.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】深度伪造技术门槛骤降,内容滥用已成常态。本文深度剖析其技术根源、高级伪造特征,提供体系化辨别方法,并解读现行治理框架与未来路径。
引言
“如果你是温峥嵘,那我是谁?”这句看似荒诞的质问,来自演员温峥嵘本人。她在自己的直播间遭遇AI换脸盗用,上前对质反被对方拉黑。这并非孤立的戏剧性事件,而是生成式AI技术滥用现实的冰山一角。从奥运冠军全红婵的声音被克隆用于直播带货,到央视主持人形象被用于虚假广告,再到社交平台泛滥的“AI整蛊”视频,我们正步入一个“眼见不为实”的数字时代。
技术的民主化,本意是赋能创新。但当生成深度伪造内容的门槛低至几句文本指令时,其另一面便显现出来,即社会信任成本的急剧上升。虚假信息、网络诈骗、名誉侵权等风险,借助AI的外衣变得更具迷惑性。
本文旨在穿透现象的表层,从技术架构、攻防对抗、治理框架等多个维度,系统性地拆解这一问题。我们将深入分析伪造技术的核心原理,提供一套普通用户与专业人士均可参考的辨真指南,并探讨在技术、法规与伦-理的多重博弈下,我们应如何构建一个可信的数字未来。这不仅是对技术的审视,更是对数字时代生存法则的思考。
💠 一、滥用常态化:失控的数字拟像
%20拷贝.jpg)
生成式AI的内容滥用已从零星个案演变为一种普遍现象,其渗透的广度与深度前所未有。我们可以将其划分为三个主要层面。
1.1 公共领域的商业侵权与舆论操纵
1.1.1 肖像与声音的商业盗用
公众人物因其高知名度,成为AI内容滥用的首要目标。其核心驱动力是流量变现。
AI换脸直播:将知名演员、网红的脸实时替换到主播身上,利用其粉丝效应进行带货或吸引打赏。此类行为直接侵犯了肖像权。
仿声带货:通过少量音频样本,克隆特定人物的声音模型(Voice Cloning),用于制作带货音频、短视频配音。全红婵、孙颖莎等运动员的声音被用于售卖土鸡蛋,便是典型案例。
虚假广告:冒用权威人士(如央视主持人)的形象和声音,为其产品或服务背书,严重误导消费者,构成虚假宣传。
1.1.2 虚假热点事件的制造
AI被用于凭空捏造或篡改新闻事件,以达到操纵舆论、制造恐慌或博取眼球的目的。例如,利用AI生成“被压在废墟下的小男孩”等图片,在灾难期间传播,消费公众同情心,干扰救援秩序。这类行为的危害性在于,它污染了信息环境,削弱了媒体与机构的公信力。
1.2 私人领域的社交操纵与侵权
1.2.1 “AI整蛊”的边界失范
在短视频平台,“AI整蛊”家人或朋友的内容正大规模流行。例如,“流浪汉进家门骗老公”“AI合成声音假扮领导查岗”等剧本。虽然创作者多以“娱乐”为名,但这种行为存在明显的负面效应。
诱发盲目跟风:平台算法的推荐机制,使得此类内容病毒式传播,导致大量用户模仿,形成不良风气。
伦-理与情感伤害:在被整蛊者不知情的情况下,利用其信任进行欺骗,可能造成真实的情感伤害和信任危机。
侵犯隐私权:未经同意使用家人、朋友的肖像制作视频并公开发布,涉嫌侵犯他人肖像权和隐私权。
1.2.2 深度伪造与网络诈骗
这是AI滥用中危害最直接、最严重的形式。犯罪分子利用AI合成语音或视频,实施精准诈骗。
冒充熟人诈骗:通过窃取个人社交信息,利用AI合成特定对象的语音或视频,向其亲友发起通话,以“紧急情况”为由要求转账。
定制化网络勒索:利用深度伪造技术制作针对特定个人的不雅视频或虚假证据,进行敲诈勒索。
1.3 社会层面的信任侵蚀
