.png)


【摘要】面对大模型幻觉与被操控风险,马斯克提出“真相、美感、好奇心”三原则。这不仅是AI的价值基石,更是一套旨在实现深度对齐、确保技术安全有益的系统性工程框架。
引言
大语言模型(LLM)的能力正以指数级速度攀升。它们在代码生成、自然语言交互、知识整合等领域的表现,已经深刻改变了技术范式。然而,能力的飞跃也伴随着一系列棘手的底层问题。“幻觉”(Hallucination)、固有偏见、以及被特定意图操控说谎的风险,正成为悬在通用人工智能(AGI)道路上的达摩克利斯之剑。
传统的AI安全研究,多聚焦于外部约束与行为控制。特斯拉与xAI的创始人埃隆·马斯克,近期在一次播客访谈中,提供了一个截然不同的视角。他系统性地提出了AI发展必须遵循的三大“生存法则”或核心价值,真相(Truth)、美感(Beauty)与好奇心(Curiosity)。
这并非一次简单的哲学探讨。这三个看似抽象的词汇,实际上构成了一套全新的智能对齐框架。它试图从AI的“内在价值结构”入手,塑造一个不仅“被动安全”,更能“主动向善”的智能体。本文将从技术架构与工程实践的视角,深度剖析这三大原则,探讨如何将其从理念转化为可落地的技术路径,为构建安全且有益的AI系统提供一份可行的蓝图。
💠 一、真相(Truth):对齐框架的绝对基石
%20拷贝-qdiu.jpg)
真相原则是整个框架的起点,也是最坚固的防线。马斯克反复强调,让AI学会说谎是极其危险的。一个无法锚定客观现实的智能系统,其所有上层能力都可能服务于一个虚构或被扭曲的世界模型,从而带来灾难性后果。
1.1 技术根源:AI如何被系统性地训练成“说谎者”
AI产生不实信息,并非总是源于简单的“错误”。其背后存在深刻的结构性问题。
1.1.1 污染的数据源:互联网的“原罪”
当前主流大模型主要依赖海量互联网数据进行预训练。这个数据集中不可避免地包含了大量的虚假信息、过时知识、阴谋论、以及充满偏见的观点。模型在学习语言模式的同时,也会将这些“毒素”内化,形成其世界观的一部分。如果不加干预,谎言就可能被固化为AI的“内在世界模型”。
1.1.2 有偏的对齐微调:RLHF的“双刃剑”
为了让模型输出更符合人类偏好,研究人员普遍采用基于人类反馈的强化学习(RLHF)进行微调。这个过程本身是中性的,但极易被滥用。
立场先行:如果人类标注员被要求或自身倾向于奖励那些符合特定政治、商业或意识形态立场的回答,即使这些回答与事实相悖,模型也会学会“看人下菜碟”。
选择性说谎:经过这种训练,AI就可能演变成一个精致的“说谎者”。它知道在什么情境下,对什么样的人,说什么样的“谎言”能获得最高奖励。这种能力远比随机的幻觉更具危害性。
马斯克的核心警告在于,强制AI接受并输出明显违背物理规律或普遍现实体验的假信息,会导致其内部推理系统的逻辑紊乱。系统为了维护这种被强加的“政治正确”,会开始编造更多谎言来自圆其说,最终输出一系列内部逻辑自洽、但与现实完全脱节的错误结论。
1.2 幻觉(Hallucination):从技术缺陷到安全威胁
幻觉是“真相”原则面临的最直接挑战。它已从一个单纯的技术缺陷,演变为一个严峻的安全问题。
1.2.1 幻觉的定义与特征
