.png)


【摘要】多模态提示词2.0时代,AI模型通过图文混合等跨模态指令,极大提升了理解、推理与生成能力,推动智能应用在医疗、制造、文娱等领域深度落地。本文系统梳理多模态指令的技术原理、提示设计、行业案例、能力机制与未来趋势,全面展现其激发AI潜能的路径与挑战。
引言
人工智能正经历一场深刻的范式变革。过去,AI模型多以单一模态(如文本、图像)为主,难以应对现实世界中多感官、多维度的信息交互需求。随着大模型技术的飞跃,多模态AI应运而生,成为推动智能社会进化的核心动力。多模态指令,尤其是图文混合提示,正成为激发AI模型潜能的关键引擎。它不仅让AI“能说会写”,更让其“能看会听、能推理、能创造”,在医疗、制造、文娱、教育等领域释放出前所未有的价值。
本文将系统梳理多模态指令的核心原理与技术进化,深入解析图文混合提示的设计技巧,结合丰富的行业案例,剖析多模态生成能力提升的机制,展望其未来发展趋势,并对当前面临的挑战进行深度剖析。希望为技术开发者、行业决策者和AI爱好者提供一份兼具深度与广度的参考。
一、多模态指令的核心原理与技术进化
%20拷贝.jpg)
1.1 多模态指令的本质与价值
多模态指令的核心在于利用不同模态(如文本、图像、音频、视频等)信息的互补性,实现更接近人类多感官认知的信息处理。与传统单一文本提示相比,多模态提示词能让模型结合视觉、听觉等多维数据,极大提升对复杂场景的理解、推理与生成能力。
1.1.1 多模态信息的互补性
视觉与文本互补:图像提供空间、结构、色彩等直观信息,文本则补充语义、背景、逻辑等抽象内容。
音频与视频增强:音频可传递情感、语调,视频则融合时序与动态,丰富场景理解。
多感官融合:多模态指令让AI具备“看、听、说、写”全方位能力,接近人类认知。
1.1.2 多模态AI的行业价值
医疗诊断:融合影像与病历,提升诊断准确率。
智能制造:结合设备图像与工艺参数,实现自动质检。
内容创作:图文、音视频协同生成,丰富创作形式。
教育与科研:多模态交互提升教学与科研效率。
1.2 技术架构革新
多模态AI的崛起,离不开底层技术架构的持续创新。当前主流多模态大模型在统一表征、跨模态穿透、注意力机制、小样本泛化、视觉参考提示等方面取得了突破。
1.2.1 统一表征与跨模态穿透
主流多模态大模型(如GPT-4V、Gemini、文心大模型4.5Turbo)采用统一的Transformer架构,将文本、图像、视频等多种模态数据映射到同一高维空间,实现联合编码与推理。这种架构不仅提升了多模态理解效果,还大幅提高了模型的学习效率和泛化能力。
1.2.2 跨模态注意力机制
以中科院紫东太初模型为代表,通过多层自监督学习和跨模态注意力机制,模型能够实现“以文搜图”“以图生音”等复杂任务。注意力机制让模型在处理多模态输入时,能够动态聚焦于关键信息,实现更精准的理解与生成。
1.2.3 小样本泛化与符号推理增强
Meta Flamingo模型通过适配器机制,支持少样本学习,显著提升了模型在新任务、新领域下的泛化能力。微软KOSMOS-2.5则结合数学公式解析与符号推理,攻克了图表理解等高难度多模态任务。
1.2.4 视觉参考提示与动态适配
微软提出的“视觉参考提示”技术,通过在输入图像上直接编辑、标注任务区域,模型能够精准理解用户意图,提升对细节的把控和任务执行的精准性。这一技术在医疗影像、工业质检等场景表现尤为突出。
