.png)


【摘要】一种由具体问题驱动、以 AI 为导师的“递归式知识填补”学习范式,正取代传统线性课程。它强调通过构建可调试对象与制造认知摩擦,实现高效的深度学习与能力内化。
引言

技术领域的知识半衰期正在以前所未有的速度缩短。传统的、以课程为单位的线性学习路径,在应对当前技术爆炸时显得愈发笨拙。一个工程师花费数年时间,系统性地学习完计算机科学的底层基础,当他终于准备好进入前沿领域时,却可能发现技术栈已经迭代了数个版本。这种模式的反馈周期太长,学习过程与实际应用脱节,导致了极高的学习者流失率。
Gabriel Petersson 的经历,为我们提供了一个截然不同的样本。他没有传统的学术背景,却在几年内成长为 OpenAI 的研究科学家,参与 Sora 模型的研发。他的成功并非偶然,其背后是一套极具启发性的、适应 AI 时代的新型学习操作系统。这套系统摒弃了“先学后做”的陈旧观念,转向一种“边做边学、遇山开路”的工程化学习方法。
本文将深度剖析这套以“递归追问”为核心的方法论。我们将探讨其底层的学习范式转变,解析其具体的操作流程与风险控制机制,并最终将其延伸至更广泛的职业发展与个人能力构建领域。这不仅是一个人的成长故事,更是一份面向未来的、可供所有技术从业者参考的学习与进化指南。
❖ 一、学习范式的结构性变革
%20拷贝-lodz.jpg)
传统的知识获取模型,如同瀑布式开发,遵循着严格的线性顺序。而 Gabriel 所践行的方法,更像是一种敏捷开发,它以问题为中心,进行快速迭代和增量学习。
1.1 传统线性学习路径的局限
长期以来,我们习惯于一种“自下而上”的学习模式。以机器学习为例,标准路径通常如下所示。
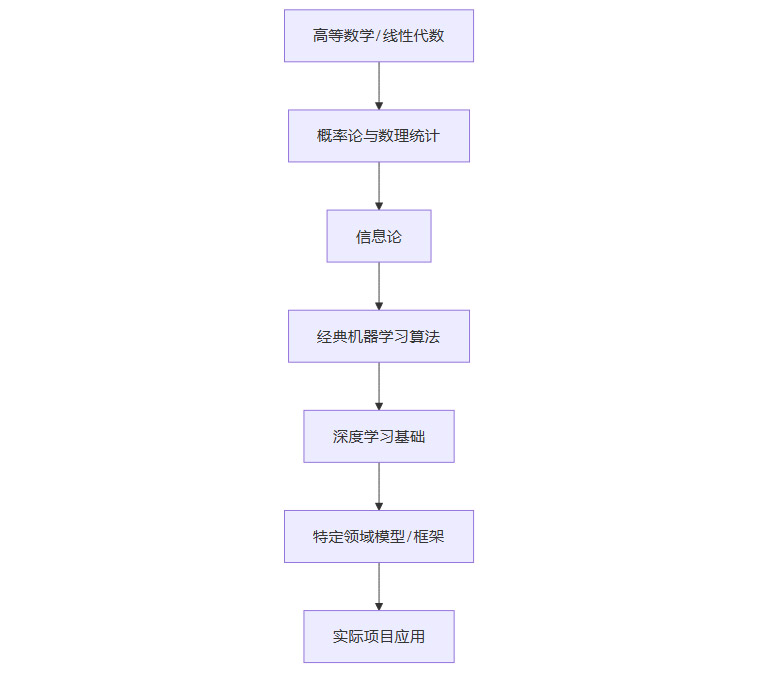
这个路径逻辑严谨,知识体系完整,但存在几个致命缺陷。
超长反馈周期。学习者需要投入大量时间在基础理论上,可能长达一两年才能接触到第一个能产生实际价值的项目。在此期间,他们无法获得即时的、正向的反馈,学习动机很容易被消磨殆尽。
知识与应用的脱节。孤立地学习理论知识,很难理解其在复杂工程问题中的实际应用场景。例如,学习拉格朗日乘子法时,如果不知道它在支持向量机(SVM)中的关键作用,这个概念就只是一个抽象的数学工具,难以形成深刻记忆。
高昂的启动成本。这种模式要求学习者具备极强的自律性和毅力,以克服前期漫长而枯燥的理论学习阶段。这无形中筑起了一道高墙,将许多潜在的优秀人才挡在门外。