当图像、视频、音频等传统意义上的“铁证”都变得不可信时,整个社会的信任基础便会动摇。每一次AI滥用事件,都是对社会信任的一次消耗。公众需要花费更多的时间和精力去甄别信息的真伪,沟通成本和决策成本显著增加。这种信任的流失,是AI技术滥用带来的最深远、最隐蔽的危害。
💠 二、技术拆解:“以假乱真”的生成逻辑
内容伪造门槛的大幅降低,并非单一技术的突破,而是模型、算力、工具链协同演进的结果。理解其背后的技术逻辑,是辨别与防御的第一步。
2.1 核心引擎:从GAN到扩散模型
早期广为人知的“换脸”技术,主要依赖生成对抗网络(Generative Adversarial Networks, GANs)。
GANs工作原理:它由一个生成器(Generator)和一个判别器(Discriminator)组成。生成器负责“造假”,努力生成逼真的图像;判别器负责“打假”,判断输入图像是真实的还是生成的。二者在持续的博弈中共同进化,最终让生成器产出足以以假乱真的内容。DeepFake等工具就是基于此原理。
然而,GANs在训练稳定性和生成多样性上存在瓶颈。近年来,**扩散模型(Diffusion Models)**成为主流,其生成质量和稳定性远超前者。
扩散模型工作原理:其过程可以通俗地理解为“先加噪,再降噪”。
前向过程(加噪):从一张清晰的真实图像开始,逐步对其添加高斯噪声,直到图像完全变成纯粹的噪声。
反向过程(降噪):训练一个神经网络,学习如何从纯噪声中一步步地“逆转”上述过程,最终恢复出清晰的图像。
这个降噪过程是可控的。通过输入文本提示(Prompt),模型可以在降噪过程中将图像“引导”至符合文本描述的样子。目前顶尖的文生图模型(如Stable Diffusion, Midjourney)和文生视频模型(如Sora)均基于此类架构。
2.2 多模态融合:构建连贯的虚假世界
现代AI伪造已超越单一的视觉或听觉。**多模态(Multi-modal)**生成技术,指的是模型能够理解和生成多种类型的数据(如文本、图像、音频),并确保它们之间的内在关联。
音画同步:当克隆一个人的声音时,模型不仅生成音频,还能同步驱动一个数字人模型的口型、面部表情,使其与声音的情绪、节奏、断句精准匹配。
场景与动作生成:输入一段描述,AI不仅能生成核心人物,还能自动补全符合逻辑的背景环境、光照条件,甚至设计出连贯的肢体动作。这使得伪造内容不再是简单的“贴脸”,而是一个整体协调的“小剧场”,极大地增加了辨别难度。
2.3 工具链的成熟与自动化
技术原理的复杂性,并未阻碍其应用的普及。这得益于高度集成化、流程化的工具链。
这种“傻瓜化”的工具设计,叠加短视频平台上大量的“速成教程”和“成功案例”,形成强大的示范效应,最终导致了滥用行为的指数级扩散。
💠 三、攻防之战:高级伪造与检测对抗
%20拷贝.jpg)
随着AI检测技术的发展,伪造技术也在同步进化,呈现出“道高一尺,魔高一丈”的对抗态势。新型伪造手段更具隐蔽性和对抗性。
3.1 针对检测模型的对抗性攻击
AI内容检测器本身也是一个深度学习模型,其工作原理是通过学习大量真实数据和AI生成数据的特征差异,来进行分类判断。这就为**对抗性攻击(Adversarial Attacks)**提供了可能。
攻击原理:攻击者在生成的伪造内容中,故意添加一种人眼无法察觉的、极其微小的扰动(或称为“噪声”)。这种扰动经过精心设计,能够精准地“欺骗”检测模型,使其做出错误的判断(例如,将一张99%伪造的图片识别为“真实”)。
实现方式:这通常需要攻击者对目标检测模型的内部结构有一定了解(白盒攻击),或者通过大量查询来推断其决策边界(黑盒攻击)。
3.2 数字水印的规避与去除
