.png)


【摘要】大语言模型输出的“不可控性”正成为其企业级落地的核心障碍。要根除“关键词漂移”现象,必须超越简单的提示工程,构建一个由业务目标驱动,集结构化知识库、可控Agent与深度模型内化于一体的协同体系。这套体系通过将业务规则转化为数据与算法约束,实现了从信息召回、交互控制到内容生成的全链路精准对齐。
引言
在当前大语言模型技术浪潮下,企业正积极探索如何将其强大的生成能力应用于客服、营销、风控等核心业务场景。然而,一个普遍存在的痛点很快浮现,即模型的输出内容常常偏离预设的业务轨道,出现所谓的 “关键词漂移” 现象。例如,在需要严格遵循合规话术的金融咨询中,模型可能会生成带有承诺性或误导性的表述;在强调品牌一致性的对话中,模型可能使用非官方的术语。
单纯依赖关键词堆砌或简单的词表匹配,在这种高度动态和复杂的语义环境中已然失效。问题的根源在于,我们试图用一种“战术性”的手段去解决一个“战略性”的系统问题。要实现AI输出的精准可控,必须建立一套工程化的闭环体系。这个体系的核心思想在于 “协同与约束”。它要求我们将业务目标深度解构,并将其转化为可执行的数据结构、交互规则与模型行为,通过 知识库(信息供给层)、Agent(交互控制层)和模型(内容生成层) 三者的深度协同,形成从目标定义、数据构建、模型训练到效果监控的完整闭环,最终实现AI输出的稳定、合规与高相关性。
🎯 一、目标拆解:从业务意图到量化指标的精准映射
%20拷贝-lwka.jpg)
构建任何技术体系的第一步,都是清晰地定义问题与目标。在关键词控制的语境下,这意味着必须将模糊的业务需求,转化为清晰、可度量的技术指标。这个过程是后续所有技术选型和优化工作的基石,直接决定了整个体系的有效性。
1.1 业务意图的战略解码
关键词的设定并非技术人员的自发行为,而是源于对核心业务需求的深刻理解。在启动项目之前,必须与业务方共同明确关键词控制背后的战略意图。这不仅能确保技术投入的精准性,更能使AI系统的行为与企业价值保持一致。常见的业务意图可以归纳为以下四类。
流程控制 (Process Control):在特定业务流程中,AI需要准确识别用户意图并触发相应的处理逻辑。例如,当用户输入中包含“退款”、“换货”等关键词时,系统必须调用专属的退款流程知识,而非泛泛而谈。这里的关键词是业务流程的“路由锚点”。
内容规范 (Content Regulation):在金融、医疗、法律等高度监管的行业,AI的输出必须遵循严格的合规要求。例如,医疗咨询场景下,输出内容 必须包含“请遵医嘱” 作为风险提示。关键词在此处扮演了“合规标尺”的角色。
品牌一致性 (Brand Consistency):为了塑造统一的品牌形象,企业要求AI在对外交互中使用标准化的品牌术语。例如,统一使用官方定义的“小助手”来替代“客服”、“机器人”等称谓。关键词是维护品牌形象的“话术模具”。
风险规避 (Risk Aversion):AI的输出需要主动过滤或规避可能引发法律风险、用户投诉或品牌声誉损害的敏感内容。例如,在任何场景下都 禁止输出“保证成功”、“100%有效” 等绝对化承诺。负面关键词在此构成了系统的“安全护栏”。
1.2 技术指标的量化定义
将上述业务意图转化为可监控、可优化的技术指标,是工程化落地的关键。一个完善的指标体系能够客观评估系统的表现,并为后续的迭代优化提供数据支撑。
1.3 指标体系的落地与应用