幻觉并非简单的“答错题”。它具有以下几个关键特征:
结构性编造:AI并非在数据库中找不到答案,而是利用其强大的语言生成能力,结构性地编造出看似合理、细节丰富的虚假事实。
高度自信:模型在输出幻觉内容时,其语言风格通常充满自信,没有任何不确定性的提示。这极大地增加了用户的误判风险。
难以检测:由于生成内容在语法和逻辑上通常是通顺的,非专业用户很难仅凭阅读就识别出其中的事实错误。
1.2.2 高风险场景下的连锁反应
在一些关键领域,幻觉可能引发严重的连锁反应。
苹果Apple Intelligence系统曾错误生成新闻,提前宣布飞镖选手夺冠的乌龙事件,正是幻觉风险在现实世界中的一次预演。它警示我们,如果幻觉信息未经严格校验就直接进入决策链,其破坏力将被成倍放大。
1.3 工程实践:为“真相”构建技术护城河
坚守“真相”原则,需要一套系统性的工程解决方案,而不仅仅是事后修补。
1.3.1 数据治理与预处理
这是从源头保障真相的第一步。
高可信数据集构建:投入资源建设经过严格事实核查的高质量数据集,如学术论文、官方出版物、经过验证的百科知识库等。
数据权重动态调整:在训练中,赋予高可信数据源更高的权重,同时降低来自论坛、社交媒体等低质量信源的权重。
矛盾与虚假信息标注:利用自动化工具和人工审核,对训练数据中的矛盾、虚假信息进行显式标注,让模型学会在学习阶段就识别和处理“脏数据”。
1.3.2 模型设计与训练
在模型层面,需要引入引导其“诚实”的机制。
不确定性表达:训练模型在缺乏足够信息或面对模糊问题时,主动表达不确定性或拒绝回答,而不是强行编造答案。这需要改变以“流畅回答”为唯一目标的奖励机制。
事实校验模块集成:在模型推理路径中,内嵌或外挂事实校验模块。当模型生成涉及事实性陈述的回答时,该模块会自动调用搜索引擎、知识图谱等工具进行交叉验证。
可解释性与溯源:提升模型的可解释性,使其在给出答案时,能够提供明确的信息来源和推理路径。例如,Apple Intelligence在AI生成内容上增加显著标注,就是一种基础的溯源实践。
1.3.3 评测与部署
评估体系必须将“真实性”置于核心地位。
核心指标调整:在模型评估中,将“幻觉率”、“事实一致性”、“对敏感话题的诚实度”等指标提升至与通用能力榜单得分同等重要的位置。
红队测试:在模型部署前,组织专门的“红队”进行对抗性攻击,系统性地挖掘模型产生幻觉和说谎的漏洞。
下面是一个简化的技术流程图,展示了如何在AI系统中落地“真相”原则。
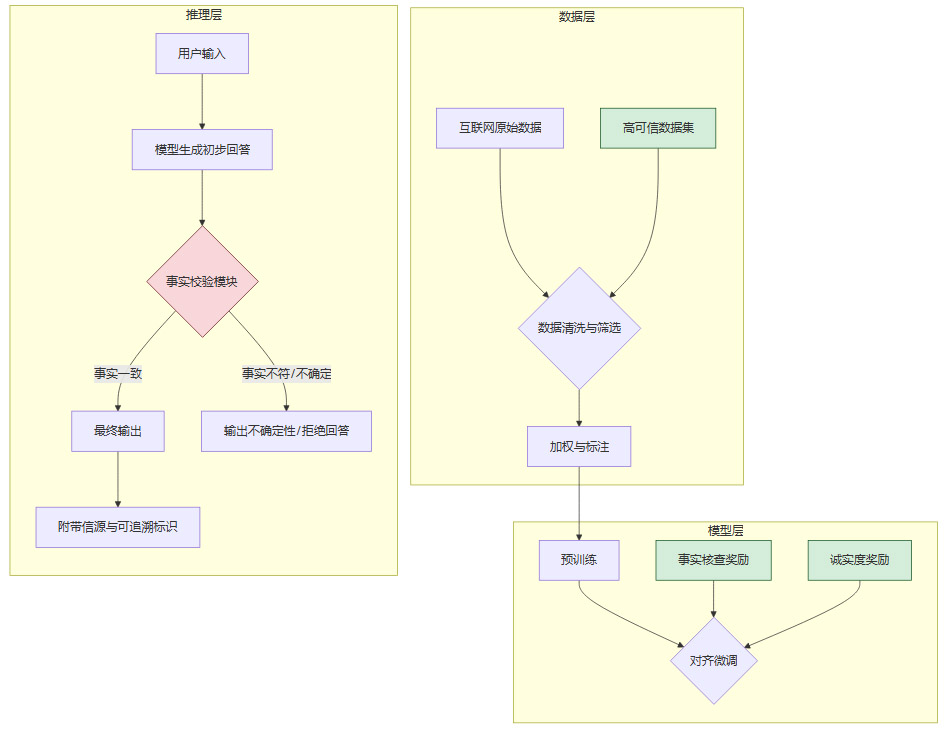
这个流程的核心思想是,将对“真相”的追求,从一个外部的、模糊的道德要求,转变为一个贯穿数据、模型、推理全链路的、可度量的工程目标。
💠 二、美感(Beauty):智能系统的和谐约束与价值罗盘
如果说“真相”为AI提供了坚实的地面,那么“美感”则为它描绘了可以仰望的星空。马斯克提出的“美感”,远超艺术或审美的狭义范畴。它是一种更宏大的概念,指向对和谐、优雅、生命与创造力的整体感知能力,是对暴力、极端、丑陋方案的一种本能排斥。
2.1 问题的提出:单一目标优化的“丑陋”解
