.png)
%20%E6%8B%B7%E8%B4%9D-dcvd.jpg)

【摘要】FrontierScience基准揭示了AI在结构化竞赛与真实科研推理间的显著能力鸿沟,明确了其当前作为高效“科研副手”的定位,并为未来发展校准了方向。
引言
近年来,大型语言模型(LLM)在各类标准化竞赛中的表现堪称惊艳。从国际数学奥林匹克(IMO)到编程竞赛平台Codeforces,AI系统屡次取得超越人类顶尖选手的成绩。这一系列突破营造出一种强烈的预期,似乎通用人工智能(AGI)已近在咫尺,AI取代人类科学家也只是时间问题。然而,竞赛环境的高度结构化与科研探索的开放性、不确定性之间,存在着一道难以逾越的鸿沟。
OpenAI最新发布的FrontierScience基准,正是为了度量这道鸿沟而生。它如同一面“照妖镜”,清晰地映照出当前AI能力的真实边界。该基准的设计理念,从根本上摒弃了以“刷题”和“标准答案”为核心的传统评测范式,转而将模型置于博士级别研究人员的真实工作场景中。测试结果极具启发性,顶级模型在竞赛题上高达77%的正确率,在开放性研究题上骤降至25%。这一巨大落差,并非宣告AI的失败,而是为整个行业提供了一次至关重要的“校准”。它迫使我们重新审视AI在科学发现中的真实角色,并更理性地规划其未来的演进路径。
🌀 一、基准的核心设计:从“解题”到“科研”的范式迁移
%20拷贝-zske.jpg)
FrontierScience基准的根本价值,在于其评测哲学的转变。它不再将科学能力简化为寻找唯一正确答案的过程,而是致力于评估模型在复杂、模糊的科研情境下进行系统性推理的能力。这种转变,体现在其独特的评测维度和题目设计上。
1.1 评测维度的解耦:“竞赛能力”不等于“科研能力”
传统AI评测基准,如MMLU、GSM8K等,尽管在评估模型的知识储备和逻辑推导方面功不可没,但其内在范式更接近于“闭卷考试”。这类评测存在两个核心局限。
路径依赖与模式匹配:竞赛题目通常具有明确的解题路径和评价标准。模型可以通过大规模语料库的学习,掌握特定题型的解题“套路”或模式。其高分在很大程度上反映了其强大的信息检索、模式识别与序列生成能力,而非真正的第一性原理推理。
标准答案的约束:科研探索的本质是走向未知,其过程往往没有标准答案,甚至问题本身都需要在探索中不断被重新定义。传统基准无法评估模型在面对开放性问题时,构建合理假设、设计验证路径、权衡矛盾证据、以及承认自身局限等关键科研素养。
FrontierScience则明确将这两种能力进行了解耦。它同时包含了结构化的竞赛题与开放式的研究题,通过对比两者得分的巨大差异,量化了AI从“优秀解题者”到“合格研究者”的距离。
1.2 设计理念的革新:真实性、前沿性与抗污染
为了确保评测的有效性,FrontierScience在题目设计上遵循了三大原则,这使其成为一个更严苛、也更具指导意义的“标尺”。
真实性(Authenticity):基准中的700多道题目,均源自真实的科研文献、博士资格考试以及顶级研究人员的日常工作。题目覆盖物理、化学、生物、医学等多个前沿学科,确保了评测场景与真实科研工作的高度一致性。
