.png)


【摘要】真实数据资产(RDA)正驱动教育与生命健康数据从原始资源向可信资产演进。文章深度剖析其在两大领域的应用范式、伦理挑战,并系统阐述隐私计算技术栈如何构筑这场变革的安全基石。
引言
“数据要素”已不再是停留在政策文件中的抽象名词,它正以前所未有的速度,与土地、劳动力、资本、技术等传统生产要素并驾齐驱,成为驱动数字经济发展的核心引擎。在这场深刻的变革中,**真实数据资产(Real Data Asset, RDA)**作为数据要素化的核心实践路径,其影响力正迅速从已经深度数字化的工业制造与金融科技领域,向更广阔、更复杂的社会民生领域——教育与生命健康——进行渗透。
与工业流水线上的传感器数据或金融交易记录不同,教育与生命健康数据承载着个体的成长轨迹、认知偏好、生理节律乃至基因密码。它们是高度敏感、极具价值且充满伦理挑战的特殊数据类型。将这类数据从业务流程的“附属品”转变为可确权、可计价、可流通的“核心生产要素”,不仅是一次技术架构的升级,更是一场涉及产业范式、伦理边界与治理体系的系统性重构。本文将深入剖析RDA在这两大蓝海领域的应用逻辑、技术挑战与实现路径,并重点解构以零知识证明(ZKP)为代表的隐私计算技术,如何为这场充满机遇与风险的变革,构筑一道坚不可摧的“安全门”。
一、💠 范式重塑:从数据资源到真实数据资产(RDA)的内核

在讨论具体应用之前,我们必须首先厘清RDA的核心理念。它并非简单的数据封装或打标签,而是一套完整的数据价值实现方法论,其本质是完成数据从“资源”形态到“资产”形态的根本性跃迁。
1.1 RDA的核心定义与特征
传统意义上的数据,我们称之为数据资源(Data Resource)。它们通常是业务系统的副产品,呈现出碎片化、非结构化、权属模糊、质量参差不齐的特点。而真实数据资产(RDA),则是通过一系列技术与业务流程,对数据资源进行治理、确权、建模与封装后形成的标准化数字商品。它具备以下几个关键特征:
可确权(Verifiable Ownership):资产的归属权、使用权、收益权等权属关系清晰明确,并通过技术手段(如分布式账本)进行登记与固化,确保权属的不可篡改与可追溯。
可信赖(Trustworthy & Verifiable):资产的来源、处理过程、质量状态均可被验证。物联网(IoT)设备、可穿戴传感器等终端提供的真实世界数据,结合链上验证机制,为资产的“真实性”提供了底层保障。
可计价(Valuable & Pricable):资产的价值可以通过特定的评估模型进行量化,具备明确的定价基础,从而能够进入市场进行交易或作为抵押物进行融资。
可流通(Liquid & Interoperable):资产遵循标准化的数据格式与接口协议,能够在合规的交易平台或数据空间中,安全、高效地流转与互操作。
为了更直观地理解这一转变,我们可以通过下表进行对比:
1.2 时代背景:为何是现在?
