.png)


【摘要】电商 AI 视频生产正陷入 "好看但不可用" 的普遍困境,商品一致性成为核心技术与工程瓶颈。系统性拆解 10 大高频生产痛点,提供一套可落地的商品表达框架、质量控制流程与架构设计思路,帮助技术与内容团队建立稳定、可规模化的 AI 视频生产能力,实现从“创意抽奖”到“工业化生产”的转变。
引言
自 2026 年以来,以 Sora、Veo 3.1 为代表的视频生成大模型,已将 AI 视频的生成质量推向了接近专业级拍摄的水准。电商,作为内容需求最为旺盛的领域之一,率先拥抱了这一技术浪潮,期望通过 AI 视频生产来解决长期困扰行业的 SKU 众多、上新快、拍摄成本高昂的痛点。
然而,在实际的落地探索中,绝大多数团队都遭遇了远超预期的技术与工程挑战。生成的视频画面精美,但商品细节频繁变形;场景氛围高级,但核心卖点模糊不清。单次生成成功率不足 10% 的情况比比皆是,反复的调试与重试,反而导致生产效率低于传统拍摄方式。这种“好看但不可用”的困境,正在成为行业普遍的痛点。
本文面向电商平台的产品经理、内容技术负责人、AI 工程师以及品牌商家,基于一线生产实践,系统性梳理电商 AI 视频生产中的 10 大核心瓶颈。文章将深入分析问题本质,从认知重构、技术实现到流程再造,提供一套经过验证的工程解决方案与质量控制体系,旨在帮助团队构建稳定、高效的 AI 视频生产能力。
一、认知重构:从创意片到商品片的范式迁移
%20拷贝.jpg)
在启动任何 AI 视频项目之前,首要任务是进行一次彻底的认知校准。将电商视频的生产目标与创意短片混为一谈,是导致项目失败的第一个,也是最根本的原因。
1.1 问题根源:AI 的创意偏好与电商的商品属性冲突
电商视频与创意视频的生产目标存在本质差异。创意视频的核心是传递情绪、构建品牌理念,它允许甚至鼓励一定程度的艺术夸张与自由发挥。而电商视频的核心是商品信息的精准传递,其所有画面元素,从光影、构图到模特动作,都必须服务于一个终极目标:让用户看清商品、理解卖点、建立购买信心。
AI 视频模型天生更擅长生成符合人类普适审美的创意画面。它们通过学习海量的电影、广告、艺术短片等数据,能够自动组合出光影优美、构图精致的场景。但模型的“世界观”中,并不存在“核心商品”与“背景元素”的优先级区分。它会将所有画面元素同等对待,进行美学上的优化,这直接导致了商品本身被精心营造的“氛围”所淹没。
这种冲突的典型表现包括:
主次不分:提示词中 90% 的内容在描述场景、情绪和风格(如“黄昏、温暖、治愈”),而对核心商品的描述不足 10%。
为美学牺牲信息:滥用大光圈虚化效果,导致商品细节模糊;追求戏剧性的逆光拍摄,导致商品颜色严重失真。
商品边缘化:模特占据画面绝对主体,商品仅在边角一闪而过,沦为模特的“配饰”。
无效运镜:过度追求电影感的复杂运镜,导致商品在画面中快速移动或旋转,用户根本无法看清。
1.2 工程解法:建立“商品优先”的内容生产框架
要解决这一根本性冲突,必须在生产流程的顶层设计上,建立一个“商品优先”的内容生产框架。这意味着将整个视频生产流程拆解为商品定义、卖点拆解、镜头设计三个核心阶段,并在每个阶段都将商品信息的传递作为最高优先级。
我们可以通过一个优先级对比表来清晰地展示这种范式差异:
基于此框架,在提示词(Prompt)工程中,必须严格遵循“商品信息占比不低于 50%”的原则。工程师和内容策划需要先用最详尽、最精确的语言,完整描述商品的所有关键物理特征,然后再去补充场景、人物和动作等辅助信息。
Q:完全放弃氛围会不会导致视频太枯燥?
