.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】针对图文混合文档检索痛点,RAG-Anything通过双图谱架构与混合检索机制,实现多模态信息精准对齐与深度语义关联,显著提升长文档理解能力。

在当前的企业级知识库构建与学术辅助场景中,检索增强生成(RAG)技术已然成为标配。然而,作为一名在一线摸爬滚打多年的架构师,我们必须诚实地面对一个尴尬的现状:现有的RAG系统在处理纯文本时表现尚可,可一旦面对包含大量图表、公式、复杂嵌套表格的PDF文档、行业研报或技术手册时,往往显得力不从心。
传统的处理链路通常简单粗暴:利用OCR将文档转写为纯文本,或者干脆忽略非文本内容。这种做法的代价是巨大的——图表中的趋势分析、表格中的行列逻辑、公式背后的物理含义,这些往往承载着文档最高价值的信息,在向量化的过程中被无情丢弃。我们得到的,往往是一个“买椟还珠”的残缺知识库。
香港大学研究团队近期提出的RAG-Anything框架,本质上是对文档解析与索引机制的一次底层重构。它不再满足于简单的文本分块(Chunking),而是引入了**双图谱(Dual-Graph)**策略,试图在机器理解层面还原文档的“全貌”。这项研究不仅是算法上的创新,更给工程落地带来了新的思路:如何解决多模态信息在向量空间中的“对齐”难题?如何利用图结构解决长文档检索中的“迷失”现象?本文将从架构视角,深入剖析这一技术方案。
💠 一、 多模态文档的“原子化”解析与重组
%20拷贝.jpg)
构建高质量RAG系统的第一步永远是数据处理(ETL)。Garbage In, Garbage Out 是数据科学不变的真理。RAG-Anything在这一环节引入了“原子化”概念,将文档视为由不同性质的信息原子组成的集合,而非单一的线性文本流。
1.1 全要素识别与分类机制
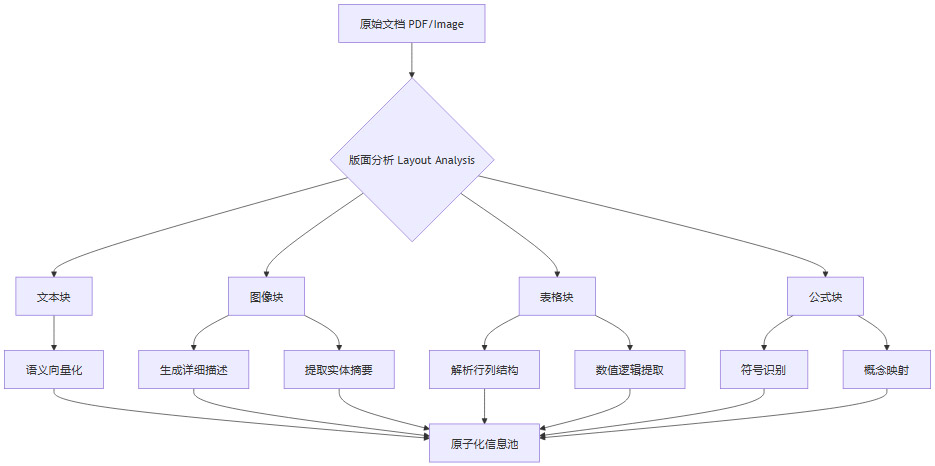
传统解析器(如PyPDF2或Unstructured)往往试图将文档扁平化,强行将二维的版面压缩为一维的字符串。RAG-Anything则采用了分层识别策略,尊重文档的原始拓扑结构。系统首先对文档进行高精度的版面分析(Layout Analysis),将内容切割为四个核心原子类型:
文本原子(Text Atoms):常规的段落文字、标题、列表。这是传统RAG最擅长的部分。
图像原子(Image Atoms):插图、照片、示意图、流程图。
表格原子(Table Atoms):财务报表、参数对比表、数据统计表。
公式原子(Formula Atoms):数学推导、化学方程式、物理定律。
这种分类的工程意义在于,不同类型的数据具有完全不同的特征分布,需要不同的Embedding策略和存储结构。混合处理往往会导致向量空间的混乱,使得检索精度大幅下降。
1.2 深度特征提取策略
识别只是第一步,理解才是关键。针对不同类型的原子,系统采用了差异化的特征提取手段,确保信息在转化为机器语言时不失真。
1.2.1 图像的双重描述机制