1.2 问题驱动的非线性学习范式
与线性路径相对,一种“自上而下”的、问题驱动的非线性学习范式正在兴起。它的核心逻辑是,从一个明确且具体的目标或任务切入,在实践过程中主动暴露知识缺口,然后利用工具进行精确、高效的“即时学习”。
这个范式的流程可以被抽象为以下循环。
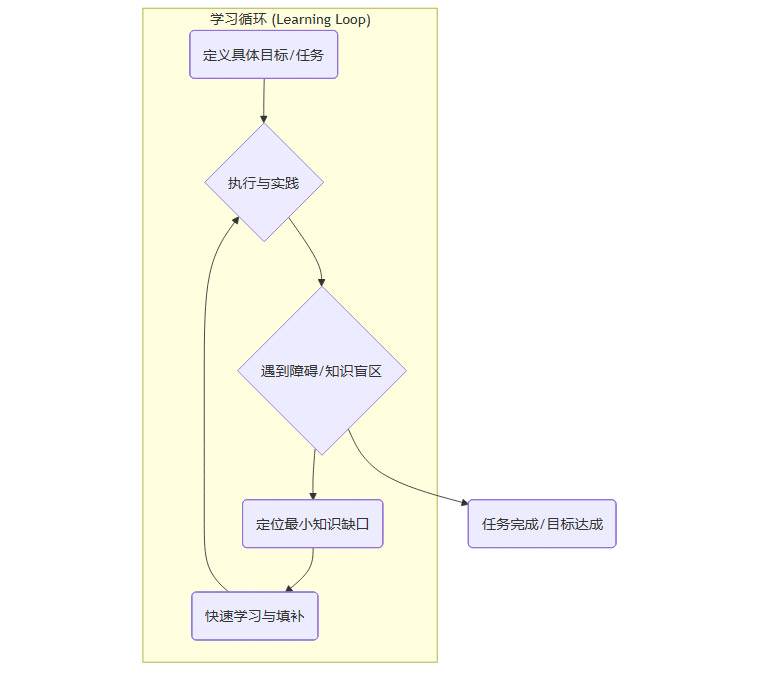
这种模式的优势显而易见。
即时反馈与高动机。每解决一个问题,填补一个知识缺口,都能在项目中看到立竿见影的效果。这种持续的正反馈是维持学习动力的关键。
知识与场景强绑定。所有学到的知识都直接服务于当前的目标,因此理解得更深刻,记忆也更牢固。你知道为什么要学这个,以及它能用在哪里。
低启动成本。你不需要成为一个领域的专家才能开始。你只需要有一个足够小的、可以上手的项目,然后就可以启动这个学习循环。
在过去,这种模式的主要障碍在于,当遇到知识缺口时,寻找一个能够随时提供精确、深度解答的导师是极其困难的。而现在,大型语言模型(LLM)的出现,完美地填补了“全知导师”这一角色,使得这种高效的学习范式变得前所未有的可行。
❖ 二、核心方法论 “递归式知识填补”深度解析
“递归式知识填补”(Recursive Gap-Filling)是问题驱动学习范式的具体实现。它是一种将复杂系统拆解,并对每个未知模块进行深度钻研的结构化学习技术。其本质,是将学习过程本身,视为一次对未知代码库的调试(Debugging)。
2.1 原则一 “代码/产出先行”以构建可调试对象
在传统的学习观念中,“先看懂再动手”是金科玉律。但在递归式学习中,这个顺序被颠倒了。我们强调“产出先行”,即先让系统以最快速度跑起来,哪怕它非常粗糙,甚至充满了我们不理解的“黑箱”。
这么做的目的,不是为了投机取巧,而是为了构建一个“可调试对象”(Debuggable Object)。一个可运行的程序、一个可交互的原型、一份可验证的报告,它们为我们的学习提供了一个具体的“实体”。没有这个实体,我们的理解很容易停留在抽象的口号和模糊的概念上。
以学习扩散模型(Diffusion Models)为例,传统方法会让你先去读懂相关的数学论文,理解马尔可夫链、变分推断等复杂概念。而递归式学习的第一步,则是直接向 AI 索要一个最小化的实现。
示例 Prompt:
