.png)


【摘要】颠覆传统“窄-宽-窄”MLP范式,提出“宽-窄-宽”沙漏架构。通过高维固定随机投影与窄瓶颈计算,实现参数效率与模型性能的双重提升,为AI架构设计开辟了新路径。

引言
几十年来,多层感知器(MLP)的设计范式几乎固化。工程师们习惯于一种形似“漏斗”的结构,即“窄-宽-窄”模式。信息从相对狭窄的输入维度进入,在宽阔的隐藏层中进行复杂的非线性变换,最终再被压缩回狭窄的输出维度。这种设计直观且有效,构成了现代深度学习模型的基石,尤其是在前馈网络(FFN)中。
然而,看似天经地义的设计,其背后是否隐藏着未被充分挖掘的优化空间?MediaTek Research与台湾国立大学的团队对此提出了一个根本性质疑。他们反其道而行,将这个“漏斗”彻底倒置,构建了一种全新的“沙漏”(Hourglass)架构。这项工作不仅是对MLP结构的一次大胆重构,更深层次地,它挑战了我们对于神经网络中信息处理维度的基本假设。研究表明,将计算与学习置于一个人工构造的高维空间,可能比在“自然”的低维空间中更为高效。这篇发表于arXiv(2510.01796v1)的研究,为我们揭示了一条提升AI效率的新航路。
一、 架构范式重塑:从“漏斗”到“沙漏”
%20拷贝-hpan.jpg)
神经网络架构的演进,本质上是对信息流与计算资源分配方式的持续优化。沙漏MLP的核心贡献,正是对这两者关系的重新定义。
1.1 传统MLP的“窄-宽-窄”瓶颈
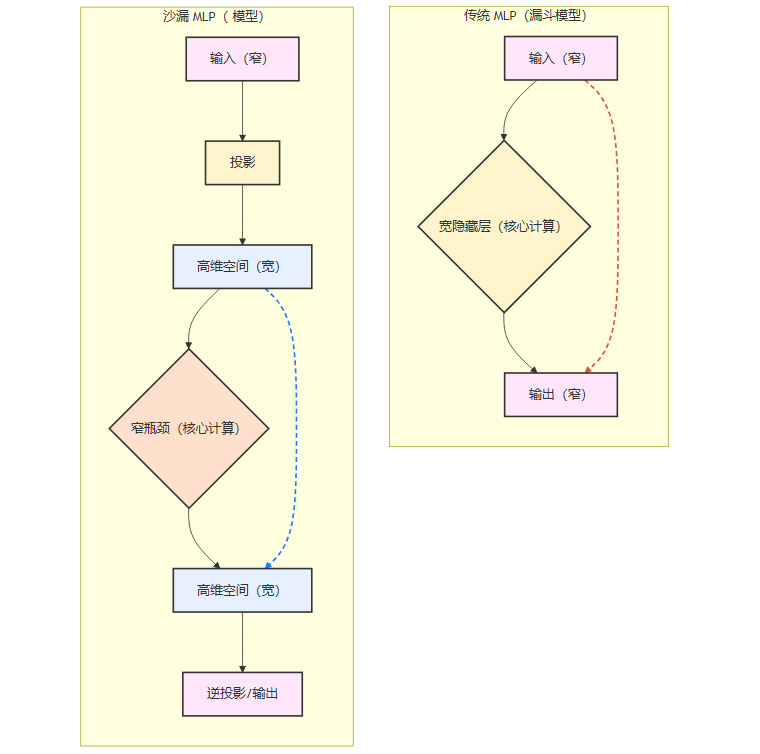
传统MLP的“窄-宽-窄”设计,可以理解为一种集中式变换模型。
信息流路径:输入数据(低维) → 扩展至宽隐藏层(高维) → 压缩至输出(低维)。
计算核心:绝大部分的参数与计算量集中在中间的宽隐藏层。模型试图在这个宽阔的空间内一次性完成从输入到输出的复杂映射。
跳跃连接的局限:在ResNet等引入残差连接的现代架构中,跳跃连接通常建立在输入与输出之间,即在两个“窄”端进行。这意味着,所有渐进式的学习与修正,都被迫在低维空间中完成。这好比一位工匠,始终被限制在一个狭小的工作台上,即使拥有再强大的工具(宽隐藏层),其操作空间也受到了根本性的制约。
这种设计的内在假设是,渐进式改进应在“自然”的数据维度上进行。但如果原始维度本身并不适合进行细微的调整,这种设计就会遇到效率瓶颈。
1.2 沙漏MLP的“宽-窄-宽”革命
沙漏MLP彻底颠覆了上述逻辑,提出一种分布式、高维修正的模型。
信息流路径:输入数据(低维) → 投影至高维空间(宽) → 通过窄瓶颈处理(窄) → 在高维空间输出(宽)。
计算核心:非线性变换的核心计算被压缩在中间的“窄瓶颈”中,而参数量较大的跳跃连接则建立在两端的“宽”空间。
高维空间的跳跃连接:这是沙漏架构的精髓。输入首先被一个投影矩阵“提升”(lift)到一个维度远高于输入输出的高维空间。所有的残差学习和渐进式改进都在这个宽广的空间中进行。这相当于把原材料先搬入一个巨大的工厂车间,在这里进行精细打磨和微调,而具体的加工步骤(非线性变换)则由一个高效、紧凑的自动化工具(窄瓶颈)完成。
下面是两种架构信息流的直观对比:
1.3 核心思想转变:跳跃连接的最佳位置
这项研究引发了一个更深层次的思考,跳跃连接应该设置在哪里?
