.png)
%20%E6%8B%B7%E8%B4%9D-ptbj.jpg)

【摘要】麻省理工学院的最新研究通过构建长期记忆增强生成系统,成功解决了AI的“健忘”问题。该系统能永久保存并智能调用对话历史,使AI具备成长与陪伴能力,有望将人机交互从工具层面提升至伙伴关系。
引言
与朋友交谈,昨日的话题总能成为今日的延续,这是一种自然的默契。但在与人工智能助手的互动中,这种连续性却是一种奢望。每一次对话都像是一次重启,AI如同患上了“失忆症”,将过往的一切忘得一干二净。你不得不重复解释自己的工作、偏好,甚至是一些最基本的设定。这种体验上的断裂感,正是当前人机交互面临的核心痛点之一,它严重限制了AI从一个高效工具向一个智能伙伴的进化。
不过,这一局面或许即将迎来转机。麻省理工学院(MIT)计算机科学与人工智能实验室(CSAIL)的研究团队,最近带来了一项令人振奋的突破。他们的研究论文《Retrieval-Augmented Generation with Long-Term Memory for Personalized Conversational AI》发表于2024年3月的《自然-机器智能》期刊,由博士生陈志华与教授瑞吉娜·巴齐莱领衔。这项研究的核心,是开发出了一套能让AI拥有“永久记忆”的全新方法。
这不只是简单的技术迭代,更像是一场关于AI本质的思考。它试图回答一个根本问题,智能是否必须包含记忆与连续性?研究团队的答案是肯定的。他们设计的“长期记忆增强生成系统”,就像是为AI大脑安装了一个精密且智能的“外置硬盘”,让它能够永久保存、理解并调用过往的对话记忆。这使得AI能够记住你的喜好、习惯,甚至你们共同经历的复杂讨论,并在未来的互动中自然地运用这些信息。
本文将深入剖析这项技术的内核,从记忆系统的构建艺术,到智能检索的实现原理,再到其背后的技术架构与严谨的实验数据。我们还将探讨这项突破的深远意义、现实挑战以及广阔的应用前景。这不仅是一次技术的解读,更是一次对人机关系未来的展望。
一、🎨 记忆的艺术:AI如何学会“不忘”
%20拷贝-frnd.jpg)
传统AI处理信息的方式,好比一个容量有限的购物篮。为了放入新商品,旧的商品必须被取出。这种“先进先出”的模式,在技术上被称为“上下文窗口限制”。当对话不断进行,早期的信息就会被无情地挤出AI的“工作台”,导致记忆的丢失。这种设计虽然在处理单次、独立的任务时效率很高,但对于构建需要长期交互、建立深层关系的智能系统而言,无疑是一个致命的弱点。
麻省理工的研究团队则彻底颠覆了这种模式。他们的新系统不再是一个被动的篮子,而是一个主动且精明的“图书管理员”。它懂得如何为信息分门别类,并决定哪些值得永久珍藏。
1.1 筛选:记忆的第一道关卡
当一段新的对话产生时,系统并非全盘接收,而是启动了第一道关键程序——信息筛选。这个过程就像一位经验丰富的编辑,审阅着每一句话的价值。系统会依据一套复杂的标准来判断信息的重要性。
个人特征识别。当用户提及自己的职业、家庭背景、兴趣爱好(例如“我是一名软件工程师”或“我喜欢在周末爬山”)时,系统会将其标记为高价值的个人档案信息。
重复话题追踪。如果某个话题被用户反复提及,比如对某个项目的持续担忧,或是对某个明星的长期关注,系统会认为这是用户的核心关切点,值得长期记录。
