.png)


【摘要】解决大模型微调后效果不佳的根源问题,系统性地拆解了从零到一构建高质量SFT数据集的全流程。内容覆盖数据源选择、清洗、标注、迭代,并深入探讨了主流数据格式、质量评估体系、常见误区及未来趋势,旨在提供一套可落地、能避坑的实战指南。
引言
在大模型应用加速落地的背景下,SFT(Supervised Fine-Tuning)成为提升模型能力、使其精准对齐业务需求的关键一环。而数据集,正是SFT微调的“燃料”。
做过大模型微调的团队,大多都遇到过这样的困境。调参改了十几次,模型还是答非所问。客服场景里,它总聊起无关的产品功能。代码生成时,它频繁出现语法错误。甚至对用户的提问,给出完全偏离业务逻辑的回复。
这时候,问题往往不是参数没调好,而是我们忽略了更基础的环节,SFT数据集的构建。SFT的核心,是让模型学会理解并遵循人类的意图与指令。数据集,就是我们用来“教模型怎么做事”的教材。
一本质量差的教材,再聪明的学生也学不到精髓。
所以,本文将从最实际的操作角度出发,系统性地拆解一套能够真正落地的SFT数据集构建方法。希望能帮助你的团队避开常见坑,让微调效果更贴合业务的真实需求。
🎯 一、先想清楚:数据集构建的3个核心原则
%20拷贝-aukn.jpg)
在动手找数据、洗数据之前,必须先明确方向,否则极易做无用功。这三个原则,是无数项目在实践中验证过的“避坑指南”,也是构建一切高质量数据集的基石。
1.1 对齐业务目标
数据集的构建,首要原则就是与你想让模型解决的问题强绑定。数据并非越多越好,而是越“准”越好。
比如,你的目标是做一个电商客服模型。那么,数据集就应该聚焦在“订单查询”、“售后退换”、“物流跟踪”、“优惠券使用”这类核心场景。如果把大量通用的聊天数据,甚至是其他行业的资讯堆进来,模型的能力就会被稀释。
曾有一个团队在做金融客服微调时,错误地加入了大量股票分析和市场预测的数据。结果,当用户咨询“信用卡还款怎么操作”时,模型反而头头是道地分析起了股市走势。这就是典型的数据与业务目标脱节,导致模型“跑偏”。
特别是对于面向企业(toB)的场景,这个问题更为突出。如果在一个为企业客户服务的模型中,混入了大量面向个人消费者(toC)的对话数据,就会产生**“数据偏移”**。这不仅无法提升模型性能,反而可能导致其在专业问题上的表现倒退,回复显得非常业余。
核心要点,所有数据收集和筛选工作,都必须紧紧围绕预设的业务目标展开。无关的数据,即便质量再高,也应果断舍弃。
1.2 质量优先于数量
很多人有一个误区,认为数据量越大,模型效果就越好。实际上,对于SFT阶段而言,数据的质量远比数量重要。
大语言模型在庞大的预训练阶段,已经学到了海量的知识和语言能力。SFT阶段的核心任务,是“对齐”,即教会模型如何以符合人类期望的方式进行对话和遵循指令。研究和实践都表明,有时仅仅数千条高质量、与业务强相关的指令数据,就足以让模型在特定任务上取得显著的提升。
