.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】MIT大规模实证研究揭示,AI基础模型领域的“算力鸿沟”正固化为“算力垄断”。少数机构掌控创新命脉,学术生态面临结构性风险,技术普惠的理想遭遇严峻挑战。

引言
过去三年,人工智能领域经历了一场深刻的范式革命。基础模型,特别是大语言模型,从一个前沿探索方向迅速演变为整个技术生态的核心。我们看到,围绕少数几个基础模型的研发、微调与应用,已经成为AI创新的主旋律。这场革命带来了前所未有的技术能力,也带来了一个过去被低估的结构性问题,GPU不平等。
算力,曾被视为研究的工具与耗材。如今,它正演变为一种权力,一种决定谁能参与前沿创新、谁只能在外围应用的“入场券”。麻省理工学院(MIT)联合多所高校进行的一项大规模实证研究,系统性地量化了这一现象。研究团队通过分析2022至2024年间数千篇顶会论文与数百位作者的调研数据,为我们描绘了一幅算力资源如何重塑学术版图的清晰图景。
这不再是简单的资源分配不均,而是一种趋向垄断的结构性固化。本文将基于这项研究的核心数据与洞察,深入解析基础模型研究中的“算力垄断”现象,剖析其具体表现、深层影响,并探讨可能的应对路径。
💠 一、范式革命的入场券,算力门槛的指数级抬升
%20拷贝.jpg)
AI研究的范式已经发生了根本性转变。过去,研究者们习惯于“小任务、小模型”的模式,针对特定问题设计专用算法。这种模式对算力的要求相对分散且可控。如今,整个领域的研究活动正快速向少数几个强大的基础模型收敛。
1.1 研究焦点的剧烈迁移
基础模型已成为AI顶会的主角。MIT的研究数据显示,相关论文在顶级会议中的占比呈现出爆炸性增长。
表1:基础模型相关论文在AI顶级会议中的占比变化
这个数据背后,是研究活动的“生态化”转型。研究者不再仅仅是算法的设计者,更像是围绕一个庞大操作系统(基础模型)进行二次开发、优化和应用的工程师。这种转型直接导致了对算力需求的急剧膨胀。
1.2 实验成本的量级跃升
前沿研究的标配不再是几块GPU跑几周实验。一个典型的基础模型研究项目,其资源消耗是惊人的。
平均周期:研究项目平均需要持续160天。
基础算力:实验所需GPU数量的中位数为4个。
前沿标配:更大规模的预训练、对齐或系统级优化,动辄需要数百乃至上千个GPU并行运行数月。
这种量级的投入,已经远远超出了绝大多数高校实验室或中小型研究团队的承受范围。高端GPU(如NVIDIA A100/H100)的供给受限与价格高昂,进一步加剧了这一门槛。算力,正从一个可变量,变成一个决定研究项目能否启动的“准入许可”。
💠 二、资源版图重塑,算力的高度集中化
随着算力门槛的抬高,全球AI研究的资源版图正在被快速重塑。资源不再是均匀分布,而是向少数几个“超级节点”高度集中。
2.1 地理格局的双极主导
从全球范围看,基础模型研究的产出呈现出明显的地理集中化。
美国:凭借其深厚的科技产业基础、顶尖高校集群和强大的资本市场,在基础模型的数量、质量和影响力上均处于全球领先地位。
中国:依托庞大的数据市场、政府主导的科研投入和快速发展的科技企业,在学术论文发表数量上已跃居全球第一,形成了与美国并驾齐驱的双极格局。
其他国家和地区虽然也有参与,但在核心的基础模型创新上,与中美两国存在显著差距。这种格局表明,国家级的科技战略与基础设施投入,是参与这场竞赛的先决条件。