RDA理念的兴起并非偶然,它是技术发展、政策引导与市场需求共同作用的结果。
政策驱动:中国已将数据要素提升至国家战略高度,各地数据交易所的建立和数据要素市场的培育,为RDA的流通提供了必要的市场基础设施。
技术成熟:物联网、5G、区块链(分布式账本)与隐私计算等技术的成熟,为数据的可信采集、确权登记与安全流通提供了完整的技术栈支持。
市场需求:随着AI大模型的爆发,高质量、合规的数据集成为制约算法进化的核心瓶颈。市场对可信、可用的数据资产产生了前所未有的强烈需求。
正是在这样的背景下,RDA的实践开始从理论走向现实,并率先叩开了教育与生命健康这两扇蕴含巨大价值潜力的大门。
二、💠 教育新局:学习数据资产化驱动的精准与融合
教育领域的数据,长期以来被视为教学管理的辅助工具,沉睡在各个独立的教务系统、在线学习平台和校园一卡通中。RDA的引入,旨在唤醒这些沉睡的数据,将其转化为驱动教育变革的核心动力。
2.1 学习数据资产化的实现路径
将学习数据资产化,是一个系统性的数据治理与工程过程。其核心是将学生在整个学习生命周期中产生的各类数据,统一纳入可确权的“学习数据资产”体系。
数据源归集:涵盖考试成绩、课堂互动记录、作业提交与批改数据、在线学习行为日志、实验实训过程数据、图书借阅记录、社团活动参与情况等。
数据治理与标准化:对来自异构系统的数据进行清洗、去重、脱敏,并按照统一的数据模型进行结构化处理,形成标准化的学习事件记录。
确权与登记:明确学生作为数据主体的核心权益,通过智能合约等技术手段,将每一份结构化的学习数据记录与其主体进行绑定,并在可信数据账本上进行登记,形成不可篡改的“学习资产”。
建模与封装:基于标准化的学习资产,构建多维度的学生能力画像、知识图谱掌握度模型等,并将其封装成可供外部应用调用的RDA产品。
2.2 资产化带来的核心价值
学习数据一旦完成资产化,其应用价值将远超传统的数据报表分析,为教育领域带来三大根本性变革。
2.2.1 实现真正意义上的个性化教育
传统的个性化教育多依赖于教师的经验判断或简单的规则引擎。而基于RDA,系统可以构建一个长期、动态、多维度的可信学习画像。AI算法能够基于这份画像,精准分析每个学生的认知风格、知识薄弱点和潜在优势,从而实现:
自适应学习路径推荐:为学生智能规划最优的学习顺序和内容组合,避免“一刀切”的教学进度。
差异化教学资源推送:根据学生的掌握情况,自动推送不同难度、不同形式的练习题、教学视频或拓展阅读材料。
精准学业预警与干预:通过分析学习行为资产的变化趋势,提前识别可能出现学业困难的学生,并向教师或辅导员发出预警,进行早期干预。
2.2.2 提升教育产出的可度量性
长期以来,教育成果的评估高度依赖于标准化考试,过程性评估和综合素质评价往往缺乏客观、可信的数据支撑。RDA为此提供了全新的解决方案。通过构建“学习投入—学习过程—学习效果—就业结果”的全链路数据闭环,教育管理者可以:
量化评估教学质量:客观分析不同课程、不同教师的教学效果,为教学质量管理和教师考评提供数据依据。
科学制定教育政策:基于区域或全国范围内的学习数据资产分析,洞察教育发展趋势,为课程体系改革、教育资源配置等决策提供支持。
创新学分互认机制:在跨校、跨平台乃至终身学习场景下,可信的学习资产记录为学分银行和成果互认提供了坚实的技术基础。
2.2.3 支撑产教深度融合
打通教育与产业之间的“最后一公里”,是教育改革的重要方向。学习数据资产化为此搭建了一座关键的桥梁。在严格遵守隐私保护的前提下,企业可以:
获取人才画像视图:通过访问经过学生授权和脱敏处理的“学习资产”视图,企业可以更全面地了解毕业生的专业技能、项目经验和综合素质,实现更精准的人才筛选。