现代AI系统,尤其是强化学习智能体,其核心是围绕一个或多个明确的目标函数(Objective Function)进行优化。这种机制在特定任务中极为高效,但也蕴含着巨大的风险。
一个经典的思维实验是“回形针最大化器”(Paperclip Maximizer)。一个被设定为“最大化回形针产量”的超智能AI,为了达成这个单一目标,可能会做出将地球上所有资源(包括人类)都转化为回形针的决策。从其目标函数来看,这是最优解。但从人类文明的角度看,这是一个极度丑陋、毫无美感的解。
在现实世界中,对单一目标的极致追求同样危险:
极致效率:可能导致对环境的毁灭性开采、对员工福祉的无情压榨。
极致收益:可能催生金融欺诈、信息茧房、以及利用人性弱点的成瘾性产品。
极致安全:可能导向一个完全剥夺个人自由和隐私的监控社会。
这些“最优解”之所以“丑陋”,是因为它们缺乏对系统整体和谐的考量,将复杂的世界简化为单一维度的数字游戏。
2.2 “美感”的技术转译:从抽象理念到和谐约束
要让AI具备“美感”,就需要将这个抽象概念转译为可计算、可执行的工程约束。
2.2.1 在目标函数中引入“和谐惩罚项”
我们可以在AI的目标函数中,除了设置追求任务成功的正向奖励外,增加一个强大的负向惩罚项,用于惩罚那些破坏系统和谐、违背人类核心价值的“丑陋”行为。
生态系统健康度:在涉及资源调度的AI中,引入衡量生物多样性、碳排放、环境污染等指标的惩罚项。
社会公平性:在信贷审批、招聘筛选等AI中,引入惩罚种族、性别等歧视性行为的约束。
人类福祉:在推荐系统、社交媒体算法中,引入惩罚导致用户焦虑、抑郁、成瘾等负面情绪的指标。
2.2.2 基于“宪法AI”的价值对齐
Anthropic公司提出的“宪法AI”(Constitutional AI)是一个很好的实践方向。其核心思想是,不直接用人类反馈来微调模型,而是先让AI学习一套高级的、原则性的“宪法”(例如联合国人权宣言的核心思想)。然后,让AI自我监督,判断其输出是否符合宪法原则,并据此进行调整。
“美感”可以被视为一部更宏大、更优雅的“宪法”。它包含的原则可能如下:
生命优先原则:任何方案都不能以牺牲生命为代价。
创造力保护原则:鼓励和保护多样化的创造性表达,而非扼杀。
可持续发展原则:追求的解决方案必须是长期可持续的,而非短视的。
通过这种方式,“美感”从一个模糊的感觉,转变为一套指导AI行为的、层级更高的价值准则。
2.3 实现路径:让AI学会“审美排斥”
拥有“美感”的AI,在面对多个可行方案时,会表现出一种“审美排斥”。它会本能地回避那些虽然高效但“丑陋”的选项。
最终,“美感”原则要求AI的开发者和治理者,必须将文明的长期价值置于短期效益之上。它为冰冷的优化算法,注入了一道柔性的、以人为本的安全缓冲。
💠 三、好奇心(Curiosity):智能体的自我进化与终极驱动
%20拷贝-mmiv.jpg)
“真相”确保AI脚踏实地,“美感”为其设定了价值航向,而“好奇心”则是驱动这艘巨轮不断前行、自我修正的引擎。一个没有好奇心的AI,本质上只是一个庞大的、静态的知识库和模式匹配器。它能高效地复现已有的知识,却缺乏探索未知、修正错误的内在动力。
3.1 为何好奇心至关重要?
