.png)
%20%E6%8B%B7%E8%B4%9D-otpa.jpg)

【摘要】DataFi通过创新的自动化做市商(AMM)机制,将动态的现实世界数据资产(RDA)转化为可定价、可交易的金融产品,为AI和量化投资构建“数据粮仓”,开启万亿级数据金融新时代。
引言
我们正站在一个新时代的门槛上。这个时代的核心资产,不再是土地、石油,甚至不是静态的数字藏品,而是我们每个人、每个组织在数字世界中留下的动态、鲜活的“足迹”——数据。长期以来,这些数据要么沉睡在孤立的服务器中,要么被平台巨头无偿利用,其巨大的经济价值从未被真正释放。
现在,情况正在改变。一个名为DataFi(Data Finance)的新赛道正在悄然崛起。它并非简单的概念炒作,而是将数据作为一种核心生产要素,与去中心化金融(DeFi)的强大引擎相结合,旨在为动态、持续更新的数据流提供前所未有的定价、交易和流动性解决方案。
想象一下,一个商圈未来24小时的人流量预测、一台工业机器人实时的运行参数、一片农田未来一周的土壤湿度变化……这些不再是孤立的信息,而是可以被封装、定价、交易的标准化资产。这就是DataFi的核心愿景。它所依赖的两大基石,一是RDA(现实世界数据资产)的确权与标准化,二是为这种全新资产量身定制的自动化做市商(AMM)定价机制。
本文将深入剖析DataFi的底层逻辑,从RDA的定义与创新,到AMM定价机制的革命性改造,再到多样化的交易模式与广阔的市场前景。我们将一同探索,当RDA这头“巨兽”遇上AMM这个“引擎”,如何共同引爆一个属于数据金融的全新纪元。
一、 💡 定义新赛道:DataFi与RDA的深度解析
%20拷贝-iyvj.jpg)
要理解DataFi,我们必须首先厘清其交易的标的物——RDA,以及它与我们熟知的RWA有何本质不同。
1.1 DataFi的诞生:从数据要素到数据金融
DataFi,即数据金融,是一个专为RDA设计的去中心化金融生态系统。它的出现并非偶然,而是数字经济发展的必然结果。当数据被正式确立为与土地、劳动力、资本、技术并列的生产要素时,一个核心问题随之而来,如何让数据这种无形的要素实现市场化的价值流转?
传统的中心化数据交易所虽然做出了一些尝试,但始终面临确权难、定价难、交易效率低、隐私保护成本高等挑战。而DeFi的出现,以其透明、无需许可、可组合的特性,为解决这些难题提供了全新的思路。
DataFi正是DeFi理念在数据要素市场的垂直应用。它利用区块链技术解决数据的确权与溯源问题,通过智能合约实现交易的自动化与可信执行,最终构建一个全球化、高效率的数据资产金融市场。
1.2 RDA的核心要义:超越RWA的“实数融合”
在DataFi的世界里,交易的不是普通的加密货币,而是RDA(Real Data Assets,现实世界数据资产)。这个概念由上海数据交易所等先行者提出,其核心是**“实数融合”**。
很多人会将RDA与RWA(Real World Assets,真实世界资产)混淆。虽然两者都致力于将链下价值引入链上,但其侧重点截然不同。
RWA 更侧重于将物理资产或传统金融资产的所有权进行通证化。例如,将一栋房产、一批黄金或一笔国债的所有权或收益权上链,其核心是资产的静态所有权。
RDA 则强调用区块链、物联网(IoT)等技术,将真实可信的运营数据流与实体资产深度绑定,形成一种全新的数字资产。RDA的灵魂在于其动态性和可验证性。
举个例子,一个光伏电站的RWA可能只是代表该电站所有权的代币。但它的RDA,则是一个封装了该电站实时发电量、光照强度、设备损耗率、电网接入状态等动态数据流的数字资产包。这些持续更新的数据,为电站的真实运营状况和未来现金流提供了透明、不可篡改的信用背书,使其价值评估从静态估算转变为动态可验证。