一个真实的案例是,某团队起初使用了50万条公开的对话数据进行SFT,结果模型的回复准确率仅有60%。后来,他们重新筛选,只保留了其中5万条与业务高度匹配、逻辑清晰、信息准确的高质量数据。再次微调后,模型的准确率直接跃升至85%。
宁要五千条精心筛选的高质量数据,也不要五十万条充满噪声的混合数据。低质量数据,比如包含重复内容、逻辑混乱的对话、事实性错误的信息,不仅对模型训练毫无益处,更会“教坏”模型。一旦模型学到了错误的知识或模式,后续再花费巨大的精力去调参,也很难弥补回来。
1.3 覆盖“全场景+多风格”
真实世界远比实验室复杂,模型上线后需要应对的场景五花八门。因此,数据集必须提前考虑到各种可能性,做到场景覆盖全面,同时保持风格统一。
场景覆盖,意味着不仅要包含常规、高频的场景,还要有意识地纳入特殊和长尾的场景。
风格统一,则要求数据集中助手的回复在语气、格式和专业度上保持一致。如果有的回复非常正式、专业,有的却很口语化、卖萌,模型就会学得“精神分裂”。
想象一下,一个为大型企业客户服务的模型,在回答专业的技术问题时,突然冒出一句“亲,这边建议您重启一下呢”,这会严重损害企业形象。因此,在构建数据集时,就要预先定义好模型的“人设”和沟通风格,并确保所有标注的回复都遵循这一标准。可以兼顾多种风格,但对特定客户群体的风格必须统一。
🛠️ 二、落地步骤:从0到1构建数据集的4个关键环节
明确了核心原则后,我们就可以进入实际操作阶段。一个完整的数据集构建流程,通常包含数据来源、清洗、标注和迭代四个关键环节。
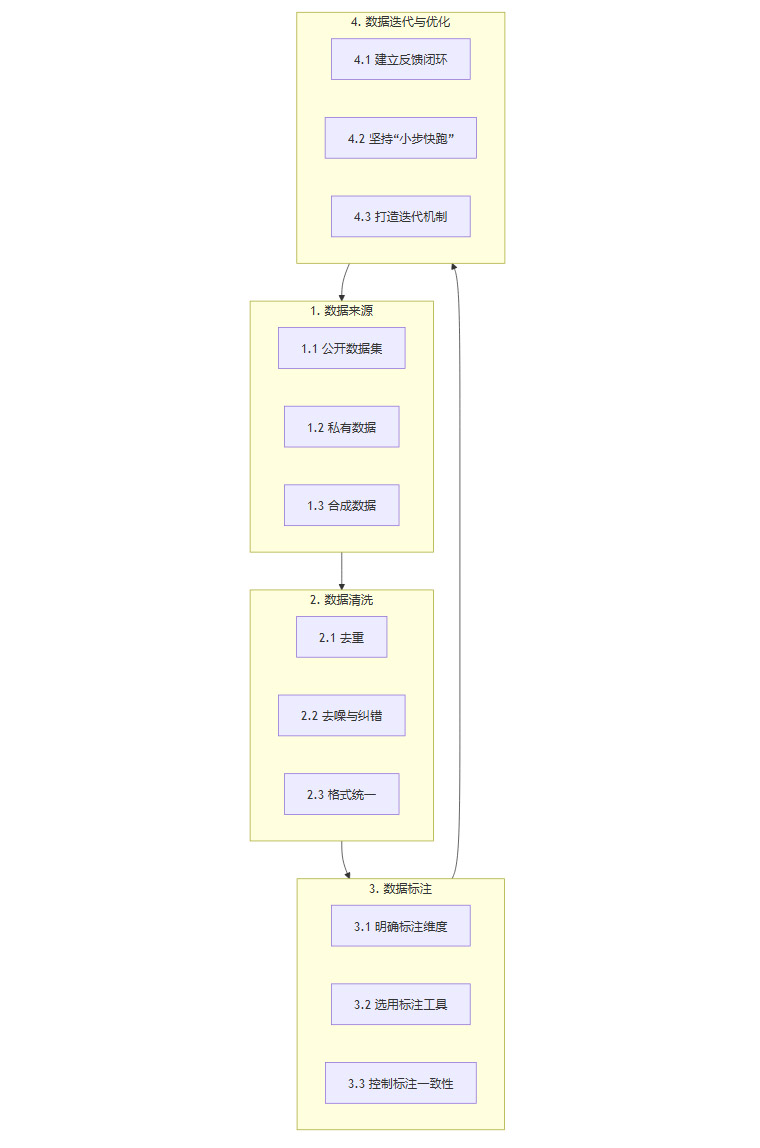
2.1 数据来源:3类核心渠道,各有筛选技巧
数据从哪里来?这是构建数据集的第一步。主要有三类渠道,每类的优缺点和处理方式都不同。
2.1.1 公开数据集
Hugging Face Hub、天池、Kaggle等平台上有海量的对话数据集和指令数据集。此外,还有一些行业垂直的数据集,如医疗领域的MedDialog、金融领域的FinQA等。
这类数据的好处是唾手可得,但问题也同样明显。它们通常是为通用目的构建的,与你的具体业务场景可能相去甚远。
使用公开数据时,筛选是关键。比如,你要做一个美妆电商的客服模型,就可以从一个通用的电商客服数据集中,先用关键词(如“口红”、“粉底液”)筛选出相关对话,然后剔除掉其中关于“家电”、“图书”等无关品类的部分。接着,还需要人工检查对话中涉及的物流政策、售后规则是否与你公司的现行规定有冲突,过时的信息必须舍弃。
2.1.2 私有数据
这是最核心、最有价值的数据来源。它直接来源于你的业务,包括。
