.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】OpenAI发布ChatGPT Atlas,以AI智能体模式重塑浏览器为任务终端,引爆市场竞争,多模态AI技术正驱动互联网入口的范式革命。
引言
2025年10月21日,OpenAI正式发布其首款AI驱动的网页浏览器ChatGPT Atlas。这一事件并非简单的产品上新,它更像是一次明确的信号。这个信号预示着互联网最基础的交互单元——浏览器,正在经历一场深刻的范式革命。我们习惯了将浏览器视为获取信息的窗口,一个被动的入口。Atlas的出现,试图将这个入口彻底改造为一个主动的任务执行终端。
这次变革的核心驱动力,源自两个层面。其一,是AI智能体(Agent)技术的应用落地,它赋予了浏览器“思考”与“行动”的能力。其二,是底层多模态AI技术的成熟,它让机器能够像人一样,通过多种感官协同理解这个数字世界。本文将从产品解构、市场格局与技术脉络三个维度,深入剖析ChatGPT Atlas发布背后所揭示的技术浪潮与产业变迁。
🌀 一、范式重塑:从信息入口到智能任务终端
%20拷贝.jpg)
浏览器的本质在过去二十年间未曾发生根本性改变。它始终是一个渲染引擎,一个将代码转化为可视化页面的工具。用户通过它拉取信息,进行有限的交互。Atlas的设计理念,则是要打破这种单向的信息流,建立一个由AI驱动的双向任务闭环。
1.1 ChatGPT Atlas的核心架构与功能解构
Atlas基于Chromium内核开发,这保证了其对现有Web生态的兼容性。它的颠覆性不在于内核,而在于上层构建的AI能力层。这一层深度整合了ChatGPT,并实现了几种关键的交互创新。
1.1.1 智能体模式 (Agent Mode) 的工作流
智能体模式是Atlas最具革命性的功能。 它允许浏览器在获得用户授权后,自主执行跨越多个步骤甚至多个网站的复杂任务。这背后是一套完整的“意图理解-任务分解-动作执行”工作流。
我们可以用一个简化的流程图来理解其工作原理。
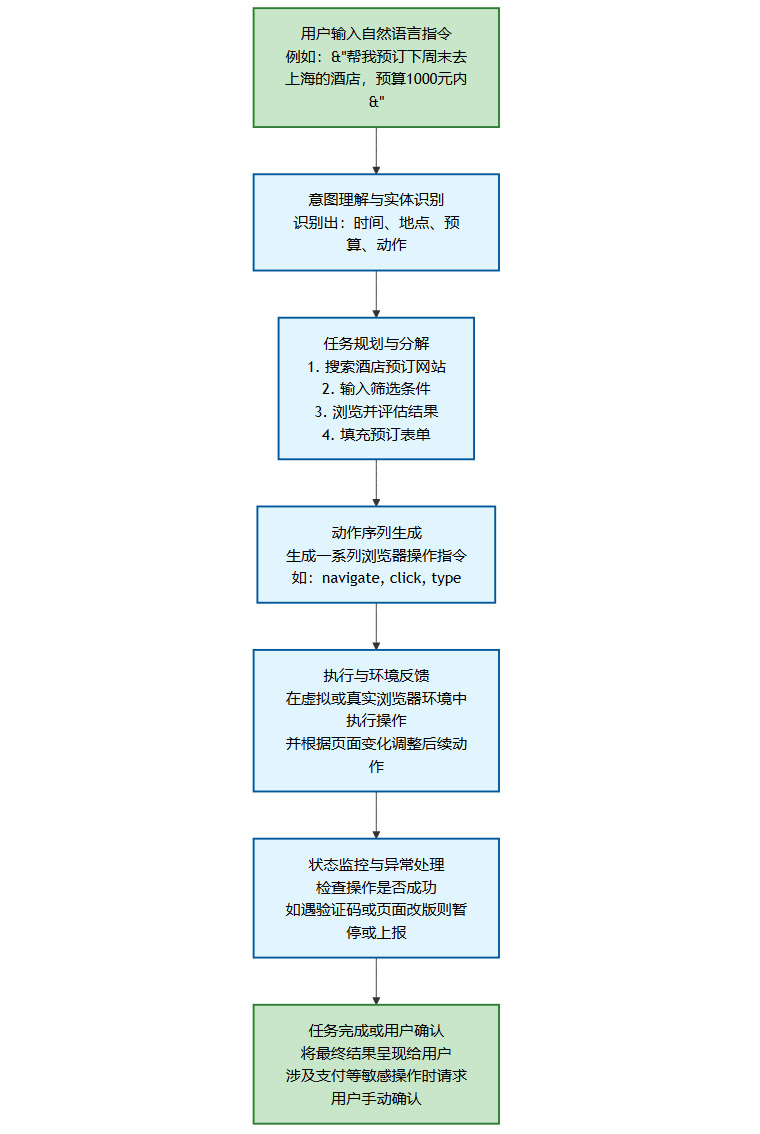
这个流程的实现,依赖于大型语言模型(LLM)强大的推理和规划能力。模型不仅要理解自然语言,还需要理解DOM树结构、网页元素的语义以及用户操作的逻辑。目前,该功能优先对ChatGPT Plus、Pro及Business付费用户开放预览, 这也暗示了其背后高昂的计算资源消耗。
1.1.2 AI优先的交互设计
除了强大的后台智能体,Atlas在前台交互上也进行了彻底的AI化改造。
“搜索反转” (Search Inversion)