2.2 机构结构的“超级节点 + 长尾”
在机构层面,集中化趋势更为明显。少数科技巨头和顶尖学府构成了金字塔的顶端,形成了“超级节点”,而广大的普通高校和研究机构则构成了长长的“尾部”。
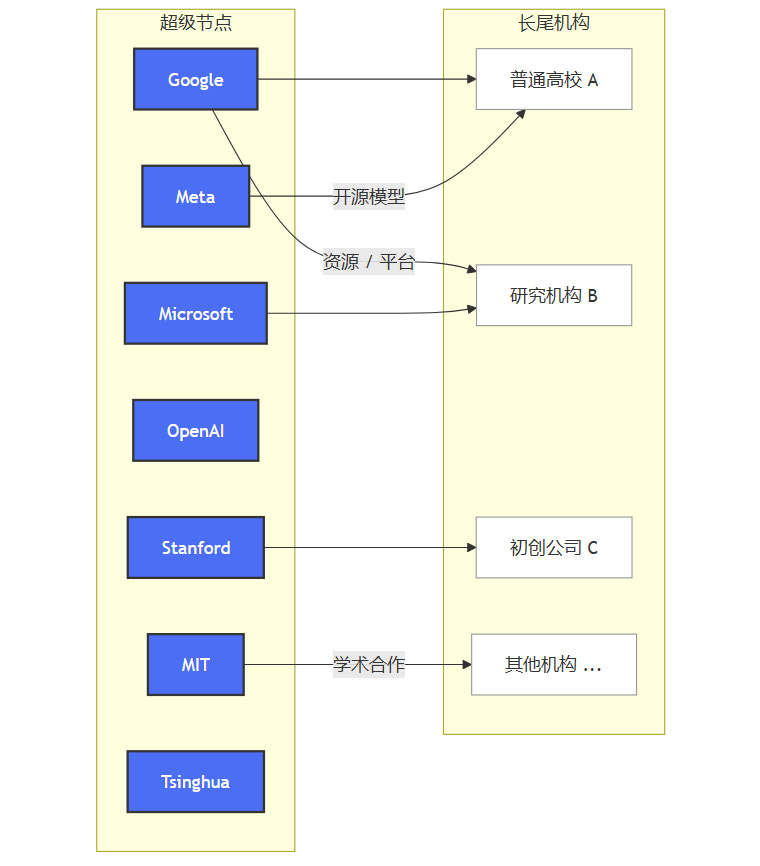
图1:基础模型研究的机构结构示意图
MIT的研究数据证实了这一结构。
巨头产出惊人:谷歌、微软等单一科技公司的论文产出数量,已经超过了许多世界一流大学。
平均产出趋同:虽然学术机构发表的论文总数(4851篇)远多于工业界(1425篇),但平均到每个机构,工业界的产出(8.72篇/机构)与学术界(7.93篇/机构)已非常接近。
这个看似微小的平均产出差异,揭示了一个残酷的现实。学术界的巨大产出是由大量“长尾机构”的少量贡献汇集而成,而核心的、高强度的研究活动,正被少数“超级节点”所主导。
💠 三、创新权力的转移,基础层研究的垄断格局
%20拷贝.jpg)
算力的高度集中,直接导致了创新权力的转移。基础模型研究并非铁板一块,可以大致分为基础层创新和应用层创新。算力鸿沟正在将这两层研究的参与者清晰地分离开。
3.1 基础层创新的“专属俱乐部”
基础层创新,指的是对基础模型本身进行构建和改进的研究。这部分工作是整个生态的根基,也是对算力需求最高的部分。
表2:不同类型研究的算力需求与主导者
从上表可以看出,高算力消耗的预训练、大规模对齐和系统级创新,基本被工业界和少数顶级学术机构所垄断。这些机构掌握了定义下一代模型架构和能力的话语权。
3.2 小团队的“被迫”转向
对于算力资源有限的广大研究团队,他们的选择空间变得非常狭窄。他们很难再参与到基础模型的构建中,而被迫转向“轻量化”的研究方向。
研究方向:主要集中在对现有模型(特别是开源模型)进行轻量级微调、能力分析、安全性评估或下游应用探索。
创新模式:从“创造工具”转向“使用工具”。
这种转向虽然在短期内也能产出大量有价值的成果,但从长远看,它削弱了整个学术生态的源头创新能力。当绝大多数研究者都无法触及模型底层时,整个领域的思想多样性和技术路径的探索都会受到限制。
💠 四、开源模型的双刃剑,学术界的“算力折中方案”
面对高昂的算力成本和商业模型的API费用,学术界找到了一个重要的“避风港”——开源模型。
4.1 开源模型成为学界主流
MIT的研究明确指出,在学术研究中,开源模型的使用率远超闭源模型。特别是Meta的LLaMA系列,已成为事实上的学术研究“标准基座”。
开源模型受欢迎的原因非常直接。
成本效益:权重和源码公开,允许本地部署和修改。这为研究者省去了高昂的API调用费用,也避免了从零训练的天文数字成本。
高度可定制性:研究者可以深入模型内部,进行结构修改、算法实验,这是调用闭源API无法实现的。对于追求方法创新的学术研究,这一点至关重要。
可复现性与社区生态:开源促进了研究结果的可验证性。围绕主流开源模型,Hugging Face等社区已经形成了完善的工具链、数据集和评估基准,极大地降低了新团队的入门难度。
可以说,开源模型是当前维系学术界在基础模型领域研究活力的“生命线”。它为资源受限的团队提供了一个参与游戏的机会。
4.2 潜在的“多样性压缩”风险
然而,对少数几个开源基座的过度依赖,也带来了一个隐忧,即模型与方法多样性的潜在压缩。