“请用 Python 和 PyTorch 实现一个最简单的 Denoising Diffusion Probabilistic Models (DDPM),用于在 MNIST 数据集上生成手写数字。不需要复杂的网络结构,使用一个简单的 U-Net 即可。请确保代码可以完整运行,并附上所有必要的依赖和启动脚本。”
拿到这段代码后,我们可能 80% 的内容都看不懂。但这不重要。重要的是,我们可以运行它,看到它生成模糊的数字,然后逐渐变得清晰。这个运行过程本身,就为我们建立了关于扩散模型的第一个直观感受。更关键的是,我们现在有了一个可以设置断点、打印变量、修改参数并观察结果的“沙盒”。我们的学习,将围绕这个沙盒展开。
2.2 原则二 结构化的递归追问循环
有了可调试对象,下一步就是进入核心的追问循环。这个过程不是随机的、碎片化的提问,而是一种结构化的、层层深入的探索。我们可以将追问的层次定义为以下几个阶段。

2.2.1 第一层追问 What (它是什么)
这是最基础的定义层。针对代码中的一个具体模块或函数,我们要问清楚它的功能和输入输出。
Prompt 示例:“在 DDPM 代码中,
noise_scheduler这个类的作用是什么?它的add_noise方法和step方法分别接收什么参数,返回什么结果?”
2.2.2 第二层追问 Why (为什么需要它)
这是设计理念层。我们要理解这个模块存在的必要性,以及它在整个系统中的位置和价值。
Prompt 示例:“为什么在训练扩散模型时,需要逐步向图像中添加噪声?直接从原图预测一个完全噪声的图像,或者反过来,从噪声一次性生成原图,为什么不可行?”
2.2.3 第三层追问 How (它是如何实现的)
这是深入原理层。对于关键模块,我们需要追问其背后的数学原理或算法逻辑。
Prompt 示例:“请详细解释
noise_scheduler中beta序列是如何生成的?alpha和alpha_bar是如何根据beta计算出来的?请给出具体的数学公式,并解释每个符号的含义。”
2.2.4 第四层追问 What-if (如果改变它会怎样)
这是边界探索层。通过提出假设性问题,我们可以检验自己是否真正理解了模块的核心约束和工作边界。
Prompt 示例:“如果我将
beta的调度策略从线性(linear)改为余弦(cosine),会对模型的训练过程和生成结果产生什么影响?为什么余弦调度在某些情况下效果更好?”
