.png)
%20%E6%8B%B7%E8%B4%9D-yqvg.jpg)

【摘要】AI Agent的规模化落地,核心在于构建可信体系。本文深入剖析可观测、可控、可进化的工程方法,为打造用户长期依赖的智能体提供系统性架构指引。
引言
AI Agent的技术竞赛,正悄然转向一个新的赛道。业界共识已经形成,单纯比拼模型参数或功能列表的时代正在过去。规模化落地的真正瓶颈,并非能力的上限,而是信任的底线。一个Agent无论多么强大,如果用户不敢在关键业务中托付于它,其价值终将归零。
我们追求的,是让Agent从一个偶尔惊艳的“魔法师”,转变为一个用户敢用、愿用、长期依赖的“智能同事”。要实现这一目标,必须建立一套体系化、可持续的信任基石。这不仅是产品理念的转变,更是对底层技术架构、交互设计与工程实践的全面重塑。本文将从可观测性、安全可控、持续进化与落地路径四个维度,系统性地拆解构建AI Agent可信体系的核心方法论。
❖ 一、信任的基石:可观测性与“白盒化”交互
%20拷贝-qttf.jpg)
信任始于理解。一个行为无法预测的“黑箱”,天然会引发人的警惕与不安。在企业级应用中,这种对结果可靠性的担忧尤为突出。超过三分之二的企业用户,将结果的可靠性置于纯粹的能力指标之上。因此,将Agent的内部运作过程透明化,是构建信任体系的第一个,也是最关键的一步。
1.1 范式迁移:从结果导向到过程导向
传统软件交互,用户关心的是结果。点击按钮,任务是否成功执行。Agent则不同,它是一个具备自主推理与决策能力的系统。用户不仅关心“它做了什么”,更关心“它为什么这么做”。这种体验重心的转移,要求我们将产品设计从结果导向彻底转向过程导向。
过程的透明度本身,就是一种核心价值。用户愿意牺牲部分即时效率,来换取对过程的掌控感和心理上的确定性。一个让用户全程“看见”其思考过程的Agent,即便偶尔犯错,也因为错误路径清晰可见而易于修正和谅解。反之,一个给出错误结果却无法解释原因的黑箱,会迅速摧毁用户的所有信任。
1.2 轨迹外显:推理与行动的可视化
要实现过程导向,就必须将Agent的“内心独白”外化。目前业界广泛采用的**ReAct (Reasoning and Acting)**框架,为我们提供了坚实的理论基础。其核心思想是在每一步行动(Action)之前,都先生成一步思考(Thought),形成一个“思考-行动-观察”的循环。
我们的任务,就是将这个内部循环,用一种清晰、直观的方式呈现给用户。
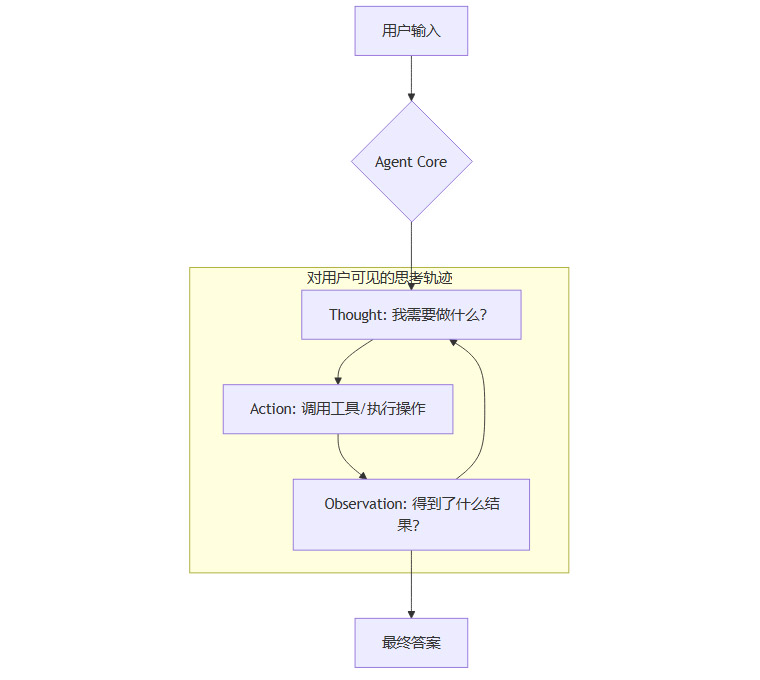
这个过程的本质,是一种认知卸载。通过外部化Agent的思考过程,用户无需费力猜测其意图,只需跟随其逻辑即可。这极大地降低了用户的心智负担,建立了初步的信任连接。
