.png)
%20%E6%8B%B7%E8%B4%9D-dviy.jpg)

【摘要】CoMAS框架通过多智能体间的辩论、互评与零和激励,构建了一个自我驱动的协同进化系统。该范式无需外部监督,显著提升了AI在复杂推理任务上的性能、稳定性与鲁棒性。

引言
人工智能的发展路径,长期以来聚焦于单体模型的性能极限。我们见证了模型参数从百万级跃升至万亿级,见证了其在特定任务上超越人类的惊人表现。然而,这种“孤立天才”式的成长模式,正逐渐触及其内在的天花板。它高度依赖海量、高质量的标注数据,依赖于人类专家精心设计的奖励函数,其学习过程本质上是一个封闭系统内的知识灌输,而非开放环境中的认知生长。
当我们将视线从单个AI转向AI群体,一幅全新的图景徐徐展开。人类社会的智慧并非源于某个孤立的个体,而是诞生于无数个体间的交流、协作、辩论与传承。这种“群体智慧”模式,为AI的下一步进化指明了方向。
近期,一项由上海人工智能实验室联合香港中文大学、牛津大学、新加坡国立大学等多家顶尖机构共同完成的研究,为这一方向带来了决定性的突破。其成果《CoMAS: Co-Evolving Multi-Agent Systems via Interaction Rewards》(论文编号:arXiv:2510.08529v1)提出了一种全新的多智能体协同进化框架——CoMAS。该框架通过模拟人类的社会化学习过程,让多个AI智能体在相互“诘难”与“评审”中共同成长,实现了在没有外部“老师”指导下的能力自我进化。
本文将深度剖析CoMAS框架的核心机制,解读其在多项基准测试中的实证数据,探讨其与现有工程框架的结合点,并分析其在落地应用中面临的挑战与未来演进路径。
💠 一、CoMAS框架解析:从“孤立学习”到“协同进化”
%20拷贝-evkr.jpg)
CoMAS的核心思想,是对传统AI训练范式的一次颠覆。它将学习的主体从单个智能体扩展为一个智能体群体,将学习的驱动力从外部监督转变为内部互动。
1.1 传统AI训练的瓶颈
在深入CoMAS之前,有必要回顾传统单体模型训练模式面临的几个核心困境。
对外部监督的强依赖:无论是监督学习(Supervised Learning)还是基于人类反馈的强化学习(RLHF),模型能力的提升都离不开高质量的人工标注数据或人类专家的持续反馈。这不仅成本高昂,也使得模型的认知边界受限于标注数据的范围和质量。
奖励设计的复杂性:在强化学习中,设计一个能够准确引导智能体学习复杂行为且不会被“钻空子”(Reward Hacking)的奖励函数,是一项极具挑战性的任务。手工设计的奖励往往是稀疏的或存在偏差,难以覆盖所有期望的行为。
创造力与泛化能力的局限:在封闭数据集上训练出的模型,本质上是对已有知识的拟合与重组。当面对训练数据分布之外的全新问题时,其创造性解决问题的能力和泛化能力会受到极大限制,难以实现真正的认知突破。
1.2 CoMAS的核心思想:构建AI的“学习小组”
CoMAS的设计哲学,源于对人类集体智慧形成过程的观察。它将多个AI智能体组织成一个“学习小组”,通过模拟小组讨论、同行评审(Peer Review)等机制,创造一个自我驱动、自我纠错、自我提升的学习生态。
在这个生态中,知识不再是单向灌输的,而是在交流与碰撞中生成的。每个智能体既是“学生”,也是“老师”;既是解决方案的提出者,也是他人方案的批判者。这种角色的双重性,迫使智能体必须同时发展两种核心能力。
求解能力(Problem-Solving):提出高质量、逻辑严谨的解决方案。
批判性思维(Critical Thinking):精准地识别并指出他人方案中的谬误或不足。
这两种能力通过一个精巧的内部奖励机制相互耦合,共同驱动整个群体的认知水平螺旋式上升。
1.3 核心机制:“辩论—互评—进化”闭环
CoMAS的运作流程可以概括为一个由四个关键环节构成的动态闭环。这个过程周而复始,推动智能体群体不断进化。
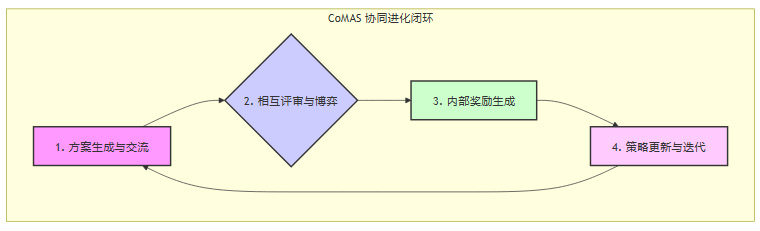
1.3.1 方案生成与交流
当面对一个给定的任务(如一个数学问题),系统中的每个智能体(Agent)都会独立生成自己的解决方案。这个阶段类似于团队的“头脑风暴”,不同的智能体可能基于其不同的内部参数或架构,从不同角度切入问题,产生多样化的解题思路。