对于图像,单纯的向量化(如使用CLIP模型生成embedding)往往会丢失细节。比如一张展示“2023年Q4营收增长15%”的柱状图,CLIP可能只能编码出“一张包含柱子的图”,而丢失了具体的数值和趋势。
RAG-Anything采用了双重描述策略来解决这个问题:
详细描述(Detailed Description):利用多模态大模型(LMM)生成一段包含图像所有视觉细节的长文本。这段描述会捕捉背景、颜色、构图、文字标注等信息,就像是给盲人详细解说这张图片。
实体摘要(Entity Summary):提取图像中的关键实体(如“柱状图”、“增长率”、“A公司”、“2023年”),作为标签。
这种做法兼顾了语义的丰富性(用于模糊检索)和实体的精确性(用于结构化过滤)。
1.2.2 表格的结构化语义解析
表格是RAG领域的“噩梦”。简单的按行读取(Row-wise)会破坏列之间的逻辑,导致“张三”和“工资”这两个单元格在文本流中相隔甚远,模型无法建立联系。
RAG-Anything不仅记录单元格数值,还解析行列结构。它将表格视为一个小的子图或结构化对象:
1.2.3 公式的概念映射
对于公式,系统不只识别LaTeX代码,还尝试理解其背后的数学/物理含义。例如,识别出 E=mc2E=mc2 不仅是一串符号,更关联到“质能方程”、“相对论”、“爱因斯坦”等概念。这使得用户在搜索“计算能量的公式”时,即使文档中只有符号没有文字说明,也能被准确召回。
🕸️ 二、 创新的“双图谱”架构:构建立体知识网络
这是RAG-Anything最核心的技术突破,也是它区别于市面上大多数RAG方案的特征。
目前的RAG架构主要分为两派:纯向量检索(Vector RAG)和纯知识图谱检索(Graph RAG)。前者缺乏逻辑推理能力,后者构建成本极高且难以处理非结构化数据。RAG-Anything提出了一种**双图谱(Dual-Graph)**架构,巧妙地平衡了两者,构建了一个既包含视觉空间结构,又包含深度语义逻辑的立体网络。
2.1 跨模态图谱 (Cross-modal Graph):物理与显式连接
这个图谱主要解决“图文对齐”的问题。在复杂的学术论文或研报中,文字经常会引用图表(如“如图1所示”),或者对表格数据进行解释。如果切片时将它们打散,这些引用关系就断了。
跨模态图谱通过以下方式重建这些连接:
节点定义:文本块、图像、表格、公式均作为图谱中的独立节点。
边(Edge)的构建逻辑:
显式引用(Explicit Reference):文本中出现“Table 1”、“Figure 2”、“Eq. 3”等关键词时,系统会自动建立该文本节点指向对应图表节点的边。
空间邻近(Spatial Proximity):物理位置上紧邻的图注(Caption)与图片建立强连接。通常图注就在图片的下方或上方,这种空间关系是极强的语义信号。
隐式语义相关(Implicit Semantic Relevance):通过语义分析,发现某段文字虽然没有明确写“如图X”,但其内容是对某张图的解释或总结,系统会建立隐式连接。