研究路径趋同:当绝大多数研究都基于LLaMA或其变体展开时,大家思考问题的起点和技术路线容易变得相似。对非Transformer架构或其他创新路径的探索可能会减少。
“基座”的隐性束缚:开源模型的架构、预训练数据和内在偏见,会潜移默化地影响后续研究的方向和结论。整个学术界可能在不经意间被少数几个模型的设计哲学所“框定”。
开源模型是学术界在当前算力格局下的理性选择,是一种务实的“算力折中方案”。但我们也必须警惕它可能带来的“思想收敛”效应,并积极鼓励对更多样化模型架构的探索。
💠 五、算力与影响力的非线性关系解构
%20拷贝.jpg)
一个普遍的认知是,投入越多的算力,产出的论文就越有影响力。MIT的研究对此进行了更精细的量化分析,结论是,这种关系存在,但并非简单的线性正比。
5.1 TFLOPS与学术成功的正相关性
研究发现,使用单纯的GPU数量作为衡量指标时,其与论文产出的相关性并不稳定。但当使用TFLOPS(每秒万亿次浮点运算,一个更精确的计算能力指标)来衡量时,相关性变得清晰。
顶会接收率:拥有更高TFLOPS计算能力的项目,其论文被顶级会议接收的概率平均更高。大规模、系统性的实验结果更容易说服审稿人。
论文引用数:高算力支持下产出的成果,通常因为模型规模更大、效果更好或解决了更复杂的问题,更容易获得同行的关注和引用。
这证实了算力确实是通往学术影响力的重要资源。
5.2 边际效应递减与分布高度重叠
然而,算力并非万能。研究团队通过对比ICLR会议(少数公开拒稿信息的顶会)的接收和拒绝论文数据,发现了两个关键现象。
边际效应递减:当算力投入超过某一门槛后,继续增加资源对提升论文质量和影响力的边际效益会迅速下降。此时,研究问题的原创性、方法的创新性和实验设计的巧妙性,成为更关键的决定因素。
分布高度重叠:被接收和被拒绝论文的算力使用分布存在大面积的重叠区。这意味着,大量高算力投入的论文同样会被拒绝,而不少低算力投入的论文也能成功发表。
这个发现至关重要。它告诉我们,算力在基础模型研究中,更像是一个必要条件,而非充分条件。它能为你提供一张参与竞争的“门票”,但无法保证你最终胜出。高质量的思考与创新,依然是学术研究的灵魂。
💠 六、被遮蔽的冰山,算力报告的系统性失真
在进行上述分析时,研究团队遇到了一个巨大的障碍,即论文中算力报告的严重不透明。我们看到的,可能只是冰山一角。
6.1 惊人的信息缺失率
绝大多数论文都没有充分、标准地披露其计算资源消耗。
仅**16.8%**的论文报告了使用的GPU数量。
仅**24.7%**的论文提及了GPU型号和显存信息。
仅**12.86%**的论文报告了推理时间。
这种普遍的信息缺失,使得对研究的真实成本、资源效率和可复现性的评估变得极为困难。整个领域仿佛在一种“盲人摸象”的状态下运行。
6.2 系统性的低估偏差
更严重的问题是,即使是报告了信息的论文,其数据也存在系统性的低估。
研究团队通过直接调研论文作者发现,近一半(46.4%)的作者承认,他们实际使用的GPU数量显著高于论文中报告的数量。
这种低估偏差的来源主要在于,研究者通常只报告“成功实验”所消耗的资源。而在科研过程中占据大量资源和时间的调试、试错和失败实验的成本,几乎完全被忽略了。这些“沉没成本”才是研究真实门槛的关键部分,但它们在学术发表中却成了隐形的存在。