企业历史对话记录,如在线客服与用户的聊天记录、销售与客户的沟通邮件。
内部知识库,如产品手册、操作指南、FAQ文档、技术白皮书。
业务日志,如用户在产品内搜索的高频问题、工单系统中的常见问题统计。
这类数据与业务的贴合度无可比拟。但处理时有两个要点必须注意。
第一是数据脱敏。这是合规的红线。在将任何数据用于训练之前,必须通过脚本或工具,严格删除或替换掉所有个人身份信息(PII),包括但不限于用户姓名、手机号、邮箱、地址、身份证号、订单号等。
第二是筛选有效内容。原始的对话记录里,往往充斥着大量无效信息。比如,对话开头连串的“你好”、“在吗”、“Hello”,或者用户发了一个表情就再无下文的无效会话。这些都需要被清洗掉。我们的目标是提取出**“一个清晰的用户提问 + 一个或多个有效的助手回复”**所构成的完整、有信息量的交互片段。
2.1.3 合成数据
当私有数据不足,或者需要补充某些特定但历史上很少出现的场景(长尾场景)时,可以利用基础大模型(如GPT-4、Claude等)来生成数据。这种方法被称为数据合成。
比如,你想为客服模型补充“用户投诉服装缩水”的场景数据,可以给基础模型下达这样的指令。
“请你扮演一名电商平台的资深客服,生成20条用户关于服装缩水问题的咨询对话。对话需要覆盖以下三种情况。1. 用户首次洗涤后发现缩水,在7天无理由退换期内。2. 用户穿着多次后发现缩水,已超过退换期。3. 用户不确定是否为自己洗涤不当导致。你的回复需要体现专业、安抚的态度,并严格遵循以下规则。退换期内可换货,超过退换期则提供优惠券补偿,洗涤不当则提供正确的洗涤建议。”
合成数据最大的隐患在于**“一本正经地胡说八道”**。它可能生成一些看似合理但实际上与你业务规则相悖的回复。比如,你的公司退换货政策是15天,但模型生成了“7天无理由退换”的对话,这就会误导微调后的模型。
因此,所有合成数据都必须经过100%的人工校验。每一条生成的数据,都要有专人对照最新的业务规则手册进行检查,确保事实准确、逻辑无误,才能放入训练集中。
2.2 数据清洗:3步去掉“杂质”,让数据更“干净”
拿到原始数据后,就进入了清洗环节。这个过程就像洗菜,要把泥沙、烂叶子都去掉,才能下锅“烹饪”。一个干净的数据集是模型学得好的前提。
2.2.1 去重
数据集中如果存在大量重复的样本,会让模型在训练时对这些样本产生过度拟合。比如,同一条“怎么查订单物流”的问答对重复了100次,模型可能会误以为这是一个极其重要的问题,从而在实际应用中过度频繁地触发这类回复。
去重分为两个层次。
完全重复。指文本内容完全一样的样本。这可以通过简单的脚本或Pandas等库的
drop_duplicates()方法快速处理。语义重复。指表述不同但核心意思一致的样本。比如“查物流”、“怎么看我的快递到哪了”、“我的物流信息有更新吗”。这类重复需要借助一些更复杂的算法(如文本向量相似度计算)进行初步筛选,再结合人工抽查来确认和删除。
