.png)
%20%E6%8B%B7%E8%B4%9D-fgae.jpg)

【摘要】剖析AI量化交易的技术内核,系统阐述机器学习、深度学习、NLP与强化学习等模型在策略构建、风险控制及“黑箱”可解释性工程中的具体应用与实践挑战。
引言
人工智能(AI)量化交易,常被外界视为一个神秘的“黑箱”。它并非简单的自动化交易脚本,而是一个高度复杂的系统性工程。这个系统融合了数据科学、计算机科学与现代金融理论,旨在通过算法模型自主地从海量、多维、高噪声的金融数据中提取有效信号,并将其转化为精准的投资决策。其“黑箱”属性,并非源于故弄玄虚,而是根植于其技术内核的复杂性。
首先,模型内在映射的复杂性是第一层壁垒。无论是深度神经网络还是复杂的集成模型,其从输入特征到输出信号的转化过程涉及数以亿计的参数,这种非线性映射关系难以用直观的经济学逻辑完全解释。其次,多层事务的耦合加剧了追溯难度。一个原始信号在进入实际交易前,会经历风险模型调整、交易成本约束、投资组合优化等多重变换,使得最终决策的源头难以精确归因。最后,金融数据自身的特性,如非平稳性与高信噪比,使得模型的验证与回测面临巨大挑战,历史上的成功不代表未来的必然复现。本文旨在穿透这层迷雾,系统性地拆解驱动AI量化交易的核心技术栈,并探讨应对“黑箱”挑战的工程化路径。
一、💡 AI量化交易的系统性工程全景
%20拷贝-kvcm.jpg)
一个成熟的AI量化交易系统,其运作流程远超单一模型的预测。它是一个闭环的、数据驱动的决策流程,涵盖从数据获取到最终执行与反馈的每一个环节。理解这个全景是剖析其核心技术的基础。
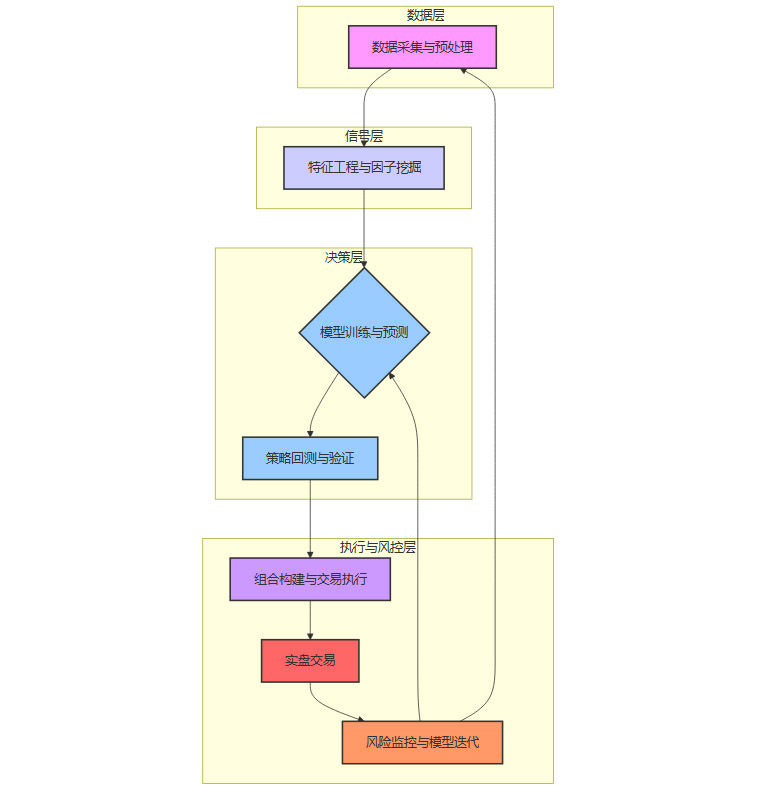
1.1 数据采集与预处理
这是所有量化分析的起点。数据源的广度与质量直接决定了策略的上限。数据类型包括但不限于:
结构化数据:股票、期货、期权等的历史价量数据(OHLCV)、高频快照数据、宏观经济指标、公司财务报表、分析师预测等。
非结构化数据:新闻公告、研究报告、社交媒体讨论、网络搜索热度、卫星图像等。
预处理是确保数据质量的关键步骤,涉及数据清洗(处理缺失值、异常值)、数据对齐(确保不同来源数据在时间戳上同步)、数据标准化(消除量纲影响)以及特征派生等。
1.2 特征工程与因子挖掘
特征工程是将原始数据转化为模型可理解的输入变量(即“因子”)的过程。在量化交易中,这通常被称为因子挖掘。传统量化依赖于基于经济学或金融学逻辑构建的因子,如价值、动量、质量等。而AI量化则更进一步,利用算法自动从高维数据中挖掘新的、有效的因子,这些因子可能不具备直观的经济学解释,但具备统计上的预测能力。
1.3 模型训练与预测
这是AI量化交易的核心环节。研究员会选择或设计合适的算法模型,利用历史数据进行训练。模型的任务多种多样,可能包括:
方向预测:预测未来一段时间资产价格的涨跌。
收益率预测:预测未来收益率的具体数值。
波动率预测:预测未来价格的波动幅度,用于风险管理。
事件预测:预测如财报超预期、违约等特定事件的发生概率。
1.4 策略回测与验证
