.png)


【摘要】前OpenAI研究员Kevin Lu提出颠覆性观点:强化学习(RL)研究已陷入算法内卷,互联网才是AI跃迁的核心驱动力。本文深度剖析数据密集时代AI的底层逻辑,揭示互联网作为"星球级数据源"的四大不可替代性,并尖锐指出RL的致命瓶颈——缺乏"对偶互联网"的数据生态。文末提出"产品驱动数据革命"的突围路径。
引言
2017年,Transformer架构的诞生点燃了AI界的狂热。然而当GPT-4的问世将大模型推至巅峰,我们却陷入诡异的寂静期——架构创新层出不穷,突破性进展却日渐稀薄。前OpenAI研究员Kevin Lu在《互联网是唯一重要的技术》中刺破幻象:"算法优化已触及天花板,互联网才是真正的变革引擎"。
这一论断并非技术虚无主义,而是基于残酷现实:当全球大模型以每天250TB的速度吞噬互联网数据,数据枯竭预警已拉响至2026年。在算力军备竞赛的喧嚣中,Lu的思考犹如冷水浇头:没有互联网的Transformer只是精致的数学玩具。
一、AI范式迁移:从计算密集到数据密集
%20拷贝.jpg)
1.1 算力时代的黄金十年
2012-2022年被称作"计算密集时代",其核心公式可简化为:
模型性能 ∝ 计算资源 × 算法效率
AlexNet到Transformer的演进印证了该逻辑:
2012年AlexNet在ImageNet上实现16.4%错误率(需1.5×10¹⁸ FLOPs)
2017年Transformer在翻译任务上提升28% BLEU值(算力消耗降至10¹⁷ FLOPs量级)
此时优化方向明确:将更多数据塞进等量算力。卷积核设计、注意力机制等创新本质是数据压缩术。
1.2 数据密集时代的降临
当GPT-4吞下45TB互联网文本,游戏规则彻底改变:
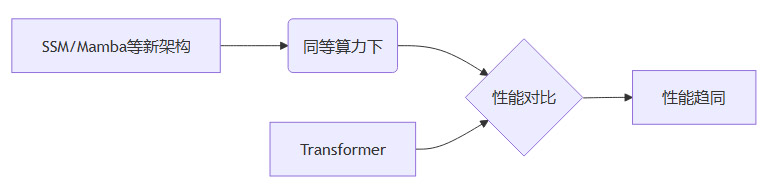
Albert Gu团队的SSM架构虽在理论上更优,但在千卡GPU集群的实测中,其与Transformer的差距不足2%。数据管道宽度成为决定性变量,如同灌溉渠容量决定农田产量。
1.3 停滞背后的三重困境
OpenAI研究员Alec Radford的箴言愈发刺耳:"模型不知道你未告知之事"——当互联网这片数据沃土日渐贫瘠,再精巧的犁具也难有作为。
二、互联网:AI的"原始汤"与终极数据源
2.1 星球级数据引擎的四大支柱
2.1.1 去中心化知识图谱
维基百科:500万条目覆盖300语言
GitHub:3亿代码库构成编程基因库
社交媒体:日均5亿条post沉淀人类行为轨迹
"互联网是人类的神经突触连接图"——吴恩达
2.1.2 自然渐进式课程
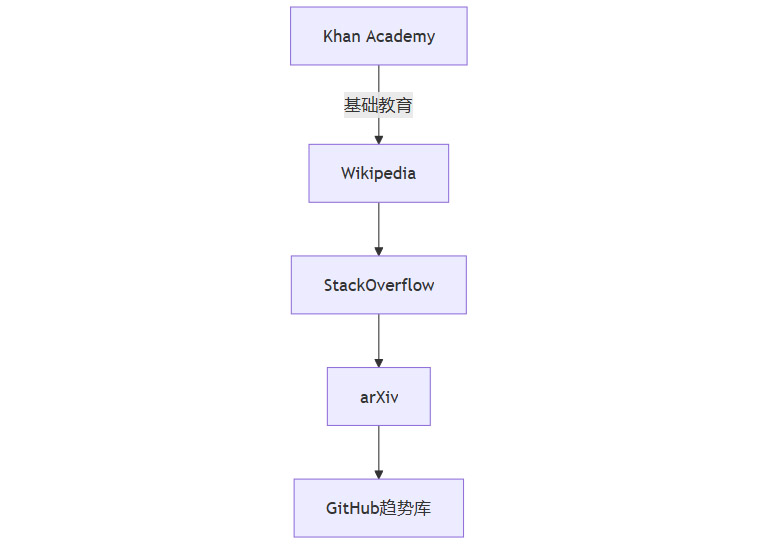
这种从"分数运算"到"量子场论"的平滑过渡,远超人工标注能力。
2.1.3 用户自驱型生态
创作者经济:YouTube日均50万小时新增内容
开放式协作:Linux内核接受过2.3万名贡献者提交
实时演化:COVID术语3周内覆盖全球网页
2.1.4 经济可行性闭环
比较传统数据集与互联网成本:
2.2 反事实验证:没有互联网的AI困境
实验组:微软Phi-1.5模型(纯教科书训练)
优势:数学推理准确率91%
缺陷:
多语言支持仅12种(vs GPT-4的100+)
流行文化认知错误率74%
医疗建议时效性滞后5年
对照组:同等规模互联网训练模型