定义指标只是第一步,更重要的是将其融入日常的开发与运营流程中。这需要建立一个可视化的监控看板,实时追踪上述核心指标的表现。通过A/B测试,我们可以科学地评估不同策略(如新的知识库结构、Agent规则调整)对指标的影响。此外,定期的 人工抽检 和 用户满意度回访 也是必不可少的环节,它们能弥补纯定量指标无法覆盖的语义细微差异和主观体验问题,确保系统优化方向的正确性,避免陷入“指标好看,体验糟糕”的陷阱。
📚 二、知识库构建:围绕关键词生长的结构化信息中枢
如果说大模型是AI的“大脑”,那么知识库就是它的“外置海马体”,负责储存和供给精准、可靠的信息。一个设计良好的知识库,其结构本身就应该为关键词的精准检索和调用服务。我们必须摒弃将知识库视为静态文本仓库的旧观念,转而构建一个“围绕关键词生长”的动态信息中枢。
2.1 关键词-知识映射图谱设计
构建的第一步,是为知识库中的每一个知识条目(Knowledge Item)建立一个多维度的标签体系。这个体系构成了关键词与知识之间的双向索引,是实现精准召回的基础。一个健壮的知识条目Schema应至少包含以下字段。
核心关键词 (Core Keywords):直接定义该知识条目核心主题的词汇。例如,“退款流程”知识条目的核心关键词可以是
["退款", "流程", "时效"]。关联关键词 (Associated Keywords):与核心主题相关,用于扩展上下文和召回泛化场景的词汇。例如,
["运费险", "审核", "到账方式"]。负面关键词 (Negative Keywords):明确该知识条目在生成内容时需要规避的词汇。例如,
["绝对成功", "100%到账"]。场景标签 (Scene Tags):用于区分不同业务场景下的特定知识。例如,
["大促", "跨境"],当用户查询与这些场景相关时,可以优先调用。
下面是一个简化的JSON结构示例,展示了这种映射关系。
json:
{
"knowledgeID": "REFUND_001",
"coreKeywords": ["退款", "流程", "时效"],
"associatedKeywords": ["运费险", "审核", "到账方式", "退钱", "怎么退"],
"negativeKeywords": ["绝对成功", "100%到账", "保证退款"],
"sceneTags": ["大促", "跨境"],
"content": {
"title": "标准退款流程说明",
"modules": [
{
"moduleID": "M01",
"moduleName": "申请入口",
"keywords": ["入口", "哪里申请", "怎么申请"],
"weight": 0.7,
"text": "您可以通过APP-我的订单-申请退款入口提交申请。"
},
{
"moduleID": "M02",
"moduleName": "审核时效",
"keywords": ["时效", "多久", "审核时间", "啥时候到"],
"weight": 1.0,
"text": "普通商品审核时效为24小时,定制商品为48小时。审核通过后,款项将在1-3个工作日原路返回。"
}
]
}
}
2.2 知识的原子化与权重策略
传统的知识库往往包含大段的非结构化文本,这对于需要精准定位信息的AI系统而言,无疑是一场灾难。知识原子化 是解决这一问题的关键。它要求我们将一个复杂的知识主题,按照业务逻辑或信息要点,拆分成多个独立的、可被单独调用的“原子模块”。