1.3 “白盒化”交互:思考原语与自然语言呈现
直接将技术日志(如"Calling function: get_weather(city='Beijing')")抛给用户是无效的。技术语言必须被翻译成用户能够理解的产品语言。为此,我们需要定义一套标准化的“思考原语”,将Agent的内部状态映射到这些人类易于理解的概念上。
表1:思考原语定义与示例
通过这套原语,Agent的每一步行动都有了清晰的语义。用户看到的不再是冰冷的代码执行,而是一个逻辑清晰、有条不紊的“智能同事”在汇报它的工作进展。
1.4 架构支撑:事件流驱动的实时交互
为了实现流畅、实时的思考轨迹呈现,后端架构需要相应的支撑。异步事件流架构是理想的选择。Agent的每一个决策节点,无论是开始思考、调用工具、获得观察结果,还是遇到错误,都应被封装成一个独立的事件,推送到消息队列中。
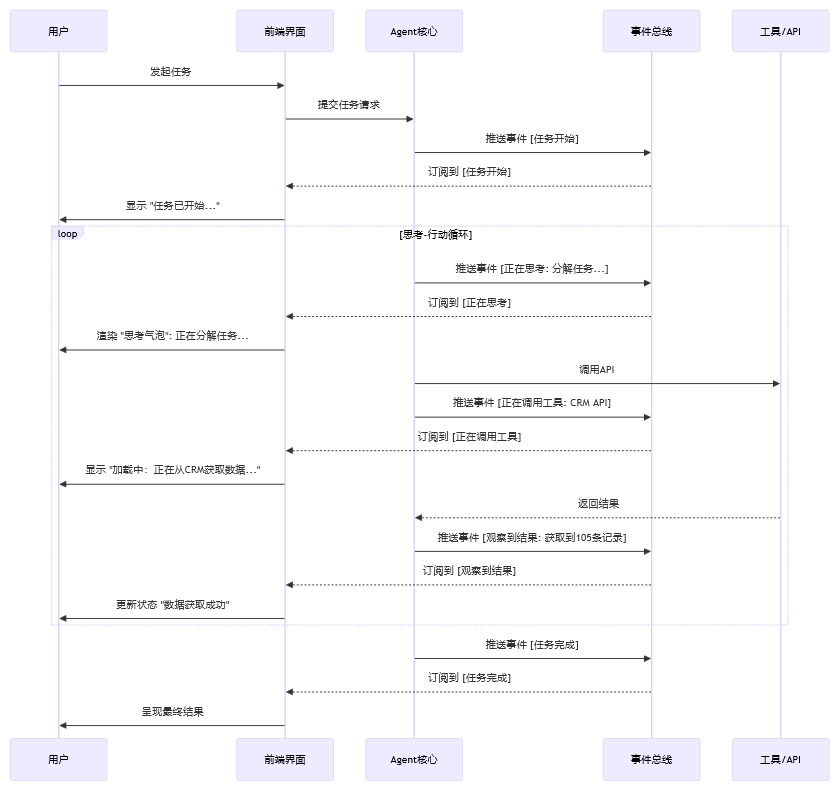
这种架构的优势在于解耦。Agent核心只负责产生事件,前端则根据订阅到的事件流,灵活地设计和渲染各种交互组件,如“思考气泡”、加载动画、错误提示、回退路径等。这为产品经理和设计师提供了极大的创作空间,以打造透明、丰富的用户体验。
1.5 协作升级:从被动观察到主动干预
可观测性的终极形态,是允许用户在关键节点进行主动干预。当Agent展示出它的执行计划时,用户应该有能力对其进行修改。
编辑计划:用户可以修改某个步骤的具体指令。
更换工具:用户可以指定Agent使用另一个更合适的工具。
调整顺序:用户可以拖拽调整任务步骤的执行顺序。
这种设计,将用户从一个被动的观察者,提升为主动的协作者。用户不再是简单地“授权”Agent工作,而是在与Agent“共同”工作。这种深度的参与感,是消除“黑箱”恐惧、建立牢固信任关系的根本途径。
❖ 二、安全的护栏:可控的执行与工程级保障
仅仅让用户“看见”是不够的,还必须让他们能“控制”。信任源于选择,而非被迫接受。在任何涉及高风险、高价值的操作中,最终的决策权必须牢牢掌握在用户手中。这是一个不可逾越的产品伦理和工程底线。
2.1 风险分层:精细化的权限管理
在设计Agent的行动能力时,必须进行严格的风险分级。不能笼统地给予Agent“读”或“写”的权限,而应将其能够执行的所有动作,按照潜在影响进行精细化分层。
表2:Agent操作风险分级模型 (ARLM)
基于这个分级模型,我们可以为不同等级的操作设计不同的授权、确认和审计机制。这为用户提供了“知情权”与“决策权”的双重保障,是构建安全护栏的第一道防线。
2.2 人机回环:优雅地嵌入确认节点