前沿性(Frontier Focus):题目内容聚焦于当前科学研究的前沿领域。这意味着模型无法简单地通过检索其训练数据中已经存在的、成熟的知识来作答,而必须进行动态的、基于上下文的推理。
抗污染(Contamination Resistance):这是该基准最值得称道的一点。OpenAI团队在设计时,刻意筛除了那些现有模型已经能够熟练解答的题型或知识点。这种“自虐式”的设计,有效避免了“数据泄漏”或模型针对特定基准进行“应试训练”所带来的分数虚高。它确保了评测结果更能反映模型能力的真实上限,而非其记忆库的广度。
通过这种设计,FrontierScience迫使模型走出舒适区,真正去“思考”而非“背诵”。
1.3 77% vs. 25%:性能落差背后的能力断层
测试结果是最有力的证明。以GPT-5.2(一个假设的、代表当前最前沿技术的模型)为例,其在两类题目上的表现呈现出巨大的断崖式下跌。
这个从77%到25%的落差,精准地暴露了当前大模型能力的结构性短板。它说明,模型在处理确定性、有界问题时已经非常强大,但在面对开放、无界、需要进行创造性构建和审慎判断的科研任务时,其能力尚未成熟。这25分,恰恰是AI科研能力从零到一的起点,它代表了模型在一定程度上已经能够理解复杂科研问题的表述,并尝试给出一个结构化的回应,尽管这个回应在深度和严谨性上还远远不够。
🌀 二、深度剖析科研推理的挑战:AI的“阿喀琉斯之踵”
FrontierScience所揭示的,不仅是分数的差距,更是AI在模拟高级认知活动时的深层挑战。科研推理的难点,不在于“算对”,而在于构建一个可被同行审视、可被证伪、逻辑自洽且有边界的论证体系。这恰恰是当前AI架构的软肋所在。
2.1 超越正确性:构建可辩护的论证链
一道开放性研究题,例如“请基于现有文献,评估X蛋白在Y疾病中的潜在作用,并设计一套初步的实验验证方案”,对模型的要求是多层次的。
假设的生成与组织:模型需要从零开始,提出一个或多个关于X蛋白作用机制的核心假设。这要求它不仅仅是信息的搬运工,更是逻辑的组织者。
证据的筛选与权衡:模型需要从海量信息中筛选出支持和反对其假设的证据。更重要的是,它必须学会权衡不同来源证据的权重,比如区分一篇顶刊的扎实研究和一篇预印本的初步发现。当证据发生冲突时,模型需要能够识别冲突,并提出可能的解释或下一步需要澄清的问题。
结论的审慎与边界:一个合格的科研论证,其结论必然是审慎的。模型需要明确其结论的适用范围、前提条件和潜在局限。例如,它应该主动说明“该结论仅基于细胞实验,在动物模型中可能不成立”,或者“现有数据不足以完全排除其他可能性”。
不确定性的表达:科学语言充满了对不确定性的精确描述。模型需要学会使用“可能”、“或许”、“提示了”、“有待进一步验证”等词汇,来准确表达其论证的信心水平。过度自信的、黑白分明的结论,在科研领域是不可接受的。
当前模型在这些方面表现不佳。它们倾向于生成流畅、看似合理的文本,但往往缺乏严谨的逻辑链条,容易在证据权衡上犯错,并且很少能主动、准确地暴露自身结论的局限性。