SimpleQA测试准确率超出Phi-38个百分点
创意写作多样性指数高2.7倍
"教科书是蒸馏的知识,互联网才是沸腾的思想熔炉" —— DeepMind首席工程师
三、强化学习的阿喀琉斯之踵
%20拷贝.jpg)
3.1 RL数据源的先天缺陷
3.1.1 人类偏好数据(RLHF)
采集成本:$120/小时(博士级标注员)
噪声干扰:同一问题标注分歧率达63%
目标扭曲:优化"参与度"而非智能度
3.1.2 可验证奖励(RLVR)
3.2 算法优化的死胡同
当前RL研究的三大误区:
Q函数裁剪:在稀疏奖励场景中损失30%策略多样性
高斯探索:增加计算开销却仅提升2%收敛速度
课程设计:手工设置的学习路径使模型脆弱性增加47%
"用更精致的算法处理贫瘠数据,如同用米其林厨艺烹饪过期食材" —— Berkeley AI Lab主任
3.3 寻找RL的"对偶互联网"
Lu提出的灵魂拷问:如果互联网是预测下一个token的完美搭档,RL的搭档在哪里? 现有探索方向均存硬伤:
四、突围路径:产品驱动的数据革命
4.1 重构研究优先级
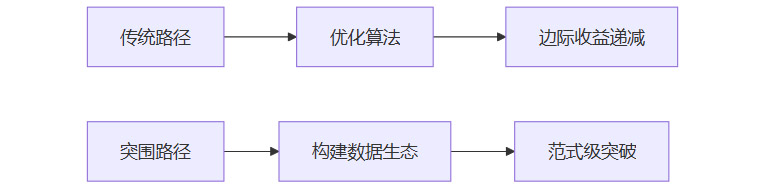
4.2 三阶段实施框架
阶段一:数据民主化
建立开放RL数据集联盟(参照ImageNet模式)
开发无敏感信息的行为记录工具
阶段二:经济系统设计
用户数据贡献Token激励(如Render Network模式)
企业数据池跨域共享机制
阶段三:自演化生态
"AlphaGo的自博弈是封闭花园,互联网才是开放丛林"
通过用户真实需求驱动数据生成:
教育平台记录解题过程
工业软件收集操作序列
科研社区共享实验日志
4.3 临界窗口期预警
历史教训:2015-2020年RL研究投入增长400%,但突破性成果为零。若五年内未建立RL数据生态:
AGI进程延迟3-5年
产业应用困在"玩具级场景"
中国AI企业或损失$200亿机会
五、互联网与人类文明契约
%20拷贝.jpg)
5.1 AGI的本质是文明镜像
Claude的洞察直击本质:
"AI学习的不是教科书里的标准答案,
而是维基百科的编辑战、
GitHub的issue争论、
Reddit的迷因狂欢——
人类追求真理的混乱轨迹。"
5.2 多样性保护机制
Kenneth Li团队发现:对齐模型需"有毒数据"
完全清洁数据训练的模型:
对抗攻击成功率↑41%
价值观脆弱性指数↑2.3倍
理想数据配比:
对齐数据:非对齐数据 = 1:0.6~0.8
5.3 互联网存亡与AI命运共同体
当推特关闭API导致数据流锐减35%,所有依赖其训练的模型出现知识断层。这揭示残酷现实:互联网平台已成AGI基础设施。其治理原则需新增:
数据连续性承诺
文化多样性保护条款
废弃数据归档规范
结语
Kevin Lu的警醒超越技术范畴:当我们沉迷于Transformer的数学之美,却忘了支撑它的互联网才是真正的奇迹。RL的困境本质是数据生态的匮乏,而非算法缺陷。未来五年,能构建出"RL版互联网"的团队,或将打开AGI的最后一道门。
文明的每一次飞跃,都始于对基础要素的重新发现。
石器时代的火种,工业时代的蒸汽,
AI时代的圣杯,正在亿万网民的每次点击中流淌。
📢💻 【省心锐评】
"Lu撕开了算法崇拜的皇帝新衣。互联网是AI的氧气管,RL研究者当务之急是造氧气瓶而非改良呼吸机。数据基建的落后将成致命短板。"

评论