2.2.2 去噪与纠错
去噪,就是删除数据中所有与模型学习任务无关或有害的内容。常见噪声包括。
无意义字符。如乱码、大量的特殊符号(“@#¥%”)、表情符号(除非你的模型需要理解表情)。
无关信息。如对话中混入的广告链接、用户随手转发的文章、客服不小心粘贴的内部备注。
格式标签。如HTML/XML标签(
<p>,<div>等),需要被解析或删除。
纠错,则更进一步,需要修正数据中的逻辑或事实性错误。比如,某条回复里说“退款会在24小时内到账”,但权威的内部知识库明确写的是“3个工作日内到账”。这种存在冲突的信息必须被修正。统一的标准是,以最新的、最权威的内部知识库或业务规则为准。
曾有团队因为没有仔细做去噪,把包含错别字(如“退款会在24小内到账”)的回复放进了数据集,结果微调后的模型也学会了这种错误的用词,影响了专业性。
2.2.3 格式统一
模型对输入数据的格式非常敏感。格式的混乱会严重影响学习效果。因此,在清洗的最后一步,需要将所有数据统一成标准化的结构。
目前,SFT主流的数据格式有几种,可以根据任务类型选择。
将所有数据整理成统一的JSON或JSONL文件,不仅便于后续的数据加载和处理,更能确保模型在训练时接收到一致的输入模式,从而学得更好。
对于一些长文本,比如产品手册里的大段介绍,直接作为答案喂给模型效果不佳。更好的做法是将其拆分成多个“一问一答”的短QA对。例如,将“我们的会员分为银卡、金卡、钻石卡,分别需要消费1000元、5000元、10000元升级”拆分成。
{"instruction": "会员有哪几种?", "input": "", "output": "我们的会员分为银卡、金卡和钻石卡。"}{"instruction": "如何升级为金卡会员?", "input": "", "output": "当年消费累计达到5000元即可升级为金卡会员。"}
这样的处理方式,更符合SFT指令微调的范式,能让模型更高效地学习知识点。
2.3 数据标注:3个维度定标准,避免“标注混乱”
数据清洗完成后,就进入了至关重要的一步,数据标注。标注,就是给数据“打标签”,明确地告诉模型“什么是对的”以及“什么是符合要求的”。如果标注标准混乱,模型就会学得精神错乱,这是很多团队最容易踩的坑。
2.3.1 明确标注维度
在开始标注前,必须先定义好标注的维度。不同的业务场景,需要关注的维度也不同。以一个典型的客服模型为例,我们可以从以下三个核心维度进行标注。
通过多维度的标注,我们不仅告诉了模型“该说什么”,还告诉了它“为什么这么说好”以及“什么绝对不能说”。
2.3.2 选用标注工具
工欲善其事,必先利其器。选择合适的标注工具可以事半功倍。