传统观点认为,它应该连接语义最接近的层,通常是维度相同的输入和输出层。沙漏架构则表明,跳承连接的最佳位置可能并非“自然”维度,而是一个人工构造的、维度足够高的空间。即使这需要额外的投影和逆投影步骤,其带来的收益也可能远超成本。这个思想的转变,是从“在给定空间内优化”到“主动创造一个更优的学习空间”的跃迁。
二、 理论基石:高维空间的数学保证
将信息投向高维空间并非空穴来风,其背后有坚实的数学理论支撑,这也是沙漏架构敢于挑战传统范式的底气所在。
2.1 Johnson-Lindenstrauss (JL) 引理的启示
JL引理是高维几何领域的一个著名结论。它指出,对于一个高维空间中的点集,存在一个到低维空间的线性映射(随机投影),使得点与点之间的距离能够以很小的失真度被保留下来。
反过来理解,将低维数据随机投影到一个足够高维的空间,同样能够保持其内在的几何结构。这意味着,尽管投影是随机的,但数据点之间的相对关系、聚类形态等关键信息不会丢失。这为沙漏架构的“升维”操作提供了理论保障。在高维空间中进行渐进式修正,不会因为投影过程而破坏原始信息的完整性。
2.2 固定随机投影的工程价值
理论上的可行性,还需要转化为工程上的高效实现。沙漏架构在此处引入了一个极具价值的创新,固定随机投影(Fixed Random Projection)。
在传统的思路中,用于升维的投影矩阵通常被视为模型参数,需要通过反向传播进行学习和训练。研究团队发现,当目标高维空间的维度足够大时,这个投影矩阵完全不需要训练。一个在初始化后就固定不变的随机矩阵(例如,从高斯分布中采样生成)就足以胜任。
这一发现的工程意义是巨大的。
固定随机投影的成功,意味着模型可以将更多资源集中于学习窄瓶颈中的非线性变换,而不是浪费在学习如何“打包”和“解包”信息上。
2.3 理论的延伸:水库计算与随机特征
沙漏MLP的思想并非孤立存在,它与机器学习领域的一些其他理论思想遥相呼应。
水库计算 (Reservoir Computing):这是一种循环神经网络的计算范式。它使用一个大型的、固定的、随机生成的循环网络(“水库”)来将输入信号映射到高维空间,然后只训练一个简单的线性读出层。其核心思想与沙漏MLP的固定随机投影异曲同工。
随机特征 (Random Features):该方法通过一个随机映射将输入数据转换到高维特征空间,然后在这个新空间上训练一个线性模型,用以逼近复杂的核函数。这同样利用了高维随机投影能够保持信息结构的特性。
这些理论的共通之处在于,它们都认识到一个固定的、足够复杂的随机映射,可以为后续的学习任务提供一个良好的特征空间。沙漏MLP则巧妙地将这一思想与深度、残差学习结合,创造出一种全新的前馈网络架构。
三、 实证分析:性能与效率的双重验证
%20拷贝-xxzc.jpg)
一个新架构的价值,最终需要通过严谨的实验来证明。研究团队在多个生成式任务上,对沙漏MLP与传统MLP进行了系统性的比较。选择生成任务,是因为它们通常需要模型进行精细的、渐进式的改进,这恰好是沙漏架构声称的优势所在。
3.1 实验设计与基准设定
数据集:
MNIST:经典的手写数字数据集,用于初步验证。