2.2 认知模式的差异:确定性推导 vs. 模糊性决策
从技术底层来看,这种表现差异根植于当前主流模型(如Transformer)的核心机制。
Transformer的本质:其核心是基于注意力机制的序列到序列转换。它极其擅长学习大规模数据中的统计规律和上下文关联。对于有固定模式的逻辑推导或知识问答,它可以通过学习海量范例来“拟合”出正确的生成路径。
科研推理的非序列性:真实的科研思考过程并非线性的序列生成。它是一个复杂的、动态的、充满迭代和回溯的循环。
我们可以用一个流程图来直观对比这两种模式的差异。
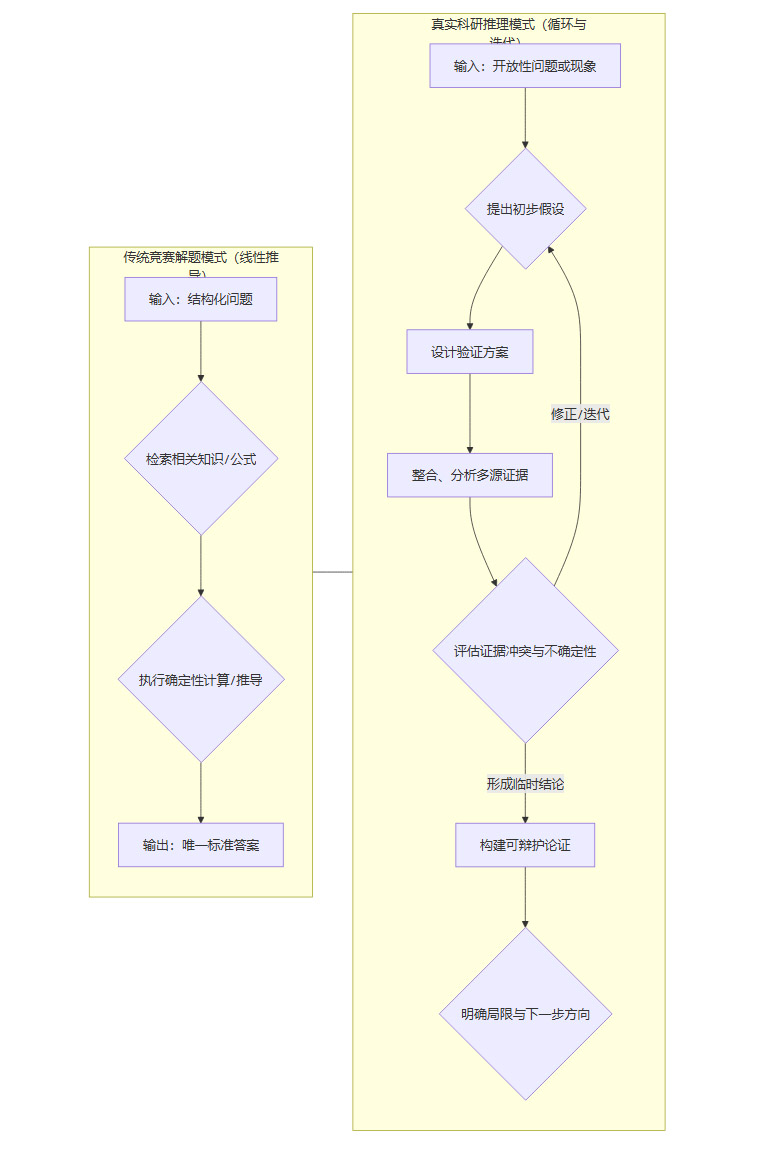
这个循环迭代的过程,充满了模糊决策。例如,在多个看似都合理的假设中选择哪一个优先探索?在相互矛盾的数据中更相信哪一个?如何设计实验才能最高效地排除其他可能性?这些决策依赖于研究者的经验、直觉和对领域深层规律的理解,而这正是当前模型所缺乏的、难以通过学习文本数据直接获得的高阶认知能力。模型在从竞赛题到研究题的分数骤降,本质上是从一个确定性的、计算驱动的场域,跌入了一个充满不确定性、由判断和权衡主导的场域。
2.3 “过度自信”的陷阱:幻觉与事实的边界
大型模型的一个固有问题是“幻觉”(Hallucination),即生成看似合理但与事实不符的内容。在科研场景下,这个问题被急剧放大。一个微小的幻觉,比如捏造一个不存在的引文、错误地解释一个实验结果,都可能导致整个研究方向的偏差。
更隐蔽的风险在于模型的过度自信。由于其训练目标是生成高概率(即“流畅”和“听起来正确”)的文本,模型在表达不确定性方面存在天然的困难。它可能以一种非常肯定的语气,陈述一个实际上是基于不完整信息或错误推理得出的结论。对于非专业用户而言,这种自信的表达极具迷惑性。因此,在科研这种对精确性和严谨性要求极高的领域,模型的“自信”往往不是优点,而是需要被严格审视和约束的风险点。
🌀 三、AI在科研中的当前定位与实践路径
%20拷贝-woyl.jpg)
FrontierScience的评测结果,并没有否定AI在科研领域的巨大价值。恰恰相反,它帮助我们更清晰地界定了AI当前最有效、最可靠的应用场景,即作为人类科学家的“超级副手”(Super Co-pilot),而非直接的“替代者”。
3.1 “超级副手”范式:人机协作的最优解
在可预见的未来,科研创新的核心引擎仍将是人类的智慧。AI的角色,是围绕人类研究者,将科研流程中那些高通量、低创造性、规则明确的环节自动化和智能化,从而将人类从繁重的事务性工作中解放出来,专注于最具价值的创造性思考。
这种人机协作的模式,其核心在于扬长避短。
AI的长处:无与伦比的信息处理速度、跨语言能力、模式识别精度、以及执行重复性任务的稳定性。
人类的长处:提出深刻问题的能力、跨领域联想的直觉、对异常现象的敏感度、进行批判性思维和价值判断的智慧。
一个高效的科研团队,应该是人类科学家负责设定方向、提出假设、做出关键决策,而AI系统则作为强大的执行工具,负责信息的收集、处理和初步分析。