人机回环 (Human-in-the-Loop, HITL)是确保高风险操作安全的核心机制。但其实现方式需要精心设计,以避免生硬的弹窗打断用户心流。我们的目标是,将确认环节无缝地融入用户的工作流中。
上下文确认:当Agent生成邮件草稿后,不在页面中央弹窗,而是在草稿旁边提供一个清晰的“发送”按钮,并附上提示“请您审阅后点击发送”。
批量预览与确认:对于一系列批量操作(如批量修改文件名),先生成一个“变更预览”界面,清晰展示每一项操作前后的变化,让用户一键批准或拒绝。
流程内核对页:在一个复杂的业务流程(如报销)中,在提交给下一环节(如财务审批)前,生成一个包含所有关键信息的摘要确认页面,作为流程的最后一道人工关卡。
更进一步,系统应提供个性化的控制策略,允许用户根据任务风险和自身信任度,动态调整控制强度。
表3:个性化控制强度设置
用户可以为不同类型的任务预设控制级别,例如“所有涉及金额超过100元的操作,都必须由我手动确认”。这种个性化设计,让用户感觉自己是Agent的主人,而非被其支配。
2.3 工程级护栏:纵深防御体系
除了产品层面的控制,还需要坚实的工程级护栏来提供底层安全保障。这是一个纵深防御体系,确保即使在极端情况下,系统的行为依然可控。
表4:Agent核心工程护栏
这些工程护栏是Agent可信赖的基石,它们在用户看不见的地方,默默守护着系统的稳定与安全。
2.4 合规与数据治理的制度基础
在企业环境中,信任不仅是技术问题,更是合规问题。一个完善的可信体系,必须建立在严格的数据治理和合规框架之上。
PII与敏感数据隔离:在数据处理的每个环节,自动识别并脱敏个人身份信息(PII)和业务敏感数据。Agent只能在授权范围内访问和处理非敏感信息。
数据驻留与加密:严格遵守各地数据主权法规,确保用户数据存储在合规的地理位置。所有静态存储和动态传输的数据,都必须采用强加密标准。
访问控制与合规审计:基于角色(RBAC)和属性(ABAC)的访问控制模型,精细化管理谁可以在什么条件下访问Agent的何种功能。所有操作日志必须符合行业审计标准(如SOC 2, ISO 27001)。
这些制度基础,是向企业用户做出的最严肃的信任承诺。
2.5 面向失败设计
一个成熟的系统,必须承认不确定性的存在,并为失败做好准备。这在Agent系统中尤为重要。
不确定性提示:当Agent对某个问题的回答或某个计划的把握度不高时,必须坦诚地向用户展示其置信度分数,并主动提示“此信息可能不完全准确,建议您核实”。
备用方案与数据源:在核心工作流中,为关键的工具或数据源设计备用方案。当主方案失败时,Agent可以自动或在用户指导下切换到备用路径。
自检与纠错机制:Agent在执行复杂任务时,应内置检查点(Checkpoint)。在每个检查点,它会自我评估当前状态是否偏离预定目标,如果偏离,则尝试自我纠错或请求用户帮助。