通过这样一套结构化的追问流程,我们能像剥洋葱一样,一层层地揭开复杂系统的面纱。每完成一个模块的追问循环,就意味着我们填补了一个知识缺口。当所有关键模块都被“点亮”后,我们对整个系统的理解就从一个模糊的黑箱,变成了一个清晰的白盒。
❖ 三、AI 的角色定位 从“执行者”到“教练”
%20拷贝-fuus.jpg)
工具的价值,取决于使用它的人。同样是大型语言模型,不同的使用方式会导向截然不同的结果。一种是能力的外包与退化,另一种是能力的加速与进化。其根本区别在于,你是否在与 AI 的交互中,保留了必要的“认知摩擦”(Cognitive Friction)。
3.1 “认知萎缩”陷阱 AI 作为执行者
当我们将 AI 视为一个单纯的“执行者”或“代工厂”时,我们实际上是在将自己的思考过程外包出去。这种模式下,我们只关心最终的产出,而忽略了通往产出的路径。
场景一 编码。你向 AI 描述需求,它返回代码。你复制、粘贴、运行。代码跑通了,任务完成了。但如果此时关闭 AI,让你手写一遍核心逻辑,你可能会发现大脑一片空白。
场景二 写作。你给出主题和提纲,AI 生成文章。你润色、修改、发布。文章看起来很专业,但其中的论证逻辑、遣词造句,都不是经由你自己的大脑构建的。
微软研究院与卡内基梅隆大学的研究证实了这种现象。频繁使用生成式 AI 完成任务的个体,其批判性思维和创造性解决问题的能力会显著下降。医学领域的研究也发现,过度依赖 AI 辅助诊断的医生,其自身的诊断技能会在数月内出现 measurable 的衰退。
这背后的机制是**“用进废退”**。当我们绕过思考的艰难过程,直接获取答案时,我们大脑中负责推理、分析和创造的神经网络连接,就失去了被激活和强化的机会。久而久之,这些能力便会自然萎缩。
3.2 “能力增强”路径 AI 作为教练
要避免认知萎缩,就必须重新定位 AI 的角色,将其从一个“执行者”转变为一个**“认知教练”(Cognitive Coach)或“思维陪练”(Sparring Partner)**。在这个模式下,AI 的主要价值不再是提供答案,而是激发和深化我们自己的思考。
下表对比了两种模式在不同任务中的具体差异。
在教练模式下,我们始终是思考的主体。AI 负责提供信息、启发思路、扮演对手、进行评估。每一次交互,都是一次对我们自身知识体系的检验和拓展。这个过程充满了“认知摩擦”,它要求我们把模糊的想法清晰化,把被动的接受转化为主动的探究。正是这种摩擦,才让知识真正“长”在了我们自己的大脑里。
3.3 强制内化的实践机制
为了确保学习效果,我们需要建立一套机制,将从 AI 那里获取的外部知识,强制转化为我们自己的内部能力。
复述与转述。在理解一个新概念后,尝试用自己的话重新组织并向 AI 复述一遍。甚至可以要求 AI 扮演一个初学者,由你来向它“教学”。
举一反三。要求 AI 举一个与当前例子完全不同领域的案例,来解释同一个原理。然后,由你自己再想出第三个例子。
手动复现。对于代码或技术实现,在理解之后,关掉参考答案,凭记忆和理解在空白编辑器中完整地复现一遍。这个过程会暴露许多你自以为“看懂了”但实际并未掌握的细节。
构建小测验。让 AI 针对你刚学完的知识点,生成几个选择题、填空题或简答题,进行自我测试。这是一种简单高效的知识固化手段。
通过这些机制,我们可以确保自己不只是知识的“搬运工”,而是知识的真正“消化者”和“创造者”。
❖ 四、风险管控 递归学习中的“地基”问题
递归式学习方法虽然高效,但它也存在一个重大风险。由于整个学习过程是建立在一系列连续追问之上的,如果这个追问链的“地基”——即 AI 提供的某个底层解释——是错误的,那么基于这个错误解释构建起来的整个知识大厦都将是空中楼阁。这就是**“幻觉的放大效应”**。
4.1 错误地基的风险传导
大型语言模型存在“幻觉”(Hallucination)现象,即一本正经地编造事实。在递归追问中,这种风险会被急剧放大。
假设在学习扩散模型的过程中,AI 在解释噪声调度器时,给出了一个错误的 alpha_bar 计算公式。你基于这个错误的公式,继续向下追问,推导出了后续的所有步骤。你可能会花费数小时,构建起一套看似逻辑自洽但实际上完全错误的理论体系。当你最终发现地基是错误的时候,推倒重来的成本将非常高昂。
这种风险传导机制,类似于软件工程中底层模块的 Bug。一个隐藏在核心库里的微小错误,可能会引发上层应用中一系列莫名其妙的、难以排查的连锁反应。