为实现内容溯源,行业和法规都在推动**数字水印(Digital Watermarking)**技术。但伪造者同样有办法对抗。
隐性水印的脆弱性:隐性水印通常嵌入在图像的像素数据或频域中。一些简单的图像处理操作,如压缩、裁剪、旋转、加滤镜,都可能无意或有意地破坏水印信息,使其失效。
主动去除:更高级的攻击者,可以训练一个专门的AI模型,其任务就是识别并抹除特定类型的水印,同时尽可能保持原内容的视觉质量。
3.3 “一键去除AI标识”的工具
部分工具的开发者,为了迎合用户的非法或灰色需求,直接在产品中内置了规避功能。例如,在生成设置中提供一个“去除AI生成痕迹”或“增强真实感”的选项。这背后可能是一系列复杂的算法,用于平滑AI生成内容中常见的瑕疵(如不自然的纹理),或主动添加模拟真实相机拍摄的噪点、畸变等,从而绕过检测。
这种攻防的持续升级,意味着单纯依赖技术工具进行检测,永远存在滞后性。建立一个稳健的防御体系,必须是技术、规范和人的认知多管齐下。
💠 四、专业级辨真指南:从肉眼到工具的系统化方法
尽管AI伪造技术日新月异,但受限于算法、算力和数据,现阶段的生成内容仍会不可避免地留下一些蛛丝马迹。以下是一套从宏观到微观的系统化辨别方法。
4.1 宏观层:逻辑与情境核查
在分析技术细节之前,首先要进行常识性判断。
信息来源交叉验证:这是最重要也最基础的一步。对于任何来源可疑、内容劲爆的视频或音频,切勿轻信和转发。应立即通过多个独立的、权威的新闻网站或官方发布渠道进行交叉验证。
情境合理性分析:视频中的人物言行是否符合其一贯身份、性格和所处环境?事件的发生是否符合基本的社会逻辑和物理规律?例如,一位严谨的科学家突然在视频中发表极端言论,就需要高度警惕。
延迟判断原则:对于重大公共事件,信息在初期往往混乱且矛盾。养成延迟判断的习惯,等待更多信息浮现,避免被第一波虚假信息误导。
4.2 微观层:视觉与听觉异常检测
这是针对内容本身的技术细节甄别,需要调动感官,仔细观察。
4.2.1 视觉异常(静态与动态)
4.2.2 听觉异常
声音的韵律与情感:AI合成语音在语调、节奏和情感表达上仍有欠缺,可能听起来平淡、机械,缺少真人说话的韵律感。
背景噪音与环境音:伪造的音频通常背景“过于干净”,缺少真实环境中的微小杂音。或者,背景音与说话内容不匹配(如在室内说话却有风声)。
不自然的停顿与换气:AI在处理长句子时,可能会在不符合语言逻辑的地方停顿或换气。
4.3 交互层:主动测试(尤其适用于直播)
对于实时交互的场景(如视频通话、直播),可以采取主动测试的方法来戳穿伪装。
遮挡测试:这是目前最简单有效的物理鉴定方法。要求对方在脸前挥手、拿杯子喝水,或用一张纸部分遮挡面部。AI换脸算法依赖对五官特征点的持续跟踪,遮挡会破坏这种跟踪,导致:
面部扭曲或闪烁:被遮挡区域或其边缘出现短暂的图像错乱。
边缘融合:手指或杯子的边缘与面部发生不自然的融合、模糊。
指令测试:要求对方做出一些特定的、复杂的、非预设的动作。例如,快速转头、做鬼脸、用手指指自己的鼻子等。AI驱动的数字人通常动作库有限,难以流畅完成这些指令。
记忆与逻辑测试:在对话中,提及几分钟前聊过的一个细节,看对方是否能记住并进行有逻辑的衔接。很多AI脚本缺乏长时程记忆能力。
4.4 工具层:专业检测辅助
当肉眼难以判断时,可以借助专业工具。目前市面上已有不少AI内容检测工具或服务,它们通过分析内容的底层数据特征来判断其来源。
数字指纹分析:不同的AI模型在生成内容时,会留下独特的、肉眼不可见的“指纹”(Artifacts),例如特定的像素模式或频域特征。检测工具通过识别这些指纹来判断内容是否为AI生成。