这种“诚实”和“有预案”的设计,远比假装无所不能,更能赢得用户的长期信赖。
❖ 三、成长的轨迹:持续学习与系统性评估
%20拷贝-frqw.jpg)
单次表现出色,不等于长期可靠。信任不是一次性建立的,它需要通过持续的、可验证的良好表现来巩固和维系。一个今天表现完美但明天可能犯下低级错误的Agent,无法获得用户的深度信赖。因此,系统必须具备一套“自证清白”的进化机制。用户需要看到Agent在持续进步,看到自己的反馈被有效采纳,看到它变得越来越懂自己的工作模式。这种成长的可见性,是维系长期信任关系的关键。
3.1 评估体系重构:从流量到任务
传统互联网产品的评估指标,如点击率、停留时长,对于Agent产品是具有误导性的。一个频繁出错、需要用户反复纠正的Agent,其“交互时长”可能非常高,但这恰恰是失败的信号。我们必须抛弃流量思维,建立一套以任务为中心的评估体系。
表5:面向Agent的核心评估指标
我们团队曾犯过一个错误,过度关注“生成速度”,导致Agent为了求快而省略关键思考步骤,错误率不降反升。后来我们将指标权重调整为以任务达成率为核心,虽然平均响应慢了一点,但用户满意度和信任度反而显著提高。
3.2 端到端评测:捕获真实世界中的失效
单元测试和集成测试对于Agent系统是远远不够的。它们无法覆盖真实用户交互中复杂、多轮、充满变数的场景。一个工具单独测试时工作正常,但在一个长链条任务的中间环节,可能会因为上下文理解偏差而失败。
因此,必须建立端到端的会话级(或线程级)回归评测体系。
日志采集:在线上环境中,完整记录用户与Agent交互的全过程,包括用户的每一轮输入、Agent的完整思考轨迹、工具调用日志以及最终结果。
标注与用例化:将这些真实的交互日志,特别是那些典型的成功和失败案例,进行标注,转化为标准化的评测用例。
自动化回归:每当Agent的核心逻辑、模型或工具集发生变更时,自动运行这些端到端用例,对比新旧版本的表现差异。
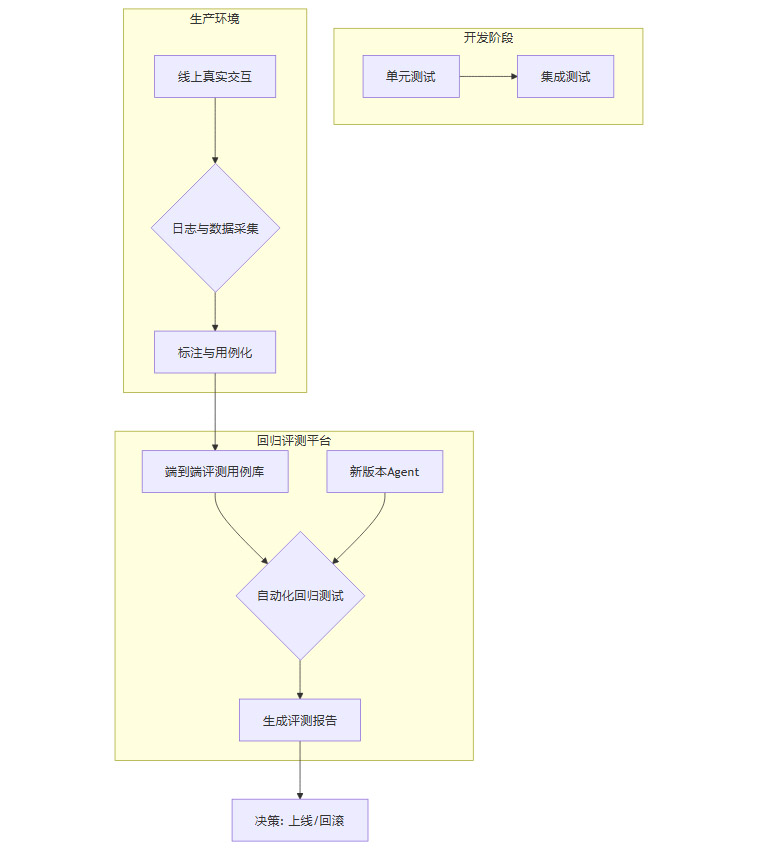
这个闭环确保了任何代码或模型的改动,都不会在真实复杂场景中引入非预期的行为衰退。它让我们能捕捉到那些在孤立测试中永远无法发现的、系统性的失效模式。
3.3 反思式学习:从结构化反馈中进化
用户的每一次“点踩”,都是一次宝贵的学习机会。但简单的“不满意”标签,信息量太低。一个好的反馈系统,应该像一个耐心的老师,引导用户给出具体、可操作的反馈。
我们的做法是,当用户表示不满意时,不直接询问“为什么”,而是将Agent当时的完整思考过程(基于思考原语)重新展示出来,并提问“您认为在哪一步出了问题?”