传统的地址栏是URL或关键词的入口。在Atlas中,它变成了一个自然语言问题的入口。用户输入“2024年最佳旅行目的地”,得到的不再是链接列表,而是一个由AI整合分析后直接生成的答案摘要和目的地推荐。这实质上是将搜索引擎的“索引-排序”模式,升级为“理解-生成”模式。“上下文侧边栏” (Contextual Sidebar)
用户在浏览任何网页时,都可以随时唤出侧边栏的ChatGPT。这个ChatGPT实例能够感知当前页面的全部内容。用户可以要求它总结文章、解释专业术语、甚至比较页面中提到的两款产品。它免去了用户在不同标签页之间切换、复制、粘贴的繁琐操作,实现了信息的就地处理。“光标聊天” (Cursor Chat)
这是一个轻量级的交互创新。用户在撰写邮件或编辑在线文档时,只需用光标选中文本,即可实时调用AI进行润色、扩写、翻译或解释。它将AI能力无缝嵌入到了用户的核心创作流程中。
1.1.3 记忆机制与隐私边界
Atlas具备“浏览器记忆”功能,能够记住用户访问过的网页内容和关键信息点。这使得AI在后续的交互中能提供更具个性化和上下文感知能力的帮助。
然而,记忆功能也触及了用户隐私的红线。 OpenAI对此采取了相对谨慎的策略。
用户完全控制。用户可以随时查看、编辑或删除浏览器的记忆内容。
显式的隐私模式。提供类似Chrome的“隐身模式”,在该模式下不会记录任何记忆。
数据隔离与最小化。强调本地处理与云端处理的界限,并承诺仅在必要时调用完成任务所需的信息。
尽管如此,如何在提供深度个性化与保障用户数据主权之间找到平衡点,将是所有AI浏览器长期面临的技术与伦理挑战。
1.2 横向对比:AI浏览器赛道的核心玩家
Atlas的入局,让原本由传统巨头主导的浏览器市场瞬间变得拥挤。各方势力都在加速布局,但其战略意图和实现路径各有侧重。
从上表可以看出,Atlas的打法最为激进,它试图重新定义“浏览器”这个产品形态。 而谷歌和微软则更倾向于在现有产品上做“AI增强”,是一种防御性和渐进式的策略。Perplexity等初创公司则选择了一个更垂直的切入点。
⚔️ 二、市场震荡:浏览器赛道的新战争
一款新浏览器的发布,竟能引发谷歌母公司Alphabet股价在短期内下跌近5%,这在过去是难以想象的。这背后反映了市场对互联网底层商业逻辑可能被颠覆的深切忧虑。
2.1 谷歌的“护城河”保卫战
谷歌的商业帝国建立在搜索之上,而Chrome浏览器是其最坚固的护城河。全球超过60%的用户通过Chrome接入互联网,这为谷歌的搜索引擎带来源源不断的流量,并最终转化为广告收入。
Atlas的威胁是双重的。
流量截断。“搜索反转”功能让用户在浏览器地址栏就完成了信息获取,可能不再需要跳转到Google搜索页面。这直接威胁到了搜索广告的展示机会。
数据黑盒。当用户通过AI智能体完成订票、购物等高价值行为时,这些行为数据和商业转化可能被锁定在OpenAI的生态内。谷歌将失去对这部分用户行为数据的洞察。