RDA的本质,是让数据完成了从确权、价值化到金融化的全过程。只有权属明晰、来源可溯、持续流动的数据资产,才能真正参与到资本市场的交易与证券化中。
1.3 RDA的标准化之路:从确权到交易
一个原始的数据流并不能直接成为可交易的RDA。它需要经历一个标准化的“资产化”过程。这个过程通常可以分为三个核心阶段,确保了RDA的合规性、可信性和流动性。
这个流程确保了每一份在DataFi平台上交易的RDA,都具备清晰的法律权属、可追溯的数据来源和标准化的技术接口。例如,上海数据交易所的实践就为这一流程提供了重要的参考,它推动了RDA的标准化,并为资产的发行、交易及合规提供了全方位的保障。这为DataFi在全球范围内构建募资通道和交易市场奠定了坚实的基础。
二、 ⚙️ 基础设施革命:为动态数据定价的AMM新范式
为RDA这种全新的动态资产定价,是DataFi面临的核心挑战。传统的订单簿模式效率低下,而DeFi中流行的经典AMM模型也难以胜任。因此,一场围绕AMM的“基础设施革命”势在必行。
2.1 传统AMM的局限性
自动化做市商(AMM)是DeFi的基石之一。以Uniswap V2的恒定乘积做市商(CPMM)为例,其核心公式为 x * y = k。
x和y分别代表流动性池中两种代币的数量。k是一个恒定乘积。
当交易者用代币A兑换代币B时,池中A的数量增加,B的数量减少,为了维持k的恒定,B相对于A的价格就会自动上升。这个模型简洁而优雅,非常适用于价值相对稳定的同质化代币(如USDC/ETH)。
但是,当我们将其中一种代币换成RDA时,这个模型就立刻失灵了。原因在于:
时间衰减性:数据是有时效性的。“明天天气预报”的数据,到了后天就几乎毫无价值。经典AMM无法捕捉到这种内在价值的自然衰减。
质量波动性:数据质量并非恒定。一个传感器的读数可能因为故障而失准,一个预测模型可能因为市场突变而失效。经典AMM无法区分高质量数据和低质量数据。
非同质性:即使是同类数据,其价值也可能天差地别。来自核心商圈的人流数据,显然比来自偏远郊区的数据更有商业价值。经典AMM难以处理这种内在的非同质性。
因此,DataFi平台必须对AMM进行脱胎换骨的改造,使其能够理解并量化数据的动态特性。
2.2 DataFi AMM的算法创新:引入动态因子
DataFi AMM的核心思想,是将恒定乘积公式 k 升级为一个由多个动态变量决定的函数。这个函数能够实时反映数据资产的内在价值变化。一个可能的改良版AMM公式可以表示为:
x * y = K(t, q, c, ...)
其中,K 不再是恒定的 k,而是一个动态函数,其变量至少包括:
t(时间因子)q(质量因子)c(置信度因子)
2.2.1 时间衰减函数 (Time-Decay Function)
这是最关键的创新之一。AMM需要内置一个时间衰减函数,自动降低过期数据的价格。例如,一个交易对是“某商圈未来24小时人流量预测数据”对USDC。
发布前:数据价值最高,价格处于峰值。
发布后:随着时间流逝,预测的“未来”部分越来越短,数据的不确定性降低,其价值也随之线性或非线性地下降。
到期时:数据变为历史记录,预测价值归零,其价格自动衰减至一个基础的历史数据价值。
这个过程可以通过在智能合约中嵌入一个与时间 t 相关的衰减因子 f(t) 来实现。例如,价格函数可以调整为 Price_RDA = (Pool_USDC / Pool_RDA) * f(t)。当 t 接近到期时间时,f(t) 趋近于一个很小的值,从而拉低RDA的报价。
2.2.2 数据质量与信誉系统 (Data Quality & Reputation System)
数据的质量是其价值的生命线。DataFi平台需要一个机制来验证和量化数据质量。
链上验证:通过预言机网络,将数据提供方承诺的服务水平协议(SLA)与实际提供的数据进行比对。例如,SLA承诺数据更新频率为1分钟/次,延迟低于2秒。预言机可以持续监控API,并将违约率记录在链上。
