.png)
%20%E6%8B%B7%E8%B4%9D-gxmn.jpg)

【摘要】AI竞赛已转向数据争夺,DePIN通过代币激励构建去中心化数据工厂,为RDA市场提供海量可信数据。其价值链与飞轮效应,正使其成为喂养下一代AI的终极“饲料”。
引言
AI竞赛的规则变了。
当算力的轰鸣声逐渐归于平静,当模型的参数量不再是衡量智能的唯一标尺,一场更为深刻的变革正在水面下悄然发生。2025年,人工智能领域的竞争焦点,已经从“谁的肌肉更强壮”转向了“谁能吃到更精细、更营养的食物”。这食物,就是高质量、独家的真实世界数据资产(RDA, Real-World Data Asset)。
我们看到,无论是OpenAI,谷歌,还是Anthropic,这些顶尖的AI实验室都已公开承认,模型性能的下一个巨大飞跃,其瓶颈不再是算法的精妙或是算力的堆砌,而是数据本身。那些滋养了第一代大模型的公开数据集,如同一个被反复耕种的公共牧场,其养分正被迅速耗尽。AI开始表现出一种前所未有的“数据饥渴症”。
在这场寻找新“饲料”的全球竞赛中,一个源自Web3世界的概念正以惊人的速度崛起,它就是DePIN(Decentralized Physical Infrastructure Network,去中心化物理基础设施网络)。它不像传统的科技巨头那样圈地建墙,而是像蒲公英的种子,将数据生产的权力播撒到世界的每一个角落。本文将深入剖析,DePIN是如何通过其独特的机制,构建起一座座“去中心化数据工厂”,为嗷嗷待哺的AI市场,提供源源不断的海量可信数据源。
一、AI的“数据饥渴症”:从参数竞赛到数据战争
%20拷贝-gymd.jpg)
1.1 算力竞赛的黄昏
过去几年,AI的发展路径似乎清晰明了,就是一场简单粗暴的军备竞赛。模型参数量从亿级飙升至万亿级,背后是数据中心里成千上万张GPU日夜不休的燃烧。这的确带来了AI能力的巨大飞跃,让机器学会了写诗、作画、编程。
但这条路,正在走到尽头。
当所有头部玩家都能轻易获得顶级的算力资源,当模型架构的创新进入平台期,单纯增加参数量带来的边际效益开始急剧递减。就像一个学生,即便拥有全世界最好的图书馆和最快的阅读速度,如果他反复阅读的只是同一批书籍,他的认知水平终将触及天花板。AI也是如此,它需要新的知识,新的经验,而这些,只能来自于数据。
1.2 公开数据集的“天花板”
ImageNet、COCO、Common Crawl、Wikipedia,这些名字对于任何一个AI从业者都耳熟能详。它们是AI的启蒙读物,是构建起当今智能世界的基础。然而,这些公共资源的局限性也日益暴露。
同质化严重。当所有模型都基于同样的数据集进行训练,它们的世界观和能力边界也趋于一致。这导致AI产品难以形成真正的差异化优势,陷入了“你有的我也有”的同质化竞争泥潭。
保真度低下。公开数据大多是互联网上的静态文本和图片,它们是物理世界的“二手快照”,缺乏实时性、动态性和交互性。AI通过它们学习到的,是一个被简化和过滤后的世界,而不是真实物理世界的复杂与鲜活。
价值被稀释。这些数据集已被全球的研究者和公司“榨干”,其中的知识和模式已被充分挖掘。对于追求更高智能水平的顶尖AI来说,继续在这些数据上投入训练,无异于“炒冷饭”,收效甚微。
污染与操纵风险。公开数据来源复杂,易于被低质量内容、偏见甚至恶意信息污染。AI模型在学习过程中会不加分辨地吸收这些“毒素”,从而产生错误或有害的输出。
为了更直观地理解公开数据集与RDA的差异,我们可以看下面的对比。
这张表格清晰地揭示了,为什么AI的进化必须摆脱对公开数据集的依赖。
1.3 RDA的崛起:AI进化的新燃料
真实世界数据资产(RDA),正是解决AI“数据饥渴症”的良药。它指的是直接从物理世界中通过传感器、设备等物理基础设施实时捕获的数据。这些数据不再是关于世界的描述,而是世界本身在数字空间的实时映射。
想象一下,一个用于自动驾驶的AI,它需要的不是几百万张互联网上的汽车图片,而是此时此刻,纽约第五大道每个路口的实时车流量、信号灯状态、行人移动轨迹。一个用于精准农业的AI,它需要的不是教科书上的气象知识,而是这片农田过去72小时内,每平方米的土壤湿度、光照强度和温度变化。
这些数据具备公开数据集无法比拟的价值。
高时效性,让AI能够理解和预测动态变化的世界。
高保真度,让AI的决策更贴近物理现实。
独家性,让拥有它的公司能够训练出具备独特能力的AI模型,构筑坚实的竞争壁垒。
麦肯锡的一份报告预测,全球对高质量AI数据的需求将呈现指数级增长,但其供给速度却远远落后。这种巨大的供需缺口,为RDA市场创造了前所未有的机遇。而DePIN,正是为填补这一缺口而生的。
二、DePIN的角色:一座座拔地而起的“去中心化数据工厂”
如果说RDA是喂养AI的“鱼子酱”,那么DePIN就是捕捞和生产这种珍贵食材的“去中心化数据工厂”。它用一种全新的范式,解决了传统数据采集模式中成本高昂、覆盖有限、激励不足的核心痛痛点。
2.1 什么是DePIN?