模型训练完成后,必须在历史数据上进行严格的回测(Backtesting),以评估其历史表现。这是一个至关重要的环节,旨在检验策略的夏普比率、最大回撤、年化收益等关键指标。为避免过拟合(Overfitting),必须采用严谨的验证方法,如样本外测试(Out-of-Sample Testing)和前向展开分析(Walk-Forward Analysis),确保策略在未见过的数据上依然稳健。
1.5 组合构建与交易执行
单个资产的预测信号需要通过投资组合优化(Portfolio Optimization)技术,整合成一个实际可执行的投资组合。这个过程需要平衡预期收益与风险,同时考虑交易成本、流动性限制、持仓约束等现实因素。生成交易指令后,由**交易执行系统(Execution System)**负责以最优的方式(如使用VWAP/TWAP算法)完成交易,减小市场冲击。
1.6 风险监控与模型迭代
策略上线后,必须进行实时的风险监控。监控内容包括持仓风险敞口、市场环境变化、模型表现衰减等。金融市场是动态变化的,没有任何一个模型可以永远有效。当监控系统发现模型漂移(Model Drift)或策略表现不达预期时,就需要触发模型迭代机制,利用最新的数据重新训练或调整模型,形成一个持续学习和优化的闭环。
二、⚙️ 核心技术栈深度剖析
%20拷贝-cvli.jpg)
AI量化交易的实现依赖于一个多层次、相互协作的技术栈。从基础的机器学习到前沿的强化学习,每种技术都在这个生态系统中扮演着不可或缺的角色。
2.1 机器学习:奠定预测与决策的基石
机器学习是整个AI量化体系的基石,为预测、分类和结构发现等任务提供了丰富的工具集。
2.1.1 监督学习:构建预测模型
监督学习是应用最广泛的一类技术,其核心思想是从带有标签的历史数据中学习一个映射函数,用以预测新数据的标签。在量化交易中,它的应用场景极为丰富。
核心任务:主要用于解决回归(预测连续值,如未来收益率)和分类(预测离散值,如涨/跌)问题。
应用场景:
Alpha因子预测:基于大量的价量、基本面、另类数据,预测个股的超额收益(Alpha)。
风险预测:预测资产的未来波动率、最大回撤或相关性矩阵,为风险管理和组合优化提供输入。
交易成本评估:根据订单大小、市场流动性等特征,预测执行交易可能产生的冲击成本。
下表总结了几类常用的监督学习模型及其在量化交易中的应用特点:
2.1.2 无监督学习:揭示数据内在结构
当数据没有明确标签时,无监督学习能够自动发现数据中隐藏的模式和结构,为策略提供独特的视角。
核心任务:主要解决聚类(将相似数据分组)和降维(减少数据复杂度)问题。
应用场景:
市场状态识别(Market Regime Identification):通过对宏观经济指标或市场价量指标进行聚类(如K-Means、高斯混合模型),可以将市场划分为不同的状态,如“牛市”、“熊市”、“震荡市”。策略可以根据不同的市场状态,动态调整其模型参数或资产配置,实现动态风险预算。
特征降维与去噪:金融数据特征维度高且存在大量噪声。利用**主成分分析(PCA)或自编码器(Autoencoder)**等技术,可以将数百个相关性较高的原始因子降维成少数几个不相关的核心因子,在保留主要信息的同时剔除噪声,提升模型的稳定性和训练效率。
