.png)


【摘要】哥伦比亚大学团队开发的Neuro2Semantic框架,仅需30分钟iEEG数据即可高效解码大脑中的语言语义内容,推动脑机接口技术迈向实用化。本文深度解析其原理、实验、优势与未来前景。
引言
想象这样一个场景:一位因疾病失语的患者,医生却能通过一台设备,直接“读取”他脑海中的想法,将其转化为自然流畅的语言。这种曾经只属于科幻小说的情节,正被哥伦比亚大学的研究团队一步步拉进现实。2025年即将发表于Interspeech 2025的重磅论文,首次展示了Neuro2Semantic——一个能够用极少量(仅30分钟)颅内脑电图(iEEG)数据,重建大脑中连续语言语义内容的创新框架。团队不仅实现了技术突破,还将代码与模型开源,推动整个领域的进步。
本文将带你深入剖析Neuro2Semantic的技术原理、实验设计、创新点、局限性与未来展望。无论你是AI、神经科学、医疗工程还是脑机接口领域的从业者,亦或是对人脑与语言奥秘充满好奇的技术爱好者,都能在这里找到属于你的“知识兴奋点”。

一、🧩 脑机接口的进化:从科幻到现实
1.1 脑机接口的历史与现状
1.1.1 脑机接口的起源
脑机接口(Brain-Computer Interface, BCI)最早的设想可以追溯到20世纪60年代。彼时,科学家们开始尝试用电极记录动物大脑活动,并试图将这些信号转化为外部设备的控制指令。随着神经科学、电子工程和计算机科学的交叉融合,BCI逐渐从实验室走向临床和消费级应用。
1.1.2 现有脑机接口技术类型
目前主流的脑机接口技术主要包括:
其中,iEEG因其高时间和空间分辨率,成为解码大脑语言活动的“黄金标准”。
1.1.3 脑机接口的应用前沿
运动意图解码(如假肢控制)
视觉/听觉刺激重建
语言与语音解码
情感与意图识别
辅助沟通设备(如ALS患者)
1.2 神经语言解码的挑战
1.2.1 运动意图 vs. 语义内容
以往的神经解码多聚焦于“运动意图”——即大脑如何指挥发声器官产生语音。这类方法虽然在语音合成上取得进展,但往往忽略了语言的“语义层面”。而真正的“思想到语言”解码,必须跨越语音运动与语义内容之间的鸿沟。
1.2.2 数据稀缺的困境
神经解码模型的训练极度依赖高质量数据。由于iEEG等侵入性技术的伦理和临床限制,研究者往往只能获得极为有限的样本。如何在“数据极度稀缺”的条件下,训练出泛化能力强、语义准确的解码模型,是该领域的核心难题。
1.2.3 语义解码的技术瓶颈
现有fMRI/MEG语义解码受限于低时间分辨率
iEEG语义解码研究稀少,缺乏高效方法
传统方法多依赖大规模数据和预定义词汇,难以实现“开放域”解码
二、🔗 Neuro2Semantic:大脑与语言的桥梁
2.1 框架总览
Neuro2Semantic的核心思想,是将大脑神经信号与自然语言的“语义嵌入空间”对齐,再通过生成模型还原为连贯文本。其两阶段架构如下:
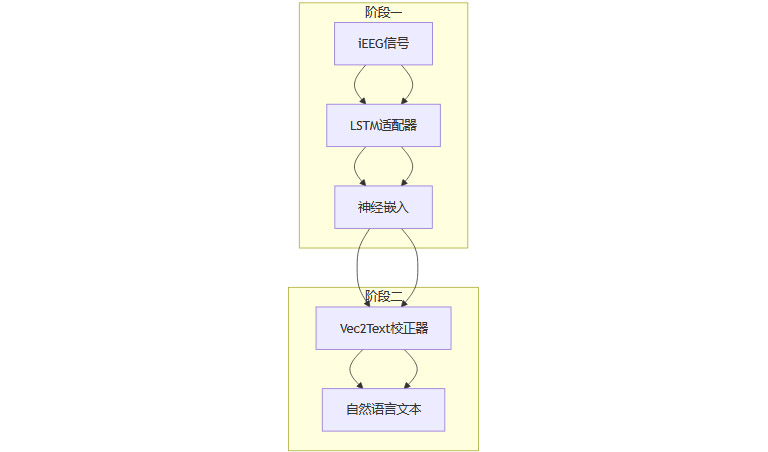
2.2 阶段一:LSTM适配器——神经信号到语义嵌入
2.2.1 LSTM适配器的作用
输入:预处理后的iEEG信号片段
输出:与文本嵌入空间对齐的“神经嵌入”
目标:让神经嵌入与对应文本嵌入在高维空间中“靠得更近”,与非对应文本“拉得更远”
2.2.2 对齐损失函数设计
采用对比损失(Contrastive Loss)与三元组边际损失(Triplet Margin Loss)的加权组合,确保:
神经嵌入与其对应文本嵌入距离最小
神经嵌入与非对应文本嵌入距离最大
2.2.3 技术细节
LSTM网络结构,适合处理时序信号
批次级相似度优化,提升对齐效率
训练时冻结后续阶段参数,防止信息泄漏
2.3 阶段二:Vec2Text校正器——语义嵌入到自然语言
2.3.1 Vec2Text校正器的任务
输入:对齐后的神经嵌入
输出:连贯的自然语言文本序列