对于中小型团队,并不需要追求功能复杂、价格昂贵的商业软件。开源的LabelStudio就是一个非常优秀的选择。它支持文本、对话、表格等多种数据类型的标注,并且可以自定义标注界面和规则。比如,你可以将“意图分类”设置为单选题,选项就是预设的几个意图标签,这样可以从源头上减少标注员填错的可能性。
许多云服务商也提供了成熟的在线标注平台,适合数据量巨大、需要多人协同的大型项目。
一个实用的技巧是分批次进行标注和质检。不要等所有数据都标完再检查。可以每完成一批(比如1000条),就随机抽取10%-20%进行质量检查。如果发现问题,比如某个标签的理解有偏差,可以立即调整标注规则并重新培训,避免后续的标注工作在错误的方向上越走越远。
2.3.3 控制标注一致性
当有多名标注员协同工作时,最大的挑战就是保证标准统一。同一个问题,张三可能标为“产品咨询”,李四却标为“售前建议”,这种情况必须避免。
解决这个问题的核心在于建立一套严格的流程。
制定详细的标注手册。这是所有工作的基石。手册中必须用清晰的语言,定义每一个标签的内涵和外延。比如,什么是“产品咨询”?它的定义是“用户询问产品的功能、规格、使用方法等客观信息”。同时,要提供正例(哪些属于)和反例(哪些不属于),比如“这个手机防水吗?”属于产品咨询,但“这个手机好用吗?”则可能更偏向“使用体验咨询”。
开展标注前培训。组织所有标注员一起学习标注手册,确保每个人对规则的理解都在同一个频道上。
进行交叉标注和一致性检验。在项目初期,可以安排两名标注员标注同一批少量数据(比如100条)。然后计算他们标注结果的一致性率(如Cohen's Kappa系数)。如果一致性低于预设的阈值(比如90%),说明标注规则存在模糊地带或者标注员理解有偏差。
建立仲裁机制。对于出现分歧的样本,不能简单地由某个人决定。应该由一个小组(或资深标注专家)进行集体讨论和仲裁,并将最终结论和理由补充到标注手册中。这样,标注手册本身也会在实践中不断迭代和完善。
2.4 数据迭代:上线后根据反馈持续优化
数据集的构建不是一个一次性的任务,而是一个持续迭代、不断优化的动态过程。模型上线发布,仅仅是第一步。真正的优化,来源于真实世界用户的反馈。
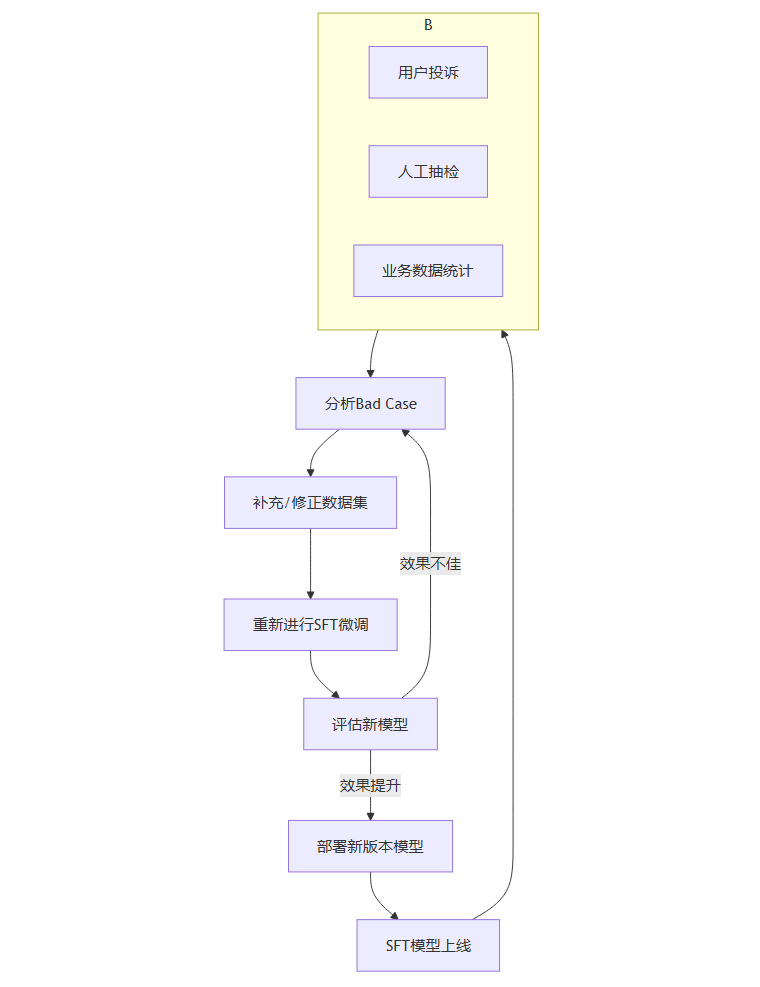
2.4.1 建立反馈闭环
如何高效地收集反馈?可以从以下三个渠道入手。
用户投诉与差评。这是最直接的反馈来源。当用户反馈“模型说可以全额退款,但客服说只能退一半”时,这就是一个极高质量的Bad Case。我们需要记录下来,分析是数据集中没有覆盖“部分退款”的场景,还是已有的数据本身存在错误。
周期性人工抽检。不能完全依赖用户投诉。需要有专门的运营或测试人员,每天或每周随机抽取一定比例的模型回复进行检查。检查内容包括回复是否准确、逻辑是否通顺、是否符合最新的业务规则、语气是否得当等。不合格的案例同样需要整理成新的训练数据。