因此,谷歌在Chrome中集成Gemini,并非简单的功能升级,而是一场关乎核心利益的保卫战。它必须证明,在AI时代,传统的“搜索框+链接列表”模式依然有其价值,或者它能提供比Atlas更无缝、更整合的AI体验。
2.2 微软的生态整合牌
微软的策略则不尽相同。凭借Windows操作系统的桌面霸权和Office 365在企业市场的渗透,微软的目标是将Edge浏览器和Copilot打造为连接个人生活与工作的AI中枢。
系统级集成。Copilot不仅存在于Edge侧边栏,也存在于Windows任务栏和Office全家桶中。这种系统级的无缝体验是OpenAI短期内难以企及的。
企业级市场。对于企业用户,数据的安全性和与现有工作流的整合至关重要。微软可以利用其在企业服务领域的信任背书,推广集成了AI能力的Edge浏览器,将其作为企业知识库和内部应用的智能入口。
微软的牌,是用B端的生态优势,反哺C端的浏览器产品。
2.3 初创公司的破局之路
以Perplexity为代表的AI原生搜索公司,也加入了这场浏览器战争。它们无法与巨头在用户规模上抗衡,因此选择在产品体验上进行极致创新。
它们的产品逻辑是,用户需要的是“答案”,而不是“链接”。因此,它们的浏览器或搜索引擎产品,会直接给出一个经过整合、附带引用来源的摘要式答案。这种专注和极致,帮助它们在技术爱好者和专业人士群体中建立了良好的口碑。它们的存在,像一条“鲶鱼”,不断推动巨头们加速创新,不敢懈怠。
🧬 三、底层驱动:多模态AI的技术脉络
%20拷贝.jpg)
如果说AI智能体是Atlas呈现给用户的“表象”,那么多模态AI技术就是支撑这一切的“里子”。浏览器面对的互联网,本身就是一个多模态的世界,充满了文本、图像、视频和声音。只懂文本的AI,无法真正理解和操作这个世界。
3.1 多模态AI的定义与核心价值
多模态AI,指的是能够协同处理、理解和生成来自不同模态(如文本、图像、音频、视频等)信息的人工智能系统。其核心价值在于,通过融合不同来源的信息,获得比任何单一模态更全面、更准确的认知。
这与人类的认知方式非常相似。我们通过眼睛看、耳朵听、语言交流,将多种感官信息在大脑中融合,才形成了对世界的完整感知。多模态AI正是对这一过程的模拟和超越。
3.2 关键技术挑战与实现路径
实现强大的多模态能力,需要克服一系列技术挑战。
3.2.1 模态表示与融合 (Representation & Fusion)
表示 (Representation)。如何将图像的像素、声音的波形和文本的词向量,转换到同一个高维数学空间中,让它们可以相互比较和计算?这是多模态学习的第一步。目前主流的方法是使用各自领域的深度学习模型(如CNN/ViT处理图像,Transformer处理文本)提取特征,然后通过特定的投影层将它们映射到统一的表示空间。
融合 (Fusion)。在获得统一表示后,如何有效地将它们融合起来?
