.png)


【摘要】苹果最新论文质疑当前AI推理模型的“推理能力”,引发业界热议。本文深度剖析苹果的实验设计、核心发现、业界反响及其背后技术与商业逻辑,全面探讨AI推理模型的现状与未来挑战。
引言
2024年6月,一篇来自苹果的AI研究论文在全球科技圈引发轩然大波。苹果团队罕见地“开炮”当前大热的推理模型(如DeepSeek-R1、o3mini等),直指它们“没有真正的推理能力”,更像是“记忆力超群的背题机器”。这一观点不仅在X(原推特)上引发千万级围观,也让AI领域的技术、产业和学术界陷入激烈争论。
推理模型一直被视为通向通用人工智能(AGI)的关键路径。苹果的质疑,是对AI推理能力的深刻反思,还是商业竞争下的“酸葡萄心理”?本文将以技术论坛的深度视角,系统梳理苹果论文的实验设计、核心发现、业界回响,并结合AI推理模型的技术发展现状,探讨其背后的技术逻辑、产业影响与未来挑战。
一、🍏苹果“炮轰”推理模型:事件全景与核心观点
%20拷贝.jpg)
1.1 事件回顾:苹果论文引爆AI圈
2024年6月,苹果AI研究团队发布论文,首次系统性地质疑当前主流推理模型的“推理能力”。论文一经发布,相关推文在X平台引发超千万次浏览,成为AI领域的年度大事件。苹果的核心观点是:
当前推理模型在数学、编程等基准测试中表现优异,实则依赖“记忆”而非“推理”。
现有评测方法存在数据污染和过程不可观测等严重缺陷。
推理模型的“思考机制”本质上是复杂的启发式搜索或模式匹配,缺乏真正的逻辑推理能力。
1.2 研究背景:AI推理能力的衡量困境
1.2.1 传统评测方法的局限
数据污染:模型训练时可能见过测试题目或类似题型,答对题目未必代表具备推理能力。
过程不可观测:只看最终答案,忽略模型推理过程的合理性与逻辑性。
1.2.2 推理模型的技术现状
以Transformer为代表的大模型,通过大规模数据训练,具备一定的“推理”能力。
业界普遍采用数学、编程等标准化测试集评估模型能力,忽视了推理过程的可解释性和泛化性。
1.3 苹果的核心论点:“思考的幻象”
苹果团队认为,当前推理模型的“思考”更像是对已知模式的复杂匹配,而非真正的逻辑推理。其主要论据包括:
模型在复杂问题上准确率骤降,且“思考token”数量反而减少,显示其推理机制存在根本性缺陷。
对于简单问题,模型过度思考,浪费资源;对于复杂问题,早期犯错且难以自我纠正。
即使提供完整的解析算法,模型仍无法正确执行,暴露出基础逻辑能力的缺失。
二、🔬苹果实验揭秘:创新测试方法与核心发现
2.1 跳出常规:苹果的创新测试范式
2.1.1 传统基准测试的弊端
数据污染:模型可能“背题”,答对不等于会推理。
过程不可观测:只看结果,忽略推理路径。
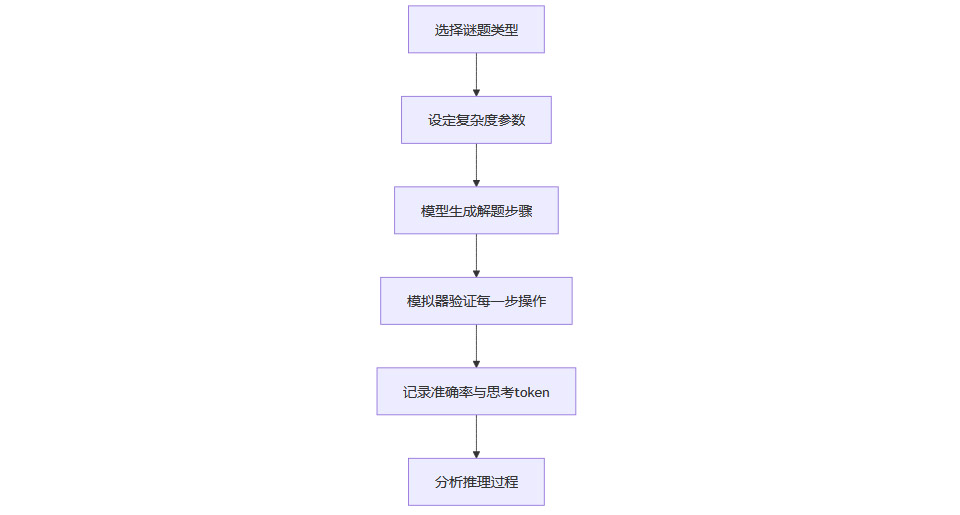
2.1.2 苹果的谜题测试环境
苹果团队设计了四类经典谜题,作为推理能力的“试金石”:
这些谜题逻辑结构稳定,复杂度可控,能有效排除数据污染。
通过模拟器验证模型每一步操作,量化推理过程。
2.1.3 测试流程图
2.2 三大发现:挑战AI推理模型的“神话”
2.2.1 性能“三重奏”:模型能力与问题复杂度的关系
低复杂度:标准模型表现优于推理模型,推理模型反而“过度思考”。
中等复杂度:推理模型展现优势,能处理一定逻辑推理任务。
高复杂度:两类模型均崩溃,准确率归零,推理模型未突破能力瓶颈。
2.2.2 “思考退化”之谜:准确率与思考token数量的异常变化
随着问题复杂度提升,模型准确率骤降,思考token数量反而减少。
说明模型在面对难题时,内部推理机制“崩溃”,缺乏深入思考能力。
2.2.3 思维“迷局”:推理模型的非人类思考路径
简单问题:过度思考,浪费资源。
复杂问题:早期犯错,难以自我纠正。
基础逻辑能力缺失:即使给出完整算法,模型仍无法正确执行。
2.2.4 发现总结表
三、🧠推理模型的技术本质与发展瓶颈
%20拷贝.jpg)
3.1 推理模型的技术原理
3.1.1 以Transformer为核心的语言模型
通过大规模文本数据训练,学习语言模式、逻辑关系。
具备一定的“推理”能力,但本质是概率统计与模式匹配。
3.1.2 推理能力的实现方式