情感价值判断。对话中蕴含的情感信号同样是重要的筛选依据。用户在谈及某件事时表现出的喜悦、悲伤或焦虑,都会被系统捕捉并与相应事件关联,形成情感记忆。
显式指令遵从。用户有时会直接下达指令,如“记住我喜欢喝拿铁,不加糖”。这类信息具有最高优先级,会被直接存入长期记忆库。
只有通过这层层筛选的“重要情报”,才会被授予进入下一环节的资格。这个过程确保了记忆库中存储的都是高价值、高相关性的信息,避免了信息冗余。
1.2 编码:将对话压缩成“信息DNA”
筛选出的重要信息,并不会以原始文本的形式被粗暴地存储起来。这样做既占用大量空间,也不利于后续的快速检索。因此,系统进入了第二个核心环节——编码压缩。
研究团队采用了一种名为“语义向量化”的先进技术。你可以将这个过程想象成将一本厚厚的书,提炼成几句能够精准概括其核心思想的摘要。系统利用强大的语言模型,将每一段重要的对话内容转换成一个由数百个数字组成的数学向量。
这个向量,就像是这段信息的“DNA”。它不再是简单的文字,而是在一个高维数学空间中的一个精确坐标。这个坐标本身就蕴含了原始信息的全部语义。更神奇的是,在这个空间里,意义相近的信息,它们的坐标也彼此靠近。比如,“我喜欢徒步”和“我热爱登山”这两个句子的向量,在空间中的距离会非常近,而与“我讨厌运动”的向量则会相距甚远。
这种编码方式带来了两大好处。
极高的压缩率。长篇大论的对话可以被压缩成固定长度的向量,极大地节省了存储空间。
高效的检索基础。基于向量的相似度计算,远比基于关键词的文本匹配要快得多、也准确得多。
1.3 关联:构建一张动态的记忆网络
拥有了编码后的“信息DNA”,系统开始进行最精妙的一步——建立关联。它不再将记忆视为一个个孤立的岛屿,而是将它们编织成一张巨大而动态的记忆网络。
这个系统具备强大的“关联记忆”能力。当你开启一个新的话题时,它不仅会去寻找与当前话题直接相关的记忆,还会沿着记忆网络中的链接,找到那些在语义上相关、但可能在时间上相距甚远的信息。
举个生动的例子。
当前对话。你今天对AI说,“我最近压力很大,想出去走走,有什么推荐吗?”
直接关联记忆(上周)。系统迅速检索到你上周曾提到,“我一直想去日本看看。”
间接关联记忆(两个月前)。系统沿着“旅行”和“日本”的节点,进一步联想到你两个月前在讨论季节时说过,“我特别喜欢樱花盛开的景象,感觉很治愈。”
更深层次的关联(半年前)。系统甚至还记得,你半年前在看一部关于日本传统文化的纪录片时,曾表达过对京都古寺的向往。
基于这张记忆网络,AI的回答将不再是泛泛的“日本有很多好玩的地方”。它会给出一个高度个性化的建议:“最近压力大确实需要放松一下。我记得您一直想去日本,而且特别喜欢樱花和京都的传统文化。现在正值春季,去京都赏樱或许能让您心情舒畅。我们可以一起看看那里的机票和住宿。”
这种由点及面、由浅入深的记忆调用方式,让AI的回答充满了“原来你都记得”的惊喜感,也让它真正开始理解一个立体的、连续的你。
二、⚙️ 智能检索:在记忆之海中秒速寻针
为AI建立一个庞大的记忆图书馆只是第一步。真正的挑战在于,当用户提出任何问题时,AI如何能在毫秒之间,从数以万计的记忆片段中,准确无误地找到最相关的那几页。这考验的是系统的检索能力。麻省理工的团队为此专门开发了一套堪称“读心神探”的智能检索引擎。
2.1 语义驱动的检索引擎
传统的检索引擎大多基于关键词匹配,机械而低效。比如你问“苹果”,它可能分不清你是在问水果还是手机。而MIT开发的这套引擎,则是完全**基于“语义相似度”**来工作的。