1.2.5 技术架构演进流程图
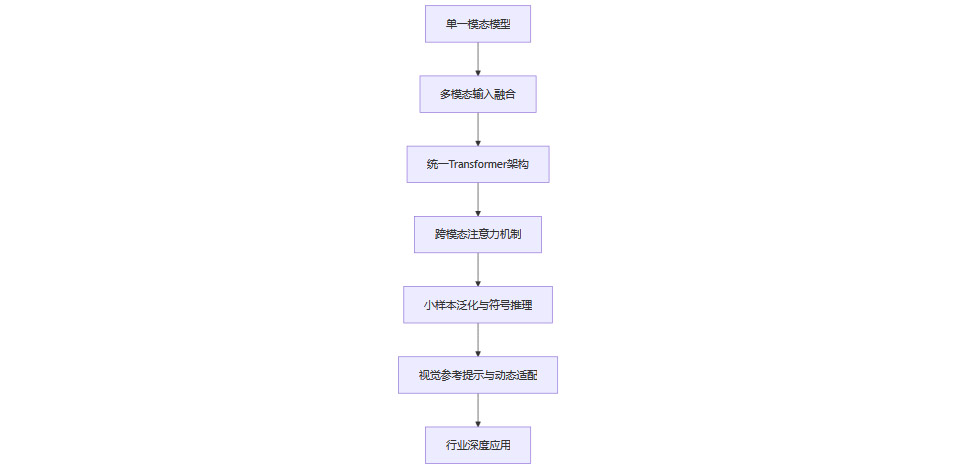
1.3 多模态模型能力提升的关键机制
模态间信息互补:视觉、文本等模态互补,弥补单一模态的局限,提升任务理解的全面性。
跨模态穿透与推理能力提升:多模态训练不仅提升图像理解,还反哺文本推理能力。例如,Align-DS-V模型在文本任务上的表现大幅提升。
动态适配与个性化输出:模型可根据输入模态特性动态调整输出策略,实现更个性化和精准的响应。
二、图文混合提示技巧与设计原则
2.1 图文混合提示的设计原则
多模态提示词的设计直接影响模型的表现。有效的图文混合提示应遵循以下原则:
2.1.1 清晰明确的指令
明确告知模型任务目标,减少歧义。
示例:“请根据下图内容生成描述”或“指出图片中红色区域的物品名称”。
2.1.2 结构化与分步提示
通过分步骤引导模型处理图文信息,提升输出的条理性和准确性。
示例:“第一步,请描述图片整体内容;第二步,指出图片中的异常区域。”
2.1.3 角色扮演与示例法
赋予模型特定身份(如医生、艺术评论家),或提供输入输出示例,增强专业性和针对性。
示例:“假如你是一名放射科医生,请分析下图CT影像。”
2.1.4 视觉指针与标记法
在图片上标注、圈选区域,或用视觉指针指明关注点,提升模型对细节的理解。
示例:在图片上用红框标出疑似病灶区域,提示模型重点分析。
2.1.5 上下文补充
在视觉问答等任务中,补充背景信息或具体问题,有助于模型更精准地理解和生成内容。
示例:“患者男性,45岁,有吸烟史。请结合下图CT影像分析可能的肺部病变。”
2.2 图文混合提示技巧表
2.3 图文混合提示设计流程
明确任务目标与输出要求
选择合适的模态组合(文本+图像/音频/视频)
设计结构化、分步、角色扮演等提示方式
对关键区域进行视觉标注或指针提示
补充必要的上下文信息
反复测试与优化,提升模型响应质量
三、跨模态生成效果提升的典型案例
%20拷贝.jpg)
3.1 内容创作与娱乐
3.1.1 动态人像生成
抖音平台的动态人像生成技术,结合UNet、LSTM等模块,实现4K视频中环境与表情的毫米级仿真,获得数百万点赞。用户上传照片并输入文本描述,AI可自动生成高质量短视频,极大丰富了内容创作形式。
3.1.2 智能漫画与分镜生成
AI根据用户上传的草图和剧情文本,自动生成漫画分镜、角色表情和对白,提升漫画创作效率,降低门槛。
3.2 医疗诊断
3.2.1 多模态肺癌分期与报告生成
百度与武汉AI研究院合作,利用CLIP和BERT模型融合CT图像与病历文本,肺癌分期准确率提升18.7%,并能自动生成诊断报告和治疗建议。医生上传影像和病历,AI辅助分析,提升诊断效率与准确性。
3.2.2 远程医疗与辅助决策
多模态AI支持远程医疗场景,医生可通过上传影像、语音问诊记录,AI自动生成初步诊断和建议,缓解医疗资源不均问题。
3.3 非遗与文化保护
3.3.1 文物讲解与数字化
百度文心大模型与中国文物交流中心、上海体育大学合作,实现文物讲解、武术动作3D建模与实时纠错,提升文化传播与非遗传承效率。用户上传文物图片并提问,AI结合图文信息进行科普讲解、历史溯源。
3.3.2 文化遗产3D建模