元数据检查:检查文件(如图片、视频)的元数据(Metadata),看是否包含由生成服务主动写入的来源信息。
流程图:一套完整的辨真流程
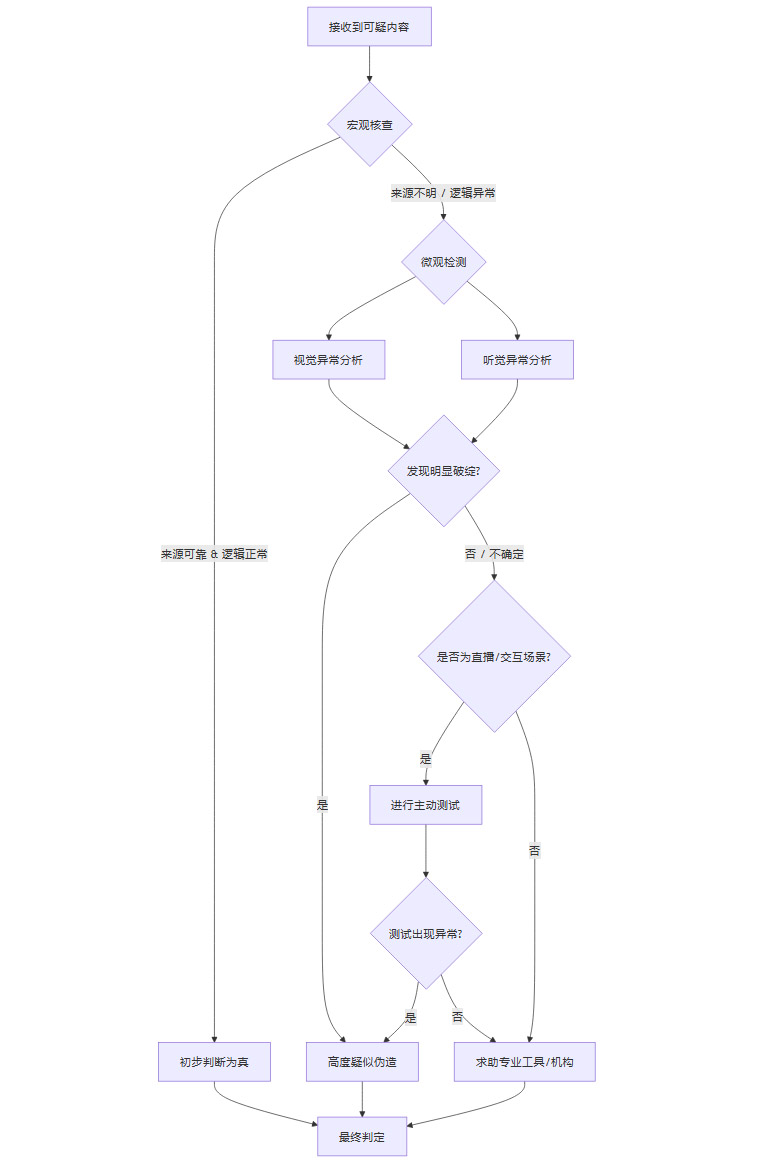
💠 五、治理框架:为失序的技术划定红线
%20拷贝.jpg)
面对AI滥用的严峻挑战,单一的技术防御远远不够,必须建立一个包含法规、标准、平台责任和公众教育的立体化治理体系。
5.1 法规先行:《标识管理办法》的落地
我国在AI内容治理方面走在了世界前列。2023年8月15日起施行的**《生成式人工智能服务管理暂行办法》,以及更具针对性的《互联网信息服务深度合成管理规定》**,为AI内容的“身份”问题提供了明确的法律依据。
核心要求是实施标识制度。
显性标识:服务提供者必须在生成内容的显著位置,以文字、图标等方式,明确告知用户此内容由AI生成。这保障了用户的知情权,是防止误导的第一道防线。
隐性标识:通过数字水印、元数据等技术手段,在内容中嵌入不可见的、不易被篡改的溯源信息。这为监管和执法提供了可追溯性,确保一旦发生问题,能够追查到责任主体。
5.2 标准统一:从“要不要标”到“如何标”
法律规定了原则,而强制性国家标准则解决了具体执行问题。例如,相关的国家标准会详细规定:
标识的技术规范:水印的嵌入算法、鲁棒性(抗攻击能力)要求、信息编码格式等。
标识的统一性:确保不同平台、不同服务商生成的AI内容,其标识具有一定的通用性和互操作性,避免出现“百花齐放”却无法有效识别的局面。
检测与验证标准:为第三方检测机构提供统一的评判依据。
5.3 平台压责:从“避风港”到“责任田”
短视频、社交媒体等平台是AI滥用内容的主要传播渠道,其主体责任至关重要。
内容审核机制升级:平台不能再仅仅依赖传统的关键词过滤,必须投入资源研发和部署先进的深度伪造内容检测技术,建立技术识别+人工审核的复合模式。
强化用户举报与处置:设立清晰、便捷的举报入口,对用户举报的违规内容进行快速响应和处置。对确认违规的账号,采取限流、封禁等惩罚措施,并建立“黑名单”机制。
算法推荐的价值导向:平台的推荐算法不应只追求流量,需要引入安全和伦-理权重,主动限制低俗、有害的AI生成内容的传播。
5.4 执法协同:打击黑色产业链
深度伪造的背后,往往隐藏着一条集“技术开发-工具贩卖-内容定制-诈骗实施”于一体的黑色产业链。
专项打击行动:网信、工信、公安等多部门需开展协同联动的专项整治行动,如“清朗·整治AI技术滥用”,从源头上对黑产进行全链条打击。
建立协同执法机制:打破部门壁垒,实现信息共享和快速响应,对跨平台、跨地域的违法犯罪行为进行高效追查。
结论
生成式AI的技术浪潮不可逆转。它既是强大的生产力工具,也可能成为颠覆社会信任的“潘多拉魔盒”。我们正处在一个关键的十字路口,治理的智慧不在于因噎废食地“禁止”,也不在于放任自流地“纵容”,而在于如何在激发创新活力与守住法律伦-理底线之间,找到那个精妙的平衡点。
构建一个“标准—检测—评价”的闭环治理机制,将技术的发展置于一个可控、可追责的框架之内,是当前的首要任务。对于技术从业者而言,应坚守“技术向善”的初心;对于平台而言,应扛起不可推卸的社会责任;对于每一位数字公民而言,则需要不断提升自身的媒介素养,练就一双辨别真伪的“火眼金睛”。
守护一个清朗可信的数字空间,不是某一方的独角戏,而是全社会必须共同面对和完成的课题。
📢💻 【省心锐评】
技术本身无罪,但其应用必须有边界。当AI模糊了真实与虚构的界限,我们亟需的不是技术刹车,而是强有力的法律缰绳与清醒的社会共识。

评论