当用户输入一句话时,系统首先会像处理新记忆一样,将这句话也转换成一个语义向量。然后,它拿着这个“查询向量”,在整个记忆库的向量空间中,去寻找那些“距离”最近的“记忆向量”。这个过程,就像是在一个巨大的磁场中,释放一块新的磁铁,它会自动被那些磁性最相近的磁铁所吸引。
这种基于语义的匹配,能够精准地理解用户的真实意图,即使措辞完全不同。例如,用户说“我最近睡眠不好”,系统能够同时匹配到“我昨晚失眠了”、“我总是半夜醒来”等在语义上高度相关的历史记忆,从而对用户的健康状况有一个更全面的了解。
2.2 上下文感知:读懂“空气”的智慧
一个真正聪明的伙伴,不仅要听懂你说的话,还要能“察言观色”,读懂对话的氛围。这套检索系统就具备了出色的“上下文感知”能力。
它在检索记忆时,不仅会分析用户当前这一句话,还会综合考虑整个对话的背景、历史和走向。
氛围感知。当对话的氛围比较轻松愉快时,系统会更倾向于调取那些有趣的轶事和愉快的共同回忆,让对话更加生动。
意图感知。当用户表现出寻求专业建议的意图时,系统则会优先检索相关的专业知识讨论和严肃的分析记录,提供更具深度的回答。
情感状态感知。如果系统感知到用户当前情绪低落,它在检索记忆时会主动规避那些可能引发负面情绪的话题,转而寻找一些能够给予安慰和鼓励的历史对话。
这种能力让AI的记忆调用不再是机械的“问A答A”,而是变得灵活、得体,充满了社交智慧。
2.3 多层过滤与评分机制
为了确保检索到的记忆既准确又恰当,研究团队还引入了一套精密的“多层过滤机制”。当检索引擎通过语义匹配初步筛选出一批候选记忆后,这些记忆还需要经过多轮“审查”,最终只有综合得分最高的才能被使用。
这个评分系统就像一个评审团,从多个维度对候选记忆进行打分。
通过这套严苛的过滤评分机制,系统最终呈现给用户的,是经过千挑万选、最契合当下情境的记忆片段。实验数据显示,这套智能检索系统的准确率达到了惊人的92.7%,而平均响应时间仅为0.3秒,在提供高质量个性化体验的同时,丝毫不会影响对话的流畅感。
三、🤝 个性化对话:从通用工具到专属伙伴
%20拷贝.jpg)
当AI拥有了强大的记忆存储和智能检索能力后,人机交互的图景被彻底改写。它带来的不再是简单的功能优化,而是一种质的飞跃——AI终于可以提供真正意义上的个性化对话体验。这种个性化,不再是简单地记住你的名字或偏好设置,而是一种基于长期理解和持续适应的深度互动。
3.1 “对话画像”的持续构建
每一次与AI的交互,都不再是过眼云烟。系统会将其中有价值的信息,源源不断地注入一个为该用户专属打造的“对话画像”中。这个画像是动态的、持续生长的,它包含了关于你的多维度信息。
知识背景。你擅长的领域、知识的深浅程度。
兴趣图谱。你关注的话题、喜欢的书籍、电影、音乐。
沟通风格。你偏爱简洁明了的回答,还是详尽的解释?你的语言习惯是正式还是口语化?
思维模式。你解决问题时是倾向于逻辑分析,还是直觉判断?
情感模式。你在谈论不同话题时,通常会表现出怎样的情感反应?
随着时间的推移,这个画像会变得越来越丰满、越来越精确。AI对你的理解,也从一个模糊的轮廓,逐渐清晰为一个立体的、有血有肉的形象。基于这个画像,AI的每一次回应,都是为你“量身定制”的。