4.2 多层交叉验证协议
为了规避这一风险,我们必须在递归学习的过程中,引入一套严格的多层交叉验证协议。尤其是在涉及到关键的、基础性的概念时,绝不能轻信单一来源的信息。
4.2.1 第一层 模型交叉验证
这是最快捷的验证方式。将同一个关键问题,同时抛给多个不同的、基于不同架构或训练数据的大型语言模型。
工具组合。例如,可以同时使用 OpenAI 的 GPT-4、Anthropic 的 Claude 3 和 Google 的 Gemini。
验证方法。对比它们的回答。如果三者给出的核心解释(尤其是公式、关键参数、基本定义)完全一致,那么该信息的可信度就较高。如果出现分歧,就需要启动更高层级的验证。
4.2.2 第二层 来源交叉验证
对于严肃的技术学习,不能完全依赖于经过模型“消化”后的二手信息。必须养成**追溯原始信息来源(Source of Truth)**的习惯。
权威文献。要求 AI 提供其解释所依据的核心论文。例如,在学习 DDPM 时,就应该找到并粗读《Denoising Diffusion Probabilistic Models》这篇原始论文,核对关键公式。
官方文档。如果是学习某个框架或库,官方文档是最高优先级的信源。
高质量图书。经典的、经过同行评审的技术书籍,其内容的准确性远高于网络上的博客文章。
4.2.3 第三层 实验交叉验证
对于算法和代码,实践是检验真理的唯一标准。最可靠的验证方式,就是编写一个最小化的实验来亲自验证。
构建最小可复现示例(MRE)。针对一个有疑问的知识点,编写一小段独立的、不依赖于复杂项目的代码来测试它。
单元测试思维。将学习过程中的每个关键断言,都视为一个需要通过测试用例来验证的假设。例如,如果你不确定某个数学变换的实现是否正确,可以手动计算一个简单的输入,然后与代码的输出进行比对。
通过这套**“模型 -> 来源 -> 实验”**的三层验证协议,我们可以最大限度地确保我们递归学习的地基是稳固的,从而避免在错误的道路上越走越远。
❖ 五、知识沉淀的形态演变
%20拷贝-pwqq.jpg)
在传统的评价体系中,学历和证书是衡量个人知识水平的主要凭证。然而,在一个技术快速迭代、终身学习成为常态的时代,这种静态的、一次性的认证方式正在失去其原有的说服力。Gabriel Petersson 的经历,特别是他在申请美国“杰出人才”签证时的做法,为我们揭示了一种新型的、动态的知识沉淀与能力证明方式。
5.1 从静态证书到动态贡献
传统的学历教育,其产出物是静态的。一张毕业证书,证明的是你在过去某个时间点,完成了某个预设课程体系的学习。它无法反映你毕业后的持续学习能力,也无法体现你在特定工程领域的实战经验。
与之相对,AI 时代的能力证明体系,正在转向一种动态的、可验证的公开贡献。这种体系的核心,不再是你“学过什么”,而是你“做过什么”以及“分享过什么”。
Gabriel 将自己在程序员社区发布的高质量技术帖子,整理作为“学术贡献”的替代证明,并成功获得移民局的认可。这个案例极具象征意义。它表明,由实际项目驱动、经过社区验证的知识产出,其价值正在被主流评价体系所承认。
5.2 构建个人“能力证据链”
对于技术从业者而言,有意识地构建自己的“能力证据链”,其重要性日益凸显。这不仅是为了求职或职业发展,更是为了系统化地沉淀和反思自己的学习成果。
5.2.1 技术博客 思考的结构化输出
撰写技术博客,是强制自己将碎片化的思考进行结构化、体系化梳理的最佳方式。当你尝试向他人清晰地解释一个复杂概念时,你会立刻发现自己理解上的所有模糊地带。**“以教为学”(Learning by Teaching)**是最高效的学习方法之一。
实践建议。不要追求长篇大论。可以将每一次“递归追问”的过程,都整理成一篇短小精悍的博文。例如,“DDPM 中 Cosine 噪声调度策略的直观理解与代码实现”。
5.2.2 开源贡献 协作与工程能力的证明
参与或发起开源项目,是展示你工程实践能力、代码规范以及团队协作能力的硬通货。
实践建议。可以从为知名项目提交一个简单的文档修复 PR(Pull Request)开始,逐步过渡到修复 Bug,乃至贡献新功能。或者,将自己学习过程中的最小化示例代码(MRE)整理成一个独立的、文档齐全的 GitHub 仓库,供他人学习和使用。
5.2.3 社区答疑 知识的“反刍”与深化