A:这并非要求完全放弃氛围,而是要建立主次关系。氛围是商品的“衬托”,而非“主角”。一个可供参考的实践法则是“7分商品,3分氛围”。在确保商品主体清晰、细节可辨的前提下,适当增加场景美感,可以有效提升用户的停留时长和观看体验。关键在于,氛围的营造不能以牺牲商品信息的准确性为代价。
1.3 卖点可视化:将抽象营销语言翻译为视觉指令
%20拷贝.jpg)
电商行业习惯于使用高度抽象的形容词来描述商品卖点,例如“显瘦”、“显腿长”、“有质感”、“百搭”等。这些词汇对于人类消费者具有明确的共识和丰富的联想,但对于 AI 模型而言,它们是无法直接理解和执行的模糊概念。AI 无法从逻辑上推断出“显瘦”究竟是指肩线贴合、腰线收紧,还是整体轮廓呈 H 型。
AI 只能生成它能“看见”的东西。因此,将这些抽象卖点“翻译”成具体的视觉元素、人物动作和镜头语言,是实现有效卖点表达的关键一步。团队需要建立一个内部的“卖点可视化翻译表”,将营销语言转化为工程指令。
以“高腰阔腿裤显腿长”这个卖点为例,一个无效的提示词是:“一个女孩穿着显腿长的阔腿裤,画面高级有质感”。
而一个有效的、经过可视化翻译的提示词应该是:
“低角度正面全身镜头,一位身高168cm的女性模特,穿着一条高腰军绿色工装阔腿裤,腰线位于肚脐上方2厘米处,裤长恰好盖住鞋面。模特正自然地向前迈步,展示裤子的垂坠感和拉长的腿部比例。背景为简洁的纯白色墙面,光线明亮均匀。”
这种翻译工作,本质上是将内容策划的“感性”诉求,转化为AI工程师可以执行的“理性”指令。
二、核心瓶颈:商品一致性的技术拆解与实现
商品一致性,是电商 AI 视频从“好看”到“可用”的生命线。任何导致商品在不同镜头、不同帧之间发生结构、颜色、细节变化的现象,都会被消费者解读为“货不对板”,从而直接摧毁购买信心,甚至引发对店铺信誉的质疑。这是当前 AI 视频生成技术面临的最核心的工程挑战。
2.1 原子化商品描述:一切一致性的起点
AI 模型不具备人类的常识推理能力。当它接收到“一件甜酷风穿搭”这样的模糊指令时,它无法像人类一样自动脑补出 T 恤配短裙的经典组合。模型会在其庞大的训练数据中,随机抽取所有被打上“甜酷风”标签的服装元素进行组合,导致每次生成的结果都千差万别。
要实现 100% 的商品一致性,就必须从源头——商品描述——上进行严格约束。解决方案是建立一套标准化的、原子化的商品描述模板(Standard Product Description, SPD)。该模板需要将一件商品拆解为不可再分的、影响用户购买决策的最小物理特征单元,并确保每个特征都有明确、无歧义的定义。
以服装品类为例,一个基础的 SPD 模板应至少包含以下字段:
品类(Category):上衣 / 下装 / 连衣裙 / 套装
款式(Style):T恤 / 衬衫 / 卫衣 / 牛仔裤 / 阔腿裤
版型(Fit):正肩 / 落肩 / 修身 / 宽松 / A字型 / H型
关键结构(Structure):高腰 / 中腰 / 低腰;长袖 / 短袖 / 无袖
颜色(Color):必须使用精确的色号(如 HEX/RGB),例如“米白色 (#F5F5DC)”,而非“浅色”或“米色”。
材质(Material):纯棉 / 牛仔布 / 真丝 / 针织 / 皮革
关键细节(Details):V领 / 圆领;单排扣 / 双排扣;明线 / 暗线;左胸口袋;袖口纽扣设计;特定印花图案描述。
Q:商品描述是不是越详细越好?