质量评分
q(t):这个违约率或其他质量指标(如数据完整性、准确性)可以被量化为一个质量分q(t)。这个分数会直接影响AMM的定价。例如,当一个数据源的质量分下降时,其在流动性池中的权重或报价会被自动调低。信誉即质押:长期提供高质量数据的数据源会积累高信誉分。这个信誉分可以作为一种无形的“质押”,使其在发行新的RDA时获得更高的初始定价和更低的抵押要求。
2.2.3 集中流动性与主动做市
借鉴Uniswap V3的集中流动性思想,DataFi的AMM可以允许流动性提供者(LP)将资金集中在数据价值最活跃的价格区间内。例如,对于一个天气预测数据,其价格在发布前后波动最大,LP可以将流动性集中在这个区间,从而极大地提升资本效率,并为交易者提供更低的滑点。
对于波动性较低、价值相对稳定的数据资产(如历史数据库的访问权),还可以引入**主动做市商(PMM)**策略。PMM可以参考外部市场的价格信息(通过预言机),更主动地调整报价,从而进一步降低无常损失和交易摩擦。
下表清晰地对比了传统AMM与DataFi AMM的差异:
通过这些革命性的改造,AMM不再是一个简单的价格发现工具,而是进化成了一个能够实时评估、量化动态数据价值的复杂定价引擎。这正是DataFi能够从概念走向现实的底层技术基石。
三、 📈 交易机制创新:RDA的多样化玩法
%20拷贝-xmdc.jpg)
在创新的AMM基础设施之上,DataFi催生了多种前沿的RDA交易模式。这些模式将无形的数据流,转化为标准化的、可交易的金融产品,让“数字足迹”的价值变现拥有了清晰的路径。
3.1 数据流NFT (StreamNFT):将数据访问权通证化
这是DataFi中最具代表性的交易模式之一。数据流NFT(StreamNFT)将一个特定时间段内的数据访问权,封装成一个非同质化代币(NFT)。
与我们熟知的代表图片或艺术品所有权的PFP(Profile Picture)NFT不同,StreamNFT的持有者拥有的不是一个静态文件,而是一个动态的“权益凭证”。这个凭证通常包含以下核心信息,并记录在NFT的元数据中:
数据源标识:指向提供数据的特定API或数据库。
数据内容描述:明确该NFT对应的数据类型,如“上海静安区未来72小时PM2.5浓度预测”。
有效期:NFT生效的开始和结束时间。
访问权限:通常是一个加密的API密钥或访问令牌,只有NFT的当前持有者才能解密和使用。
服务水平协议(SLA):定义了数据提供方应满足的质量标准,如更新频率、数据精度、在线率等。
3.1.1 StreamNFT的生命周期
一个StreamNFT的生命周期清晰而完整,完全由智能合约自动执行,无需人工干预。
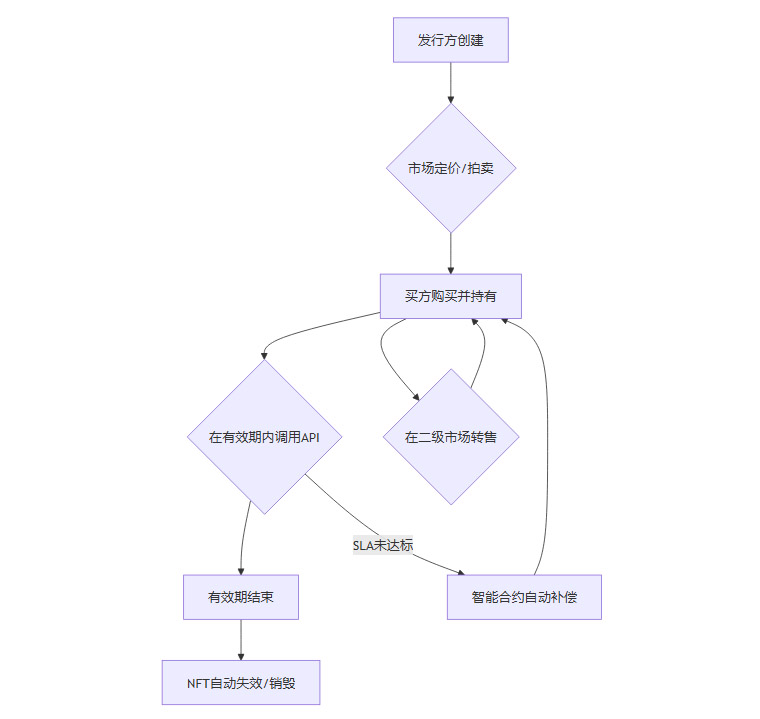
创建与发行:数据提供方(如一家气象科技公司)通过DataFi平台的工厂合约,定义好数据流的各项参数(内容、有效期、SLA),铸造出一个StreamNFT。
一级市场销售:这个新铸造的NFT可以在一级市场上通过拍卖、固定价格或结合AMM曲线进行销售。一个量化基金或农业保险公司可能会购买这个NFT。
持有与使用:买方成为NFT的持有者后,可以通过连接自己的钱包,解密并获取API访问权限。在NFT的有效期内,他们可以持续调用该API,获取实时数据流用于其业务模型。
二级市场流转:如果持有者发现自己不再需要这份数据,或者数据的市场价格上涨,他们可以随时在OpenSea等兼容的NFT市场上将这个StreamNFT转售给下一个需要它的人。NFT的价格会受到剩余有效期、市场需求以及数据源信誉等多种因素的影响。
到期与结算:一旦到达预设的结束时间,智能合约会自动将该NFT标记为“已过期”。其绑定的API访问权限也会随之失效。