[目标澄清] “我理解您的目标是...” -> 用户反馈:“我的目标理解错了。”
[任务分解] “我计划分三步走...” -> 用户反馈:“第二步的计划是多余的。”
[信息收集] “我查询了A数据库...” -> 用户反馈:“数据源错了,应该查B数据库。”
这种结构化的反馈,能够精准定位问题根源。更重要的是,它能连同当时的完整交互上下文,形成一条高质量的负样本或优化指令,直接用于模型的持续微调。这正是Reflexion(反思)框架的核心思想,通过对失败案例的反思来实现自我进化。这个数据闭环,是驱动Agent能力持续成长的核心引擎。
3.4 集体智慧:模板与共享库的生态效应
Agent的成长不应只依赖于开发团队的迭代和单一用户的反馈。我们可以通过构建集体智慧的生态来加速其进化。
任务模板市场:允许用户将自己成功验证过的工作流,保存为可复用的任务模板。例如,“每周销售周报生成器”、“竞品舆情监控助手”等。
解决方案共享库:一个用户成功解决了一个复杂问题,其脱敏后的解决方案(如一系列指令、工具组合和校验规则)可以被分享给有类似需求的其他用户。
这种社区驱动的模式,能带来多重价值。
降低使用门槛:新用户可以直接复用成熟模板,快速上手。
加速信任扩散:“别人已经验证过可行”,这本身就是一种强大的信任背书。
涌现最佳实践:社区会自然筛选和沉淀出针对各类场景的最优解决方案,极大地丰富了Agent的应用生态。
这不仅能加速Agent的进化,更能形成强大的网络效应和社区粘性,构建起难以被复制的竞争壁垒。
❖ 四、渐进式落地:分阶段渗透与心智建设
%20拷贝-aisd.jpg)
信任无法一蹴而就。试图一步到位,做一个“无所不能”的通用Agent,往往会因为在关键场景的不可靠而适得其反。正确的路径是设计一条清晰的、风险可控的采纳路径,像教新手开车一样,引导用户逐步建立对Agent的认知和信任。
4.1 MVP选型原则:高频低风险先行
Agent落地的第一步,场景选择至关重要。我们应该优先选择那些高频率、低风险、结果容错性高的场景作为突破口。
可以绘制一个四象限图来辅助决策。

优先突破区(高频/低风险)是理想的起点。例如信息查询、内容摘要、会议纪要生成。在这些场景,用户可以频繁地与Agent互动,快速感知其价值,同时又不必担心因其失误造成严重后果。我们团队早期的教训就是,第一个版本就挑战客户服务,结果因理解错误导致回复不当,险些丢失重要客户。后来调整策略,从内部文档摘要工具做起,积累了足够的用户信任和行为数据后,才逐步扩展到更高风险的外部场景。
4.2 三阶段演进路线:从助手到代理者
用户需要清晰地知道Agent的能力边界和成长路径。我们可以规划一个透明的三阶段演进路线图,并将其在产品中明确展示出来。
表6:Agent能力演进三阶段
在产品中,可以设计一个“能力成长中心”,让用户看到Agent当前处于哪个阶段,已解锁哪些技能,以及下一阶段将学习什么。这种透明化的成长路径,能有效管理用户预期,极大降低用户的心理防线,让他们与Agent共同成长。
4.3 用户心智教育:贯穿始终的沟通
很多时候,用户对Agent的不信任源于期望错位。他们要么高估了Agent的能力,要么低估了正确使用它的方式。因此,用户心智教育必须贯穿整个产品体验。
Onboarding引导:在用户初次使用时,通过简短的教程,明确告知Agent擅长什么、不擅长什么,以及最佳的提问方式。
情境化提示:在复杂任务开始前,主动提示“这个任务可能需要您的多次确认”;在Agent不确定时,坦诚告知“我对这个问题的把握度不高,建议您核实”。
边界声明:在产品界面的显著位置,清晰地声明Agent的能力边界和数据使用策略。
错误解释:当Agent犯错时,除了提供反馈渠道,还应尝试解释错误可能的原因,并告知用户如何避免类似问题。
这种持续、诚实的沟通,是在帮助用户建立一个关于Agent的正确心智模型。当用户真正理解了Agent的工作原理和能力边界后,他们就能更合理地使用它,从而形成一种良性的、可持续的人机协作关系。
结论
AI Agent的竞争,最终将回归到商业的本质,即为用户创造稳定、可靠的价值。当模型能力逐渐趋同,技术本身不再是决定性的壁垒。真正的护城河,是那个通过精心设计和持续运营建立起来的用户信任体系。
这个体系,由可观测的设计、可控制的交互、可进化的系统和可预期的路径共同构成。它沉淀在产品的每一个细节里,最终内化为用户的肌肉记忆和情感依赖。作为架构师和产品构建者,我们的职责,是敢于对纯粹的技术驱动说“不”,敢于为了用户的安全感增加看似“不智能”的确认环节,敢于坦诚暴露Agent的能力边界。
这种选择短期内或许不够“酷”,但长期来看,它为产品赢得的是最宝贵的资产,用户的信任与忠诚。未来的胜负手,将不再由算法精度或模型参数决定,而是由这个更本质的维度,信任,来定义。
📢💻 【省心锐评】
Agent的未来,不在于炫技的“无所不能”,而在于可信赖的“有所不为”。工程化的信任体系,是其从玩具走向工具的唯一路径。

评论