启发式搜索:在解题空间中寻找最优路径。
模式匹配:根据历史数据找到相似问题的解法。
有限泛化:对未见过的问题,尝试组合已知模式。
3.1.3 技术瓶颈
泛化能力有限:难以应对全新、复杂的推理任务。
自我纠错能力弱:一旦早期犯错,难以回头修正。
推理过程不可解释:黑箱式决策,难以追踪思考路径。
3.2 苹果实验的技术启示
3.2.1 谜题测试的创新意义
通过可控谜题,精准量化推理过程,避免数据污染。
使推理能力的评估更接近“人类思维”标准。
3.2.2 对现有推理模型的挑战
揭示了推理模型在复杂任务上的“思考退化”与“迷局”。
强调推理过程的可解释性与逻辑一致性。
3.2.3 对未来AI推理能力的启发
需要突破“记忆-匹配”范式,发展具备自我纠错、泛化与逻辑推理的新型AI架构。
推理能力的评估应关注过程而非仅仅结果。
四、🌐业界回响:支持与反对的交锋
4.1 支持者:理性反思与技术警钟
4.1.1 支持观点
当前大模型主要依赖数据记忆,推理能力有限。
在机器人、医药研发等实际应用中,推理模型的局限性日益凸显。
苹果研究为业界敲响警钟,促使技术路线反思。
4.1.2 典型案例
4.1.3 支持者观点小结
苹果研究有助于行业认清AI推理模型的真实能力,避免盲目乐观。
4.2 反对者:质疑动机与方法
4.2.1 反对观点
质疑苹果“吃不到葡萄说葡萄酸”,因其大模型进展不及对手。
认为苹果测试谜题过于理想化,不能代表现实复杂问题。
指出实验对模型输出的token数量限制,可能影响模型真实表现。
4.2.2 反对者的技术批评
谜题测试环境与现实世界差距大,难以全面评估推理能力。
token限制如同考试限字,影响模型“发挥”。
4.2.3 反对者观点小结
苹果研究结论有待商榷,需更多现实场景验证。
五、🧩推理模型的现实挑战与未来方向
%20拷贝.jpg)
5.1 现实挑战
5.1.1 泛化与自我纠错能力
现有模型难以应对全新、复杂的推理任务。
缺乏自我纠错与动态调整能力。
5.1.2 推理过程的可解释性
黑箱式决策,难以追踪和理解模型的推理路径。
影响AI在高风险领域(如医疗、金融)的应用落地。
5.1.3 评测体系的完善
需要更贴近人类思维的推理能力评测方法。
应关注推理过程的合理性与逻辑一致性。
5.2 未来发展方向
5.2.1 新型AI架构探索
结合符号推理与神经网络,发展“可解释AI”。
引入元学习、自我监督等机制,提升泛化与自我纠错能力。
5.2.2 推理能力的多维评估
设计多样化、可控的推理任务,量化模型在不同场景下的表现。
强化对推理过程的观测与分析。
5.2.3 产业应用的落地与反馈
在机器人、医疗、自动驾驶等领域,推动推理模型的实际应用与反馈。
以真实场景需求反哺模型设计与评测体系。
六、📊苹果实验与业界主流推理模型对比分析
6.1 主流推理模型能力对比表
6.2 推理模型能力提升的技术路径
数据多样性提升:引入更多类型的推理任务,丰富训练数据。
结构创新:结合符号推理与神经网络,提升逻辑推理能力。
过程可解释性:开发可追踪推理路径的模型架构。
自我纠错机制:引入元学习、自我监督等机制,提升模型自我修正能力。
七、📝结论:苹果“炮轰”背后的技术与产业启示
苹果对推理模型的“炮轰”,无疑为AI推理能力的评估与发展带来了新的思考。其创新的谜题测试方法,揭示了当前推理模型在复杂任务上的“思考退化”与“迷局”,对业界盲目乐观的情绪敲响了警钟。尽管苹果的动机和方法受到争议,但其核心发现具有重要的技术与产业启示:
AI推理能力的提升,不能仅依赖大数据与模式匹配,更需突破逻辑推理与自我纠错的技术瓶颈。
推理模型的评估体系亟需完善,应关注推理过程的可解释性与泛化能力。
产业应用的反馈,将成为推动AI推理能力进化的关键动力。
未来,AI推理模型的发展需要技术创新、评测体系完善与产业场景深度结合。苹果的“炮轰”或许只是开始,真正的AI推理革命,仍在路上。
📢💻 【省心锐评】
从智能语音助手到图像识别技术,从自动驾驶到医疗诊断辅助,AI 已经深入到我们生活的方方面面 。虽然现在它还存在一些局限,但这也正是科技进步的动力源泉 。未来,随着研究的不断深入,也许会有新的算法、新的技术出现,突破当前的瓶颈,让 AI 真正拥有强大的推理能力 。

评论