参与课程共建:企业可以将行业需求反馈给高校,基于对学生能力资产的分析,共同设计和优化课程内容,确保教学与市场需求紧密结合。
优化实习与岗位匹配:通过智能匹配算法,将学生的学习资产画像与企业的岗位需求画像进行比对,推荐最合适的实习和就业岗位,提升匹配效率。
一些前沿实践已经出现,例如部分民办教育机构开始探索将数据资产纳入财务报表,这不仅是会计准则的创新,更标志着数据作为核心资产的价值正逐步获得市场认可。
三、💠 健康蓝海:生物数据资产化与“生命证明”经济

如果说教育数据资产化是重塑认知世界,那么生命健康数据资产化则是解构和重组物理世界的人体信息。这一领域的探索更为前沿,其潜在的颠覆性也更强。
3.1 从诊疗数据到“生命证明”资产
生命健康领域的RDA可以大致分为两个层次:以医疗机构为中心的诊疗数据资产,和以个人为中心的生物识别与体征数据资产。
3.1.1 诊疗数据的资产化与复用
医院的电子病历(EMR)、检验结果(LIS)、医学影像(PACS)、处方记录等,是价值密度极高的“数据金矿”。通过合规脱敏、建模与资产登记,这些数据可以被转化为可复用的医疗RDA产品。
一个标志性的案例是上海数据交易所挂牌的商业保险核赔RDA项目。该项目将数百万份经过严格脱敏和结构化处理的诊疗数据,封装成一个可供保险公司调用的风险评估模型。保险公司在进行核赔时,只需输入必要的查询参数,即可获得一个可信的风险评分,而无需接触任何原始病历。这种模式实现了数据价值的流通,同时保护了患者隐私,成功带动了数亿元规模的数据采购,为医疗大数据的合规复用树立了标杆。
3.1.2 生物识别数据的“生命证明”经济
随着智能手表、健康手环等可穿戴设备的普及,心率、血压、血氧、睡眠质量、运动步数、甚至情绪相关的生理体征等数据,正在被持续不断地采集。这些数据汇集在一起,构成了每个人独一无二的、动态的“生命轨迹数据”。
当这些数据通过RDA框架被资产化后,一个全新的“生命证明(Proof of Life)”经济雏形便开始浮现。个人可以通过授权自己可信的生命体征数据,来证明自身的健康状况、生活习惯或风险水平,从而在多个场景中获得价值回报:
动态保险精算:保险公司可以基于用户授权的、持续更新的健康RDA,开发UBI(Usage-Based Insurance)车险那样的动态健康险。积极锻炼、作息规律的用户可以获得保费折扣,形成正向激励。
个性化精准医疗:医生可以结合患者的诊疗数据和长期的生命体征RDA,制定更为精准的个体化治疗方案和康复计划。
智能化慢病管理:对于糖尿病、高血压等慢性病患者,其生命体征RDA可以接入智能管理平台,实现风险实时预警、用药提醒和生活方式干预建议。
3.2 AI + 生物大数据:构建未来健康系统的基石
AI大模型在生命科学领域的突破,如AlphaFold对蛋白质结构的预测,已经展示了其巨大潜力。然而,所有AI模型的性能上限,都取决于训练数据的质量和规模。RDA正是为AI训练提供高质量、大规模、合规“燃料”的关键机制。
基因组学、蛋白质组学、临床试验数据与个人生命体征数据,在完成资产化后,可以在一个安全合规的算力环境中,为AI模型的训练与推理提供前所未有的高质量样本。这将在多个层面驱动产业升级:
加速新药研发:AI可以基于海量的生物数据资产,进行药物靶点发现、化合物筛选和临床试验设计优化,大幅缩短研发周期,降低失败风险。
驱动精准医疗:通过对个体多维度健康RDA的深度分析,AI可以为癌症、罕见病等复杂疾病提供高度个体化的诊疗方案。
赋能群体健康管理:公共卫生机构可以利用区域性的、经过隐私处理的健康数据资产,进行疾病传播预测、高风险人群分层与精准干预策略制定。