在 Stack Overflow、GitHub Discussions 或专业论坛上回答他人的问题,是一种绝佳的知识“反刍”过程。它迫使你从不同角度审视同一个问题,并在帮助他人的过程中,深化自己的理解。
通过持续地进行这些公开贡献,你不仅在为社区创造价值,更是在为自己构建一条不可伪造、持续更新、可被随时验证的能力证据链。这条证据链,在很多时候,比一纸文凭更具说服力。
❖ 六、方法论的通用迁移
“递归式知识填补”这套方法论,其核心思想——目标驱动、即时反馈、迭代修正——具有极强的通用性,完全可以从编程和 AI 领域,迁移到任何需要深度学习和技能提升的场景。
6.1 跨领域应用的统一框架
无论是学习市场营销、金融分析,还是产品设计,我们都可以套用一个统一的五步框架。
定义一个具体的可交付任务(Task)。
市场营销:为一款新产品设计一个为期一周的社交媒体推广活动方案。
金融分析:基于某上市公司的公开财报,撰写一份投资价值分析报告。
产品设计:为一个在线教育 App 设计用户注册与登录流程的原型。
构建最小可行闭环(Minimum Viable Loop)。
市场营销:利用 AI 生成一个最基础的推广文案和图片模板,先在自己的社交账号上发布测试。
金融分析:利用 AI 提取财报中的关键数据,并生成一个初步的 SWOT 分析框架。
产品设计:使用即时原型工具(如 a16z 的 a16z-infra/v0),根据文本描述生成一个可交互的初步界面。
针对闭环中的未知模块进行递归追问。
市场营销:“为什么这个文案的 CTA(Call to Action)是这样设计的?A/B 测试是什么?如何设计一个有效的 A/B 测试来验证文案效果?”
金融分析:“什么是‘自由现金流’?它为什么比‘净利润’更能反映公司的真实价值?请解释计算公式并举例。”
产品设计:“为什么推荐使用‘手机号+验证码’而非‘邮箱+密码’的注册方式?这背后的用户心理和安全考量是什么?”
通过交叉验证确保关键认知。
市场营销:查找经典的营销学著作(如《定位》)或权威的市场分析报告,验证 AI 提供的策略建议。
金融分析:核对公司财报原文,或参考知名券商的研究报告,验证关键财务数据的准确性。
产品设计:参考主流 App(如微信、支付宝)的实际设计,并阅读相关的用户体验设计指南(如 Apple Human Interface Guidelines)。
沉淀为可复用的资产(Asset)。
市场营销:将成功的推广活动流程,整理成一份标准作业程序(SOP)。
金融分析:将分析报告的框架,制作成一个可复用的模板(Template)。
产品设计:将设计过程中的思考和决策,记录成一份设计文档(Design Doc)。
通过这个框架,任何领域的学习者都可以将抽象的知识学习,转化为具体的、以产出为导向的技能训练。
6.2 职业趋势 “一专多能”的 T 型人才
AI 极大地降低了跨学科学习的入门成本。在过去,要掌握一门新领域的知识,达到 80 分的水平,可能需要数年的专业学习。而现在,借助 AI 作为“教练”,这个过程可能被缩短到几个月甚至几周。
这将深刻地改变未来的职业形态和人才结构。“一专多能”的 T 型人才将成为主流。这里的“T”,指的是一个深厚的专业领域(“一竖”),以及多个涉猎广泛、达到可用水平的辅助领域(“一横”)。
程序员 + 产品设计 + 商业分析 = 独立开发者 / 产品经理
内容创作者 + 数据分析 + 编程 = 增长黑客 / 技术型创作者
设计师 + 3D 建模 + 营销 = 全链路品牌设计师
递归式学习法,正是打造 T 型结构中那一“横”的利器。它使得个人能够根据项目需求,快速补齐自己的能力短板,从而形成更完整的、端到端的交付能力。“一人公司”(One-Person Business)的形态将变得越来越普遍,因为个体借助 AI 的杠杆,其生产力的上限被极大地提升了。
❖ 七、构建个人化的“追问清单”
%20拷贝-rddx.jpg)
为了将递归式学习法从一种“心法”固化为一种“流程”,我们可以为自己构建一套标准化的“追问清单”(Interrogation Checklist)。这套清单可以在我们学习任何新知识时,作为思维的脚手架,确保我们探索的深度和广度。
7.1 模板化追问清单示例
以下是一个通用的追问清单模板,可以根据不同领域的特点进行定制。
第一阶段 概念层 (Conceptual Layer)
定义 (Definition):它是什么?用最简单的语言(或一个比喻)来解释。
目的 (Purpose):它解决了什么问题?为什么需要它?