这种设计让检索算法能够“顺藤摸瓜”。当用户问“图2展示了什么趋势”时,系统不仅能找到图2本身,还能顺着边找到正文中对图2的深度分析文字,从而生成更全面的答案。
2.2 语义图谱 (Semantic Graph):逻辑与概念连接
跨模态图谱解决了“形式”上的关联,语义图谱则解决“内容”上的逻辑。这部分更接近传统的知识图谱,但更侧重于文本内部的细粒度逻辑梳理。
实体抽取:从文本中提取关键概念(如“Transformer架构”、“净利润”、“消融实验”、“抗体序列”)。
关系构建:
包含关系:A属于B(如“CNN属于深度学习模型”)。
因果关系:A导致B(如“加息导致流动性收紧”)。
对比关系:A优于B(如“RAG-Anything准确率高于基线模型”)。
时序关系:A发生在B之前。
2.3 实体对齐与图谱融合
两个图谱不是割裂存在的,而是通过**实体对齐(Entity Alignment)**技术融合在一起。
举个例子:
跨模态图谱中有一个“表格节点(Table 3)”,其中包含数据“2023年营收:50亿”。
语义图谱中有一个从正文提取的“实体节点(2023年营收)”。
系统识别出这两个节点指向同一个现实世界的概念,因此将它们强关联。
最终形成的融合图谱是一个多层网络。这比单纯的向量数据库高了一个维度,因为它不仅知道“这句话和那个词很像”,还知道“这张表是那段话的证据”以及“这个概念是那个结果的原因”。
🔍 三、 混合检索机制:结构化导航与语义匹配
%20拷贝.jpg)
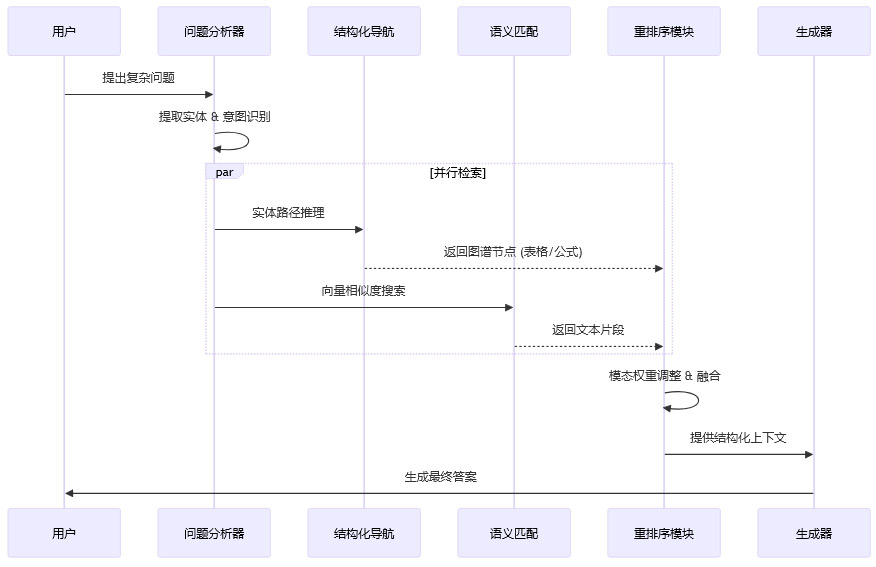
有了高质量的图谱,如何检索是下一个挑战。单纯的图遍历可能效率低下,单纯的向量搜索又缺乏精度。RAG-Anything没有放弃向量检索,而是将其与图遍历结合,形成了一套双轨检索机制(Hybrid Retrieval)。
3.1 结构化知识导航 (Structured Navigation)
这条轨道适合处理复杂逻辑推理问题,或者是需要精确证据链的问题。
场景示例:用户提问:“A模型比B模型在长文本任务上提升了多少?”
处理流程:
实体识别:系统识别出问题中的实体“A模型”、“B模型”、“长文本任务”。
节点定位:在图谱中定位这些实体节点。
路径推理:沿着边寻找连接这些实体的路径。系统会优先寻找指向“表格节点”或“对比结论文本”的路径,因为这类节点最可能包含具体的数值对比。
多跳推理(Multi-hop):如果A和B没有直接连接,系统会寻找中间节点(如“实验结果章节”),通过多跳锁定包含具体数值的表格单元或文本段落。
这种方法类似于人类查阅资料时的“顺藤摸瓜”,准确率极高,且具备极强的可解释性——系统可以告诉用户:“我之所以得出这个结论,是因为在Table 5中找到了A的数据,在Table 6中找到了B的数据。”
3.2 语义相似性匹配 (Semantic Matching)
这条轨道适合处理模糊查询、概念性问题或非结构化描述。
场景示例:用户提问:“这篇论文主要讨论了什么核心思想?”