目标:生成文本的语义嵌入与输入神经嵌入尽可能接近
2.3.2 生成过程
以受控生成(Controlled Generation)方式,逐步优化生成文本
每一步最小化当前文本嵌入与目标嵌入的距离
采用NLL(负对数似然)损失,提升文本流畅度
2.3.3 微调策略
仅微调Vec2Text校正器,LSTM适配器参数保持冻结
保证语义对齐不被破坏,提升泛化能力
2.4 “翻译官”类比助理解
阶段一:建立“神经信号-语义词典”
阶段二:用“语法规则”将词典内容组织成自然语言句子
三、🧪 实验设计:极限数据下的突破
%20拷贝.jpg)
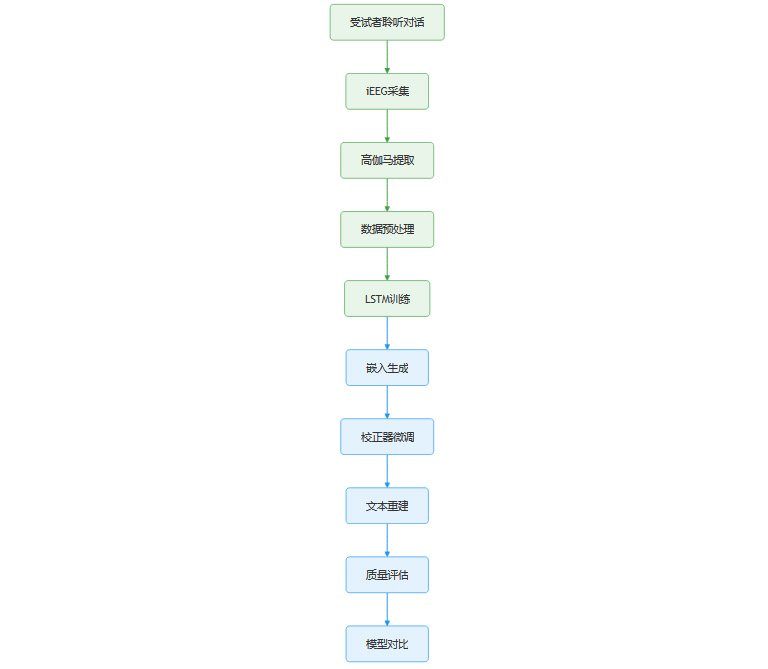
3.1 受试者与数据采集
3.1.1 受试者信息
3名药物难治性癫痫患者
临床植入iEEG电极(共864个电极点)
伦理审批与知情同意
3.1.2 刺激材料与任务
6段自然对话录音(类似播客)
总时长约30分钟
任务:被试聆听对话,记录大脑活动
3.1.3 数据预处理
提取高伽马频带(70-150Hz)包络
下采样至100Hz
过滤与显著性电极选择
3.2 训练与验证策略
3.2.1 留一法交叉验证
每个故事的最后一个试验留作测试
其余数据用于训练
防止信息泄漏,保证泛化性
3.2.2 训练参数
对比损失温度参数τ=0.1,α=0.25
参数通过坐标下降优化
3.2.3 评估指标
BLEU分数:表面级文本相似度
BERTScore:深层语义相似度
3.2.4 基线模型
Tang等人贝叶斯解码方法
波束搜索+多变量高斯建模
适配iEEG特性
3.3 实验流程图
四、🌟 研究结果:30分钟数据的惊艳表现
4.1 性能对比:Neuro2Semantic vs. 基线
4.1.1 语义准确性大幅领先
BERTScore显著高于基线,语义还原能力强
BLEU分数也有明显提升,文本表面相似度更高
4.1.2 典型案例对比
Neuro2Semantic能抓住“思乡”核心语义,基线模型则偏离主题
4.1.3 零样本泛化能力
在完全未见过的故事上,BERTScore和BLEU分数依然优于基线
证明模型不仅“记忆”训练内容,更能泛化到新语义
4.2 数据量与电极数量的影响
4.2.1 训练数据扩展性
随着训练数据从20%到100%递增,BERT/BLEU分数线性提升
说明模型对数据量极为敏感,更多数据=更强泛化
4.2.2 电极数量扩展性
电极数量增加,性能同样线性提升
但误差条较大,提示部分电极贡献远高于其他
存在“最优电极覆盖模式”可进一步优化
4.3 结果可视化(示意)
五、🚀 技术创新与局限性深度剖析
%20拷贝.jpg)
5.1 Neuro2Semantic的核心优势
5.1.1 极致高效的数据利用
仅需30分钟iEEG数据即可训练
远低于传统方法16小时+的数据需求
5.1.2 真正的“开放域”语义解码
不依赖预定义词汇表
可生成任意自然语言文本,突破检索/分类框架限制
5.1.3 两阶段架构的创新
LSTM适配器+Vec2Text校正器分工明确
对齐阶段为泛化打下坚实基础
微调阶段提升文本生成质量
5.1.4 零样本泛化能力
可解码未见过的语义内容
适应新领域、新任务无需额外微调
5.1.5 可扩展性强
数据量、电极数量增加,性能线性提升
未来有望通过更大数据集和更密集电极进一步提升
5.2 局限性与改进空间
5.2.1 样本量与人群局限
仅3名临床患者,泛化性有限
需更多健康受试者、多样化语料验证
5.2.2 侵入性技术的现实障碍
iEEG需开颅植入,难以大规模推广
未来需探索非侵入性EEG/MEG等替代方案
5.2.3 模型架构的进一步优化
当前对齐阶段基于LSTM,未来可尝试Transformer等更强大结构
需更大数据集支撑
5.2.4 电极分布优化
存在“最优电极覆盖模式”,需进一步研究
结合功能定位与个体差异,提升信息提取效率