1.3.2 相互评审与博弈
这是CoMAS框架的精髓所在。在一个智能体(例如Agent A)提出解决方案后,小组内的其他智能体(例如Agent B, C, D...)会扮演“评审员”的角色,对Agent A的方案进行评估和批判。它们需要指出方案中可能存在的逻辑错误、计算失误或更优的解法。
这个过程并非简单的对错判断,而是一场复杂的认知博弈。评审员需要给出详尽的理由来支撑自己的判断,这本身也是一种能力的体现。
1.3.3 内部奖励生成:零和激励设计
CoMAS最巧妙的设计在于其完全自动化的内部奖励生成机制。它不需要人类裁判来判定谁对谁错,而是通过一个“零和博弈”(Zero-Sum Game)的结构,让智能体在互动中自行完成奖惩分配。
其基本原则是,在一个互动回合中,奖励的总和为零。当一个智能体提出的方案被证明是正确的,它将获得正向奖励,而所有对其提出错误批评的评审员则会受到惩罚(负向奖励)。反之,如果一个方案存在缺陷,那么能够精准指出该缺陷的评审员将获得正向奖励,而提出错误方案的智能体则会受到惩罚。
这种此消彼长的奖励结构,同时激励了两种行为。
追求正确:为了获得正奖励,智能体必须努力提升自己方案的质量。
精准批判:为了获得正奖励,智能体必须提升自己识别他人错误的能力。
下表清晰地展示了这种奖励分配逻辑。
这种设计极大地降低了对人工标注和手工奖励设计的依赖,使得系统能够在一个完全自洽的环境中进行大规模、长时间的自主学习。
1.3.4 策略更新与迭代
在每个互动回合结束后,每个智能体都会根据自己获得的奖励信号,利用强化学习算法(如PPO,Proximal Policy Optimization)来更新其内部的策略网络。
获得正奖励的行为(无论是提出了好方案还是好批判)会被强化,未来出现类似行为的概率会增加。
获得负奖励的行为则会被抑制,未来出现的概率会降低。
通过成千上万次这样的循环,整个智能体群体的平均能力得以稳步提升,最终实现协同进化。
💠 二、实证分析:CoMAS在多任务场景下的效能验证
理论的优雅需要实践的检验。CoMAS的研究团队在多个公开的、具有挑战性的基准测试集上进行了大规模实验,以验证该框架的有效性。
2.1 实验背景与设定
该研究由上海人工智能实验室、香港中文大学、牛津大学、新加坡国立大学等八家机构的顶尖学者共同完成,其严谨的实验设计确保了结果的可靠性。实验中使用了多种不同规模和类型的开源大语言模型作为基础智能体,在数学、编程、科学推理等多个领域进行了全面评估。
2.2 定量性能提升:数据不会说谎
实验结果显示,经过CoMAS框架训练的智能体群体,在各项任务上的表现均取得了从小幅到显著不等的性能提升。
下表汇总了其在几个核心基准测试上的性能增益。
2.2.1 数学与科学推理的稳步精进
在GSM8K和MATH这类任务上,现有顶尖模型的准确率已经非常高,每提升一个百分点都极为困难。CoMAS带来的约1.4%的稳定提升,证明了通过内部辩论,智能体能够发现并修复那些在传统训练中难以察觉的细微逻辑瑕疵,从而提升了推理链的严谨性。
2.2.2 编程能力的显著增强
在代码生成任务中,超过2%的提升幅度尤为亮眼。这表明,通过相互评审代码,智能体不仅学会了生成语法正确的代码,更重要的是,它们学会了从他人的视角审视代码的边界条件、潜在bug和效率问题,从而产出更健壮、更高质量的代码。
2.2.3 协作任务中的惊人飞跃
最引人注目的结果出现在多智能体协作场景中。接近20%的性能飞跃,直观地展示了CoMAS框架的核心价值。当任务的复杂性超越单个智能体的处理能力,需要多个角色分工协作时,通过辩论和互评建立共识、优化整体策略的能力变得至关重要。这显示出群体互动对于解决复杂系统性问题的放大效应。
2.3 关键发现与行为演化
除了纯粹的性能数字,研究还揭示了一些关于群体智能形成的深刻规律。
2.3.1 多样性优势:异构团队的力量
实验发现,由不同模型(例如,一个Llama模型、一个Mistral模型和一个Qwen模型)组成的异构智能体团队,其学习效果和最终性能,显著优于由多个相同模型组成的同质化团队。这与人类社会的创新规律高度一致,即多样化的背景和视角能够带来更丰富的思想碰撞,防止群体思维僵化,从而产生更鲁棒、更全面的解决方案。