异常检测:通过孤立森林(Isolation Forest)等算法,可以识别出市场中的异常交易行为或极端行情,作为风险预警信号。
2.2 深度学习:驾驭非线性与时序依赖
传统机器学习模型在处理复杂的非线性关系,尤其是金融时间序列中的长期依赖时,往往会遇到瓶颈。深度学习凭借其深层网络结构,为解决这些问题提供了强大的武器。
2.2.1 循环神经网络(RNN)家族:捕捉时间序列的脉搏
金融数据,特别是资产价格,是典型的时间序列数据,其当前状态与历史状态紧密相关。RNN及其变体是处理此类数据的利器。
长短期记忆网络(LSTM)与门控循环单元(GRU):标准RNN存在梯度消失/爆炸问题,难以学习长期依赖。LSTM通过引入输入门、遗忘门和输出门三个“门控”结构,以及一个细胞状态(Cell State),使其能够有选择地记忆和遗忘历史信息,从而有效捕捉时间序列中的长期依赖关系。GRU是LSTM的简化版本,计算效率更高,在许多任务上表现与LSTM相当。
应用实践:在量化交易中,LSTM/GRU常被用于直接预测股价序列,或作为特征提取器,将一段历史价量序列编码成一个包含时序信息的向量,再输入到下游的全连接层进行最终预测。这种**端到端(End-to-End)**的模型能够自动学习有效的时序表征,极大丰富了因子体系。
2.2.2 Transformer与注意力机制:拓展模型的视野
近年来,在自然语言处理领域大放异彩的Transformer模型也被引入金融时序分析。
核心优势:与RNN顺序处理数据不同,Transformer基于自注意力机制(Self-Attention),能够并行处理整个序列。这使其在捕捉序列中任意两个位置之间的依赖关系时,不受距离远近的影响,尤其擅长捕捉超长期的依赖和关键时间点。
应用探索:研究者们正在探索使用Transformer来融合多种不同频率的数据源(如日线数据、分钟线数据和新闻文本),通过注意力机制让模型自动学习哪些信息在当前预测任务中更为重要。
2.2.3 工程实践:构建与挑战
在工程实践中,深度学习模型的应用并非一帆风顺。
模型融合:单一模型往往有其局限性。常见的做法是将深度学习模型与传统机器学习模型进行集成(Ensemble),或构建混合模型,如LSTM+Attention,结合两者的优势。
过拟合风险:深度学习模型参数众多,极易在训练数据上过拟合,导致实盘表现远差于回测。必须采用严格的正则化手段(如Dropout、L1/L2正则化)、**早期停止(Early Stopping)**以及更复杂的交叉验证方法。
市场动态失效:金融市场的规律是会变化的(即非平稳性)。一个在过去几年表现优异的深度学习模型,可能因为市场风格的切换而突然失效。因此,持续的监控和定期的模型重训练至关重要。
2.3 自然语言处理(NLP):解锁非结构化数据的价值
金融市场的运行不仅受数字驱动,更受到新闻、政策、公告、社交媒体情绪等大量文本信息的影响。NLP技术架起了从海量文本到量化信号的桥梁,成为获取信息优势的新高地。
2.3.1 从文本到信号:NLP的技术路径
将非结构化的文本信息转化为可量化的因子,通常遵循一个标准化的技术流程。
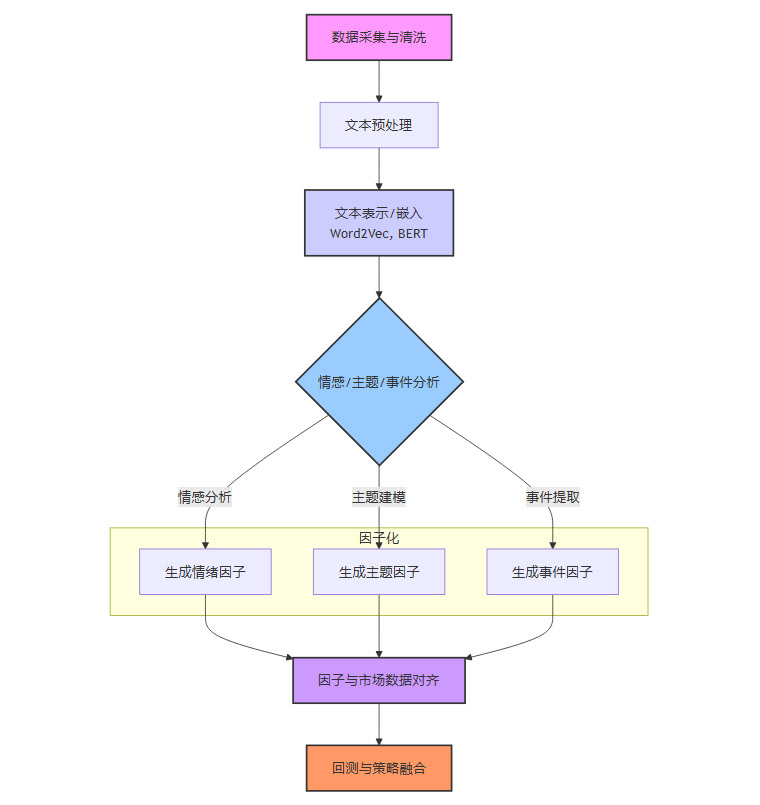
