.png)
-yffr.jpg)

【摘要】Transformer架构自2017年问世以来,已成为AI领域的核心基石。本文系统梳理其十年演进,从NLP到多模态通用底座,深度剖析技术突破、产业落地、未来趋势与挑战,全面展望其在具身智能、边缘计算等新兴领域的广阔前景。
引言
2017年,Google团队提出的“Attention is All You Need”论文,首次将Transformer架构带入大众视野。短短十年间,Transformer不仅彻底颠覆了自然语言处理(NLP)领域,更以惊人的速度渗透到计算机视觉(CV)、多模态学习、具身智能、边缘计算等众多前沿领域。如今,Transformer已成为AI技术的“通用底座”,支撑着从智能助手、自动驾驶到医疗影像分析等多元应用场景。本文将以技术演进为主线,系统梳理Transformer架构的里程碑式突破、产业落地、最新研究进展与未来趋势,深入探讨其在多模态、具身智能、边缘计算等新兴领域的创新与挑战,并对其社会影响与伦理问题进行全面剖析。
一、Transformer技术演进路径回顾

1.1 萌芽与NLP革命(2017-2018)
1.1.1 Transformer的诞生与自注意力机制
Transformer架构的核心创新在于自注意力机制(Self-Attention),它能够高效捕捉序列中任意位置之间的依赖关系,极大提升了模型对长距离信息的建模能力。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer在并行计算、建模能力和扩展性方面展现出显著优势。
1.1.2 预训练模型的崛起
BERT(Bidirectional Encoder Representations from Transformers)模型的提出,标志着预训练-微调范式的兴起。BERT通过大规模无监督语料预训练,显著提升了下游NLP任务的表现。与此同时,OpenAI的GPT系列模型以生成式预训练为核心,推动了自然语言生成、对话系统等领域的突破。GPT-3拥有1750亿参数,成为当时最大规模的语言模型,验证了“Scaling Law”(规模定律)在Transformer架构下的有效性。
1.1.3 关键技术节点
2017年:Transformer架构首次提出,开启NLP新纪元。
2018年:BERT横空出世,刷新多项NLP基准任务纪录。
2018-2020年:GPT系列持续迭代,推动生成式AI浪潮。
1.2 爆发与跨模态探索(2019-2021)
1.2.1 视觉领域的突破
Vision Transformer(ViT)首次将Transformer应用于图像分类任务,通过将图像划分为Patch并序列化处理,实现了对全局特征的高效建模。ViT在ImageNet等主流数据集上超越了传统CNN,掀起了视觉领域的“Transformer化”浪潮。
1.2.2 多模态能力的崛起
CLIP模型通过联合训练文本和图像,实现了跨模态检索与理解。DALL·E则展示了文本生成图像的能力,推动了AI在内容生成、艺术创作等领域的应用。多模态Transformer模型的出现,标志着AI从单一模态向多模态、跨模态智能迈进。
1.2.3 模型规模化与硬件协同
随着模型参数规模的不断扩大,分布式训练框架(如Megatron-LM)和专用AI芯片(如NVIDIA H100、华为昇腾910B)应运而生,为大模型训练和推理提供了强有力的硬件支撑。
1.2.4 关键技术节点
2020年:ViT模型问世,Transformer进军视觉领域。
2021年:CLIP、DALL·E等多模态模型发布,AI能力大幅拓展。
2021年:分布式训练与AI芯片加速大模型落地。
1.3 多模态扩展与通用底座形成(2022-2023)
1.3.1 统一多模态架构