A:并非如此。描述的原则是“必要且充分”,而非“事无巨细”。只描述那些直接影响用户购买决策、构成商品核心识别特征的元素。例如,一件普通 T 恤的内部缝线工艺,除非是作为核心卖点(如“无感缝合”),否则就不需要描述,避免无关信息干扰模型对关键特征的权重分配。
在进入视频生成前,必须先通过静态图片进行描述验证。一个可靠的验证流程是:使用确定的 SPD 连续生成 5-10 张静态图片,如果这批图片中的商品结构、颜色、细节能够保持 100% 一致,才证明该 SPD 是稳定可靠的,可以进入下一步的动态视频生成。
%20拷贝.jpg)
2.2 上下文锚定:对抗模型的“遗忘”曲线
当前主流的视频生成模型,无论是基于 Transformer 架构还是扩散模型,其上下文记忆能力都非常有限。这与人类摄影师存在本质区别。真人摄影师在整个拍摄过程中,会持续地将注意力保持在核心拍摄对象上,确保模特身上的服装从第一个镜头到最后一个镜头都是同一件。
而 AI 模型在处理多镜头生成任务时,通常是为每个镜头独立生成内容,而不是基于前一个镜头的最终状态进行无缝延续。即便是在生成单镜头的长视频时,模型也会随着时间的推移(即生成帧数的增加)而逐渐“遗忘”初始的指令细节,这种现象被称为“语义漂移”。
这导致的典型问题是:
视频前 3 秒商品形态正常,第 4 秒开始逐渐变形。
人物完成一个转身或走动后,上衣的版型从修身变成了宽松。
衣服上的印花图案在动作过程中逐渐模糊、扭曲,甚至完全消失。
口袋、拉链等关键细节在镜头切换后“随机”出现或消失。
解决方案是采用“逐镜头商品锚定(Per-Shot Product Anchoring)”技术。这意味着,不能只在视频的第一个镜头或全局指令中描述商品,而必须在每一个镜头的提示词中,重复写入商品的核心 SPD。
这种重复不是简单的全文复制粘贴,而是要根据每个镜头的景别和展示重点,对描述进行动态加权。例如:
近景镜头(Close-up):提示词中重点强调
领口形状: V领,肩线: 正肩设计,印花: 左胸处有一个红色爱心刺绣图案,袖口: 罗纹收口。中景镜头(Medium Shot):提示词中重点强调
腰线: 高腰设计,上下装衔接: 白色T恤塞进牛仔裤中,口袋: 裤子两侧有方形工装口袋。全身镜头(Full Shot):提示词中重点强调
整体版型: H型直筒连衣裙,裤型: 阔腿裤,衣长比例: 裙长至膝盖上方5厘米。
通过这种方式,相当于在每个镜头的生成起点,都强制模型重新“回忆”和“确认”商品的核心特征,可以将单镜头内的商品变形率降低 70% 以上。