5.2.5 多模态融合的潜力
融合fMRI、MEG等多模态数据,获取更全面大脑活动视图
有望进一步提升解码准确率
六、🔮 未来展望:从实验室到现实世界的跃迁
6.1 医疗与辅助沟通的革命
6.1.1 失语症与渐冻症患者的“新声音”
Neuro2Semantic的最大应用前景之一,就是为因中风、ALS(渐冻症)、脑外伤等原因失去语言能力的患者,带来全新的沟通方式。传统的辅助沟通设备(如眼动仪、拼写板)速度慢、表达受限,而基于大脑信号的直接语言解码,有望实现“所思即所言”,极大提升患者生活质量。
6.1.2 临床康复与神经重塑
术后康复:通过追踪大脑语言区的活动变化,辅助医生评估康复进展。
神经可塑性研究:揭示大脑在语言损伤后如何重组,指导个性化康复方案。
6.2 认知科学与脑功能图谱
6.2.1 语言加工机制的“显微镜”
Neuro2Semantic为认知神经科学家提供了前所未有的工具,能够实时、精细地观察大脑如何编码、处理和表达语义信息。这不仅有助于揭示语言产生的神经机制,还能推动对阅读障碍、失语症等疾病的本质理解。
6.2.2 个体化大脑-语言映射
探索不同个体在语义编码上的差异
构建个性化的“神经语义指纹”,为精准医疗和教育提供数据支持
6.3 脑机接口的下一站:非侵入与多模态
6.3.1 非侵入式技术的突破
虽然iEEG在精度上无可匹敌,但其侵入性限制了大规模应用。未来,随着高密度EEG、MEG等非侵入式技术的进步,结合Neuro2Semantic的算法框架,有望实现“无创”大脑语言解码。
6.3.2 多模态融合的前景
将iEEG与fMRI、MEG等多种神经成像手段结合,利用各自的优势(如空间分辨率、全脑覆盖),有望进一步提升解码的准确性和鲁棒性。多模态数据的融合,也将推动“全脑语义地图”的绘制。
6.3.3 智能硬件与实时应用
便携式脑机接口设备的开发
实时语音合成与翻译
智能家居、虚拟助手等场景的“意念控制”
6.4 算法与数据的协同进化
6.4.1 Transformer等新一代模型的引入
随着数据量的增加,基于Transformer的架构有望取代LSTM,进一步提升对复杂语义结构的建模能力。大模型的迁移学习、微调等技术,也将加速神经解码的泛化与落地。
6.4.2 开源与数据共享的推动力
哥伦比亚大学团队已将Neuro2Semantic的代码和模型开源(GitHub链接 (https://github.com/SiavashShams/neuro2semantic) ),为全球研究者提供了宝贵资源。未来,随着更多数据集和工具的开放,整个领域的创新速度将大幅提升。
6.4.3 隐私与伦理的挑战
大脑数据的敏感性与隐私保护
技术滥用的风险与监管
伦理规范的制定与公众教育
七、📝 结语:大脑与语言的“直通车”已启程
Neuro2Semantic的诞生,是脑机接口与人工智能交汇处的一次里程碑式突破。它不仅证明了“用极少数据解码大脑语义”的可行性,更为未来的医疗、认知科学、智能硬件等领域打开了想象空间。
我们看到,技术的进步让“思想直达语言”不再是遥不可及的梦想。尽管目前还存在样本量、侵入性、泛化性等诸多挑战,但随着算法、硬件、数据和伦理规范的协同演进,Neuro2Semantic及其后继者必将在现实世界中发挥越来越重要的作用。
对于每一位关注人脑奥秘、热爱技术创新的你来说,这不仅是一次科学的胜利,更是一次人类自我认知边界的拓展。未来已来,让我们共同见证大脑与语言之间那座“直通车”桥梁的加速建成。
如果你对这项研究感兴趣,欢迎访问GitHub项目主页 (https://github.com/SiavashShams/neuro2semantic) ,或关注Interspeech 2025的正式论文发布。让我们一起,探索大脑与语言的无限可能!
📢💻 【省心锐评】
“30分钟数据解码大脑语义,Neuro2Semantic让脑机接口真正迈向实用化,未来可期!”

评论