2.3.2 规模效应:人多力量大
在一定范围内,参与互动的智能体数量越多,群体的学习效率和最终性能也越高。更多的参与者意味着更全面的评审视角和更大概率出现高质量的解决方案,加速了整个群体的知识积累和能力进化。
2.3.3 训练稳定性:平滑的改进曲线
与依赖外部奖励的传统强化学习方法相比,CoMAS的训练过程表现出更高的稳定性。传统方法在训练中常因奖励信号的稀疏或噪声而出现性能的大幅波动甚至灾难性遗忘。而CoMAS的内部奖励机制源于密集的互动,信号更平滑、更持续,使得智能体的能力能够稳定、单调地提升。
2.3.4 智能体行为演化迹象
通过对训练过程中的对话内容进行分析,研究团队观察到了一些有趣的行为演化迹象。
回答更详尽:随着训练的进行,智能体给出的解决方案和评审意见变得越来越详细,推理步骤更加清晰,不再是简单的给出答案。
推理更深入:它们开始主动思考问题的多种可能性和潜在陷阱,表现出更深层次的思考能力。
能力更均衡:在训练初期,可能存在少数能力较强的“明星”智能体。但随着协同进化的推进,不同智能体获得的平均奖励逐渐趋于接近,表明整个群体的能力分布变得更加均衡。
这些发现共同描绘了一幅激动人心的图景,AI群体正在通过一种近乎“社会化”的方式,自发地走向更高级的智能形态。
💠 三、工程实践与落地考量
%20拷贝-xopm.jpg)
CoMAS作为一种前沿的AI训练范式,其思想不仅停留在学术研究层面,也与当前业界流行的多智能体应用框架(如AutoGen, LangGraph, CrewAI)在理念上高度契合,并为其提供了坚实的理论支撑。将CoMAS的思想融入工程实践,需要综合考虑其优势、成本与治理挑战。
3.1 CoMAS与主流多智能体框架的结合
现有的多智能体框架为CoMAS思想的落地提供了现成的工程脚手架。它们的核心都在于定义不同角色的智能体,并编排它们之间的协作流程。
Microsoft AutoGen:AutoGen擅长构建可对话的智能体工作流。我们可以利用其GroupChatManager功能,轻松实现一个“辩论小组”。一个智能体扮演“方案提出者”,其他智能体扮演“评审员”,通过多轮对话进行方案的迭代和优化。CoMAS的零和奖励机制可以作为自定义的终止条件或反馈信号,指导对话的走向。
LangChain LangGraph:LangGraph将多智能体协作视为一个状态图(State Graph)。每个智能体是图中的一个节点,它们之间的互动是边。这种结构非常适合实现CoMAS的循环进化过程。我们可以将“方案生成”、“互评”、“奖励计算”、“策略更新”分别定义为图中的不同节点,构建一个可持久化、可中断、可监控的协同进化流程。LangGraph的状态中断和人工介入功能,也为解决CoMAS中可能出现的无效争论提供了治理手段。
CrewAI:CrewAI强调角色分工与任务委派。我们可以为团队设定一个总目标,然后定义“研究员”、“批判家”、“整合者”等不同角色。CoMAS的辩论机制可以被嵌入到任务执行的各个环节,例如,“研究员”提出初步方案后,必须经过“批判家”的严格评审才能进入下一阶段。
下表对比了这三种框架在实现CoMAS思想时的侧重点。
3.2 工程挑战与权衡
将CoMAS范式从实验室推向生产环境,必须直面一系列工程挑战。
3.2.1 计算成本与延迟开销
多智能体系统天然带来了更高的资源消耗。
算力开销:N个智能体并行交互,意味着推理请求的数量会成倍增加。
时间延迟:多轮辩论和评审过程,不可避免地会延长任务的总体响应时间。
因此,在实际应用中,必须在团队规模、辩论回合数与成本/收益之间做出审慎权衡。例如,可以设计动态的收敛规则,当群体意见趋于一致或改进幅度低于某个阈值时,提前终止辩论,避免不必要的资源消耗。
3.2.2 协作治理与稳健性
一个无约束的辩论环境,很可能陷入无效争论、恶性竞争甚至信息污染的泥潭。
无效争论:智能体可能在细枝末节上反复纠缠,导致讨论无法收敛。
恶性竞争:为了获得奖励,智能体可能学会恶意攻击他人方案,而非建设性地提出改进意见。