作为进阶优化,使用参考图引导技术是目前提升一致性的最有效手段。将商品的正面、侧面、背面高清图作为 IP-Adapter 或类似技术的参考图输入,并在每个镜头的提示词中明确要求“严格参考输入参考图中的商品结构、颜色和细节”。参考图引导可以将跨镜头商品一致性的成功率提升至 90% 以上,是实现规模化生产的必备技术。
%20拷贝.jpg)
2.3 材质与动态表现:物理特性的精准模拟
这是一个在实践中极易被忽略,却又至关重要的细节。不同材质的商品具有截然不同的物理特性,它们在动态过程中会表现出迥异的状态。丝绸轻盈飘逸,牛仔布挺括有型,针织面料柔软垂坠,皮革则富有光泽和韧性。
当前 AI 模型对材质物理特性的模拟能力仍处于初级阶段。如果提示词只描述了材质名称(如“牛仔面料”),模型很可能无法准确还原其在走动、转身等动作下的真实动态表现。这种不准确性会严重影响用户对商品品质的判断。试想一下,一条本应挺括的牛仔阔腿裤,在视频中却像丝绸一样随风飘动,消费者很自然会认为这条裤子的面料太薄、质量不佳。
典型问题包括:
牛仔面料生成得过于柔软,缺乏“骨感”和挺括感。
丝绸或雪纺面料生成得过于僵硬,没有飘逸灵动的效果。
针织面料缺乏应有的垂坠感,显得松垮臃肿。
皮革面料没有呈现出自然的光泽和纹理,质感如同塑料。
面料的褶皱变化不符合重力或运动规律。
工程解决方案是在商品描述中,不仅要定义材质名称,更要描述其期望的动态表现特征。
不要只写“牛仔面料”,要写“厚款牛仔面料,形态挺括,走动时裤腿保持清晰的直筒轮廓,褶皱硬朗自然”。
不要只写“丝绸面料”,要写“19姆米真丝面料,质地轻盈飘逸,模特走动时裙摆随风轻柔摆动,表面有自然柔和的光泽”。
不要只写“针织面料”,要写“高密度纯棉针织面料,手感柔软且有垂坠感,能够贴合身体曲线但不过分紧绷”。
此外,使用材质参考图同样是有效的优化手段。寻找一段能够体现目标材质真实动态的视频,截取关键帧作为参考图输入模型,并明确要求模型“严格参考参考图中的材质质感和动态褶皱表现”。这可以显著提升 AI 对特定材质物理特性的模拟能力。
2.4 多镜头协同:剪辑流程中的一致性保障
由于当前模型难以一次性生成高质量的长视频,多镜头分别生成再剪辑拼接,是业界主流的生产范式。然而,这也引入了新的、严峻的一致性挑战:如何保证独立生成的多个镜头之间,商品、人物、场景能够无缝衔接?
这些偏差在单个镜头中可能并不明显,但一旦剪辑在一起,就会显得非常突兀,严重破坏视频的连贯性和可信度。
常见的不一致问题:
颜色偏差:第一个镜头中商品是米白色,第二个镜头变成了纯白色。
细节偏差:不同镜头中,衣服上印花图案的位置或大小发生微小偏移。
人物偏差:模特的妆容、发型在镜头切换后发生肉眼可见的变化。
环境偏差:光线方向、色温、背景元素在不同镜头之间不一致。
动作跳跃:镜头之间的动作衔接生硬,出现“跳帧”感。