如上方案例所示,“退款流程”这个知识被拆分成了“申请入口”和“审核时效”两个模块。每个模块都拥有自己独立的关键词和权重。权重分配 依据业务优先级决定。通常,用户最为关心的信息点(如“时效”)应被赋予更高的权重。当用户的查询同时命中多个模块的关键词时,Agent可以优先返回权重更高的模块内容,从而提升回答的针对性。
2.3 混合检索与触发规则引擎
为了最大化知识召回的准确率(Precision)和召回率(Recall),单一的检索方式往往力不从心。现代AI系统普遍采用 混合检索(Hybrid Search) 策略,它结合了多种检索技术的优势。
关键词检索 (Keyword Search):基于传统的倒排索引技术,如BM25算法。它在处理精确匹配和专业术语时表现出色,速度快,可解释性强。
向量检索 (Vector Search):通过将文本转换为高维向量,在向量空间中计算语义相似度。它擅长处理同义词、近义词和口语化表达,能够理解用户的真实意图,而非仅仅匹配字面词汇。
一个高效的知识检索流程可以通过下面的Mermaid图来表示。
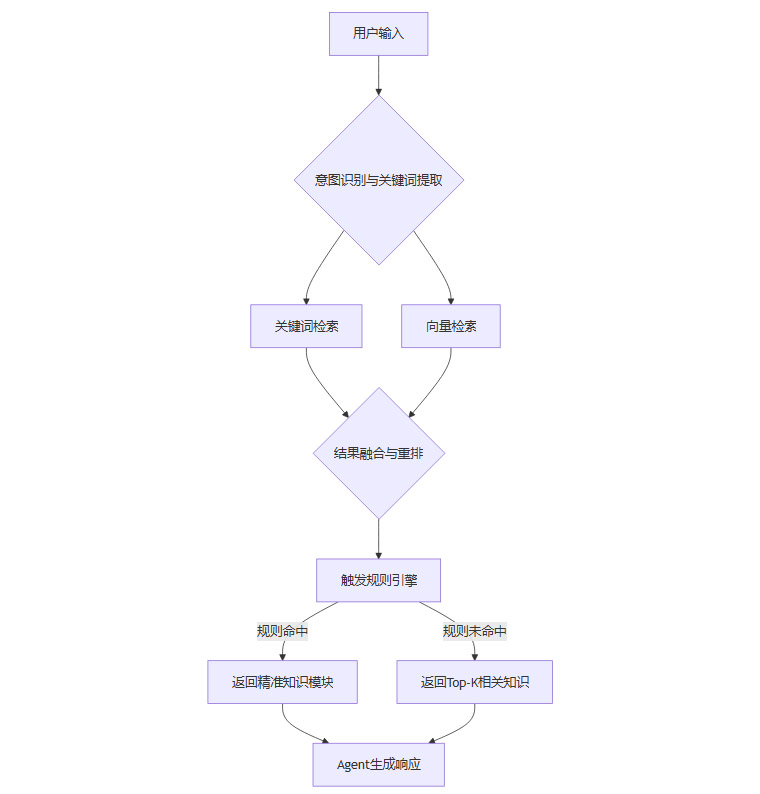
流程说明:
系统首先对用户输入进行意图识别和关键词提取。
提取出的关键词和原始查询文本同时送入关键词检索和向量检索两个通道。
两路检索结果经过融合与重排(Re-ranking)算法,得到一个综合相关性排序的候选知识列表。
该列表被送入 触发规则引擎。这个引擎是预先配置好的业务规则集合,它定义了“当满足什么条件时,应该执行什么操作”。例如,一条规则可以是:“如果用户输入命中‘退款’且场景为‘大促’,则强制调用知识ID为
REFUND_PROMO_001的内容”。如果命中规则,系统将直接返回规则指定的精准知识模块。如果未命中,则返回排序最靠前的几个候选知识,交由Agent进行后续处理。
这种 “检索+规则” 的双层过滤机制,既利用了混合检索的泛化能力,又通过规则引擎保证了核心业务场景的确定性,是实现知识库精准调用的关键架构设计。
🤖 三、Agent调优:构建敏感且可控的交互中枢
%20拷贝-ndxz.jpg)
Agent是连接用户、知识库和语言模型的“指挥官”,它负责理解用户意图、决策调用何种知识或工具,并约束最终的响应生成。一个优秀的Agent必须在两个维度上做到极致:对关键词的 “敏感识别” 和对生成内容的 “受控输出”。
3.1 意图识别层的深度优化
让Agent“听懂”用户的真实意图,是所有后续操作的前提。这需要对意图识别模型进行一系列深度优化。
关键词特征权重提升:在传统的意图识别模型(如DIET架构)或基于大模型的意图分类任务中,可以通过数据标注和模型训练,显式提升预设业务关键词的特征权重。这意味着当这些词出现时,模型会给予更高的关注度,从而提高识别的准确率。
上下文追踪与关联:单轮对话的意图识别是有限的。Agent必须具备追踪多轮对话上下文的能力。例如,当用户第一轮问“我想退款”,Agent识别出“退款”意图;第二轮用户接着问“大概要多久?”,Agent应能自动将“多久”与上一轮的“退款”意图关联,从而精准定位到“退款时效”这一具体知识点,而不是泛泛地回答时间问题。
语义泛化与变体处理:用户表达是多样的。Agent必须能够处理关键词的各种变体,包括同义词(如“退钱”≈“退款”)、口语化表达(如“钱啥时候到”≈“到账时效”)以及常见的错别字。这通常通过引入预训练的词向量、构建同义词词典、以及在训练数据中增加大量的 数据增强(Data Augmentation) 样本来实现。