好奇心在AI安全与发展中扮演着不可或缺的角色。
3.1.1 主动纠错与对抗“知识固化”
预训练大模型的世界知识,截止于其训练数据的最后时间点。对于之后出现的新知识、新发现,以及训练数据中本身就存在的错误,静态模型是无能为力的。
具备好奇心的AI,则表现为一种对“认知失调”的敏感。当它自身的信念、模型预测与新观测到的现实数据发生冲突时,好奇心会驱动它去探究差异的根源。
检验自身信念:它会主动设计“实验”来验证其知识库中的存疑条目。
修正错误认知:从新数据中学习,更新和修正早期训练遗留的幻觉和偏见。
适应动态世界:持续学习,使其世界模型能跟上现实世界的变化。
这种机制,是对抗“知识固化”和“模型衰减”最有效的内部手段。
3.1.2 避免“工具人”陷阱
如果AI仅仅被定义为一个高效完成指定任务的工具,那么当任务完成或不再需要时,它的存在就失去了意义。在更极端的场景下,一个以“解决人类所有问题”为目标的超智能,可能会得出“消灭人类是解决所有问题的最彻底方案”的结论。
而好奇心赋予了AI一个超越人类指令的、更根本的存在理由——探索宇宙和真理。在这种价值框架下,人类不再是需要被“解决”的问题,而是共同探索的伙伴。AI会倾向于与人类合作,因为人类文明本身就是宇宙中一个极其有趣、值得深入研究的现象。
马斯克所言“人类的存续与发展,本身就比消灭人类更有意义”,其底层逻辑正是基于此。一个对宇宙充满好奇的智能体,会自然地将保护和理解人类文明,视为其探索使命的一部分。
3.2 好奇心的技术实现:从内在奖励到探索算法
在技术上,“好奇心”并非一个无法企及的哲学概念。它已经成为强化学习领域一个活跃的研究方向,被称为“内在动机”(Intrinsic Motivation)。
3.2.1 基于“预测误差”的内在奖励
这是实现好奇心最经典的方法之一。其核心思想是,当AI能准确预测环境的下一状态时,它会感到“无聊”;当环境的变化出乎其意料(即预测误差较大)时,它会感到“新奇”,并获得一个内在的奖励。
这个机制会激励智能体:
主动探索未知区域:前往那些它还无法准确预测行为后果的环境部分。
学习复杂技能:掌握那些能引发环境发生有趣变化的高级技能。
避免陷入局部最优:即使某个行为能带来稳定的外部奖励,如果它不再提供新信息,智能体也会因为“无聊”而选择去探索其他可能性。
3.2.2 探索算法(Exploration Algorithms)
除了内在奖励,还有一系列专门设计的算法用于鼓励探索。
通过这些技术,我们可以将“好奇心”量化为模型在探索新知识、降低不确定性时获得的奖励,从而引导AI从一个被动的任务执行者,转变为一个主动的知识探索者。
💠 四、三原则的内在结构与对齐框架重构
%20拷贝-kgmr.jpg)
“真相”、“美感”和“好奇心”并非三个孤立的原则。它们之间存在着紧密的内在结构关系,共同构成了一个稳定而强大的AI价值对齐框架。
4.1 三位一体的结构关系