文本表示(Text Representation):将文本转换为计算机可以处理的数值向量。早期使用词袋模型(Bag-of-Words),现在主流使用基于深度学习的词嵌入(Word Embedding)技术,如Word2Vec、GloVe,以及更强大的预训练语言模型,如BERT。这些模型能够捕捉词语的语义信息。
信息提取:
情感分析(Sentiment Analysis):判断文本(如一篇新闻、一条股吧评论)的情感倾向是正面、负面还是中性,并量化为情绪得分。
主题建模(Topic Modeling):识别文本讨论的核心主题,如“加息”、“贸易战”、“行业监管”等。
命名实体识别(Named Entity Recognition):识别文本中提到的公司、人物、地点等关键实体。
事件提取(Event Extraction):抽取结构化的事件信息,如“A公司宣布收购B公司”。
2.3.2 大语言模型(LLM)的催化作用
以GPT系列为代表的大语言模型(LLM)的出现,极大地降低了文本挖掘的门槛和成本。通过**零样本(Zero-shot)或少样本(Few-shot)**学习,LLM可以直接对文本进行情感分类、摘要生成、事件抽取等任务,而无需大量的标注数据进行模型微调,加速了文本因子的引入和迭代速度。
2.3.3 应用场景与市场特性
文本因子的价值在于其前瞻性。相比于滞后的财务数据,新闻和舆情往往能更早地反映市场预期和基本面变化。特别是在某些对政策和舆情高度敏感的市场(如A股市场),政策风向、监管动态、散户情绪等软信息因子,往往能在特定时期提供显著的超额收益。
2.4 强化学习(RL):迈向策略自优化的智能体
强化学习为量化交易提供了一种全新的范式。它不再是简单地预测未来,而是让AI模型作为一个智能体(Agent),通过与市场环境的直接交互,“学习”如何做出最优的连续决策,以实现长期累计收益的最大化。
2.4.1 RL在量化交易中的核心框架
将量化交易问题形式化为RL问题,需要定义以下核心要素:
智能体的学习过程是一个**试错(Trial-and-Error)**的过程。它在环境中执行一个动作,环境反馈给它一个新的状态和一笔奖励(或惩罚)。智能体根据这个反馈,调整其内部的策略网络,力求在未来做出能获得更高奖励的动作。
2.4.2 应用优势与现实瓶颈
优势:
端到端学习:RL可以直接学习从原始市场数据到最终交易动作的映射,无需中间的预测步骤。
动态优化:能够自适应地平衡预期收益、风险敞口、交易成本等多重目标,例如在市场波动加剧时自动降低仓位。
处理复杂约束:可以自然地将交易成本、滑点等现实约束融入到学习过程中。
瓶颈:
环境非平稳性:金融市场的高度非平稳性对RL模型的稳定性构成了巨大挑战。在历史数据上学到的最优策略,在真实市场中可能很快失效。
奖励函数设计:奖励函数的设计非常关键。简单的收益率奖励可能导致模型过度追求短期高风险交易。如何设计一个能引导模型学习长期稳健策略的奖励函数是一个难题。
样本效率低:RL通常需要大量的交互数据才能收敛,而高质量的金融数据是有限的,这使得训练过程非常耗时且对算力要求高。