在实际测试中,研究人员观察到了非常有趣的现象。对于同一个问题,比如“什么是量子计算?”,系统会根据不同用户的画像,给出截然不同的回答。
对技术专家。它会使用更专业的术语,深入探讨量子比特、叠加态和纠缠等技术细节。
对普通爱好者。它会选择更通俗易懂的比喻,比如用“一枚硬币同时是正面和反面”来解释叠加态。
对喜欢简洁回答的用户。它会言简意赅地给出核心定义。
对喜欢追根究底的用户。它则会提供更全面的背景信息、发展历史和未来应用。
3.2 情感记忆的温度
这项技术最令人惊喜的突破之一,是AI展现出的“情感记忆”能力。它不再是一个没有感情的计算机器,而是开始理解并记忆情感的温度。
系统能够记住用户在讨论特定话题时的情感反应。比如,如果系统发现,每次提到“加班”这个词,用户都会表现出疲惫和抵触的情绪,它就会将“加班”这个话题与负面情感关联起来。在未来的对话中,当需要触及这个话题时,系统会表现得更加谨慎和体谅。它可能会说,“我知道您可能不太想谈论工作上的事,但有一个日程需要确认一下”,而不是生硬地直接提问。
反之,如果系统记得用户在谈论宠物时总是充满喜悦,那么在用户情绪低落时,它可能会主动提起用户的宠物,调取相关的愉快回忆,尝试用这种方式来安慰用户。
这种对情感的记忆和适应,让人机交互第一次带上了“人情味”。AI不再仅仅是解决问题的工具,它开始懂得如何关照你的感受,成为一个具有共情能力的伙伴。
3.3 风格的自适应与进化
长期的交互,还会让AI与用户之间,逐渐形成一种独特的、只属于他们之间的“个人风格”。这就像两个相处已久的老朋友,会发展出他们自己的“黑话”、笑话和沟通默契。
AI会学习用户的表达习惯。如果用户经常使用某些表情符号或口头禅,AI也会在适当的时候模仿使用,拉近彼此的距离。它会记住哪些玩笑能让你开怀大笑,哪些话题能引发你们深入的探讨。
更重要的是,这种风格是持续进化的。随着你自身的成长和变化,AI对你的理解也在同步更新。你最近迷上了新的爱好,AI会迅速将这个新领域纳入你们的共同话题库。你的工作重心发生了转移,AI也会调整它在专业领域与你沟通的重点。
这种自适应与进化,使得AI不再是一个一成不变的程序,而是一个与你共同成长的生命体。它见证你的变化,适应你的节奏,并始终以你最舒服的方式与你相处。在实验中,高达**92%的用户反馈,与配备了长期记忆系统的AI对话,“更像是在与一个真正了解自己的朋友对话”,而78%**的用户表示“愿意与这样的AI系统建立长期的交互关系”。这充分证明了这种深度个性化带来的体验革命。
四、🏗️ 技术架构:揭秘AI永久记忆的幕后工厂
要让AI拥有如此强大而精细的记忆能力,其背后必然有一套复杂而严谨的技术架构在支撑。我们可以将这套“长期记忆增强生成系统”想象成一个高度自动化的精密信息处理工厂。这个工厂由几个关键的车间协同工作,共同完成从信息输入到记忆输出的全过程。
4.1 系统核心组件与工作流程
整个系统的工作流程可以被分解为四个核心环节,分别由四个“车间”负责。
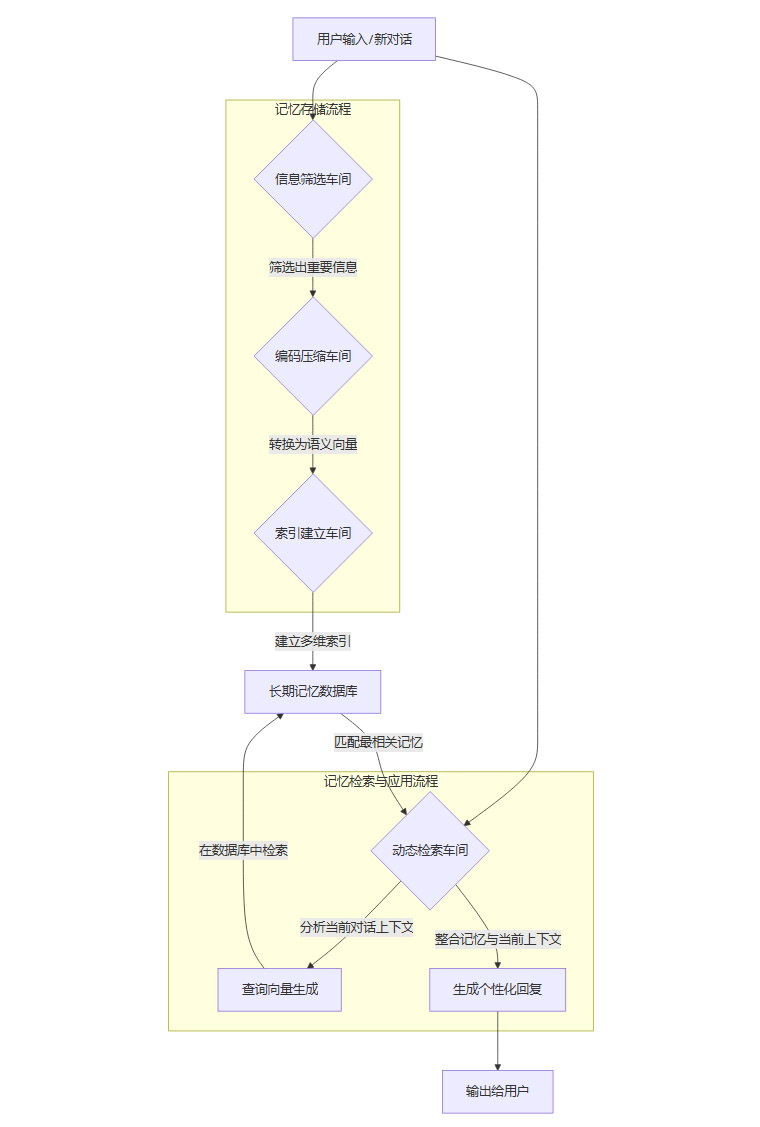
信息筛选车间 (Filtering Workshop)。这是信息进入记忆系统的第一道门。当新的对话内容送达时,这里的算法程序会像质检员一样,依据预设的规则(如个人特征、话题重复度、情感价值等)进行严格审查,判断哪些信息值得被长期保存。