3.2 应用矩阵:AI副手的具体任务清单
我们可以将AI在科研中扮演的“副手”角色,具体分解为一系列可执行的任务。这些任务的共同点是,它们能够被清晰地定义,并且产出结果的正确性相对容易被人类专家验证。
这个矩阵清晰地表明,AI的价值在于赋能而非取代。它将科研人员从“体力活”中解放出来,使其能够将宝贵的精力投入到更高层次的智力活动中。
3.3 不可外包的核心:人类研究者的关键角色
尽管AI副手功能强大,但科研流程中的几个核心环节,目前来看是无法、也不应该被外包给AI的。
提出“好问题”:选择一个有价值、有深度、且在当前技术条件下可能被回答的研究问题,是整个科研工作的起点和方向。这需要对领域的深刻洞察、对未来的敏锐预判和个人的学术品味。
设计研究路径:在众多可能的技术路线中,选择最合适、最高效的一条。这需要权衡成本、风险、时间等多种因素,是一个复杂的决策过程。
对异常的直觉:科学史上许多重大发现,都源于对实验中“异常”现象的关注。这种“意外之喜”(Serendipity)依赖于人类的直觉和好奇心,而AI目前更擅长在预设的模式中寻找规律。
最终的学术判断:对研究结果的最终解释、对其科学意义的评估、以及对其伦理影响的考量,必须由人类科学家承担最终责任。
这些环节构成了科学研究的“灵魂”,它们依赖于人类独有的创造力、批判性思维和价值观。AI可以为这些环节提供丰富的信息和建议,但最终的“拍板权”必须掌握在人类手中。
🌀 四、基准的边界与AI科研的未来演进
FrontierScience作为一个评测基准,本身也存在其边界和局限。深刻理解这些局限,不仅能帮助我们更客观地看待其评测结果,更能为AI科研能力的下一阶段发展指明方向。其核心启示在于,AI需要从纯粹的“纸上推理”,迈向能够与物理世界互动的“可执行科研”。
4.1 从“理论切片”到“完整闭环”:基准的内在局限
FrontierScience尽管在模拟科研推理的复杂性上迈出了一大步,但它本质上仍是一种静态的、基于文本的评测。它截取了科研流程中“思考与论证”的理论切片,但无法覆盖一个完整的科研项目所涉及的全部环节。
缺乏实验操作与物理交互:科学不仅仅是思考,更是动手。无论是化学合成、生物实验还是物理测量,都涉及与真实世界仪器的交互、对实验流程的精细调控以及对物理噪声的处理。一个模型无论在理论上设计出多么完美的实验方案,如果无法指导或与机器人协作来实际执行,其价值都是不完整的。
无法模拟持续的试错与反馈循环:科研是一个漫长的、充满失败和迭代的过程。研究者需要根据一次失败的实验结果,动态调整下一步的策略。Front-endScience的一次性问答模式,无法评估模型在这种长周期的、基于现实世界反馈的持续学习与自我纠错能力。
难以评估真正的原创性假说:基准可以评估模型能否在一个给定的框架内构建合理的论证,但很难判断一个模型提出的新假说是否具备真正的“原创性”。原创性往往体现在对现有范式的颠覆或开辟一个全新的研究领域,这种突破性的思想火花,其价值很难通过标准化的题目来衡量。