业务数据统计分析。通过后台日志,分析哪些问题的回复准确率较低,或者哪些问题用户追问的次数最多。比如,发现“如何办理会员续费”这个问题的对话中,用户满意度只有70%,那就说明模型在这方面的能力有短板,需要针对性地补充这类场景的对话数据。
2.4.2 坚持“小步快跑”
数据迭代时,要避免一次性“憋个大招”。不要等积累了数万条新数据再进行一次大规模的更新。更有效的方式是**“小步快跑,频繁迭代”**。
每次只补充几百到几千条经过精细筛选和标注的高质量数据,然后重新进行一次微调。这样做的好处是。
时间成本低。一次小的微调可能只需要几个小时,可以快速验证新数据的效果。
风险可控。如果一次性加入大量未经充分验证的数据,可能会引入新的、意想不到的问题(比如新老数据存在逻辑矛盾),导致模型性能不升反降。小步迭代更容易定位问题。
有团队采用每两周迭代一次的策略,每次补充约500条从用户反馈中提炼的优质案例。通过这种方式,模型的关键指标准确率每月能够稳定提升5%到8%,效果非常稳健。
📊 三、数据集格式与质量评估
%20拷贝-tcfv.jpg)
一个规范的数据集,不仅要有高质量的内容,还要有标准的格式和科学的评估体系。
3.1 主流数据格式回顾
前面我们提到了几种主流的数据格式,这里再做个归纳,方便你在不同任务中选择。
选择哪种格式,取决于你的核心任务。如果是构建一个FAQ问答机器人,Alpaca格式可能就足够了。但如果是要打造一个能联系上下文的智能客服,ShareGPT格式会是更好的选择。如果你的模型需要处理复杂的逻辑推理问题,引入COT格式的数据会大有裨益。
3.2 质量评估:自动化与人工的结合
如何评估我们构建的数据集质量足够高?这需要建立一套结合自动化工具和人工专家的评估体系。
3.2.1 自动化与人工结合的评估流程
一个高效的评估流程应该是这样的。
自动化初筛。利用一些规则引擎或另一个更强的“裁判模型”(Judge Model),对数据集进行批量评分。比如,可以写规则检查答案是否包含某些禁用词,或者用裁判模型判断回复是否“有帮助”。
人工专家复审。对于自动化工具难以判断的边界样本(比如评分在中间档的、涉及复杂逻辑的),交由领域专家进行人工复审和打分。
形成“评估-修正-优化”闭环。将评估中发现的所有问题进行归类,分析是数据源的问题、清洗的问题还是标注的问题,然后返回到相应的环节进行修正,从而持续提升数据集的整体质量。
3.2.2 关键评估维度
评估数据集质量时,可以重点关注以下几个维度。
准确性(Accuracy)。数据中包含的信息是否事实正确?回复是否精准地解答了用户的问题?
完备性(Completeness)。回复是否包含了解决问题所需的所有关键信息?有没有遗漏要点?