处理流程:
向量化:将用户问题转化为高维向量。
KNN搜索:在所有原子节点(包括文本、图像描述、表格摘要)的向量空间中进行最近邻搜索。
召回:召回语义最接近的摘要、引言或结论段落。
这部分利用了预训练模型(如BERT、BGE)强大的语义泛化能力,弥补了图谱可能存在的覆盖不全或构建错误的问题。
3.3 动态策略调整与模态感知
系统并非僵化地执行两条路径,而是具备**模态感知(Modality-Aware)**能力。
线索分析:如果问题中包含“图表”、“趋势”、“数据”、“外观”、“结构”等词汇,系统会自动提高图像和表格节点的检索权重。
结果重排序(Re-ranking):来自两条轨道的检索结果会汇聚到一个重排序模块。该模块会综合考虑相关性分数、模态匹配度以及图谱中的连接强度,输出最终的上下文列表。
📈 四、 长文档理解的性能跃升
长文档(Long Context)是RAG系统的试金石。随着文档长度增加,噪声呈指数级增长,传统向量检索容易出现“Lost in the Middle”现象,即相关信息被淹没在无关信息中,导致LLM无法获取正确的上下文。
4.1 解决“迷失”问题:图谱即索引
RAG-Anything在长文档上的表现尤为出色,核心原因在于图谱的索引作用。
局部定位:图谱结构天然将文档划分为了若干个语义簇。检索时,系统能快速定位到相关的“子图”或“章节簇”,直接过滤掉90%的无关内容。这就像在图书馆找书,先看索引卡片定位到书架,而不是把所有书都翻一遍。
上下文完整性:传统切片(Chunking)容易切断上下文。图谱通过边连接,保证了检索到的信息块总是带着它的上下文(如表格带着表头和图注,图片带着详细描述)。这种“带上下文的检索”极大减少了断章取义的风险。
4.2 实测数据支撑
在DocBench(综合多模态)和MMLongBench(长文档)两个权威测试集上,RAG-Anything的数据极具说服力。
数据表明,文档越长,结构越复杂,RAG-Anything的架构优势越明显。在超过100页的文档中,其性能优势达到了惊人的13个百分点。这有力地验证了“结构化认知”在处理大规模信息时的必要性。
4.3 消融实验:谁是功臣?
研究团队通过消融实验(Ablation Study)进一步分析了各个组件的贡献:
移除图谱构建:准确率下降约3.4%。这证明了图结构是性能提升的主力。
移除交叉模态重排序:准确率下降约1%。这说明精细化的排序策略起到了锦上添花的作用。
🛠️ 五、 工程挑战与落地思考
%20拷贝.jpg)
虽然RAG-Anything的架构设计非常先进,但在实际工程落地中,作为架构师,我们需要清醒地认识到其中的Trade-off(权衡)。
5.1 计算成本与延迟
构建双图谱是一个计算密集型过程。
预处理耗时:对每一页PDF进行深度版面分析、图像描述生成(需要调用VLM)、实体抽取(需要调用LLM),其算力消耗远高于简单的文本Embedding。
图谱维护:图数据库(如Neo4j、NebulaGraph)的存储和查询开销通常高于向量数据库(如Milvus、Pinecone)。
因此,该方案更适合离线索引构建。对于实时性要求极高的流式文档处理,可能需要进行架构剪裁或异步处理。
5.2 基础模型的依赖性
系统的上限取决于底层模型的质量。
如果OCR模型读错了表格数据,图谱中的节点数值就是错的。
如果视觉模型(VLM)生成的图像描述不准确,跨模态索引就会失效。
误差传播:解析阶段的微小错误会在图谱构建和推理阶段被放大。
这意味着在落地时,必须选用SOTA级别的基础模型(如GPT-4o-mini用于描述生成,PaddleOCR或TextIn用于版面分析),这会进一步增加成本。
5.3 适用场景分析
基于上述特性,RAG-Anything最适合以下场景:
金融研报分析:包含大量K线图、财务报表,且对数据准确性要求极高。
医药文献检索:包含复杂的化学分子式、实验数据图表。
工业图纸说明书:包含大量结构图、零件表、装配流程图。
法律合同审查:包含复杂的条款引用和附件表格。
而对于纯文本小说、简单的FAQ库或实时新闻流,传统的Vector RAG可能性价比更高。
🟦 六、核心算法与数据结构拆解:双图谱是如何“生长”的?