SLA保障:如果在有效期内,预言机检测到数据提供方未能满足SLA承诺(例如,数据中断超过约定时间),智能合约可以被触发,自动执行惩罚条款,例如向NFT持有者退还部分费用,或扣除数据提供方的质押金。这为数据消费者提供了强有力的保障。
StreamNFT模式的巧妙之处在于,它将非标准、持续变化的数据使用权,成功地标准化、通证化了。这使得数据的使用权像股票或债券一样,可以在全球金融市场上自由、高效地流通。
3.2 数据池 (Data Pool):聚合的力量
如果说StreamNFT是为特定、高质量的数据流设计的“精品店”模式,那么数据池(Data Pool)就是汇集海量同类数据的“大卖场”。
数据池的概念类似于DeFi中的流动性池(Liquidity Pool)。它允许无数个数据提供者,将他们拥有的同类型数据汇集到一个大的池子里。数据使用者则无需单独与每个提供者签约,只需向数据池支付费用,即可访问整个池子里的聚合数据。
3.2.1 数据池的运作机制
以一个“全国主要城市交通流量数据池”为例:
数据供给方:来自北京、上海、深圳等不同城市的地图服务商、网约车公司、甚至拥有大量车辆的物流企业,都可以将他们脱敏后的交通流量数据,按照统一的格式标准,注入到这个数据池中。
流动性提供(LP):数据提供者在注入数据的同时,也成为了该池的流动性提供者。他们会获得代表其贡献份额的LP代币。
数据使用方:一个需要进行全国性市场分析的零售品牌,或一个开发智能出行APP的初创公司,可以向该数据池支付一笔费用(例如用USDC)。
访问与付费:支付后,他们获得一个API访问权限,可以查询池中任何一个城市、任何时间段的交通流量数据。这种模式被称为**“访问即付费”(Pay-per-Call)或订阅制**。
收益分配:数据池获得的所有收入,会根据一定的规则,分配给所有的LP代币持有者。这个分配规则通常是动态的,不仅仅看数据量,更要看数据的质量、被调用的频率、以及数据的稀缺性。
3.2.2 动态权重的创新
简单的数据池可能按数据量来分配收益,但这会激励垃圾数据的产生。更高级的数据池会采用类似Balancer协议的多资产权重池模型。
在这种模型中,每个数据源(例如,来自北京的数据和来自上海的数据)被视为池中的一种“资产”。它们的权重不是固定的50/50,而是动态调整的。
质量权重:通过预言机验证,质量更高、更稳定的数据源会获得更高的权重。
需求权重:被用户调用次数更多的数据源,其权重也会相应提升。
稀缺性权重:来自三线城市的数据虽然调用量少,但因为供给稀缺,也可能获得一个特殊的权重加成,以激励数据多样性。
这种动态权重机制,使得数据池成为了一个自我优化的生态系统。它能自动筛选出高质量、高需求的数据,并给予提供者最公平的回报,从而解决了传统数据市场中“劣币驱逐良币”的难题。
3.3 数据资产证券化与融资:释放沉睡的价值
DataFi的想象力不止于数据交易本身,它还为数据资产的金融化开辟了广阔空间。企业和个人可以将他们拥有的数据资产打包,进行证券化融资。
数据驱动的ABS(资产支持证券):一家连锁餐饮企业,可以将其过去三年的门店客流量、翻台率、外卖订单数据打包成一个RDA。这份RDA清晰地反映了企业的经营健康度和未来现金流。基于这份可信的RDA,企业可以发行资产支持证券(ABS)进行融资,其融资成本可能远低于传统的信用贷款。
数据质押借贷:一个拥有大量高质量用户行为数据的互联网公司,可以在DataFi协议中质押其数据资产(以StreamNFT或数据池LP代币的形式),借出稳定币用于业务发展。数据的价值和质量直接决定了其借贷额度(LTV, Loan-to-Value)。