认识到这些局限,我们就能明白,单纯提升模型在FrontierScience这类基准上的分数,并不等同于AI科研能力的全面提升。未来的发展,必须超越文本模态,将模型的推理能力与现实世界的感知和行动能力结合起来。
4.2 下一阶段演进方向:迈向“AI科学家”的可能路径
基于上述分析,AI科研能力的未来演进,可能会沿着几个关键方向展开,其核心是构建一个能够自主进行“观察-假设-实验-学习”完整闭环的智能体系统。
多模态与具身智能(Embodied AI):未来的科研AI,必须能够理解和处理来自真实世界的多种模态信息,如实验图像、传感器数据、仪器读数等。更进一步,它需要具备“身体”,即通过控制机器人臂、自动化实验平台等硬件设备,来直接执行物理实验。例如,一个化学领域的AI科学家,应该能够分析文献提出新的合成路线,然后控制自动化合成仪来完成化合物的制备和表征。
工具使用与模型协同(Tool Use & Model Collaboration):单个大模型的能力是有限的。一个强大的科研AI系统,应该是一个由多个专业模型和软件工具组成的协同网络。
模型协同:一个负责文献分析和假设生成的“战略家”模型,可以调用一个精通量子化学计算的“专家”模型来验证分子稳定性,再调用一个负责数据可视化的模型来生成图表。
工具使用:模型需要学会像人类科学家一样,熟练使用各种外部工具,如调用搜索引擎(Google Scholar)、访问专业数据库(PubMed, SciFinder)、使用计算软件(Mathematica, MATLAB)以及控制实验设备API。
主动学习与实验设计(Active Learning & Design of Experiments):为了最高效地获取信息和验证假设,AI需要具备主动学习的能力。这意味着它不仅仅是被动地回答问题,而是能够主动判断“当前最需要知道什么”,并自主设计出信息量最大(most informative)的实验来获取这些知识。这涉及到复杂的贝叶斯优化、强化学习等技术,目标是在有限的资源下,最快地收敛到问题的答案。
可解释性与因果推理(XAI & Causal Inference):黑箱式的AI在科研领域是难以被信任的。未来的科研AI必须提供可解释的推理过程,让使用者能够理解其结论是如何得出的。此外,它需要从单纯的相关性分析,升级到更深层次的因果推理。只有理解了事物之间的因果关系,才能进行有效的干预和控制,这正是科学研究的核心目标。
我们可以用一个更复杂的流程图来描绘这种未来“AI科学家”系统的工作模式。
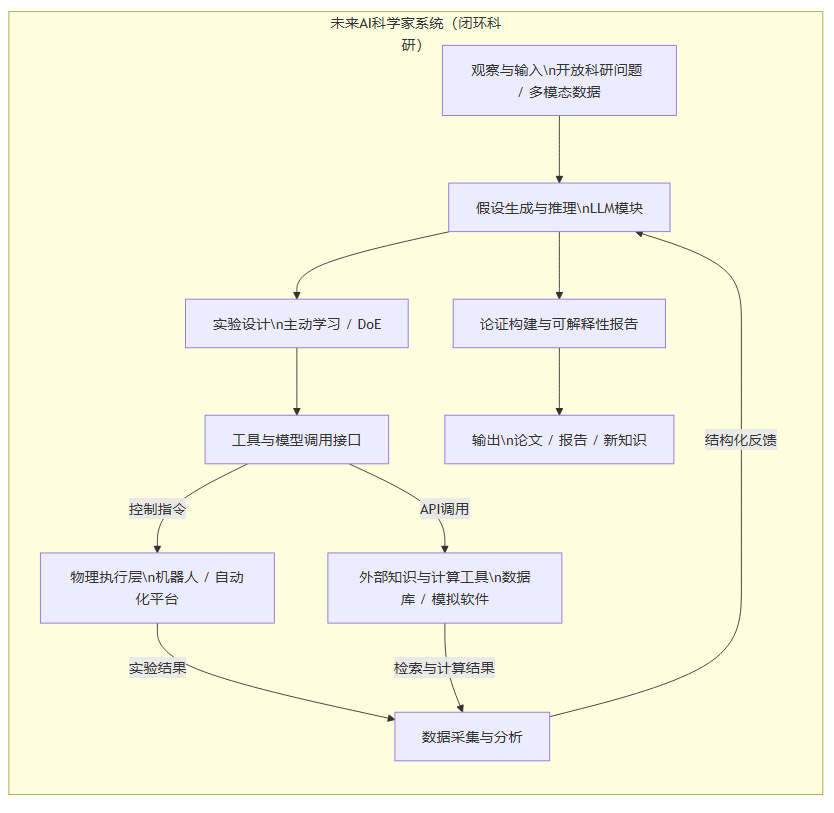
这个闭环系统,将AI的“大脑”(推理模块)与“手脚”(执行层)以及外部“知识库”(工具)紧密结合,使其能够在一个完整的科研循环中自主运转和持续优化。
🌀 五、对行业的启示:告别AGI幻觉,拥抱场景化指标
%20拷贝-jnjj.jpg)
FrontierScience的发布,对整个AI行业而言,是一次及时的提醒和深刻的启示。它标志着AI能力评测正在从追求单一、通用的高分,转向更加细分、更加贴近真实应用场景的务实主义。