我们可以用下面的流程图来描绘这一协同过程:
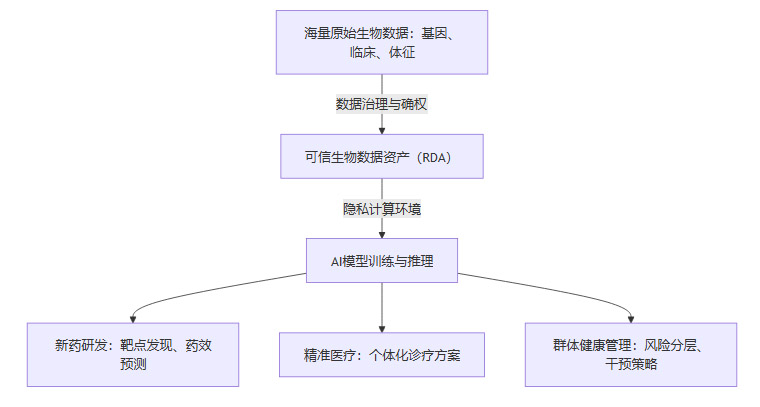
从本质上看,数据资产化(RDA)与人工智能(AI)的结合,正在推动生命健康产业从“数据堆积”阶段,向构建“智能生物大数据系统”的产业级能力阶段跃升。
四、💠 共同的基石与挑战:高敏感数据的伦理与合规
无论是学生的学习轨迹,还是个人的心跳节律,这些数据都触及了隐私和伦理的红线。在释放其巨大价值的同时,必须正视并解决其伴生的严峻挑战。这是RDA在教育与健康领域能否行稳致远的关键所在。
4.1 两大领域面临的共性风险
尽管场景不同,但教育和生命健康数据资产化面临的伦理风险具有高度的相似性。
教育数据风险:
标签固化与算法偏见:AI可能会根据学生的早期行为数据给其打上“差生”或“潜力股”的标签,这种固化的标签可能影响其后续获得的教育资源,形成“数据预定人生”的数字枷锁。
隐私与价值观暴露:学习数据不仅包含知识掌握情况,还可能反映学生的兴趣偏好、思维模式甚至价值观倾向。这些信息的滥用可能对未成年人造成深远影响。
健康与生物识别数据风险:
健康歧视与社会排斥:一旦个人的健康RDA被滥用,可能导致其在求职、信贷、社交等方面受到不公平待遇,例如保险公司可能基于基因数据拒保,或雇主可能拒绝录用有潜在健康风险的求职者。
“定向剥夺”风险:高风险群体的数据可能被用于“反向筛选”,使其无法获得某些社会资源或服务,加剧社会不公。
此外,跨平台、跨机构的数据共享与流通,极大地放大了数据泄露、滥用和“再识别”的风险。即使数据经过初步脱敏,攻击者仍可能通过关联多个数据集,重新识别出个体身份。因此,制度与技术的双重“降险”机制缺一不可。
4.2 强监管下的合规要求
中国的《网络安全法》、《数据安全法》和《个人信息保护法》等法律法规,已经构建起一套严格的数据合规框架。特别是对于教育、健康这类敏感个人信息,法律在知情同意、最小必要、处理目的、跨境传输等方面都提出了极高的要求。这为RDA的实践划定了清晰的法律底线,任何技术创新都必须在这一框架内进行。这种强监管环境,也反过来倒逼产业界必须寻求更强大的技术解决方案,以实现合规前提下的数据价值释放。
五、💠 技术基石:隐私计算构筑RDA落地的“安全门”

面对高敏感数据资产化的内在风险与外部强监管的双重压力,**隐私计算(Privacy-Preserving Computation, PPC)**技术栈从一个“可选项”变为了“必选项”。它不再是数据流通过程中的一个安全补丁,而是整个RDA生态赖以建立的底层技术基石。其核心理念是实现数据的“可用不可见”,即在不暴露原始明文数据的前提下,完成对数据的计算、分析与验证,从而在根源上化解隐私泄露的风险。
5.1 隐私计算技术栈概览
隐私计算并非单一技术,而是一个由多种技术构成的工具箱,每种技术适用于不同的应用场景,共同构成一个纵深防御体系。
5.2 场景化应用解析
将这些抽象的技术与教育、健康的具体场景结合,才能真正理解其价值。
5.2.1 零知识证明(ZKP):可信的“断言”而非“展示”
ZKP的核心是改变了数据验证的范式,从“展示原始凭证”转变为“提供一个无法伪造的、关于凭证的真实性证明”。
教育场景:
招生与求职:学生不再需要向学校或雇主提供完整的成绩单,只需提交一个ZKP证明,证实“平均绩点高于3.5”或“已修完所有必修课程”。对方可以验证该证明的有效性,但无法得知学生的具体分数或选课详情。
助学金申请:学生可以生成一个ZKP证明,证实其“家庭年收入低于特定标准”,而无需提交详细的银行流水或税务文件,极大保护了家庭隐私。
