段,如问题、答案、推理步骤、领域标签等,灵活适配不同任务需求。
1.5.3 生态兼容性
系统与主流AI训练工具链无缝集成,填补了从原始文档到训练数据的技术空白,极大提升了数据生产的标准化与自动化水平。
1.6 用户友好与零门槛体验:让每个人都能成为AI数据生产者
1.6.1 图形化界面与多平台部署
Easy Dataset提供直观易用的图形界面,适合技术和非技术用户。支持一键安装包、Docker、NPM源码运行,兼容Windows、MacOS、Linux多平台。
1.6.2 灵活模型接入与参数调控
系统支持OpenAI、DeepSeek、Ollama等云端及本地模型,用户可灵活调整温度、top-p等参数,适配不同领域和场景需求。
二、Easy Dataset的实际应用流程与操作体验
2.1 安装与部署:多样化选择,适应不同用户环境
用户可根据自身需求选择:
一键安装包,适合零基础用户
Docker部署,适合企业或团队环境
NPM源码运行,适合开发者和二次开发
2.2 项目与模型配置:以项目为单位,灵活管理
每个数据集以“项目”为单位管理,支持多模型API集成。用户只需填写模型名称、API地址和密钥,即可快速接入主流大模型。
2.3 文档上传与智能分割:批量处理,高效便捷
支持批量上传文档,系统自动解析并分割内容。用户可在可视化界面中微调分块结果,确保每个片段语义完整、长度适中。
2.4 问答生成与角色驱动:批量生成,多样化输出
系统自动为每个文本块生成多样化问题与答案,支持思维链输出和角色定制。用户可根据实际需求调整角色组合,满足不同场景下的数据需求。
2.5 人工审核与优化:全流程可控,确保高质输出
用户可在任意阶段手动编辑、优化问题和答案,系统支持自动优化与人工审核并行,提升整体数据质量。
2.6 数据导出与微调对接:一键输出,直接上手
支持一键导出为多种主流格式,直接对接LLaMA Factory、Unsloth等微调工具,无需额外格式转换,极大提升了数据流转效率。
三、实验验证与实际成效:专业与通用能力的双重提升
%20拷贝-mdus.jpg)
3.1 金融问答任务的实证检验
3.1.1 实验设计
选取五份最新金融报告,确保内容超出模型知识截止日期
基于原文构建100个专业评估问题,形成标准化测试集
以Qwen2.5-7B-Instruct为基础模型,分别用朴素与角色驱动数据微调
采用LLM-as-a-judge(如DeepSeek-V3)评测专业能力,同时在MMLU、CMMLU、HellaSwag、MATH、HumanEval等通用基准测试模型泛化能力
3.1.2 实验结果
专业能力提升显著:微调后模型在金融问答任务中得分大幅提升,角色驱动方法进一步增强了专业表现。
通用能力保持甚至提升:在MMLU等通用基准测试中,微调后模型通用能力未下降,角色驱动数据还提升了泛化能力。
3.1.3 角色驱动的多样化优势
角色驱动机制不仅提升了数据多样性,还增强了模型对不同用户提问风格的适应能力。例如,同一财务报告可生成面向高管的简洁问答和面向税务专家的技术分析,极大拓展了AI模型的应用边界。
3.2 多场景应用与行业落地
Easy Dataset已广泛应用于企业知识库、法律、医疗、学术等领域,支持企业文档助手、智能客服、行业知识图谱等垂直场景。其高效的数据生产能力和低门槛体验,极大推动了AI在各行业的普及与落地。
四、开源生态与社区影响:推动AI数据生产的民主化
4.1 社区活跃与生态完善
Easy Dataset自开源以来,已在GitHub获得9000+星,社区活跃,文档完善,持续更新。官方提供详细教程、演示视频(B站、YouTube)、丰富案例,初学者和开发者均可快速上手。
4.2 生态兼容与技术扩展
系统与主流AI训练工具链无缝集成,支持多平台部署和多模型接入,极大提升了数据生产的标准化与自动化水平。用户可根据实际需求灵活扩展,满足不断演进的AI训练需求。
4.3 行业影响与技术范式变革
Easy Dataset的出现,填补了从原始文档到训练数据的技术空白,让更多领域专家能够参与到AI模型的定制化训练中。其多格式解析、角色驱动、零代码体验等创新,正在重塑AI数据生产的行业范式。
五、常见问题与未来展望
%20拷贝-uyhs.jpg)
5.1 常见问题解答
非技术用户能否使用?
完全可以。图形界面和一键安装包,无需编程基础,初学者也能快速上手。如何处理复杂PDF(含表格、图片)?
系统先进行布局分析,分离文字与视觉区域,分别用文本提取和视觉模型解析,确保信息完整。角色驱动生成的优势?
覆盖多场景需求,提升AI对不同用户提问的适应能力和数据多样性。数据导出是否兼容主流微调工具?
支持Alpaca、ShareGPT等主流格式,直接对接LLaMA Factory、Unsloth等微调框架。
5.2 未来发展方向
Easy Dataset团队计划:
支持SQL查询、多媒体内容等更多模态,拓展数据类型
集成自动质量监控机制,提升数据一致性与可靠性
开发更高级的数据增强策略,进一步提升数据多样性与模型泛化能力
六、获取与学习资源
GitHub:https://github.com/ConardLi/easy-dataset
官方文档:https://docs.easy-dataset.com
演示视频:B站、YouTube(https://youtu.be/HlyvdE1ASRk)
社区案例:CSDN、B站等平台均有实战分享
结论
Easy Dataset以其多格式文档智能解析、角色驱动的多样化问答生成、零代码友好体验和强大的开源生态,极大降低了AI训练数据制作的门槛。它不仅提升了专业领域AI模型的定制能力,还确保了通用能力的保持和提升。无论是AI开发者、企业数据团队,还是非技术领域专家,都能通过Easy Dataset高效、低成本地构建高质量训练数据集,推动AI技术的民主化和行业落地。未来,随着更多模态和自动化质量控制的加入,Easy Dataset有望成为AI数据生产领域的标杆工具。
📢💻 【省心锐评】
Easy Dataset让AI数据生产变得像搭积木一样简单,是AI行业降本增效的典范之作。

评论