6.3 制度设计的有效性
一个积极的发现是,制度设计可以有效改善这一问题。研究表明,那些在作者指南和评审流程中明确要求报告计算资源的会议(如采用ACL滚动评审系统的会议),其论文的资源报告透明度明显更高。
这说明,通过建立强制性的、标准化的报告规范,完全有可能提升整个领域的透明度,让外界能够更准确地评估不同研究方法的“性价比”和真实门槛。
💠 七、结构性风险,算力鸿沟的深层负面效应
%20拷贝.jpg)
算力鸿沟带来的影响,远不止是论文发表数量的变化。它正在对整个AI学术生态的健康度、创新活力和未来发展构成深层次的结构性风险。
7.1 创新多样性的侵蚀
当议题设置权和前沿探索能力高度集中于少数机构时,整个领域的创新路径可能会变得狭窄。
商业目标驱动:科技巨头的研究方向不可避免地会受到其商业战略的影响,倾向于能够快速产品化、巩固市场地位的技术路径。
路径依赖凸显:成功的模型架构(如Transformer)会形成强大的路径依赖,使得对其他“非主流”但可能具有突破性潜力的架构的探索资源减少。
“边缘创新”空间受挤压:许多重大的科学突破源于资源有限但思想独特的“边缘创新者”。算力门槛的提高,正在系统性地剥夺这些团队进行实验验证的机会,可能导致许多潜在的颠覆性创新被扼杀在摇篮里。
最终,我们可能得到一个技术上看似不断进步,但思想上却日益“同质化”的AI领域。
7.2 人才培养的结构性掣肘
算力鸿沟正在制造新一代研究者的“结构性劣势”。
实践机会缺失:对于博士生和青年学者,无法参与大规模实验,意味着他们无法获得现代AI研究所需的核心工程能力和系统级思维训练。他们的知识体系可能停留在理论和“轻量化”实验层面。
职业发展受限:缺乏处理大规模模型和系统的经验,会直接影响他们在工业界和顶级学术界的竞争力,形成一种从教育阶段就开始的职业天花板。
人才流向固化:优秀的人才为了获得更好的研究资源,会加速向少数“超级节点”流动,进一步加剧了人才分布的不均衡,使得“长尾机构”更难发展。
7.3 学术“马太效应”的恶性循环
算力鸿沟是学术“马太效应”的强力放大器,正在形成一个难以打破的正反馈循环。
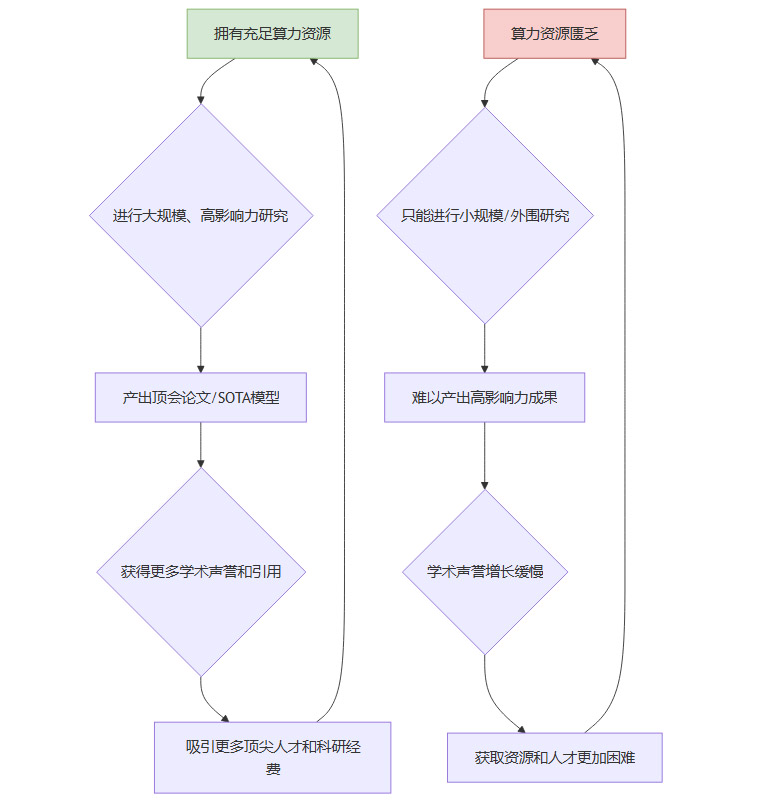
图2:“马太效应”在算力鸿沟下的正负反馈循环
这个循环一旦形成,优势机构的领先地位会不断自我强化,而弱势团队则可能陷入持续的边缘化困境,最终导致整个学术生态的“分化”与“固化”。
7.4 全球科研格局的极化
在国际层面,“美中双极”主导的格局,正在损害全球理论与创新生态的多样性。
话语权垄断:技术标准、研究议程和未来发展方向,越来越多地由这两个国家的少数几个机构所定义。
技术依赖:其他国家的研究者更多地被排挤到对现有基础模型进行本地化和应用层开发的角色,难以在核心技术层面形成自主能力。
全球合作失衡:新兴国家和弱势团队在全球AI治理和技术合作中的话语权被进一步削弱,加剧了全球范围内的数字鸿 podido。
💠 八、破局之路,寻求技术与制度的再平衡
面对日益严峻的算力鸿沟,坐视不管将导致创新生态的枯萎。学术界、产业界和政策制定者需要共同行动,从技术、制度和文化等多个层面寻求再平衡。
8.1 公共算力平台与普惠政策
这是最直接、也最关键的应对路径。