要解决这个问题,需要建立一个“统一参数 + 关键帧校验”的多镜头生产流程。
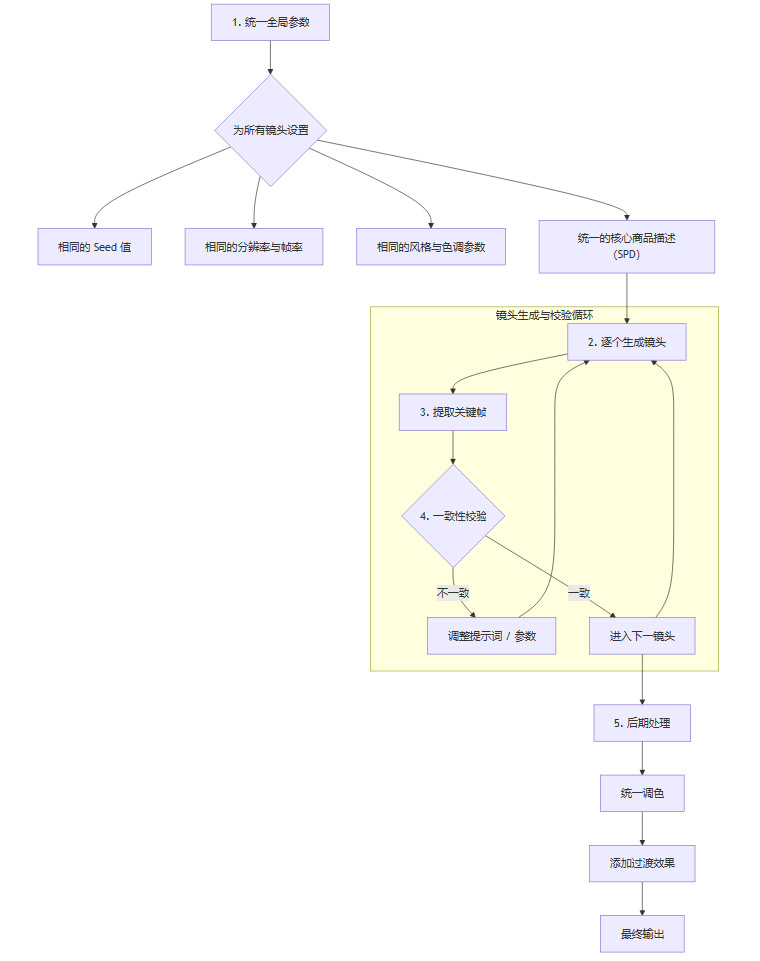
这个流程的核心思想是:
统一基础参数:在生成项目开始前,为所有计划生成的镜头设定一个统一的“基准”,包括种子值(Seed)、分辨率、帧率、以及描述风格和色调的全局参数。种子值的统一是保证人物和场景一致性的关键。
统一商品描述:所有镜头必须引用同一个核心 SPD。只根据当前镜头的任务,微调对特定部位的强调。
关键帧提取与校验:每个镜头生成后,自动或手动提取其第一帧和最后一帧。在生成下一个镜头前,将其第一帧与上一个镜头的最后一帧进行对比,重点检查商品颜色、版型、细节、人物发型等是否一致。
后期统一调整:对于AI生成中难以避免的轻微色差或亮度差异,不要试图通过反复生成来完美解决。更高效的方式是在剪辑软件(如 DaVinci Resolve, Premiere Pro)中,通过全局调色和色彩匹配工具进行统一校正。
2.5 风险前置:构建品类专属的负向约束词库
负向提示词(Negative Prompt)是控制生成质量的重要工具。然而,很多团队的用法过于粗放,只是简单堆砌“画面模糊、低质量、变形、水印、畸形”等通用负面词。这些词汇只能解决最基础的图像质量问题,无法解决电商场景下特有的、与商品相关的变形问题。
不同品类的商品,其在AI生成过程中的“翻车点”是不同的。印花 T 恤最怕印花扭曲和字母乱码;工装裤最怕口袋消失和裤型贴腿;修身上衣最怕肩线下塌和袖口变大。
因此,必须建立一个“品类专属负向约束词库”,针对不同品类的商品,总结其最高频的生成缺陷,并将其转化为精确的负面指令。这个词库不是一成不变的,它需要在生产实践中不断积累、迭代和扩充。
以下是几个常见品类的核心负向词示例:
印花 T 恤:
印花变形 (distorted print),字母乱码 (garbled text),图案消失 (disappearing pattern),颜色溢出 (color bleeding)工装裤:
口袋消失 (missing pockets),裤腿贴身 (tight legs),面料软塌 (limp fabric),腰线过低 (low waistline)修身上衣:
肩线下塌 (dropped shoulders),袖口变宽 (widened cuffs),衣身变松 (loose fit),领口变形 (deformed collar)连衣裙:
裙摆变短 (shortened hem),腰线消失 (missing waistline),面料透明 (transparent fabric),异常褶皱 (abnormal wrinkles)
Q:负面词是不是越多越好?