PaLM-E等模型将语言、视觉、传感器数据融合,支持机器人等复杂任务。Meta的ImageBind实现了六种模态的统一对齐,推动了多模态AI的进一步发展。
1.3.2 轻量化与边缘适配
为适应移动端和物联网场景,MobileViT、MobileVLM等轻量级Transformer模型应运而生。通过模型剪枝、量化、蒸馏等技术,参数量被压缩至10亿以下,实现了端侧高效推理。
1.3.3 开源生态与产业繁荣
Llama 3、Gemini 1.5等大模型的开源,极大促进了AI生态的繁荣与多模态能力的普及。开源社区的活跃推动了Transformer技术的快速迭代与广泛应用。
1.3.4 关键技术节点
2022年:PaLM-E、ImageBind等多模态统一模型发布。
2022-2023年:轻量化Transformer模型适配边缘设备。
2023年:Llama 3、Gemini 1.5等大模型开源,生态繁荣。
1.4 通用智能底座与垂直场景落地(2024-)
1.4.1 行业专用大模型
Transformer架构已广泛应用于医疗、金融、自动驾驶等垂直行业。Med-PaLM 2专注医疗问答,BloombergGPT服务金融领域,Tesla HydraNet赋能自动驾驶决策。
1.4.2 多模态生成与三模态统一
Runway Gen-2、Stable Diffusion 3等模型支持视频生成,底层依赖Transformer变体。GPT-4o、Gemini 1.5 Pro等实现了文本、图像、音频的三模态统一理解与生成,推动AI向通用智能迈进。
1.4.3 关键技术节点
2024年:行业专用大模型加速落地。
2024年:三模态统一模型推动AI通用智能发展。
二、多模态通用底座的形成与案例分析
2.1 Transformer成为AI基础架构的原因
2.1.1 架构通用性与可扩展性
Transformer的自注意力机制天然适用于处理序列数据,无论是文本、图像还是音频,都可以通过适当的编码方式输入模型。这种高度的通用性,使得Transformer能够作为多模态AI的基础架构。
2.1.2 并行计算与高效训练
Transformer摒弃了RNN的时序依赖,支持大规模并行计算,极大提升了训练效率。随着硬件性能的提升,Transformer模型的参数规模得以不断扩展,能力边界持续突破。
2.1.3 预训练-微调范式的成功
大规模预训练模型通过无监督学习掌握通用知识,再通过微调适配具体任务,极大提升了模型的泛化能力和迁移能力。这一范式已成为AI领域的主流。
2.1.4 多模态融合能力
Transformer架构能够灵活融合多种模态信息,实现跨模态理解与生成。通过联合训练和对齐机制,模型能够在文本、图像、音频等多模态间建立深层联系。
2.2 典型多模态通用底座案例
2.2.1 GPT-4o与Gemini 1.5 Pro
GPT-4o和Gemini 1.5 Pro实现了文本、图像、音频的三模态统一处理,支持多轮对话、图像理解、语音识别与生成等复杂任务,成为AI通用底座的代表。
2.2.2 CLIP与DALL·E
CLIP通过对齐文本与图像嵌入,实现了跨模态检索与理解。DALL·E则展示了文本生成图像的能力,推动了AI在内容创作、艺术设计等领域的应用。
2.2.3 PaLM-E与ImageBind
PaLM-E融合语言、视觉、传感器数据,支持机器人任务。ImageBind实现六种模态的统一对齐,推动多模态AI向更高层次发展。
2.2.4 行业专用大模型
医疗:Med-PaLM 2提升医疗问答与影像分析能力。
金融:BloombergGPT服务金融文本分析与预测。
自动驾驶:Tesla HydraNet处理多传感器数据,实现自动驾驶决策。
2.2.5 轻量化与边缘适配
MobileViT、MobileVLM等轻量级模型适配移动端和物联网场景,实现端侧高效推理,推动AI普及。
三、最新进展与应用拓展