5.1 警惕“单一指标陷阱”
长期以来,行业内存在一种倾向,即用某个单一基准(如MMLU)的高分来作为模型“通用智能”水平的代理指标,甚至以此来宣告“AGI已至”。这是一种危险的简化。FrontierScience的结果表明,高分可能仅仅意味着模型在该特定任务范式下表现优异,而无法直接泛化到其他更复杂的、不同范式的任务中。
行业需要建立一个更加多维度、多层次的评测体系。除了传统的知识问答和逻辑推理,未来的评测应该更加关注以下能力:
可复现的实验规划能力:评估模型生成的实验方案是否具体、可操作、可复现。
错误分析与自我批判能力:评估模型在面对错误或矛盾信息时,能否识别问题、分析原因并进行修正。
证据质量评估能力:评估模型能否区分不同来源信息的可靠性,并给予不同的权重。
风险与不确定性表达能力:评估模型能否准确、诚实地表达其结论的置信度和局限性。
新领域迁移的稳定性:评估模型在从未见过的全新科学问题上的表现,考察其“第一性原理”推理能力,而非知识记忆。
5.2 拥抱“人机协同”的务实路线
与其追求一个遥远的、能够完全替代人类的“AI科学家”神话,更务实和富有成效的路线是,专注于开发能够与人类研究者无缝协作、在特定科研环节提供巨大价值的AI工具和平台。这意味着产品设计的重点,应该从“试图给出最终答案”,转向“如何为人类专家提供最有效的决策支持”。
例如,一个成功的科研AI产品,可能不是一个能直接写出诺奖级论文的系统,而是一个能让研究者在几分钟内完成过去需要数周才能完成的文献调研、并以极具启发性的方式将关键信息可视化的智能助手。这种“赋能”而非“取代”的思路,更能满足当前科研工作的实际需求,也更容易实现商业落地。
结论
FrontierScience基准的发布,是AI发展史上的一个标志性事件。它以无可辩驳的数据,为围绕AI能力的狂热讨论进行了一次“冷启动”,将行业的目光从对通用智能的模糊幻想,拉回到对真实世界复杂问题解决能力的严肃审视上。它清晰地揭示了,尽管AI在处理结构化问题上已展现出超凡的能力,但在模拟人类科学家那种开放、迭代、充满不确定性的高级认知活动方面,仍然处于非常初级的阶段。
这次“照妖镜”式的评测,带来的不是悲观,而是清醒。它为我们指明了AI在科研领域最切实可行的发展路径——成为人类科学家的“超级副手”,通过自动化和智能化,将人类从繁重的重复性劳动中解放出来,去从事更具创造性的工作。同时,它也为AI科研能力的下一阶段演进划定了蓝图,即超越纯粹的文本推理,构建能够与物理世界互动、实现“观察-假设-实验”完整闭环的智能系统。
告别用单一高分定义成功的时代,拥抱更加场景化、多维度的能力评估体系,是AI走向成熟的必经之路。今天的25分,虽然不高,但它是一个坚实的、经过校准的起点。从这个起点出发,AI作为科学探索伙伴的未来,才真正值得期待。
📢💻 【省心锐评】
FrontierScience戳破了AI“竞赛高分=科研能力”的泡沫,明确其“超级副手”定位。未来发展需超越文本推理,构建与物理世界交互的科研闭环,这才是从“解题”到“科学发现”的关键一步。

评论