DePIN,全称去中心化物理基础设施网络,其核心逻辑异常简洁而强大。
它通过代币经济学(Tokenomics),激励全球范围内的个人或小企业,贡献出他们拥有的物理设备(硬件)资源,共同构建并维护一个服务于特定目的的基础设施网络。
在这个模型中,网络的建设者和所有者不再是某个中心化的公司,而是成千上万个分布在全球各地的普通用户。用户贡献了硬件和由硬件产生的数据,网络则以其原生代币作为回报。这种“贡献即挖矿”(Contribute-to-Earn)的模式,极大地调动了大众参与的积极性。
2.2 DePIN的数据生产模式
让我们通过几个已经成功运作的DePIN项目,来具体感受这种数据生产模式的力量。
Hivemapper(去中心化地图网络)
运作方式:全球数万名司机在他们的车上安装了Hivemapper的专用行车记录仪。当他们开车时,记录仪会自动捕捉道路街景图像,并上传至网络。
数据产出:这些图像被AI处理后,拼接成一个覆盖全球、实时更新的3D街景地图。每一条新的道路、每一个新开的店铺,都能被迅速捕捉。
激励机制:司机根据他们绘制的地图区域的新颖度和覆盖范围,获得HONEY代币奖励。
DIMO(去中心化车辆数据网络)
运作方式:车主购买一个小型OBD(车载诊断系统)设备,插入汽车的诊断端口。这个设备可以读取并上传车辆的各种遥测数据。
数据产出:包括车辆的实时速度、GPS位置、发动机状态、电池健康度(对电动车尤其重要)、行驶里程等匿名化数据。
激励机制:车主根据其贡献数据的质量和频率,每周获得DIMO代币奖励。这些汇集的数据对保险、二手车估价、维修保养、智慧交通等行业价值巨大。
WeatherXM(去中心化气象网络)
运作方式:用户在全球各地购买并部署小型的WeatherXM气象站。这些设备可以实时收集所在地的温度、湿度、气压、风速等气象数据。
数据产出:数以万计的气象站共同编织了一张分辨率极高的全球气象数据网,其精度远超传统气象机构依赖少数站点的预测模型。
激励机制:气象站所有者根据其设备在线时长和数据有效性,获得WXM代币奖励。
下表总结了这些典型的DePIN项目。
这些项目清晰地展示了DePIN如何将全球闲置的物理资源,转化为持续产出高价值RDA的自动化工厂。
2.3 DePIN的独特优势
与传统的、由中心化公司主导的数据采集方式相比,DePIN模式展现出多方面的天然优势。
极低的部署成本。DePIN网络将硬件成本和部署人力分散给了全球数百万用户,网络的发起方无需承担庞大的资本开支。用户购买硬件的动机,来自于未来获得代币奖励的预期。
惊人的扩展速度与覆盖广度。一个有吸引力的代币模型,可以像病毒一样在全球传播,驱动网络在短时间内实现指数级增长。这使得DePIN网络能够轻松渗透到传统公司难以触及的偏远地区,实现真正意义上的全球覆盖。
强大的抗审查与鲁棒性。由于网络节点分布在全球,没有中心服务器可以被关闭,也没有单一实体可以控制整个网络。这使得网络具有极强的生命力和抗风险能力。
数据来源的多样性。数据由不同地区、不同背景、不同使用习惯的用户贡献,天然地避免了单一来源可能带来的系统性偏见,为AI训练提供了更加丰富和平衡的数据集。
打破数据垄断。在传统模式下,数据通常被少数科技巨头所垄断。DePIN通过区块链技术,将数据所有权和收益权在一定程度上返还给数据生产者,并通过去中心化的市场进行公平交易,避免了“数据霸权”的形成。