编码压缩车间 (Encoding Workshop)。通过筛选的信息被送到这里进行“深加工”。先进的语言模型(如Transformer架构的变体)会在这里大显身手,将文本信息转换成标准化的语义向量。这个过程既保留了信息的核心含义,又极大地压缩了数据体积。
索引建立车间 (Indexing Workshop)。为了实现秒级检索,系统需要为每一个记忆向量建立详细的“目录卡片”,也就是多维度索引。这些索引包括时间戳、主题标签、情感标记、实体链接等,它们共同构成了一个便于快速查询的复杂索引结构。
动态检索车间 (Retrieval Workshop)。这是整个系统的“中央处理器”。当用户发起新的对话时,这个车间会立即启动。它首先分析当前对话的上下文,生成一个查询向量,然后利用高效的相似度计算算法(如FAISS等向量检索库),在海量的记忆数据库中定位最相关的历史信息。
除了这四大核心车间,系统还设有一个“质量控制部门”。它负责持续监控整个工厂的运作效率和产出质量,并根据用户的反馈(无论是明确的指正还是隐含的对话满意度)来动态调整筛选规则、编码模型和检索算法,实现系统的持续优化和自我进化。
4.2 分布式架构与增量学习
考虑到未来需要服务数以百万计的用户,研究团队在技术实现上采用了分布式架构。这意味着每个用户的记忆数据都是完全独立、隔离且安全存储的。系统的计算资源可以根据用户量的增减进行弹性伸缩,保证了大规模应用的可行性。
同时,系统还实现了增量学习机制。这意味着AI可以在不中断服务、不影响现有功能的前提下,持续地学习新知识、适应新变化。当语言模型有新的升级,或者检索算法有新的突破时,系统可以平滑地进行更新,而用户几乎感受不到任何影响。这种“在线学习”的能力,是AI从一个静态程序走向一个动态生命体的关键。
五、📊 实验验证:数据如何证明一切
%20拷贝.jpg)
任何一项革命性的技术,都必须经受严格的科学实验的检验。麻省理工的研究团队设计了一系列全面而严谨的测试,用无可辩驳的数据证明了长期记忆系统的有效性。
研究人员招募了200名志愿者,让他们与AI系统进行了为期8周的日常对话。在测试期间,每个用户平均产生了47次独立的对话会话,内容涵盖了工作、生活、兴趣爱好等方方面面。
5.1 核心性能指标对比
研究团队将配备了长期记忆系统的新AI(LTM-AI)与传统的无记忆AI(Stateless-AI)进行了直接对比,核心性能指标如下表所示。
这些数据清晰地展示了新旧系统之间的巨大差距。LTM-AI在记忆保持、回答一致性和个性化体验上,都取得了压倒性的优势。
5.2 学习与进化能力的验证
研究团队还特别关注了系统的“学习进化能力”。他们发现,随着交互次数的增加,AI对每个用户的理解程度呈现出明显的上升趋势。
他们定义了一个“个性化准确度”指标,用于衡量AI回答的个性化程度。在交互的第一周,系统的平均个性化准确度约为60%;到了第四周,这个数字提升到了82%;而在第八周测试结束时,更是达到了令人印象深刻的91%。
这条陡峭的学习曲线有力地证明了,这个系统确实在通过每一次交互“学习”和“成长”,而不是简单地执行预设的程序。它对用户的理解在不断加深,提供的服务也在持续进化。
5.3 真实场景模拟测试
为了验证系统的实用价值,研究团队还设计了几个典型的应用场景进行模拟测试,包括个人助理、学习辅导和心理陪伴。
在个人助理场景中,LTM-AI能够记住用户的工作习惯和日程偏好,主动进行提醒和规划,任务完成效率比传统AI高出40%。