3.1 具身智能(Embodied AI)
3.1.1 机器人控制与多模态感知
Google RT-2将视觉-语言模型与机械臂结合,实现“看图做事”,无需额外训练即可完成新任务。Perceiver、Gato等模型支持多传感器输入和多任务输出,推动机器人自主感知与交互。
3.1.2 仿真环境与训练平台
Meta Habitat 3.0为具身智能训练提供物理真实的多模态环境,支持大规模仿真与评测,加速机器人智能的发展。
3.1.3 具身智能应用流程图
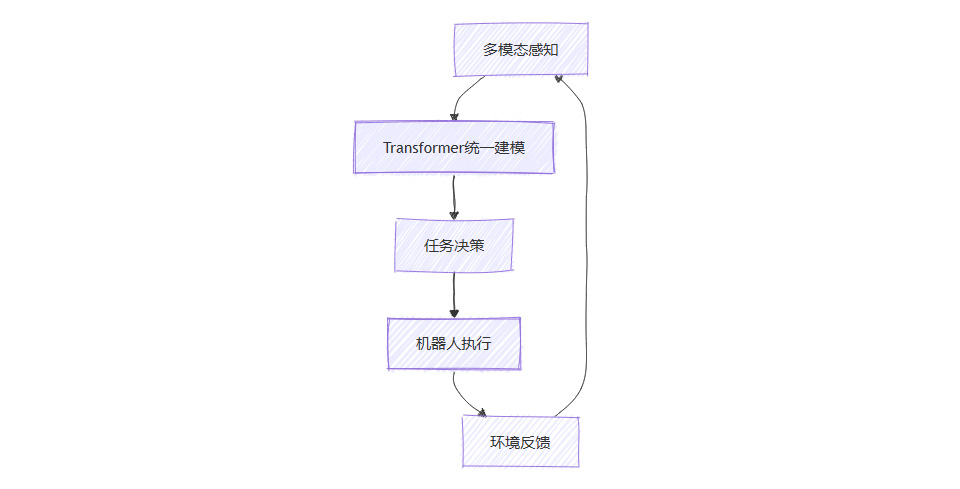
3.2 边缘计算与高效化
3.2.1 端侧推理与硬件加速
苹果A18芯片集成Transformer加速单元,iPhone可本地运行30亿参数模型。Qualcomm AI Stack支持低功耗多模态推理,推动AI在移动端和IoT场景的落地。
3.2.2 模型压缩与优化
通过剪枝、量化、蒸馏等技术,MobileBERT、Efficient Transformer等模型显著降低能耗和延迟,实现边缘设备的高效推理。
3.2.3 分布式训练与大模型扩展
Megatron-LM等分布式训练框架支持万亿参数模型的高效训练,推动大模型能力边界的持续突破。
3.2.4 边缘计算应用流程图
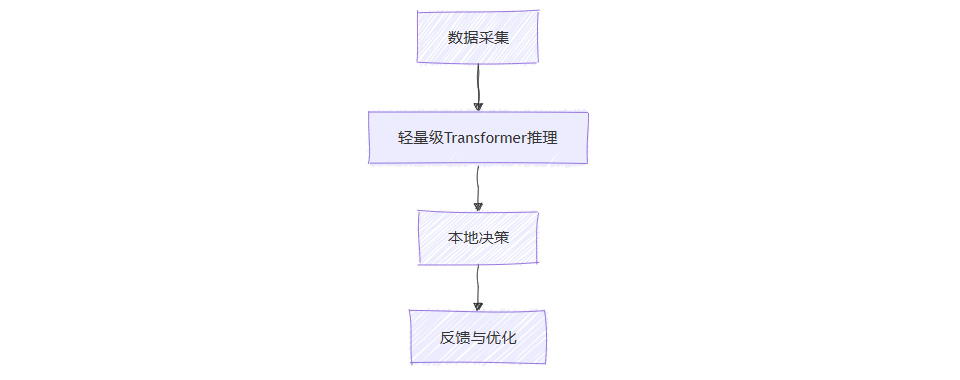
3.3 多模态与跨模态通用智能
3.3.1 统一底座支撑多元应用
Transformer作为AI通用底座,支撑搜索、智能助理、内容生成、自动驾驶等多元应用场景,实现跨模态理解与生成。
3.3.2 科学与工业领域的创新
AlphaFold 3利用Transformer预测蛋白质-配体相互作用,推动生命科学研究。西门子IndustrialGPT融合视觉与文本报告生成,提升工业质检效率。
3.3.3 行业应用案例表
3.4 行业应用案例深度剖析
3.4.1 医疗影像分析
TransUNet结合CNN与自注意力机制,提升医学图像分割精度,助力疾病诊断与治疗规划。
3.4.2 自动驾驶
Tesla利用Transformer处理多传感器数据,实现自动驾驶决策,提升安全性与智能化水平。
3.4.3 内容生成与智能助理
GPT-4o、Claude 3等多模态大模型广泛应用于智能助手、内容创作、教育等场景,极大提升了人机交互体验。
3.5 多模态生成与创新应用
3.5.1 视频与音频生成
Runway Gen-2、Stable Diffusion 3等模型基于Transformer变体,支持文本到视频、图像到视频等多模态生成任务。AI驱动的内容创作正逐步实现从文本、图像到音视频的全链路自动化,极大拓展了数字内容产业的边界。
3.5.2 智能搜索与跨模态检索
CLIP等多模态模型使得用户可以通过自然语言描述检索图片、视频等多媒体内容,极大提升了信息检索的效率和体验。跨模态检索已成为互联网平台、数字图书馆等领域的重要技术支撑。
3.5.3 智能制造与工业自动化
在工业场景中,Transformer模型被用于多模态数据融合与异常检测。例如,工业相机采集的图像与传感器数据通过Transformer统一建模,实现设备状态监测、缺陷检测和自动报告生成,提升了生产效率和质量控制水平。
3.5.4 教育与辅助决策
多模态AI助力教育个性化发展。通过分析学生的文本、语音、表情等多模态数据,智能助教能够动态调整教学策略,实现因材施教。在企业决策支持中,Transformer模型融合文本、图表、语音等多源信息,辅助高效决策。
四、技术挑战与伦理社会影响

4.1 计算资源与能耗
4.1.1 能耗问题突出
随着模型规模的不断扩大,训练和推理所需的计算资源和能耗急剧上升。例如,GPT-5等超大模型的训练能耗高达50GWh,远超普通家庭年用电量。大模型的能耗问题已成为AI可持续发展的重要挑战。
4.1.2 绿色AI与能效优化