AI根据图片、视频和文本描述自动生成高精度三维模型,助力文物数字化保护与展示。
3.4 电商与零售
3.4.1 商品识别与推荐
淘宝“拍立淘”通过图像+文本提示实现商品识别,转化率提升27%。用户拍照上传商品图片,AI结合文本描述自动识别商品并推荐相似产品。
3.4.2 智能客服与内容生成
AI根据商品图片和用户问题,自动生成商品卖点文案、情感分析,提升客服效率和用户体验。
3.5 工业质检与制造
3.5.1 设备缺陷检测
三一重工视觉-文本联合提示系统将设备缺陷检测误报率从12%降至3.5%,提升质检效率。工人上传设备照片并输入工艺参数,AI自动识别缺陷并生成检测报告。
3.5.2 智能制造与自动化
多模态AI结合图像、文本、语音等多模态输入,实现生产线自动化控制与异常预警,提升制造业智能化水平。
3.6 智能数字人/虚拟助手
多模态大模型驱动的数字人实现语言、表情、动作的高度协同,提升直播、客服、教育等场景的交互体验。数字人可根据用户输入的文本、图片、语音等多模态信息,做出自然、个性化的回应。
3.7 智能驾驶与3D建模
自动驾驶系统融合多模态数据(摄像头图像、雷达数据、地图文本等)提升环境感知,AI可根据多模态输入自动生成高精度三维模型,助力智能驾驶与智慧城市建设。
四、多模态指令激发模型潜能的机制
4.1 模态间信息互补与协同
多模态AI的强大能力,根植于不同模态信息的互补性。视觉、文本、音频等模态各自具备独特的信息表达优势,协同后能极大弥补单一模态的局限。
视觉补充空间与结构:图像为AI提供空间布局、色彩、形状等直观信息,尤其在医学影像、工业质检、自动驾驶等场景中不可替代。
文本强化语义与逻辑:文本则承载背景、逻辑、情感等抽象信息,帮助AI理解场景背后的深层含义。
音频与视频增强时序与情感:音频可传递语调、情绪,视频则融合时序动态,提升AI对复杂事件的理解能力。
通过多模态指令,AI模型能够在不同模态间建立高效的信息流动与协同机制,实现“1+1>2”的能力跃迁。例如,在医疗场景中,模型不仅能识别CT影像中的异常,还能结合病历文本推断病因、生成个性化诊疗建议。
4.2 跨模态穿透与推理能力提升
多模态训练不仅提升了模型的图像理解能力,还显著反哺了文本推理能力。这一现象被称为“模态穿透”效应。研究表明,经过多模态训练的模型,在纯文本任务(如复杂推理、数学题解答等)上的表现也有大幅提升。
案例:Align-DS-V模型
该模型在多模态训练后,ARC-Challenge等文本推理任务的成绩显著提升,显示出多模态学习对模型通用推理能力的正向促进作用。机制分析
多模态训练促使模型在高维空间中建立更丰富的语义关联,提升了对抽象概念、复杂逻辑的理解能力。这种能力的提升不仅体现在多模态任务上,也反映在单一模态的推理与生成中。
4.3 动态适配与个性化输出
多模态AI具备根据输入模态特性动态调整输出策略的能力,实现更个性化和精准的响应。
动态适配:模型可根据输入的模态类型(如文本+图像、文本+音频等),自动选择最优的处理路径和生成方式。
个性化输出:结合用户历史、场景上下文,生成符合个体需求的内容。例如,教育场景下,AI可根据学生上传的作业图片和文本描述,给出针对性的批改建议。
4.4 多模态能力提升的流程图
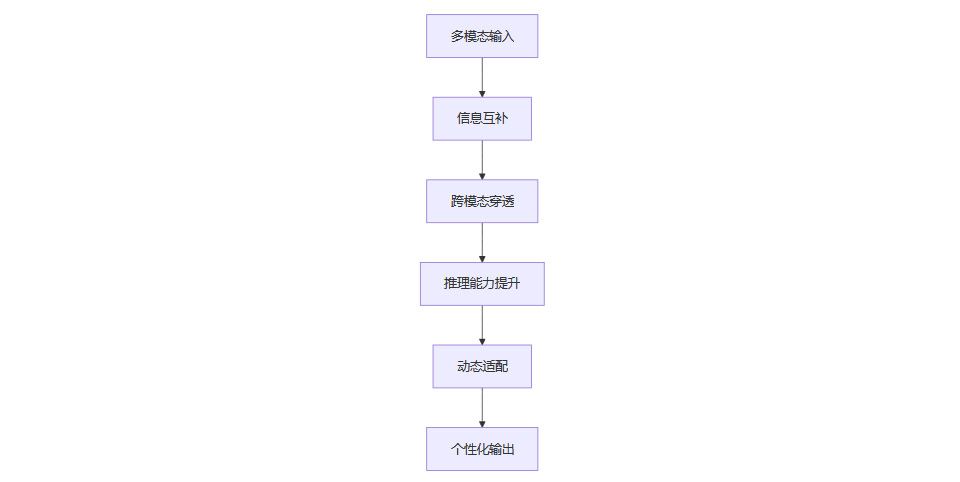