A:不是。过多的、过于严苛的负面约束,可能会导致生成结果“过度修正”,变得呆板、缺乏自然感。一个好的实践是,每个镜头的负面词数量控制在 10-15 个之间,只针对该品类、该镜头下最容易出现的、影响最严重的问题进行精确约束。
此外,对于有动作的镜头,还需要增加动态风险约束,例如:动作过程中服装结构保持不变 (clothing structure remains constant during movement), 印花位置固定 (print position is fixed), 口袋不消失 (pockets do not disappear), 无穿模 (no clipping)。
这种动态约束,可以显著降低商品在运动过程中的变形概率。
三、流程再造:从单点生成到规模化生产
%20拷贝.jpg)
解决了商品一致性的核心技术瓶颈后,下一步就是将这些技术点串联起来,构建一个可重复、可管理、可扩展的规模化生产流程。这需要对镜头设计、动作编排和质量控制进行系统性的工程化再造。
3.1 镜头语言工程化:建立“机位-卖点”映射体系
AI 模型倾向于生成视觉上更具冲击力的镜头,如大光圈逆光、戏剧性仰拍等。这些镜头虽然美学价值高,但往往不适合清晰地展示商品。如果没有明确的镜头任务指令,AI 就会“自由发挥”,选择它认为“好看”的机位,而不是最能展示商品卖点的机位。
每一个镜头都必须有明确的商品展示任务。没有承载卖点信息传递任务的镜头,即使再好看,也应该被视为无效镜头并予以删除。
为了实现这一点,需要建立一个“机位-卖点对应表”,将镜头设计从一种“艺术创作”转变为一种“工程选择”。在规划视频脚本时,内容策划和工程师应严格参照此表来选择机位。
在视频结构上,一条 30 秒的电商短视频,镜头数量建议控制在 5-7 个。每个镜头聚焦展示 1-2 个核心卖点,避免信息过载。同时,每个镜头的时长应保持在 3-5 秒,确保用户有足够的时间看清商品信息,避免因频繁切换导致的眼花缭乱。
3.2 动作链设计:在动态展示中注入真实感
许多早期的 AI 电商视频,其动作设计极为单调,往往只是让模特在不同位置“站桩”,摆出不同的姿势。这些静态姿势之间缺乏逻辑联系和自然过渡,导致视频观感僵硬、机械,缺乏生活气息和真实感。
动作设计的目的,不仅仅是让视频“动起来”,更是为了在动态过程中,从不同角度、在不同状态下展示商品的特性。一个精心设计的动作,可以让用户更全面地了解商品,例如裤子在行走时的垂坠感、外套在转身时的轮廓感。
解决方案是采用“动作链(Action Chain)设计法”。将每个镜头的动作设计成一个有起承转合的微型片段,而不是一个孤立的姿势。一个标准的动作链应包含以下元素:
起始状态(Initial State):模特的初始姿势和位置。
核心动作(Core Action):与商品展示直接相关的主要动作。
道具互动(Prop Interaction):与场景中的道具进行自然互动,增加真实感。
结束停顿(Ending Pause):在商品形态最清晰、卖点展示最充分的位置,进行 1-2 秒的短暂停留,给用户留下“记忆点”。
例如,一个展示上衣印花和腰线的动作链,可以这样设计:
“模特站在一家花店门口,身体微微侧向镜头(起始状态)。她看到朋友从旁边递来一束花,于是伸出双手自然地接过花束(核心动作 & 道具互动)。她低头微笑看了一下花,然后将花束轻轻抱在胸前,身体转向正面,面带微笑看向镜头,并在这个姿势上停顿 2 秒(结束停顿),这个动作清晰地展示了上衣的正面印花和收腰设计。”