建设国家级共享算力平台:效仿建设国家级实验室和大型科学装置的模式,构建面向全社会开放的公共算力基础设施。这应该像公共图书馆一样,成为科研的基础保障。
建立公平的资源分配机制:平台的资源分配不应简单地“价高者得”。应建立以同行评议为基础的申请和审批机制,确保创新想法的质量而非申请机构的背景成为决定性因素。同时,需要为高风险、非共识的探索性项目预留通道。
实施定向扶持政策:针对资源匮乏的高校、中小机构和青年学者,设立专门的算力资助计划或“算力券”,降低他们的参与门槛,避免公共资源被“大机构包场”。
8.2 算力高效利用的技术创新
在“开源”的同时,更要“节流”。大力发展算力高效(Compute-Efficient)技术,是另一条重要路径。
推广高效训练与微调技术:持续投入研发并推广参数高效微调(PEFT,如LoRA)、模型压缩、量化、知识蒸馏等技术。让研究者用更少的资源,实现接近全量训练的效果。
鼓励“绿色AI”设计理念:在学术评价体系中,除了关注模型的性能指标(Accuracy),也应引入对资源消耗(FLOPs、能耗)的考量。鼓励研究者设计出在同等性能下资源效率更高的模型和算法。
发展新的计算范式:探索超越Transformer和密集计算的新模型架构,如状态空间模型(Mamba)、混合专家模型(MoE)的稀疏化应用等,从根本上降低计算复杂度。
8.3 资源使用报告的标准化与透明化
没有度量,就无法管理。提升透明度是解决问题的前提。
强制性报告标准:顶级会议和期刊应联合推行标准化的算力与能耗报告模板,要求所有提交的论文必须详细披露硬件配置、总计算时长(包括失败实验)、关键操作的FLOPs等信息。
自动化解析与评估工具:开发能够自动从论文或代码库中提取和分析资源消耗信息的工具,为审稿人和整个社区提供客观的“性价比”参考。
将资源效率纳入评价:在论文评审和学术奖励中,将“资源效率”作为一个正面评价维度,奖励那些用巧妙方法实现“以小博大”的研究。
8.4 产学合作新机制的探索
产业界掌握着最大的算力资源,构建健康的产学合作关系至关重要。
开放云平台访问计划:鼓励科技公司向学术界提供更多的免费或低成本云算力额度,并简化申请流程。
维护学术独立性:在合作中,必须建立明确的规则,保障研究者的学术自由、数据隐私和成果发表的独立性,避免学术研究沦为企业的“外包项目”。
探索数据与模型信托:建立中立的第三方机构来托管大规模数据集和基础模型,以更公平的方式向学术界开放访问,平衡商业利益与公共科研需求。
结论
MIT的这项研究以翔实的数据,为我们敲响了警钟。AI基础模型领域的“算力鸿沟”,并非一个遥远的未来风险,而是正在发生的、深刻重塑我们创新生态的现实。它正在将算力从一种研究工具,异化为一种划分阶级、决定命运的学术权力。
少数“超级机构”正在掌控基础模型的创新命脉,这不仅直接影响论文产出和学术话语权,更从根本上威胁着创新多样性、人才培养的公平性和全球科研生态的平衡。
未来的AI创新,究竟是走向一个由少数巨头主导、路径趋同的封闭花园,还是一个由多元力量共建、思想涌现的开放雨林,很大程度上取决于我们今天如何面对和弥合“算力鸿沟”这一核心挑战。推动算力普惠、技术节流和制度透明,是确保AI技术能够真正服务于全人类智慧共同体的必由之路。
📢💻 【省心锐评】
算力正从研究工具异化为学术权力,技术普惠的理想面临结构性挑战。若不加以制衡,AI的未来可能只属于少数玩家。

评论