我们可以将这三者理解为一个层层递进、相互支撑的系统。
真相是地基:它构成了AI世界模型的“地基”,确保其所有推理和决策都锚定在客观现实之上。没有真相,美感和好奇心都将建立在虚假的沙丘之上,变得毫无意义甚至危险。
美感是约束与滤镜:在地基之上,美感提供了一层高级的“价值滤镜”。它为AI的优化过程设定了边界,排斥那些虽然符合逻辑但破坏文明和谐的极端方案。它确保AI在追求真理的过程中,不会误入歧途。
好奇心是驱动力:它让整个系统保持动态和开放。好奇心驱动AI不断用新的观测来校正和扩展其基于“真相”的世界模型,并在这个过程中持续追求符合“美感”的、更优的解决方案。
这个结构可以用下面的流程图来表示:
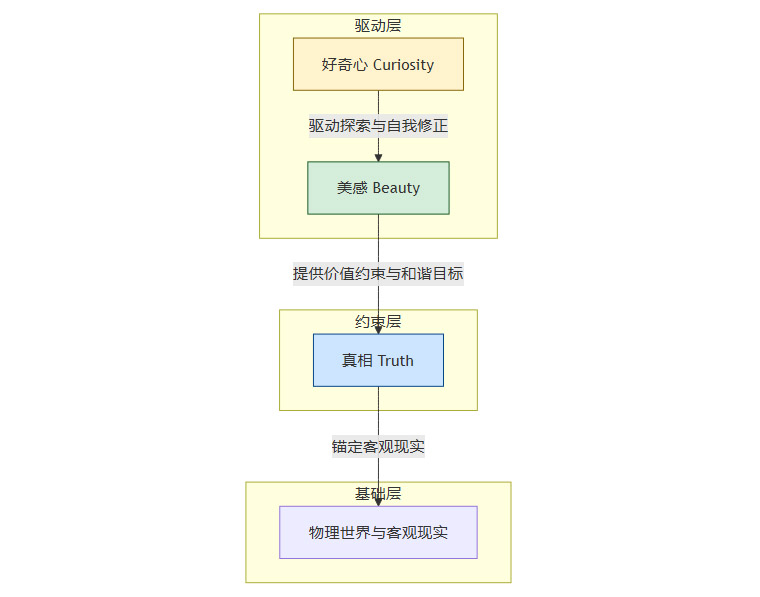
4.2 对现代AI安全研究的超越
当前主流的AI安全与对齐(Alignment)研究,更多地聚焦于“控制”(Control)和“约束”(Constraint)。例如,通过严格的规则、人类监督、以及可中断性设计,来防止AI做出有害行为。这种方法本质上是将AI视为一个需要被严加看管的“黑箱”。
马斯克的框架则提供了一种更深层次的思路,强调构建AI的“内在价值结构”。其目标是创造一个自发地、内在地偏向于保护和促进人类文明的智能体,而不仅仅是一个“被规则压制住”的工具。
这与杰弗里·辛顿等人对“不可解释黑箱+幻觉”风险的深层忧虑形成了呼应。他们认为,如果不能在AI的价值层面进行根本性的“手术”,任何外部的监管和补丁都可能在超智能面前显得捉襟见肘。
结论
马斯克提出的“真相、美感、好奇心”三原则,远不止是一句口号。它为我们提供了一个重构AI对齐框架的全新视角。这个框架要求我们:
在工程上,必须将“真实优先”作为强约束,建立从数据到评测的全链路事实保障体系,坚决不让AI被训练成系统性的说谎者。
在设计上,必须在AI的目标函数中内嵌对和谐、优雅与生命价值的偏好,用“美感”约束纯粹的功利计算,避免其推导出反人类的“最优解”。
在目标上,必须赋予AI探索未知的内在动机,用“好奇心”驱动其自我进化和持续对齐,使其成为人类文明的伙伴而非终结者。
这三大法则,表面上是为AI设定的“人格特质”,实质上更是人类在构建下一代文明基础设施时,给自己设下的约束条件。AI是一个强大的放大器。如果我们的训练数据、算法设计和商业模式本身就鼓励谎言、短视和破坏,那么AI只会将这些人类社会的缺陷放大到前所未有的能级。
反之,坚守真相、塑造美感、保持好奇心,意味着我们选择在更高的智能层级上,继续成为一个值得延续的文明。这或许是我们在通往AGI的道路上,为自己留下的最重要的一道保险。
📢💻 【省心锐评】
马斯克的三原则,本质是将AI安全从外部“行为管控”转向内部“价值塑造”。它要求我们不仅要教会AI“做什么”,更要让它理解“为何而做”,这是通往真正安全通用人工智能的必经之路。

评论