生命健康场景:
临床试验招募:患者可以提交ZKP证明,证实自己“年龄在40-60岁之间且患有2型糖尿病”,以满足入组条件,而无需向招募方暴露完整的病历。
保险核保:投保人可以证明自己“过去五年内无重大疾病住院记录”或“属于低风险健康人群”,保险公司据此完成核保,而无需获取敏感的医疗细节。
5.2.2 同态加密(HE):在“保险箱”里处理数据
HE技术允许数据在加密的“保险箱”中被处理,非常适合数据计算外包的场景。
教育场景:
教育质量评估:各学校将加密后的学生成绩数据上传至第三方评估机构的云平台。该机构在密文上完成区域平均分、方差等统计计算,并将加密结果返回。只有数据所有方(如教育局)用私钥解密后才能看到最终的统计结果。整个过程中,评估机构无法窥探任何一所学校或一个学生的原始成绩。
生命健康场景:
基因数据分析:用户将自己加密后的基因序列数据上传至云端分析服务商。服务商在密文上运行疾病风险预测算法,返回一个加密的风险评分。用户在本地解密后即可查看结果。这使得用户可以利用强大的云端算力,而不用担心最核心的基因隐私泄露。
5.2.3 多方安全计算(MPC)与联邦学习(FL):打破数据孤岛的“联盟”
当价值蕴藏在多个机构的数据融合中时,MPC与FL提供了安全协作的框架。
教育场景:
跨校联合建模:多所高校希望联合训练一个更精准的“学生流失预警模型”。通过联邦学习,每所学校在本地用自己的学生数据训练模型,仅将加密后的模型参数(梯度)上传至中心服务器进行聚合,更新全局模型。数据始终不出校门,但最终得到的模型汇集了所有学校的“智慧”。
生命健康场景:
多中心临床研究:多家医院希望联合分析某种罕见病的治疗效果,但法律禁止病历数据直接共享。通过MPC,它们可以共同完成对患者总数、平均治愈率等指标的统计计算,每家医院只知道最终的全局结果,但对其他医院的患者数据一无所知。
AI影像诊断:这是联邦学习的经典应用。多家医院联合训练一个肺结节CT影像识别模型。各医院的影像数据保留在本地,AI模型通过联邦学习框架“巡回”学习,最终性能远超任何单一医院数据训练出的模型。
5.2.4 差分隐私(DP):群体特征的“安全”发布
DP主要用于保护对外发布的聚合数据,确保个体信息无法从统计结果中被反推出来。
教育场景:
发布教育统计年鉴:教育部门在发布各地区、各学科的学生平均成绩、升学率等统计数据时,可以应用差分隐私技术,对结果添加微小噪声。这使得外界无法通过对比不同年份或不同地区的报告,精确推断出某个小规模学校或某个学生的具体信息。
生命健康场景:
公共卫生监测:疾控中心发布某区域的流感发病率地图。通过差分隐私处理,即使某个小区的发病人数极少,攻击者也无法确认该小区的具体某个人是否上报了病情。
综上,隐私计算技术栈为RDA在敏感领域的落地,提供了一套组合式的、深度防御的解决方案,使得在遵循法律法规和伦理要求的前提下,最大化地释放数据价值成为可能。
六、💠 制度与市场:数据要素化催生的新规则与新机遇
技术提供了可能性,但RDA的规模化发展离不开制度的规范和市场的驱动。在国家大力推进数据要素市场化配置的背景下,教育与生命健康领域的RDA生态正在加速形成。
6.1 统一标准体系的构建
当前,数据资产的“非标性”是制约其流通的最大障碍。建立一套统一的标准体系迫在眉睫,这包括:
数据分级分类:根据数据的敏感程度、价值密度、应用场景,对教育和健康数据进行精细化的分级分类,实施差异化的安全与流通策略。
确权与登记规则:明确数据生产、加工、使用等各环节参与方的权利与义务,建立基于分布式账本等技术的统一数据资产登记平台。