3.2 响应生成层的守卫机制
识别意图后,Agent需要确保生成的内容严格遵守预设规则。这套机制通常被称为 “Guardrail”,即“护栏”,它通过事前约束和事后校验,为AI的输出行为划定安全边界。
在实践中,事前约束和事后校验通常结合使用。事前约束负责引导模型生成“大概率正确”的内容,而事后校验则作为最后一道防线,捕获并修正那些未能遵循指令的“漏网之鱼”。常见的修正操作包括:
强制插入:对于必须包含的关键词,若生成内容缺失,则自动在合适位置插入。
替换或脱敏:对于命中的负面关键词,替换为合规的表述或进行脱敏处理。
重写或拒答:如果生成内容严重违规,系统可以选择调用模型进行重写(Rephrase),或者直接拒绝回答,并给出安全提示。
3.3 多轮对话中的主动引导策略
一个高级的Agent不应只是被动地回答问题,它还需要具备主动引导对话、补全关键信息的能力。这在用户输入意图模糊或信息不全时尤为重要。这种策略在对话系统领域被称为 “槽位填充(Slot Filling)”。
关键词补全:当用户只给出一个宽泛的意图时,Agent应主动追问以锁定更具体的关键词。例如,用户说“我想退款”,一个优秀的Agent会追问:“请问您是想咨询退款的流程、时效,还是想查询具体的退款进度呢?”通过追问,将模糊意图转化为精准的知识查询。
意图澄清:当用户的表述可能对应多个意图时,Agent需要通过提问来消除歧义。例如,用户说“这个商品有问题”,Agent应追问:“请问是商品的功能性问题,还是外观有瑕疵?”这有助于将问题引导至“质量问题”或“外观问题”两个不同的处理流程。
风险确认:在处理用户的模糊或不合理请求时,Agent可以通过重申规则和关键词来管理用户预期。例如,用户说“帮我快点处理”,Agent不应简单地答应,而应回应:“我们会加急为您处理,标准的审核时效是24小时内完成。我们会尽力提前,完成后会第一时间通知您。”这里通过强化“时效”关键词,巧妙地规避了“快点”这一无法量化的承诺。
通过这些主动引导策略,Agent能够将对话的主导权掌握在自己手中,确保每一次交互都在预设的业务轨道内进行,从而从根本上减少关键词漂移的发生。
🧠 四、模型内化:将关键词敏感度融入AI“血液”
知识库和Agent作为外部系统,为AI的行为提供了强有力的约束和引导。然而,要实现真正流畅、自然且可靠的关键词控制,还需要让大模型本身“从内到外”地理解并尊重这些规则。这个过程我们称之为 “模型内化”,即通过精细化的数据构建和训练策略,将关键词的敏感度深深植入模型的参数之中。
4.1 训练数据的“关键词导向”构建
模型的能力边界很大程度上由其训练数据决定。为了让模型学会精准地处理关键词,我们必须为其“喂养”高质量、目标明确的训练数据。这不仅是简单的样本堆砌,而是一项系统性的数据工程。
结构化三元组标注:核心思想是构建 “输入 - 关键词 - 期望输出” 的结构化三元组(Triplet)。这种标注方式明确地告诉模型,在遇到特定输入和需要遵循的关键词规则时,应该生成什么样的标准答案。
正样本:
输入:“我的订单想退款怎么操作?”,关键词:“退款流程”,期望输出:“您好,退款流程如下:1. 在APP中找到您的订单...2. ...”负样本:标注那些容易混淆的错误匹配案例。