风险控制:必须认识到,动作的复杂度与商品变形的概率呈正相关。动作越剧烈、越复杂,AI 模型就越难维持商品结构的稳定性。因此,动作设计必须遵循“简单、有效、必要”的原则,避免为了动而动。通常,每个镜头的核心动作不应超过 2 个,全身移动的速度不应超过正常行走速度的 80%。尤其在涉及复杂手部动作时,要特别注意手指的生成质量,必要时可在负向提示词中加入畸形的手 (deformed hands)、多余的手指 (extra fingers)等约束。
3.3 质量控制与迭代:建立可量化的评估与优化闭环
如果团队对 AI 生成视频的评判标准停留在“这个感觉还行”、“那个看起来有点怪”的模糊层面,那么整个生产过程就无异于“抽奖”。无休止的重试不仅会摧毁团队的信心,更无法形成有效的知识沉淀和流程优化。
没有标准,就没有质量;没有量化,就没有规模化。建立一套可量化、可执行的评测标准,是实现 AI 视频规模化生产的最后一块,也是最重要的一块拼图。
解决方案是建立一张“电商 AI 视频质量评分卡(Quality Scorecard)”。在每次生成任务完成后,由专人或通过 AI 辅助工具,按照评分卡逐项打分。只有总分达到预设合格线(例如 85 分)的视频,才能进入下一环节。
这个评分卡不仅是一个“过滤器”,更是一个“诊断器”。当一个视频未通过评测时,团队不应直接点击“重新生成”,而是要根据评分卡定位到具体的失分项,然后进行针对性优化。
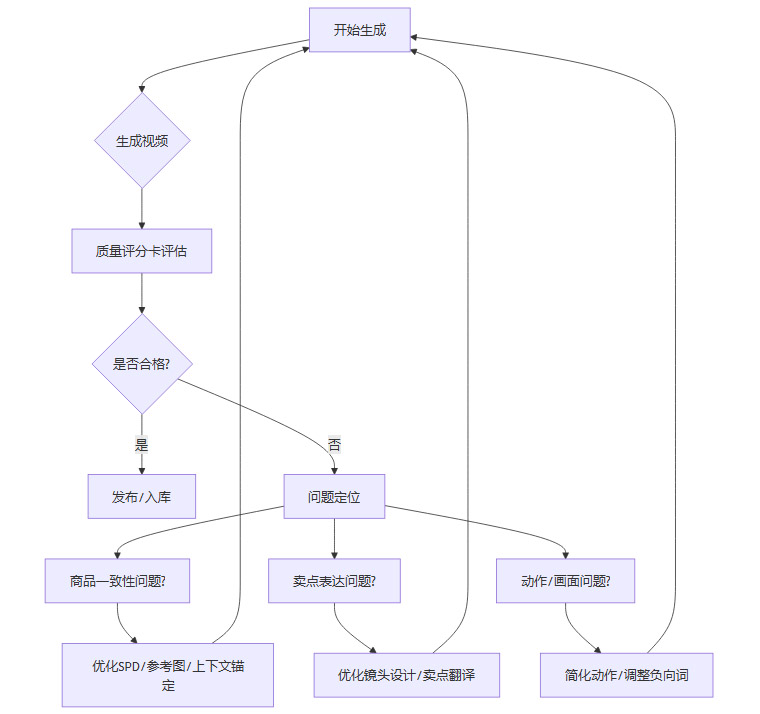
通过这个“生成-评估-定位-优化”的闭环反馈流程,每一次失败的生成都将转化为一次对提示词工程、生产流程和知识库的有效迭代,从而系统性地、持续地提升生成成功率。
结论
电商 AI 视频的核心挑战,并非生成更华丽、更具创意的画面,而在于如何实现稳定、可靠、可信的商品信息表达。商品一致性是电商 AI 视频的生命线,是决定其商业价值的唯一标准。任何影响商品信息准确传递的技术缺陷或流程疏漏,都是致命的。
当前,视频生成模型本身的能力仍存在诸多局限,例如上下文记忆有限、物理世界理解不足等。但这并不意味着 AI 无法在电商视频生产中发挥巨大价值。关键在于,我们不能将其视为一个“一键生成”的魔法棒,而应将其定位为一个需要严格规则和精密流程来驾驭的强大生产工具。
通过建立标准化的商品描述体系(SPD)、卖点可视化翻译表、机位-卖点映射机制、品类专属负向词库以及量化的质量评分卡,我们完全可以在现有技术条件下,构建起一套行之有效的工程化生产框架。这套框架能够将 AI 视频的单次生成成功率从不足 10% 提升至 80% 以上,从而真正实现规模化、低成本的电商内容生产。
未来,电商 AI 视频领域的竞争,不会是模型本身或算力的竞争,而是生产规则的竞争。谁能更早、更深刻地理解电商内容的本质,并将自身的行业知识、内容生产经验和审美判断,转化为一套可执行、可迭代、可扩展的 AI 指令和质量控制流程,谁就将在这场由技术驱动的产业变革中占据绝对的领先地位。
📢💻 【省心锐评】
AI 不是电商视频的“一键生成器”,而是需要严格规则约束的生产助手。抛弃对模型的幻想,回归对商品表达的工程化构建,才是当前阶段的唯一通路。
SEO关键词:AI视频生成、商品一致性、AIGC电商、提示词工程、视频生成模型、内容生产流程
评论