ImageNet-32:32x32分辨率的ImageNet子集,更具挑战性。
任务类型:
生成分类 (Generative Classification):输入一张图像,模型需要先生成该类别的原型图像,再进行分类。考验模型的生成与判别双重能力。
去噪 (Denoising):去除图像中的高斯噪声,恢复原始图像。
超分辨率 (Super-Resolution):从低分辨率图像重建高分辨率图像。
评估指标:
峰值信噪比 (PSNR):衡量图像重建质量,越高越好。
参数-性能权衡曲线:在不同参数预算下,比较模型的性能表现,是评估架构效率的关键。
3.2 关键任务性能对比
实验结果清晰地展示了沙漏架构的优势。在几乎所有的参数预算下,沙漏MLP的性能都优于或等于传统MLP。
ImageNet-32 关键任务性能数据
这些数据表明,沙漏MLP在参数效率上取得了显著的胜利。它可以用更少的资源,完成同样甚至更好的工作。这种优势在中低参数预算区间尤其明显,这对于资源受限的边缘设备部署场景极具吸引力。
3.3 消融研究与架构洞察
为了深入理解沙漏架构的工作机制,研究团队进行了一系列消融实验,探索不同超参数的影响。
网络深度:随着残差块数量(深度)的增加,性能会提升,但在4到5层左右趋于饱和。这表明沙漏MLP不需要很深的网络就能达到很好的效果,体现了其“浅而巧”的设计哲学。
瓶颈宽度:增加窄瓶颈的维度可以提升性能,但收益在维度达到270之后开始递减。这说明一个适度的瓶颈宽度就足以进行有效的非线性变换,过宽则会浪费参数。
高维空间维度:高维空间的维度(跳跃连接的宽度)越大,性能越好。最优配置中,该维度通常远超输入/输出维度,例如达到1000以上。
这些发现揭示了沙漏MLP独特的缩放规律 (Scaling Law)。与传统MLP倾向于使用浅层(2-3层)和极宽的隐藏层(>3000维)不同,沙漏MLP的最优配置倾向于更深的网络(4-5层)、极宽的跳跃连接和相对较窄的瓶颈。这是一种全新的、更高效的参数分配策略。
四、 应用前景与生态融合
沙漏MLP作为一种基础的架构创新,其价值远不止于替代传统的MLP块。它提供了一种新的设计思路,可以与现有的主流AI模型生态进行深度融合。
4.1 对Transformer架构的潜在改造
Transformer模型是当前大规模语言模型和视觉模型的核心。其内部的前馈网络(FFN)占据了大量的参数和计算量,通常就是一个标准的“窄-宽-窄”MLP。
将FFN替换为沙漏MLP块,是一个极具吸引力的优化方向。
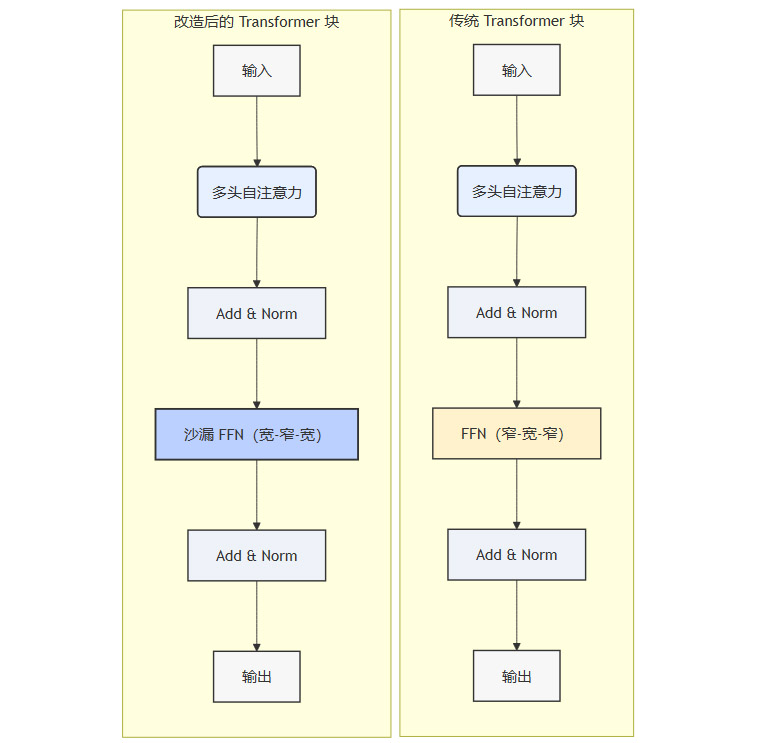
挑战:自注意力机制的输出维度需要与FFN的输入维度匹配。沙漏FFN的“宽”输入端意味着需要调整注意力头的维度或引入额外的适配层。
解决方案:可以采用**多头潜在注意力 (Multi-Head Latent Attention)**等高效注意力机制。这类机制允许在保持注意力头计算量不变的情况下,处理更高维度的表示。
收益:通过引入固定随机投影和更高效的参数分配,改造后的Transformer有望在保持甚至提升性能的同时,显著降低内存带宽需求和计算成本。