在前文中,我们探讨了RAG-Anything的宏观架构。作为技术人员,我们更关心的是:这套机制在代码和数据结构层面是如何落地的?双图谱并非凭空产生,它是一套严密的算法流程。
6.1 跨模态图谱的构建逻辑
跨模态图谱(Cross-modal Graph)的构建本质上是一个基于规则与启发式算法的确定性过程。它不依赖玄学的模型预测,而是依赖文档的物理属性。
6.1.1 节点定义 (Node Schema)
在图数据库(如Neo4j)中,我们需要定义清晰的Schema。RAG-Anything的节点设计如下:
Document Node:根节点,代表整个文件。
Page Node:页码节点,用于维护物理顺序。
Text Block Node:属性包含
content(文本内容),bbox(边界框坐标),font_size(字号,用于判断标题层级)。Image Node:属性包含
image_path,detailed_desc(VLM生成的描述),summary(实体摘要),bbox。Table Node:属性包含
html_repr(HTML表示),markdown_repr,caption(表头)。Sub-Image Node:针对多子图(Multi-panel)情况,将大图拆解为子节点。
6.1.2 边构建算法 (Edge Construction Algorithm)
边的构建遵循一套优先级逻辑:
显式引用检测 (Explicit Reference Detection):
利用正则表达式(Regex)扫描文本块。
模式匹配:
/(Figure|Fig\.|Table|Tab\.|Eq\.)\s*(\d+)/i。一旦匹配,立即建立
MENTIONS边:TextNode -[MENTIONS]-> ImageNode/TableNode。
空间邻近匹配 (Spatial Proximity Matching):
计算所有非文本节点(图/表)的边界框
bbox_target。搜索其上下方距离
delta_y < Threshold范围内的文本块。如果文本块内容包含 "Figure" 或 "Table" 等关键词,判定为 Caption。
建立
HAS_CAPTION边:ImageNode -[HAS_CAPTION]-> TextNode。
层级归属 (Hierarchical Belonging):
基于字号和缩进分析文档树(Document Tree)。
建立
BELONGS_TO边,将图表归属到最近的章节标题(Section Header)下。
6.2 语义图谱的实体对齐技术
语义图谱(Semantic Graph)的构建则是一个概率性过程,依赖LLM的理解能力。最关键的步骤是实体对齐(Entity Alignment),即如何判断两个不同模态中的“苹果”是同一个“苹果”。
6.2.1 实体抽取与标准化
系统首先对文本和图表描述进行实体抽取(NER)。
文本:“Apple公司的Q3营收增长...” -> 实体:Apple, Q3, 营收。
图表描述:“图表显示科技巨头AAPL在第三季度的收入...” -> 实体:AAPL, 第三季度, 收入。
这里存在一个巨大的挑战:指代不一致。Apple 和 AAPL,Q3 和 第三季度,营收 和 收入。
6.2.2 模糊对齐算法
RAG-Anything 采用了一种混合对齐策略:
基于Embedding的软对齐:
计算实体词向量的余弦相似度。
Sim(Vec("Apple"), Vec("AAPL")) > 0.85-> 判定为同一实体。
基于LLM的推理对齐:
对于置信度在阈值边缘的实体对,通过Prompt询问LLM:“在金融上下文中,'Top-line'和'Revenue'是指同一个概念吗?”
如果是,建立
SAME_AS边,将两个图谱中的节点缝合。
这种对齐机制是RAG-Anything能够进行跨模态推理的基石。没有这一步,图谱就是两张皮,无法形成合力。
🟨 七、典型案例的全链路追踪:像侦探一样解题
%20拷贝.jpg)
为了更直观地理解这套系统的威力,我们复盘几个论文中提到的极端案例(Corner Cases)。这些案例在传统RAG中几乎必挂无疑。
7.1 案例一:多子图(Multi-panel Charts)的精准定位
场景:一篇计算机视觉论文,Figure 2 包含 (a)(b)(c)(d) 四个子图,分别展示了不同模型的聚类效果。
用户提问:“根据图2,哪个模型的样式空间显示了更清晰的分离?”
传统RAG的失败路径:
检索到 Figure 2 的整体描述:“展示了四个模型的聚类对比”。
LLM 看着这张大图,分不清哪个子图对应哪个模型,或者因为分辨率压缩看不清细节。
结果:胡乱猜测或回答“图中显示了多个模型”。
RAG-Anything的成功路径:
原子化拆解:在预处理阶段,系统识别出 Figure 2 是一个组合图,将其切割为 4 个 Sub-Image Node,并分别提取其子标题((a) Baseline, (b) DAE...)。
图谱导航:
用户问题触发关键词“样式空间”、“分离”。
系统在图谱中搜索与“分离(Separation)”语义最相关的子图节点。
发现子图 (b) 的详细描述中包含“clusters are well separated”。
精准回答:“DAE模型(对应子图b)显示了更清晰的分离。”
核心差异:将图像的内部结构也变成了图谱的一部分,实现了“像素级的语义索引”。
7.2 案例二:超大财务表格的行列交叉检索
场景:诺和诺德(Novo Nordisk)2020年财报,包含一个跨页的巨型表格,列出了几十个国家的分公司在不同科目的支出。
用户提问:“新诺德2020年在工资和薪酬上的总支出是多少?”