输入/输出 (I/O):它接收什么作为输入,产出什么作为结果?
分类 (Taxonomy):它属于哪个更大的知识类别?与它的“兄弟”概念(相似但不同)有什么区别?
第二阶段 原理层 (Principle Layer)
核心机制 (Core Mechanism):它的内部工作原理是怎样的?可以分解为哪几个关键步骤?
数学/逻辑推导 (Derivation):如果是算法或模型,其背后的关键公式是如何推导出来的?
设计权衡 (Trade-offs):它在设计上做了哪些权衡?为了得到 A,牺牲了 B,为什么这个权衡是值得的?
历史演进 (Evolution):它是如何演变至今的?它的前身是什么?解决了前身的什么问题?
第三阶段 实现层 (Implementation Layer)
伪代码/流程图 (Pseudocode/Flowchart):它的核心逻辑可以用伪代码或流程图表示吗?
关键参数 (Key Parameters):在实际实现中,有哪些关键参数需要调整?每个参数的作用和影响是什么?
常见陷阱 (Common Pitfalls):在实现或使用它时,有哪些常见的错误或“坑”?
替代方案 (Alternatives):除了当前这种实现方式,还有哪些主流的替代方案?它们各自的优缺点是什么?
第四阶段 验证层 (Validation Layer)
边界条件 (Boundary Conditions):它在什么情况下会失效或表现不佳?
性能评估 (Performance Evaluation):如何衡量它的好坏?有哪些关键的评估指标?
可复现性 (Reproducibility):如何构建一个最小化的实验来验证它的核心功能?
反例 (Counterexample):能举出一个它不适用的反例吗?
通过将这套清单内化为自己的思维习惯,我们可以在面对任何未知领域时,都能进行系统化、结构化的深度学习,而不是停留在表面的、碎片化的信息获取上。
结论
Gabriel Petersson 的故事,并非一个无法复制的传奇。它揭示了一种在 AI 时代背景下,更为高效、更为务实的个人成长路径。这条路径的核心,是从被动地接收知识,转向主动地构建知识。
我们必须认识到,大型语言模型带来的最大变革,并非是让我们能更快地“得到答案”,而是让我们拥有了一个前所未有的、能够进行无限次深度对话的“思维陪练”。我们与这个“陪练”的交互质量,直接决定了我们自身的成长速度。
如果我们满足于第一个答案,我们就在通往认知懒惰的下行扶梯上。但如果我们能像 Gabriel 一样,将每一次提问都作为下一次提问的起点,不断地进行递归追问,直到将外部信息内化为自己的直觉和能力,那么 AI 就会成为我们认知能力的放大器。
最终,决定我们未来竞争力的,不再是我们掌握了多少存量知识,而是我们掌握新知识的速度和深度。而这一切的起点,或许只是一个简单而强大的习惯,别停在第一个答案,继续问下去。
📢💻 【省心锐评】
AI 时代的核心竞争力,是从“知识的消费者”转变为“知识的构建者”。利用 AI 作为认知杠杆,通过结构化的递归追问,将外部信息高效内化为个人能力,是实现个人能力跃迁的关键路径。

评论