4.2 赋能现有视觉模型
沙漏架构的思想也可以无缝集成到其他主流视觉模型中。
MLP-Mixer:这类完全基于MLP的视觉模型,其核心就是通道混合MLP和空间混合MLP。将这些MLP块替换为沙漏版本,可以直接提升模型的参数效率。
U-Net:作为图像生成和翻译领域的王者架构,U-Net的编码器-解码器结构与沙漏的“宽-窄-宽”有异曲同工之妙。可以将沙漏块作为U-Net中每个分辨率层级的核心处理单元,或者在U-Net的输入端引入高维投影,增强其特征表示能力。
4.3 硬件层面的优化潜力
固定随机投影的特性为硬件协同设计打开了大门。在未来的AI芯片中,可以设计专门的硬件单元,用于按需实时生成随机投影矩阵。这个矩阵无需存储在昂贵的片上SRAM或从DRAM中读取,从而彻底消除了这部分访存开销。这对于追求极致能效比的边缘计算和大规模数据中心推理场景,具有决定性的意义。
五、 挑战、局限与未来展望
%20拷贝-hzyx.jpg)
任何一项创新都非完美,沙漏MLP同样面临一些待解决的问题和广阔的探索空间。
5.1 当前研究的边界
任务与数据局限:目前的验证主要集中在低分辨率(32x32)的生成任务上。该架构在高分辨率图像、自然语言处理、强化学习等更复杂任务上的表现,仍需进一步的实证检验。
固定投影的普适性:虽然固定随机投影在当前实验中表现优异,但在需要极高精度或处理高度结构化信息的任务中,其有效性是否会下降,是一个开放性问题。
超参数选择:高维空间的维度、瓶颈宽度、网络深度等关键超参数目前主要依赖经验性的架构搜索。如何建立一套理论指导下的自动化、系统化的选择方法,是未来需要解决的难题。
5.2 未来的研究方向
理论深化:从高维几何、信息论和学习理论的交叉视角,更深入地理解为何高维空间中的渐进式改进如此有效。
架构融合与自动化:开发将沙漏思想自动化地集成到任意神经网络架构中的工具链(类似神经架构搜索NAS),并探索其与注意力、卷积等其他操作的最佳组合方式。
跨领域应用:系统性地将沙漏架构应用于NLP(例如,替换词嵌入后的处理层)、语音识别、时间序列分析等领域,验证其普适性。
生物神经学启发:探索沙漏架构与大脑皮层信息处理机制的相似性。大脑皮层中大量的神经元在高维连接空间中交互,通过相对稀疏的通路传递关键信息,这与沙漏的设计理念存在有趣的对应关系。
结论
沙漏MLP架构的提出,远不止是提供了一个新的神经网络组件。它从根本上动摇了业界沿用数十年的“维度保守主义”,用坚实的理论和详尽的实验证明,主动创造并利用高维“人工空间”进行学习,是一条通往更高AI效率的康庄大道。
这项工作展示了挑战基本假设的巨大科研价值。它提醒我们,在AI技术飞速迭代的今天,真正的突破往往源于对那些被视为理所当然的“常识”的重新审视。从“漏斗”到“沙漏”的转变,不仅是模型形态的变化,更是一种思维范式的跃迁。它为未来的AI系统设计,无论是在算法、软件还是硬件层面,都注入了全新的想象力。
📢💻 【省心锐评】
沙漏MLP的核心是把跳跃连接从低维“自然空间”搬到高维“人工空间”,配合固定随机投影,用更少的参数和带宽实现了更强的性能,是架构设计的一次思维升级。

评论