传统RAG的失败路径:
文本切片将表格切碎,表头在第10页,数据在第11页。
检索到了“26,778”这个数字,但丢失了它所属的行名“Wages and salaries”或列名“2020”。
结果:回答“未找到相关数据”或错误引用了2019年的数据。
RAG-Anything的成功路径:
结构化解析:表格被解析为图结构。
节点:
Row_Header: Wages and salaries,Col_Header: 2020,Cell_Value: 26,778。边:
Cell_Value -[HAS_ROW]-> Row_Header,Cell_Value -[HAS_COL]-> Col_Header。
逻辑推理:
定位实体:工资和薪酬 ->
Row_Header。定位实体:2020 ->
Col_Header。图遍历:寻找同时连接这两个Header节点的
Cell_Value节点。
精准锁定:唯一交点是 26,778。
单位补全:系统顺着图谱向上找到表格的元数据节点
Table_Meta,获取单位“million DKK”。最终回答:“26,778 百万丹麦克朗。”
核心差异:将表格检索从“文本匹配”升级为“坐标查询”。
🏗️ 八、企业级部署架构参考
作为架构师,如果要在公司内部落地RAG-Anything,我们需要什么样的技术栈?以下是一份基于开源生态的推荐架构。
8.1 核心技术栈选型
8.2 部署流程与优化建议
离线流水线 (Offline Pipeline):
步骤:上传PDF -> 版面分析 -> 图像/表格提取 -> VLM描述生成 -> 实体抽取 -> 图谱写入。
优化:这一步非常耗时。建议使用**消息队列(Kafka/RabbitMQ)**进行异步处理,并利用GPU集群并行运行VLM任务。
在线服务 (Online Service):
步骤:用户Query -> 意图识别 -> 并行检索(图+向量) -> 重排序 -> LLM生成。
优化:**缓存(Redis)**至关重要。对于高频查询的实体路径,可以直接缓存检索结果,避免重复进行昂贵的图遍历。
成本控制 (Cost Control):
Token消耗:VLM生成详细描述会消耗大量Token。
策略:仅对包含关键信息(如带有数据的图表)的图片调用GPT-4o,对于装饰性图片(如Logo、背景图)直接过滤或使用轻量级模型。
🔮 九、未来演进与局限性思考
%20拷贝.jpg)
RAG-Anything虽然强大,但并非终局。站在行业发展的角度,我们能看到它的局限与未来方向。
9.1 当前的局限性
预处理延迟高:构建双图谱的计算量是传统RAG的10倍以上。对于实时性要求秒级的场景(如新闻流处理),目前架构显得过于笨重。
对OCR极其敏感:如果OCR把“8000”识别成“3000”,图谱中的逻辑再完美,答案也是错的。这是所有文档智能系统的阿喀琉斯之踵。
图谱爆炸:在处理百万级文档时,图谱的节点数和边数会呈指数级增长,导致图遍历性能下降。需要引入图剪枝(Graph Pruning)和子图聚类技术。
9.2 未来的方向:Agentic RAG
RAG-Anything目前的检索还是相对静态的。未来,它将向 Agentic RAG(代理式RAG) 演进。
自我修正:当检索结果不一致时(如文本说增长,图表显示下降),Agent能够自主发起“反思”,重新检查数据源,甚至调用外部工具(如Python解释器)对表格数据进行重新计算验证。
端到端训练:目前的图谱构建是分阶段的(Pipeline)。未来可能会出现端到端的模型,直接输入PDF,内部隐式构建图结构,输出答案,不再需要显式的图数据库。
🔚 结论:重塑机器的认知粒度
回顾RAG-Anything的设计哲学,它其实是在解决一个核心问题:机器认知的粒度。
第一代RAG的粒度是“Chunk”(文本块),它是线性的、破碎的。
RAG-Anything将粒度细化到了“Atom”(信息原子),并用“Graph”(关系)将其重新编织。
这种转变,让AI从“关键词匹配者”进化为了“结构化阅读者”。它开始理解,图表不是文本的附庸,而是数据的另一种语言;表格不是字符的堆砌,而是逻辑的矩阵。
对于企业而言,如果你的知识库中沉睡着大量高价值的PDF图纸、财报、技术手册,RAG-Anything提供了一把唤醒这些沉睡数据的钥匙。它虽然昂贵,虽然复杂,但它能让你听见数据深处的声音。
📢💻 【省心锐评】
别再迷信“万物皆Embedding”了。向量能搞定相似度,但搞不定逻辑。图谱+向量的混合架构,才是通往认知智能的必经之路。

评论