个人数据变现:在严格遵守隐私保护法规(如GDPR)和采用隐私计算技术(如零知识证明)的前提下,个人未来也可以选择性地将自己的匿名化数据(如消费习惯、出行模式)授权给数据池,并从中获得持续的被动收入。这让普通人第一次有机会从自己的“数字足迹”中公平获益。
下表总结了这三种核心交易模式的特点与适用场景:
这些创新的交易机制,共同构成了DataFi丰富而立体的生态版图。它们不仅为数据的买卖双方提供了灵活高效的工具,更重要的是,它们正在构建一个全新的、以数据为核心的金融价值网络。
四、 🚀 市场前景:AI的“数据粮仓”与万亿级蓝海
DataFi的崛起,恰逢其时。它精准地切入了人工智能(AI)和量化投资两大领域对高质量数据需求的爆发点,其潜在市场规模远超人们的想象。
4.1 成为AI大模型的“数据粮仓”
当前,人工智能的发展正面临一个严峻的瓶颈——高质量训练数据的枯竭。各大科技公司已经几乎“榨干”了互联网上公开可用的文本和图像数据。模型的性能提升,越来越依赖于那些未被充分利用的、存在于各行各业的专有数据和真实世界数据。
DataFi恰好能成为解决这一问题的“数据粮仓”。
程序化、合规的数据获取:AI公司不再需要通过繁琐的商务谈判,一家一家地去获取数据授权。它们可以通过DataFi市场,以程序化的方式,大规模、合规地购买或订阅来自全球各地的、经过确权的RDA。无论是用于训练自动驾驶模型的交通摄像头数据流,还是用于训练医疗诊断模型的匿名化医疗影像数据,都可以在这里找到。
激励高质量数据的产生:DataFi的定价机制,天然地奖励高质量、经过精确标注的数据。这将激励更多专业机构和个人参与到数据标注和清洗的工作中来,为AI模型提供更优质的“养料”。
实时数据用于模型推理:AI的应用不只在训练阶段。在推理(应用)阶段,AI模型同样需要实时的外部数据来做出精准判断。例如,一个智能投顾模型,需要实时获取市场新闻、社交媒体情绪、宏观经济指标等数据流。DataFi的StreamNFT和数据池,正是为这种实时数据消费场景量身打造的。
可以预见,未来的AI巨头,其核心竞争力不仅在于算法和算力,更在于其通过DataFi网络获取和整合高质量数据的能力。
4.2 赋能量化基金的“阿尔法”源泉
在金融投资领域,信息优势即是“阿尔法”(超额收益)的来源。传统的量化基金主要依赖股票的量价数据、公司财报等公开信息。然而,随着市场越来越有效,这些传统因子的超额收益正在逐渐衰减。
因此,越来越多的量化基金开始转向另类数据(Alternative Data),试图在别人看不到的地方挖掘投资机会。这些另类数据包括:
卫星图像数据(用于监测港口货物吞吐量、停车场车辆数量)
信用卡交易数据(用于预测零售企业销售额)
社交媒体情绪数据(用于判断市场热点和风险)
供应链与物流数据(用于评估企业生产经营状况)
目前,另类数据的获取和交易仍然是一个效率低下、高度不透明的市场。而DataFi将为另类数据的交易带来革命性的改变。
量化基金可以通过DataFi平台,像交易股票一样,方便地购买和订阅各种另类数据RDA。一个交易策略可能不再是简单的“如果A股票价格上涨,则买入B股票”,而是“如果监测到某港口的铁矿石库存RDA下降,同时某钢铁厂的电力消耗RDA上升,则买入该钢铁厂的股票”。
这种基于多维、实时RDA的量化策略,将比传统策略拥有更高的维度和更强的时效性,从而更容易捕获到市场的非有效性,获得持续的阿尔法。
4.3 市场规模的估算:超越传统DeFi
DataFi的市场规模是巨大的,因为它所锚定的,是整个数字经济的核心——数据要素市场。
中国市场:根据上海数据交易所的预测,仅中国RDA市场的规模,到2025年就有望突破600亿元人民币。这还仅仅是早期阶段的估算。
全球市场:放眼全球,数据要素市场的规模更为庞大。更重要的是,DataFi作为金融基础设施,其价值不仅在于数据交易本身,还在于其衍生的金融服务。作为参考,全球稳定币市场的规模预计到2030年将达到2.8万亿美元。DataFi作为RWA的一个重要分支和延伸,其所承载的资产价值和交易量,完全有潜力达到甚至超过这一量级。