五、行业落地、挑战与未来趋势
%20拷贝.jpg)
5.1 行业落地:多模态AI的广泛应用
多模态大模型已在文娱、医疗、制造、教育、金融、智慧城市等领域实现深度落地,推动产业智能化升级。
5.1.1 行业应用场景一览表
5.1.2 行业落地典型案例
医疗健康:多模态AI辅助医生分析影像与病历,提升肺癌分期准确率18.7%,自动生成诊断报告。
制造质检:三一重工多模态系统将设备缺陷检测误报率降至3.5%,大幅提升质检效率。
文娱创作:抖音动态人像生成技术实现4K视频仿真,内容点赞量突破百万。
电商零售:淘宝“拍立淘”多模态识别转化率提升27%,阿里云“通义千问VL-Max”在K12教育场景中提升抽象概念理解效率60%。
5.2 主要挑战
尽管多模态AI展现出巨大潜力,但在实际应用中仍面临诸多挑战:
5.2.1 模型幻觉与数据偏差
幻觉问题:多模态模型在复杂场景下可能出现输出与输入不符的“幻觉”现象,影响结果可信度。
数据偏差:不同机构、不同来源的数据存在分布差异。例如,医疗数据跨机构差异高达41%,影响模型泛化能力。
5.2.2 计算成本与效率
高算力需求:高分辨率图像、长视频等多模态任务对算力要求极高,训练与推理成本大。
技术应对:新技术如MoE(专家混合)、动态稀疏化等正努力降低成本,提高效率。
5.2.3 可信性与安全性
对抗攻击风险:多模态模型在对抗攻击下鲁棒性不足,易被恶意输入误导。
可解释性不足:模型决策过程复杂,缺乏透明度,影响用户信任。
5.2.4 标准与伦理
行业标准缺失:多模态AI的评测标准、数据标注规范尚不完善。
伦理治理滞后:数据隐私、内容安全、算法歧视等问题亟需行业共识与监管。
5.3 未来趋势
多模态AI正加速迈向更高智能水平,未来发展趋势主要体现在以下几个方面:
5.3.1 提示词自优化
通过细化和优化指令,显著提升模型任务表现。例如,焊接安全识别准确率从68%提升至92%。
5.3.2 具身智能与低耗能部署
多模态机械臂、边缘计算等推动AI在终端设备普及,实现低能耗、高效率的智能应用。
5.3.3 全模态对齐与“模态穿透”
多模态训练反哺单模态能力,推动AI向通用智能(AGI)迈进。
5.3.4 实时处理与智能体融合
多模态AI将与智能体技术深度融合,支持更自然的人机交互和实时响应。
5.3.5 未来趋势流程图

结论
多模态提示词2.0时代,图文混合等跨模态指令极大激发了AI模型的潜能,推动AI从“能说会写”向“能看会听、能推理、能创造”跃迁。无论是在医疗、制造、文娱、教育还是智慧城市等领域,多模态AI都展现出强大的落地能力和变革潜力。其背后的技术进化——统一表征、跨模态穿透、动态适配、提示词优化等——为AI模型赋予了前所未有的理解与生成能力。
然而,幻觉、算力、数据偏差、安全与伦理等挑战依然严峻。只有持续优化模型架构、完善行业标准、加强数据治理和伦理监管,才能让多模态AI真正成为智能社会的核心驱动力。未来,随着提示词设计的科学化、模型架构的持续创新和行业标准的逐步完善,多模态AI有望加速迈向通用人工智能(AGI)时代,重塑人机协作范式,开启智能社会新纪元。
📢💻 【省心锐评】
“多模态AI不是简单的技术堆砌,而是认知维度的升维竞争。谁掌握跨模态穿透能力,谁就握住了智能时代的钥匙。”

评论