早期融合:在输入层就将不同模态的数据拼接在一起,送入一个模型处理。简单直接,但可能破坏各模态的内部结构。
晚期融合:各模态分别通过独立模型处理,在最后决策层才融合结果。保留了模态特异性,但可能忽略了模态间的早期交互。
混合融合:结合前两者,在模型的多个层次进行交互和融合。这是当前研究的主流方向,效果最好,但模型结构也最复杂。
3.2.2 模态对齐 (Alignment)
模态对齐是多模态理解的核心。它要求模型能够精确地建立起不同模态元素之间的对应关系。例如,在一段视频中,将“小狗在草地上奔跑”这句语音描述,与视频中奔跑的小狗的像素区域,以及“汪汪”的狗叫声在时间轴上精确对应起来。CLIP(Contrastive Language-Image Pre-training)等对比学习模型的成功,极大地推动了图文对齐技术的发展。
3.2.3 跨模态生成 (Generation)
这是多模态AI最具创造力的部分。它要求模型能够根据一种或多种模态的输入,生成一种全新模态的输出。我们熟知的DALL-E、Midjourney(文生图)、Sora(文生视频)都是跨模态生成的典型应用。
3.3 浏览器场景下的多模态应用
多模态技术对于AI浏览器而言,不是锦上添花,而是必需品。它让浏览器智能体能够真正“看懂”和“听懂”网页。
Atlas的发布,预示着多模态能力将成为下一代互联网入口的标配。 未来的浏览器将是一个全息的感知终端。
🛠️ 四、实践启示:企业与开发者的应对之道
%20拷贝-jfvn.jpg)
这场由AI浏览器引领的变革,对身处其中的企业和技术从业者提出了新的要求。被动适应已然不够,主动拥抱变化才是生存之道。
4.1 对企业决策者的战略启示
4.1.1 入口思维的转变
过去,企业官网、App是用户交互的主要入口。未来,AI智能体可能成为新的超级入口。企业需要思考,如何让自己的产品和服务对AI智能体“友好”? 这意味着需要提供结构化、语义化的数据接口(API),而不仅仅是供人眼看的可视化页面。网站的“Agent可访问性”将变得和“移动端适配”一样重要。
4.1.2 数据与隐私架构的重构
AI智能体需要访问大量数据才能高效工作。企业在利用这些能力的同时,必须建立起更为严格的数据治理和隐私保护体系。
数据分级。明确哪些数据可以被AI访问,哪些属于核心机密。
最小权限原则。授权AI智能体访问完成任务所需的最小数据集。
用户知情与可追溯。确保用户清楚AI在何时、为何访问了他们的数据,并提供完整的操作日志。
4.1.3 边云协同的部署模式
所有计算都在云端完成,成本高昂且有延迟。“边云协同”将是未来的主流模式。 一些轻量级的、对隐私要求高的AI任务(如文本润色)可以在浏览器端(边缘侧)通过小型模型完成。而复杂的、需要海量知识的智能体任务(如旅行规划)则交由云端的大模型处理。企业应评估自身业务,设计合理的边云协同AI架构。
4.2 对开发者的技术路线图
4.2.1 掌握Agent框架与API设计
开发者需要从传统的Web开发、App开发,转向学习和掌握AI智能体的开发。
学习Agent框架。熟悉LangChain、AutoGen、LlamaIndex等主流的智能体开发框架,理解其工作原理。
设计Agent友好的API。学习如何设计出能被AI智能体轻松理解和调用的API。RESTful API依然重要,但GraphQL等更灵活的查询语言可能会更受青睐。
4.2.2 拥抱多模态数据处理能力
未来的应用将不再局限于文本。开发者需要扩展自己的技术栈,涉足多模态领域。
学习主流深度学习框架。精通PyTorch或TensorFlow是基础。
掌握多模态模型。了解并实践如何使用像CLIP、BLIP等多模态预训练模型,来处理图文匹配、VQA等任务。
关注数据处理。学习如何高效地处理和标注图像、音频、视频等多模态数据。
4.2.3 关注安全与可解释性 (XAI)
AI智能体是一个强大的工具,但也可能被滥用。开发者需要具备“负责任的AI”思维。
提示词工程安全。学习如何防范“提示词注入”等针对LLM的攻击。
可解释性AI (XAI)。探索使用LIME、SHAP等工具来理解AI模型的决策过程,确保其行为是可预测和可控制的。
结论
OpenAI发布的ChatGPT Atlas,远不止是一款新浏览器。它是AI技术从云端走向用户日常交互终端的一个关键节点,是互联网从“信息互联网”迈向“行动互联网”的催化剂。它以AI智能体为核心,将浏览器从一个被动的“信息窗口”升级为一个主动的“任务伙伴”。
这一转变,正深刻地搅动着市场格局,迫使谷歌、微软等科技巨头重新审视自己的护城河。而其背后真正的技术引擎,是日益成熟的多模态AI。它让机器以前所未有的深度和广度理解我们所处的数字世界。
对于企业和开发者而言,这既是挑战也是机遇。旧的入口逻辑正在被打破,新的交互范式正在形成。唯有主动理解并拥抱这一变化,才能在即将到来的智能体时代,找到自己的位置。
📢💻 【省心锐评】
Atlas不是新浏览器,是新物种。它把网页从“只读”文档变为“可执行”程序。未来,你的数字身份将由一个AI智能体代理,互联网的交互规则正在被重写。

评论