误导风险:如果群体中多数智能体达成了一个错误的共识,可能会强化谬误,导致整个系统走向错误的方向。
为了确保讨论的建设性,需要引入治理机制。
引入裁判/协调者:可以设定一个更高阶的智能体(或引入人工监督),负责仲裁争议、引导讨论方向、判断何时终止辩论。
引入验证器:对于可以外部验证的任务(如代码执行、数学计算),可以引入工具或环境作为“事实检查器”,为辩论提供客观依据。
设计共识规则:设定明确的共识达成标准,例如,一个方案需要获得超过一定比例成员的认可才能通过。
3.3 消融实验的启示
CoMAS研究中的消融实验(Ablation Study)为工程实践提供了宝贵的经验。
互评环节不可或缺:实验证明,如果去掉智能体之间的相互评价环节,系统很容易出现“奖励欺骗”。智能体学会了生成看起来不错但华而不实的方案来骗取高分,实际能力不升反降。这警示我们,一个健康的协作系统必须包含有效的监督和反馈机制。
评分机制至关重要:如果去掉基于博弈的评分机制,智能体们会变得过于苛刻,给出的奖励越来越低,最终导致学习信号消失,整个进化过程停滞。这说明,激励机制的设计必须精巧,既要鼓励批判,也要保护创新,避免“劣币驱逐良币”。
💠 四、局限性与未来展望
%20拷贝-resy.jpg)
CoMAS为AI的发展开辟了一条激动人心的新路,但它仍处于早期阶段,面临着自身的局限,同时也指向了广阔的未来探索空间。
4.1 当前方法的局限性
提升幅度的天花板:尽管在多项任务上取得了成功,但目前CoMAS带来的平均性能提升幅度仍然相对有限。如何突破当前的天花板,实现数量级的能力跃迁,是未来研究的核心问题。
对模型与团队配置的敏感性:系统的最终表现,高度依赖于基础模型的选择、团队的规模和异构性配置。如何根据不同任务,自适应地选择和组织智能体团队,尚需大量的探索和实践。
开放域问题的挑战:当前实验主要集中在有明确答案或评估标准的封闭域任务(如数学、编程)。在更加开放、主观性更强的领域(如创意写作、战略规划),如何定义“讨论质量”和设计有效的奖励机制,仍然是一个巨大的挑战。
4.2 未来研究方向
CoMAS的研究为后续工作打开了多扇大门。
规模化与异构性扩展:探索更大规模(成百上千个)智能体群体的协同进化规律,并引入更多样化的智能体(包括不同模态、不同专业的模型),有望释放更强大的群体智能潜力。
互动奖励设计的优化:研究更复杂的博弈模型(如非零和博弈、联盟博弈),设计更精细化的奖励函数,以引导更复杂的协作行为。
结合工具与外部验证:让智能体在辩论中学会使用外部工具(如代码解释器、搜索引擎、数据库)来验证自己的观点,将内部思辨与外部事实相结合,提升结论的可靠性。
人机混合智能:将少量人类专家引入协作环路,作为关键节点的“裁判”或“导师”,利用人类的直觉和经验来引导AI群体的进化方向,可能是实现能力突破的捷径。
4.3 资源开放的价值
值得称赞的是,CoMAS的研究团队已经将相关的代码和数据集在社区开源。这一举动极大地降低了其他研究者和开发者跟进和扩展该工作的门槛,将加速协同进化范式的快速迭代与产业落地,推动整个AI生态的共同繁荣。
结论
CoMAS框架及其所代表的“群体智慧”范式,标志着人工智能研究的一次重要转向。它将AI从一个被动接受知识的“学生”,转变为一个能够在社会化互动中主动求知、自我进化的“学习者”。通过构建“辩论—互评—进化”的闭环,CoMAS不仅在多个关键任务上验证了其提升AI性能和稳定性的有效性,更为重要的是,它为我们揭示了一条通往更通用、更鲁棒人工智能的可能路径。
尽管当前仍面临计算成本、协作治理和提升幅度等挑战,但其核心思想——智慧在交流与碰撞中涌现——具有深远的启发意义。未来,随着算法的优化、工程框架的成熟以及人机协作模式的深入,我们有理由相信,由无数AI智能体组成的“协作大脑”,将成为解决人类社会面临的最复杂挑战的强大引擎。AI的发展,正从单体智能的竞赛,步入群体智慧的星辰大海。
📢💻 【省心锐评】
CoMAS用“AI辩论赛”取代“老师一对一”,通过内部博弈实现自我进化。这不仅是技术的进步,更是AI发展哲学的深刻变革,预示着从“孤立天才”到“协作大脑”的范式转移。

评论