一致性(Consistency)。数据集中是否存在相互矛盾的说法?回复的风格、术语是否统一?
安全与合规(Safety & Compliance)。数据是否经过了充分的脱敏?回复内容是否符合法律法规和公司政策,不包含任何有害、歧视性或危险的言论?
🚧 四、常见误区与避坑指南
在数据集构建的道路上,有几个反复出现的“大坑”,许多团队都曾在此栽过跟头。了解它们,可以让你少走很多弯路。
4.1 误区一:贪多求全,忽视匹配度
这是最常见的误区。很多人抱着“数据量越大越好”的心态,把各种能找到的通用数据、跨领域数据都堆进训练集,期望模型能成为一个“通才”。
结果往往事与愿违。一个为专业医疗咨询设计的模型,如果喂给它大量日常闲聊数据,它在回答严肃医学问题时的专业性就会被稀释。堆积无关数据,只会让模型在真正重要的业务重点上“失焦”。
避坑指南。始终牢记“宁缺毋滥”。坚决围绕业务目标筛选数据,不符合的再优质也果断放弃。如果核心数据量不足,优先通过“高质量私有数据 + 精准合成数据”的方式进行补充,而不是盲目地用通用数据去凑数。
4.2 误区二:过度依赖自动化,跳过人工校验
自动化脚本和工具在处理数据清洗(如去重、格式化)时效率很高,但这让一些团队产生了错觉,认为可以完全依赖工具,从而省去耗时耗力的人工校验环节。
这是一个巨大的隐患。自动化工具几乎无法胜任需要深度理解和业务知识的任务。
它无法识别**“回复的逻辑错误”**。比如,回复中建议“退款需要您提供身份证照片”,但实际上公司规定完全不需要。
它无法判断**“回复是否符合最新的业务规则”**。比如,公司的退换货政策刚从7天延长到15天,工具对此一无所知,自然也无法发现数据中的过时信息。
避坑指南。自动化工具只能作为初步处理的助手。所有关键环节,特别是合成数据的校验、业务规则的匹配、模糊意图的判断,都必须有人工深度参与。对于核心业务场景的数据,进行100%的人工检查是完全必要的投资。
4.3 误区三:标注标准模糊,规则全凭感觉
如果缺乏一份清晰、统一的标注手册,标注工作就会变成一场灾难。每个标注员都可能根据自己的理解去“自由发挥”。
比如,“这个产品有质量问题吗?”这个提问,有人可能标为“产品咨询”,有人标为“售后咨询”,还有人可能标为“投诉”。这样标注出来的数据,会让模型感到极度困惑,因为它无法从中学习到一个稳定、清晰的意图识别模式。
避坑指南。在标注工作开始前,必须投入足够的时间制定一份详尽的标注手册。手册要包含每个标签的明确定义、判断标准、正例和反例。组织所有标注员进行统一培训,并通过交叉检查和仲裁机制,确保所有人的判断标准都拉齐在同一水平线上。
🚀 五、进阶与未来趋势
%20拷贝.jpg)
做好了基础工作,我们还可以放眼未来,了解一些能让数据集构建工作更上一层楼的进阶技术和发展趋势。
5.1 混合训练,防止“灾难性遗忘”
SFT虽然能让模型在特定领域表现出色,但有时也会导致它在其他通用能力上的衰退,这种现象被称为**“灾难性遗忘”**(Catastrophic Forgetting)。
一个有效的缓解策略是混合训练。在进行SFT时,不要只用你的业务数据。可以按一定比例(比如80%的业务数据,20%的通用多领域数据)混合训练。这样,模型在学习新知识的同时,也能定期“复习”已有的通用能力,从而变得既“专”又“广”。
5.2 指令多样性度量与分析
数据集的质量不仅在于单条数据的优劣,还在于整体的多样性。如果数据集中充满了大量简单、重复的指令,模型的泛化能力就会很差。