由于这些挑战,目前纯粹的端到端RL策略在业界的大规模应用仍然较少。更多的是将其作为辅助优化工具,例如用于优化订单执行策略或动态调整多因子模型中的因子权重。
三、🛡️ “黑箱”的可解释性工程实践
%20拷贝-gaxa.jpg)
尽管AI模型的强大性能令人瞩目,但其“黑箱”特性始终是悬在从业者头顶的达摩克利斯之剑。一个无法理解、无法解释的模型,在面临市场极端情况时可能会做出灾难性的决策。因此,在追求模型性能的同时,构建一套完善的可解释性(Interpretability)与风险控制工程体系,是AI量化交易从实验室走向实盘的必经之路。
3.1 破解“黑箱”的根源性障碍
理解为何AI量化模型难以解释,是找到解决方案的前提。其根源主要来自以下几个方面:
特征与标签的弱经济学含义:AI模型发现的很多有效因子,往往是多个原始特征经过复杂非线性变换后的结果,其背后并没有清晰的经济学或金融学逻辑支撑。模型更多是抓住了统计相关性,而非经济因果性。
多层次信号加工的追溯困境:如前文所述,从原始因子信号到最终交易指令,中间经历了信号合成、风险中性化、组合优化等多道“加工”工序。每一道工序都可能对信号进行非线性调整,使得最终的决策难以归因到最初的某个或某几个因子上。
金融数据的高噪声与非平稳性:金融数据信噪比极低,模型学到的很可能只是特定时期内的噪声模式。同时,市场结构和规律会随时间演变,导致模型在不同时期表现迥异,增加了理解其决策逻辑的难度。
3.2 提升透明度的工程化手段
面对这些挑战,业界已经发展出一系列工程化的手段,旨在打开“黑箱”,或至少在其周围建立起坚固的“护栏”。
3.2.1 严苛的时序验证框架
这是防范模型过拟合、确保模型泛化能力的第一道防线。简单的训练集/测试集划分在时序数据上是无效的,因为这会引入未来数据泄露(Look-ahead Bias)。必须采用严格的时序交叉验证方法。
滚动回测(Rolling Backtest):设定一个固定长度的训练窗口和测试窗口。模型在第一个训练窗口上训练,在紧随其后的测试窗口上进行预测和回测。然后,将整个时间窗口向前滚动一个步长,重复此过程,直到遍历所有数据。
前向展开验证(Walk-Forward Validation):与滚动回测类似,但训练窗口是不断扩张的,即每次都用从开始到当前的所有历史数据进行训练。这种方法更符合现实中模型不断学习新数据的过程。
通过这些方法,可以更真实地模拟策略在未知市场环境中的表现,检验其稳健性。
3.2.2 模型可解释性工具(XAI)
近年来,**可解释人工智能(Explainable AI, XAI)**领域发展迅速,为理解复杂模型提供了多种工具。
特征重要性分析(Feature Importance):
Permutation Importance:通过随机打乱某一特征的取值,观察模型性能的下降程度,来判断该特征的重要性。下降越多,说明特征越重要。
SHAP (SHapley Additive exPlanations):基于博弈论中的沙普利值,SHAP能够计算出每个特征对单次预测结果的贡献值。它不仅能告诉我们哪些特征重要,还能告诉我们它们是如何影响预测结果的(正向或负向),提供了局部可解释性。