为应对能耗挑战,学界和产业界积极探索绿色AI和能效优化策略,包括:
模型压缩:通过剪枝、量化、蒸馏等方法减少模型参数和计算量。
高效架构:开发如Efficient Transformer、MobileViT等高效模型,适配边缘设备。
硬件协同优化:AI芯片(如NVIDIA H100、苹果A18)针对Transformer进行专门优化,提升能效比。
分布式与异构计算:利用分布式训练和异构计算资源,提升大模型训练效率。
4.1.3 能效优化流程图
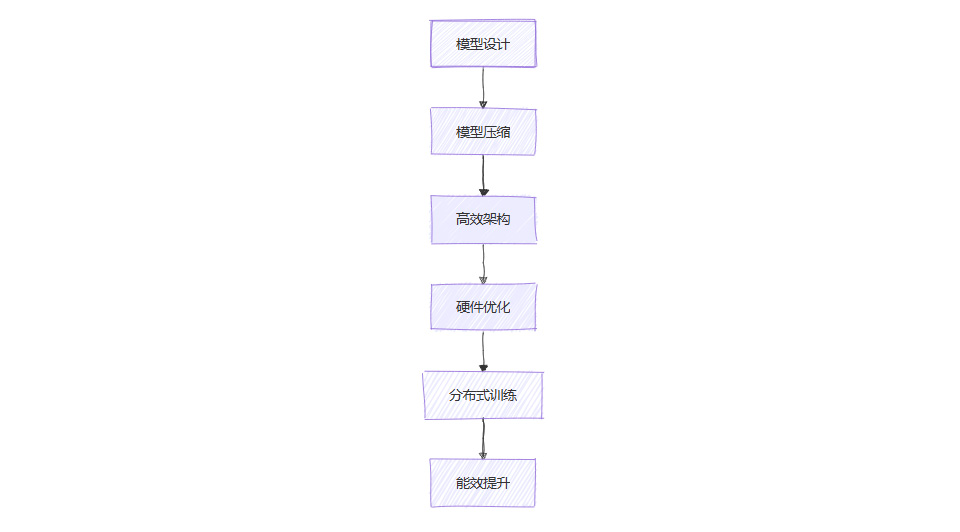
4.2 伦理与安全
4.2.1 内容检测与隐私保护
AI生成内容的检测准确率有限,尤其是在多模态生成领域。以OpenAI文本检测器为例,对GPT-4 Turbo生成内容的检测准确率仅为65%。数据隐私和可追溯性成为监管重点,欧盟AI法案等政策对高风险AI系统提出了更高的透明度和可控性要求。
4.2.2 偏见与误信息
大模型在训练过程中可能引入数据偏见,导致输出结果存在性别、种族等方面的歧视。此外,AI生成的误导性信息和“深度伪造”内容对社会信任构成挑战。提升模型可解释性、加强责任追溯成为行业共识。
4.2.3 合规与政策
欧盟《AI Act》要求高风险AI系统具备透明、可控、可追溯等特性。开源社区积极响应,推出如CleanRoBERTa等合规模型,推动AI合规发展。企业和开发者需加强数据治理、模型审计和伦理评估,确保AI系统的安全与合规。
4.2.4 伦理治理措施列表
数据去偏与多样性增强
生成内容的可追溯与水印技术
用户隐私保护与数据加密
透明度提升与可解释性增强
责任归属与合规审计
4.3 技术瓶颈与架构创新
4.3.1 能效与性能平衡
在边缘计算和移动端场景下,如何在保证模型性能的同时降低能耗,是未来AI落地的关键课题。轻量化模型和高效推理算法将持续成为研究热点。
4.3.2 新架构探索
尽管Transformer在多模态任务中占据主流地位,但新型架构如状态空间模型(Mamba)等正在崛起,试图在能效、长序列建模等方面超越Transformer。当前,这些新架构在多模态任务中的表现尚未全面超越Transformer,但为未来AI架构创新提供了新思路。
4.3.3 持续创新与生态繁荣
开源社区和产业界的持续创新推动了Transformer生态的繁荣。模型开源、数据集共享、工具链完善等举措极大降低了AI研发门槛,促进了技术的快速迭代与广泛应用。
五、未来展望
5.1 多模态统一性与通用智能
未来AI将更加强调单一架构处理无限模态组合的能力,实现真正的通用智能。Transformer作为多模态统一底座,将持续引领AI从“专用智能”向“通用智能”演进。
5.2 能效与边缘智能
Transformer将在边缘设备、低功耗场景持续优化,推动AI普及到智能手机、可穿戴设备、物联网等终端。高效模型和专用AI芯片将成为推动AI下沉的关键动力。
5.3 社会适配与伦理治理
技术发展需同步解决伦理争议、隐私保护和社会责任。AI系统的透明度、可解释性和合规性将成为产业闭环的重要组成部分。政策法规、行业标准和伦理治理体系将不断完善,保障AI健康发展。
5.4 架构创新与可持续发展
新型高效架构、绿色AI、可解释性和安全性将成为未来AI研究和产业的重点。持续的架构创新和能效优化将推动AI技术向更高水平发展,实现可持续的智能社会。
5.5 行业权威预测
Gartner等权威机构预测,到2027年,70%的企业级多模态系统将基于Transformer改进架构。Transformer的通用性和可扩展性将持续巩固其在AI生态中的核心地位。
5.6 未来发展路线图
为了更直观地展现Transformer未来的发展方向,以下以流程图形式梳理其技术演进与应用拓展的路线:

六、参考文献来源