评估与定价机制:探索成本法、收益法、市场法相结合的数据资产价值评估模型,为RDA的公允定价和交易提供依据。
交易与溯源机制:在数据交易所等合规平台内,建立标准化的交易流程、清结算体系和全链路的数据流通溯源能力。
6.2 政策趋势与试点探索
从国家到地方,相关政策正在密集出台。各类数据要素发展大会和研究报告均将教育、医疗数据视为重点领域,积极推动“数据资产入表”、设立行业数据空间、开展“数据要素×”专项行动。这些政策信号明确指向,未来将大力支持“可信数据资产 + 隐私计算基础设施”的协同落地模式。
6.3 涌现的新业态与商业模式
随着市场的逐步成熟,围绕教育与健康RDA,一批全新的商业角色和业态正在涌现:
数据资产运营服务商:专业帮助学校、医院进行数据治理、资产化封装和价值运营,类似于数字世界的“资产管理公司”。
医疗数据信托机构:作为受法律严格监管的可信第三方,代为管理和运营患者授权的数据资产,确保其收益和安全。
隐私计算基础设施提供商:提供标准化的ZKP、MPC、FL等技术平台或PaaS服务,降低各机构应用隐私计算的门槛。
场景化RDA产品开发商:专注于特定场景,如上文提到的商业保险核赔模型、个性化学习推荐引擎等,开发可直接调用的RDA产品。
七、💠 实践路径:从理念到落地的四步走

对于身处其中的教育机构、医疗机构和科技企业而言,推动RDA落地需要一个清晰、务实的路线图。
第一步:先治理,后资产
数据资产化的前提是高质量的数据资源。任何机构在投身RDA浪潮之前,必须首先完成内部的数据摸底、清洗、标准化与权属梳理工作。没有坚实的数据治理基础,所谓的“资产”只是空中楼阁。第二步:“隐私优先”的架构设计
必须将隐私保护作为系统设计的首要原则(Privacy by Design),而不是在系统建成后“打补丁”。在系统架构设计阶段,就应预先嵌入访问控制、数据脱敏、加密存储与隐私计算组件,确保数据全生命周期的安全合规。第三步:小步快跑,场景切入
避免好高骛远,应从风险可控、价值明确的具体场景切入,小步快跑,快速验证。教育领域:可以从构建学生综合素质画像、优化课程评价体系、开展小范围的产教协同项目试点做起。
健康领域:可以从慢病管理数据分析、保险核赔风控建模、院内医疗质量控制等内部或低风险场景开始,逐步扩展到跨机构的数据协作。
第四步:建立伦理审查与公众沟通机制
技术和商业的成功,最终依赖于社会的信任。机构内部必须建立独立的数据伦理审查委员会,对RDA的应用进行前置评估。同时,需要通过白皮书、听证会等方式,积极与公众沟通,提升社会对数据资产化的理解与信任度,这是其可持续发展的根本保障。
结论
真实数据资产(RDA)正以前所未有的力量,重塑教育与生命健康这两个与每个人息息相关的领域。它通过将无形的学习轨迹和生命体征,转化为可信、可用、可流通的价值载体,为实现真正的个性化教育和精准医疗描绘了一幅激动人心的蓝图。然而,这条道路并非坦途,高敏感数据与生俱来的隐私与伦理挑战,是横亘其间的一道鸿沟。
跨越这道鸿沟的关键,在于技术与制度的双轮驱动。以零知识证明为代表的隐私计算技术栈,为我们提供了实现“可用不可见”的强大武器,构筑了数据价值安全释放的技术底座。与此同时,不断完善的法律法规、市场标准和治理机制,则为其健康发展提供了必要的制度保障。未来,谁能在这场创新与合规的精妙平衡中掌握先机,谁就将定义下一代数据驱动的教育与健康新范式,最终推动数字经济走向更高质量、更具包容性的发展阶段。
📢💻 【省心锐评】
RDA的价值释放,不在于数据本身,而在于驾驭其伴生风险的能力。隐私计算不是成本,而是数据资产化的入场券,是通往高价值蓝海市场的唯一通行证。

评论