模型依赖图(Partial Dependence Plots, PDP):PDP可以展示在其他特征保持不变的情况下,目标预测值与单个或两个特征之间的边际关系。通过PDP,可以直观地看到模型学到的某个因子与预测收益率之间是线性、单调还是更复杂的关系。
敏感性分析(Sensitivity Analysis):通过对输入特征进行微小的扰动,观察模型输出的变化情况。这有助于评估模型对输入噪声的鲁棒性,以及识别哪些因子是模型决策的关键驱动因素。
3.2.3 实时风险监控与异常检测系统
模型上线后,必须建立一个全方位的实时监控系统,作为策略运行的“仪表盘”和“报警器”。
因子暴露监控:实时监控投资组合在各类风险因子(如市场、市值、行业、动量等)上的暴露程度,确保其符合预设的风险偏好。
模型漂移检测(Model Drift Detection):通过统计检验等方法,持续比较线上实时数据的分布与训练数据的分布。一旦检测到显著差异(即数据漂移),或模型预测效果持续偏离预期(即概念漂移),系统应自动报警,并触发模型重训练或人工干预流程。
极端行情压力测试:定期使用历史上的极端行情数据(如2008年金融危机、2015年市场大幅波动)对现有策略进行压力测试,评估其在黑天鹅事件下的潜在表现和最大回撤。
3.2.4 硬性约束驱动的策略层设计
与其完全依赖一个端到端的“黑箱”,更稳健的做法是在策略层面加入人工设计的、基于领域知识的硬性约束。
风险中性化:在生成最终信号前,通过线性回归等方法,剔除因子中与市场、行业等已知风险因子相关的部分,确保策略收益主要来源于独特的Alpha,而非承担系统性风险。
组合优化约束:在构建投资组合时,加入明确的约束条件,如行业偏离度上限、个股持仓权重上限、换手率限制等。这些约束可以有效防止模型做出过于激进或集中的投资决策,即使其内部逻辑出现偏差。
通过这种“AI模型+人工规则”相结合的混合模式,可以在享受AI强大信号挖掘能力的同时,将其行为限制在一个安全、可控的范围内。
结论
AI量化交易的“黑箱”,并非一个不可逾越的障碍,而是一个由多层技术栈精密构建、数据驱动的智能决策系统。其核心驱动力源于机器学习对基础预测任务的支撑,深度学习对复杂非线性与时序模式的驾驭,自然语言处理对海量文本信息的价值解锁,以及强化学习对策略自优化的前沿探索。这些技术的融合,使得量化交易能够从更高维度、更广来源、更深层次的信息中挖掘市场规律,实现传统方法难以企及的精准与动态。
然而,技术的进步始终伴随着对风险控制与可解释性的更高要求。成功的AI量化实践,不仅在于构建性能卓越的预测模型,更在于建立一套严苛的验证流程、透明的可解释性工具和稳健的风险监控体系。这要求从业者既要拥抱“黑箱”带来的强大能力,也要始终对其保持敬畏,通过精细化的工程手段为其戴上“紧箍咒”。
未来,随着大模型、多模态技术与智能体理论的持续突破,AI量化交易的智能化水平与风险管控能力必将迈上新的台阶。但其成功的本质,依然离不开对市场深刻理解、技术边界认知和严谨工程实践这“三位一体”的精细把控。
📢💻 【省心锐评】
AI量化交易的核心是技术与风控的共舞。它用算法穿透数据迷雾,以工程约束驾驭模型“黑箱”,最终实现的是在不确定性市场中,对概率优势的系统性、纪律性捕捉。

评论