传统的DeFi,其业务主要围绕加密原生资产展开,总锁仓价值(TVL)在高峰期也仅为千亿美元级别。而DataFi所面向的,是数以万亿计的、由实体经济活动产生的真实数据资产。因此,从长远来看,DataFi的市场规模有望数倍于,甚至数十倍于传统的DeFi。它将成为数字经济时代真正的底层金融基础设施和创新引擎。
五、 🛡️ 风险与治理:护航DataFi的稳健发展
%20拷贝-pquu.jpg)
任何新兴的金融市场都伴随着风险。DataFi作为一个融合了数据、金融与前沿技术的交叉领域,其面临的挑战同样复杂。一个健全的治理框架是其走向成熟的必要条件。
5.1 核心风险识别
DataFi的风险可以归纳为三大类:
5.2 治理与解决方案
针对上述风险,一个成熟的DataFi平台需要构建多层次的治理和风控体系。
经济风险治理:
采用高级AMM模型:如上文提到的,引入集中流动性、主动做市商(PMM)、动态费率等机制,最大限度地降低无常损失和滑点。
引入TWAP预言机:使用时间加权平均价格(TWAP)作为价格参考,增加价格操纵的难度和成本。
设置库容管理:对某些高风险或低流动性的数据池设置存款上限,防止因单一资产风险过大而影响整个协议。
数据与合规治理:
严格的资产准入流程:在RDA发行前,要求提供方提交完整的数据确权证明、合规审查报告和法律意见书。
集成隐私计算技术:强制要求涉及个人信息的数据,必须通过零知识证明(ZKP)、联邦学习(FL)或可信执行环境(TEE)等技术进行处理,确保“数据可用不可见”。
建立链上审计与追踪:每一笔数据的来源、处理和交易记录都清晰地记录在区块链上,形成不可篡改的审计轨迹,便于监管和问责。
技术与安全治理:
多方代码审计:智能合约在上线前,必须经过多家顶尖安全公司的独立审计。
去中心化预言机网络:采用Chainlink等多节点、去中心化的预言机服务,并结合多个数据源进行交叉验证,防止单点故障或被操纵。
防抢跑机制:研究和部署抗MEV(矿工可提取价值)的解决方案,如采用批量交易、加密内存池等技术,确保交易的公平性。
社区治理(DAO):将协议的关键参数(如费率、支持的资产类型、风险参数等)的决策权,交给持有治理代币的社区成员,通过去中心化自治组织(DAO)进行投票决定,确保协议的长期发展符合社区的共同利益。
通过这一系列严谨的风险管理和治理措施,DataFi才能在创新的同时,建立起用户的信任,吸引主流机构的参与,最终从一个前沿实验,成长为一个稳健、可靠的全球性金融市场。
结论
我们正处在一个数据价值爆发的黎明。DataFi通过将RDA(现实世界数据资产)与创新的AMM机制相结合,为我们描绘了一幅激动人心的蓝图。在这个蓝图中,动态、鲜活的数据流不再是沉睡的资产,而是可以被精确、公允地定价,并在全球市场上自由流动的金融产品。
从为AI大模型提供源源不断的“数据粮仓”,到赋能量化基金挖掘新的“阿尔法”源泉,再到让每个企业和个人都有机会从自己的“数字足迹”中获益,DataFi所开启的,是一个真正由数据驱动的金融新范式。
当然,前方的道路并非一帆风顺。技术上的挑战、合规上的模糊地带、以及市场早期的风险,都需要我们以审慎而开放的态度去面对和解决。但无论如何,将数据要素进行市场化、金融化的历史潮流已不可阻挡。
DataFi,正是顺应这一潮流而生的关键基础设施。它不仅仅是DeFi的又一个新故事,更是数字经济与实体经济深度融合的催化剂。欢迎来到DataFi时代,一个你的“数字足迹”真正拥有价值的时代。
📢💻 【省心锐评】
DataFi不是空中楼阁,它是数据要素市场化的终极形态。谁掌握了为动态数据定价的能力,谁就掌握了下一代数字经济的“央行”印钞权。

评论