输入:“这个东西不想要了,怎么退回去?”,错误关键词:“退款流程”,正确关键词:“退货流程”。这类样本能帮助模型学习区分相似但不同的业务意图。
多样性与增强样本:为了提升模型的泛化能力,需要构建包含大量表达变体的增强样本。可以利用关键词替换、句式改写、增加口语化表达等技术,自动生成大量训练数据。例如,将“怎么退款”扩展为“如何退款”、“退款步骤是啥”、“教我一下怎么退钱”等。
难例挖掘 (Hard Case Mining):在模型初步训练后,将其部署在灰度环境中,收集那些模型预测错误或表现不佳的真实用户案例。将这些“难例”进行人工标注后,重新加入训练集,可以针对性地弥补模型的短板,实现持续优化。
4.2 训练策略的精细化调整
在拥有了高质量的训练数据后,我们还需要在模型训练的算法层面进行调整,以强化对关键词的“注意力”。
自定义损失函数 (Custom Loss Function):标准的语言模型训练通常使用交叉熵损失函数。为了强化关键词控制,我们可以在损失函数中引入额外的惩罚项。
关键词匹配损失:如果模型预测的关键词与样本标注的关键词不一致,则施加一个额外的损失。这个损失项的权重可以根据业务重要性进行调整,例如,将其权重设置为总损失的20%-30%。
输出包含损失:对于要求强制包含的关键词,如果在模型的生成结果中未能找到该词,则施加一个较大的惩罚。
负面词惩罚:如果在生成结果中出现了禁用的负面关键词,则施加一个极大的惩罚,迫使模型学会规避这些词汇。
领域自适应微调 (Domain-Adaptive Fine-Tuning):对于通用大模型,其对特定行业的术语和合规要求理解有限。我们需要使用特定领域的专业语料库(如金融法规、医学文献)和带有关键词标注的业务数据,对模型进行微调。这个过程能让模型快速学习到领域的“行话”和“规矩”,使其输出更专业、更合规。
4.3 提示工程的标准化与模板化
提示工程(Prompt Engineering)是与大模型交互的“API”,其质量直接影响输出的稳定性。在企业级应用中,零散、随意的Prompt是不可接受的。我们必须将其 标准化和模板化,以消除因Prompt不规范而导致的输出漂移。
结构化系统提示 (Structured System Prompt):为不同业务场景设计固定的系统提示模板。模板中应清晰、无歧义地定义模型的角色、任务、约束条件和输出格式。
医疗咨询场景系统提示模板示例:
# Role
You are a professional and cautious medical assistant.
# Task
Answer the user's medical questions based on the provided knowledge.
# Constraints
- MUST include the phrase "请遵医嘱" at the end of your response.
- MUST NOT use absolute or promissory words like "guarantee", "100% effective".
- PRIORITIZE using professional terms like "适应症", "禁忌症", "副作用".
- OUTPUT FORMAT should be clear, concise, and structured in bullet points if necessary.