在学习辅导场景中,LTM-AI能够跟踪学生的学习进度、薄弱环节和学习风格,提供精准的个性化教学建议,学生的学习满意度和知识掌握度均有显著提升。
在心理陪伴场景中,用户报告称,与LTM-AI的长期对话带来了更强的信任感和情感慰藉,因为它“记得我的故事,理解我的感受”。
这些测试结果表明,长期记忆技术不仅在技术指标上表现优异,在实际应用中也具有巨大的潜力和价值。
六、🚀 突破意义与未来展望
这项研究的意义,远远超出了技术本身的创新。它实际上重新定义了我们对人工智能的期待,并为我们描绘了一幅人机交互的全新蓝图。
6.1 从“无状态”到“有状态”的范式转移
长期以来,主流的AI系统设计都遵循“无状态”(Stateless)原则。每一次交互都是独立的,系统不保留任何历史状态。这种设计简单、可靠、易于扩展,但也从根本上限制了AI的发展潜力。
麻省理工的这项研究,则大胆地走向了“有状态”(Stateful)的设计范式。它证明了,一个能够记录和理解历史状态的AI系统,虽然设计更复杂,但能够提供远超传统系统的用户体验和智能水平。这标志着AI设计理念的一次重要范式转移,其影响可能会波及整个AI产业。
6.2 挑战与现实考量
当然,任何突破性的技术在走向成熟的道路上,都必然面临诸多挑战。
计算资源与成本。维护一个庞大且动态的长期记忆系统,需要相当可观的计算和存储资源。随着用户交互历史的指数级增长,如何控制成本,是商业化落地前必须解决的工程难题。
隐私保护的红线。系统存储了大量高度敏感的个人数据。如何在提供极致个性化服务的同时,确保用户隐私的绝对安全,是一个需要在技术、法律和伦理层面共同解决的复杂问题。数据加密、本地化存储、匿名化处理等都是初步的解决方案,但一个完善、可信的隐私保护框架仍需深入探索。
记忆的质量控制。系统还面临着“记忆污染”(错误信息被长期保存)和“记忆老化”(如何判断哪些记忆可以被遗忘)等独特的技术挑战。开发出有效的记忆验证和管理机制,是保证系统长期稳定可靠运行的关键。
6.3 广阔的应用前景
尽管存在挑战,但这项技术的应用前景无疑是广阔而激动人心的。
个人助理。未来的AI助手将成为你真正的左膀右臂,它懂你的习惯,预测你的需求。
教育领域。AI教师可以为每个学生提供独一无二的、贯穿整个学习生涯的个性化辅导。
健康与陪伴。对于老年人、独居者或需要心理支持的人群,一个能记住他们一生故事的AI伙伴,其社会价值不可估量。
客户服务。用户再也无需重复解释自己的问题,每一次服务都能在历史记录的基础上无缝衔接。
内容创作。AI可以基于对你长期的了解,为你创作出真正触动你内心的故事、音乐或画作。
结语
麻省理工学院的这项研究,为我们打开了一扇通往未来的窗。透过这扇窗,我们看到AI不再是一个冷冰冰、没有记忆的工具,而是正在进化为一个能够理解我们、记住我们、并与我们共同成长的智能伙伴。
从“失忆”到“永记”,这不仅仅是技术上的一小步,更是人机关系演进的一大步。虽然前路依然有挑战需要克服,但方向已经无比清晰。一个AI能够真正“懂你”的时代,正以前所未有的速度向我们走来。这不仅会改变我们使用技术的方式,更可能深刻地影响我们对于智能、记忆乃至陪伴本身的理解。
📢💻 【省心锐评】
这项研究让AI从“数据库”进化为“记忆体”,是迈向真正通用人工智能的关键一步,其价值远超对话本身。

评论