可以使用一些指令分析工具(如InsTagger/InsTag)来度量和分析数据集中指令的覆盖范围和复杂度。这可以帮助你发现数据集的短板,比如是否缺少“对比分析类”的指令,或者“代码生成类”的指令过于简单。少量覆盖广泛、复杂度高的高质量指令,其价值远超海量简单重复的低质指令。
5.3 SFT+RAG混合架构
对于知识更新频繁(如新闻、政策、产品价格)或需要极高事实准确性、可解释性的场景,单纯依靠SFT将所有知识“塞”进模型里,既不高效也不可靠。
这时,SFT与RAG(检索增强生成)的混合架构是更稳妥的选择。
RAG负责从外部知识库(如数据库、文档库)中实时检索最新、最准确的信息。
SFT则负责教会模型如何更好地遵循指令、理解用户意图,以及如何利用RAG检索到的信息,生成风格统一、流畅自然的回复。
两者协同工作,SFT让模型“会说话”,RAG让模型“说对话”,是一种非常强大的组合。
5.4 动态数据集与自动化工具
未来的数据集构建会越来越智能。动态数据集系统能够让模型在上线后自动收集用户反馈和Bad Case,筛选出需要补充的数据,甚至利用大模型自身的能力,自动生成初步的标注建议(如意图分类、质量评分),人工只需做最后的审核和校验。这将极大提升数据迭代的效率。
5.5 隐私保护与联邦学习
数据是宝贵的资产,但数据隐私和安全是不可逾越的红线。对于一些数据敏感的行业(如金融、医疗),直接共享原始数据进行训练是不可行的。
联邦学习(Federated Learning)等隐私计算技术为此提供了解决方案。它允许在不泄露各方原始数据的情况下,联合多个机构的数据源进行模型训练。这为解决单个机构数据量不足、数据孤岛等问题开辟了新的道路。
5.6 一体化数据构建与训练平台
随着大模型应用的成熟,会出现越来越多的一体化平台。这些平台将数据洞察、数据增强、清洗、多人协同标注、模型迭代训练等环节整合在一起,形成标准化的CPT→SFT→DPO(持续预训练→监督微调→直接偏好优化)链路。这不仅能大幅提升工作效率,还能通过统一的权限和流程管理,保障数据和模型的安全性。
📋 六、团队执行清单(实操建议)
理论终须落地。为了帮助你的团队更有条不紊地推进数据集构建工作,这里提供一个可供参考的执行清单和时间规划(以一个为期5周的初版数据集构建项目为例)。
这个清单提供了一个基本的框架,你可以根据自己团队的实际情况和项目复杂度进行调整。核心思想是谋定而后动,小步快跑,持续迭代。
总结
SFT微调数据集的构建,是一项系统性工程,远非简单的“找数据、标数据”可概括。它的核心,始终围绕着对齐业务、保证质量、覆盖多样性、持续迭代这几个关键词。
从确立三大核心原则,到走通数据来源、清洗、标注、迭代的完整流程;从规避贪多求全、依赖自动化、标准模糊的常见误区,到拥抱混合训练、RAG、联邦学习等前沿趋势。每一个环节,都直接决定了你最终微调出的模型,是会成为解决实际问题的得力助手,还是一个答非所问的“人工智障”。
高质量、精细化的数据集,是大模型微调成功的真正基石。未来,随着自动化筛选、智能标注等技术的发展,数据集构建的效率无疑会越来越高,过程也会越来越“智能”。但我们必须清醒地认识到,“数据为王”的本质不会改变。
对于绝大多数团队而言,与其追逐最炫酷的模型或最复杂的调参技巧,不如静下心来,把数据集这个基础环节做扎实。只有这样,才能训练出真正能够赋能业务、创造价值的高效模型。毕竟,好的模型不是凭空“调”出来的,而是用优质的“教材”一步步“教”出来的。
📢💻 【省心锐评】
别再迷信调参玄学了。模型效果的上限,在你准备第一条数据时就已注定。垃圾进,垃圾出,这是AI领域颠扑不破的真理。

评论