Vaswani, A., et al. (2017). Attention is All You Need. NeurIPS. arXiv:1706.03762 [https://arxiv.org/abs/1706.03762]
Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805 [https://arxiv.org/abs/1810.04805]
Dosovitskiy, A., et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929 [https://arxiv.org/abs/2010.11929]
Radford, A., et al. (2021). CLIP. arXiv:2103.00020 [https://arxiv.org/abs/2103.00020]
OpenAI. (2024). GPT-4o Technical Report. OpenAI Blog [https://openai.com/index/gpt-4o/]
Google DeepMind. (2024). Gemini 1.5 Pro. DeepMind Blog [https://deepmind.google/technologies/gemini/]
Jaegle, A., et al. (2021). Perceiver. arXiv:2103.03206 [https://arxiv.org/abs/2103.03206]
Reed, S., et al. (2022). Gato. arXiv:2205.06175 [https://arxiv.org/abs/2205.06175]
Han, S., et al. (2021). Model Compression and Acceleration. arXiv:2106.08962 [https://arxiv.org/abs/2106.08962]
Mehta, S., et al. (2021). MobileViT. arXiv:2110.02178 [https://arxiv.org/abs/2110.02178]
Zhang, Y., et al. (2023). EdgeFormer. arXiv:2303.11309 [https://arxiv.org/abs/2303.11309]
Ouyang, L., et al. (2022). Instruction Tuning. arXiv:2203.02155 [https://arxiv.org/abs/2203.02155]
Bender, E., et al. (2021). On the Dangers of Stochastic Parrots. ACM FAccT.
MIT Tech Review (2024). The Energy Cost of AI.
欧盟AI法案、Gartner、Tesla、DeepMind、Meta、Google、OpenAI等官方报告与技术博客。
七、附录:Transformer十年发展大事记
八、结语
十年风雨兼程,Transformer架构已从学术创新走向产业主流,成为AI时代的“操作系统”。它不仅重塑了NLP、CV等传统领域,更以多模态、通用智能、绿色AI等创新引领着AI的未来。面对能耗、伦理、合规等挑战,Transformer生态正以开放、创新、责任的姿态,迈向更加智能、高效、可持续的明天。下一个十年,Transformer及其后继者,必将在AI技术与产业变革中书写新的辉煌篇章。
💬 【省心锐评】
"Transformer的十年,是AI从'专才'走向'通才'的进化史。但要让智能真正融入物理世界,我们需要的不仅是更大的模型,更是对能量、伦理与人类价值的深刻理解。"

评论