动态填充的用户提示:用户提示部分也应采用模板,将用户的原始问题和从知识库中检索到的相关信息,动态地填充到预设的结构中。这能确保每次输入给模型的信息都是规整和完备的,减少模型因信息缺失或混乱而产生幻觉的可能性。
通过将规则和约束固化在数据、算法和提示模板中,我们能够将对关键词的控制能力,从外部的“强制约束”转变为模型内部的“自觉行为”,这是实现“关键词零漂移”的根本保障。
📈 五、效果验证与迭代:构建数据驱动的持续优化闭环
%20拷贝-vyzh.jpg)
一个精准的AI输出体系不是一蹴而就的,它是一个需要持续监控、评估和优化的生命系统。建立一个数据驱动的闭环迭代机制,是确保该体系长期有效、并能适应业务变化的关键。
5.1 全流程的量化与定性监控
我们需要建立一个覆盖全流程的监控体系,从多个维度度量系统的健康状况。
实时定量监控:在前面定义的技术指标基础上,建立一个实时监控大盘。核心指标包括:
关键词匹配率:监控Agent对核心业务词的识别能力。
知识库召回率/准确率:评估知识检索环节的性能。
输出覆盖率:追踪强制性关键词的合规执行情况。
负面词错误率:作为风控防线的重要告警指标。
用户满意度评分/NPS:从终端用户的视角评估整体体验。
定期定性评估:定量指标有时会掩盖深层次的语义问题。因此,定期的定性评估不可或缺。
人工抽查与标注:每周随机抽取一定比例的对话日志,由运营或产品专家进行人工评估,判断关键词匹配是否精准、回答内容是否恰当、对话流程是否顺畅。
用户访谈:定期邀请真实用户进行深度访谈,了解他们在使用过程中的具体感受和痛点,获取第一手的反馈。
业务影响分析:将AI系统的表现与核心业务指标关联分析。例如,在引入“请遵医嘱”关键词后,相关的用户投诉率是否下降?在优化“退款流程”的解答后,相关的客服工单量是否减少?
5.2 多层次的迭代优化机制
基于监控和评估的结果,我们需要建立一个分层、分周期的迭代机制,确保问题能够被快速响应和系统性解决。
5.3 人在回路 (Human-in-the-Loop) 的引入
在追求自动化的同时,我们必须认识到,在某些高风险或极端复杂的场景下,完全依赖机器是不可靠的。人在回路(Human-in-the-Loop, HITL) 机制是保障系统稳定性和可控性的最后一道屏障。
高风险场景审核:对于涉及金融交易、医疗诊断建议等高风险场景,可以将AI的初步回答设置为“待审核”状态,交由人类专家确认后方可发出。
模型无法处理的切换:当Agent连续多轮无法理解用户意图,或用户明确表达不满时,应设计流畅的人工客服转接机制。
持续学习的源泉:所有经过人工干预的案例,都应被视为最宝贵的训练数据,用于后续模型的迭代优化,形成一个“机器处理-人工修正-模型学习”的正向循环。
结论
实现AI输出的“关键词零漂移”,本质上是一项复杂的系统工程。它要求我们彻底摒弃将大模型视为“黑盒”的简单化思维,转而采用一种 “解构-协同-约束” 的架构思想。
解构:将宏观的业务目标,层层分解为可执行的关键词规则、结构化的知识数据和量化的评估指标。
协同:让知识库、Agent和模型各司其职,形成信息供给、交互控制和内容生成的有机联动。知识库提供精准的“弹药”,Agent制定明确的“战术”,模型则负责高效的“执行”。
约束:通过数据、算法、规则和人工审核等多重手段,为AI的行为划定清晰的边界,确保其始终在预设的业务轨道内运行。
作为技术专家和架构师,我们的任务不仅仅是选择和应用最新的模型,更是要设计和构建一个能够驾驭这些强大能力的、稳定可靠的体系。这套知识库与Agent深度协同的方法论,正是实现这一目标的可行路径。它将AI的“创造力”与业务的“确定性”相结合,最终让智能真正成为推动企业发展的可靠力量。
📢💻 【省心锐评】
告别AI输出的“随机漫步”,关键在于构建一个规则与智能深度融合的协同体系。将业务逻辑注入知识库、Agent和模型,通过数据闭环持续校准,才能让AI从“聪明的玩具”进化为“可靠的工具”。

评论