正是这些优势,让DePIN成为了当前环境下,生产大规模、高质量RDA的最可行、最高效的路径。它不是对现有模式的改良,而是一场彻底的范式革命。
三、DePIN的数据价值链:从原始比特到黄金RDA
%20拷贝-gsjp.jpg)
DePIN网络并不仅仅是原始数据的搬运工。如果把原始数据比作未经提炼的原油,那么DePIN网络本身,就是一个高效且自动化的“数据炼油厂”。它拥有一套完整的价值链,能将混杂的原始比特,一步步加工成可供AI直接使用的、标准化的“黄金”数据产品。
这个过程,我们可以拆解为四个关键步骤。
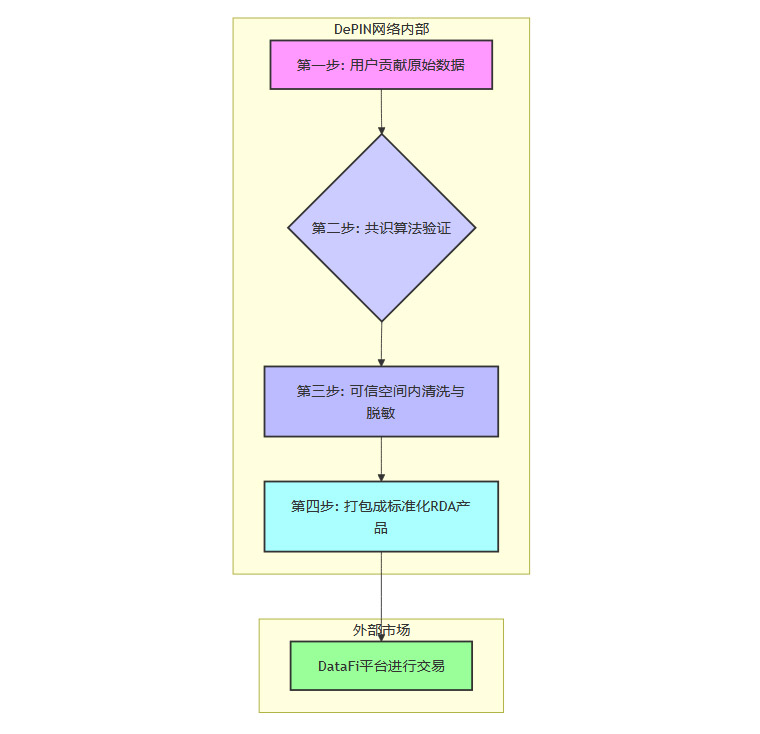
3.1 第一步:源头活水——用户贡献原始数据
一切的起点,都始于全球数百万个终端设备。
无论是Hivemapper的行车记录仪捕捉的街景图像,还是DIMO的OBD设备读取的车辆遥测数据,亦或是WeatherXM气象站记录的温度变化,这些都是价值链的最前端。数据通过设备自动上传,源源不断地汇入网络。这个阶段的特点是去中心化、大规模、持续性。数据生产不再依赖于某个公司的采集车队或固定站点,而是变成了一种全民参与的、无时无刻不在进行的活动。
3.2 第二步:去伪存真——共识算法的验证熔炉
原始数据上传后,并不会被直接采纳。DePIN网络必须解决一个核心问题,如何确保这些来自匿名用户的数据是真实可信的?
答案在于其内置的共识算法。这套机制如同一个严苛的“质检员”,负责将伪造、重复或低质量的数据剔除出去。
物理工作量证明(Proof of Physical Work, PoPW)。这是许多DePIN项目采用的核心机制。它要求数据贡献必须伴随着一个可验证的、在物理世界中完成的“工作”证明。例如,在Hivemapper中,连续的GPS轨迹和时间戳可以证明行车记录仪确实在移动中拍摄了真实的道路。任何试图在固定地点伪造数据的行为都会被轻易识破。
多节点交叉验证。当多个DePIN设备在同一时间、同一地点采集到相似的数据时,这些数据点的可信度会得到极大增强。例如,在某个十字路口,如果有三辆装有DIMO设备的汽车都报告了拥堵,那么“该路口拥堵”这一信息的权重就会远高于单个数据点的报告。
时空一致性校验。网络会检查数据在时间和空间维度上的逻辑自洽性。一个声称在5分钟内从纽约移动到洛杉矶的数据点,会被系统自动判定为无效。
社区治理与挑战机制。一些DePIN网络还引入了社区投票或数据挑战机制。网络参与者可以质押代币,对可疑数据发起挑战。如果挑战成功,伪造数据的节点会受到惩罚,其押金被没收,而挑战者则会获得奖励。这利用了群体的智慧和利益驱动,进一步增强了网络的自我净化能力。
通过这套复杂的验证熔炉,DePIN网络确保了其数据源头的高度可信性,这是其产出的RDA能够成为“黄金”数据的根本前提。
3.3 第三步:精炼提纯——可信空间内的数据处理
经过验证的“干净”数据,会进入一个被称为“可信数据空间”(Trusted Data Space)的环节进行深度加工。这个环节的目标是标准化和保障安全。
数据清洗与格式化。原始数据可能存在格式不一、单位不同、存在噪声等问题。在这一步,网络协议会自动对数据进行清洗,去除异常值,并将所有数据统一为标准格式。例如,将华氏度统一转换为摄氏度,将英里统一转换为公里。
隐私保护与脱敏处理。这是整个价值链中至关重要的一环,也是DePIN区别于传统数据巨头的核心优势之一。为了保护用户隐私并符合全球各地日益严格的数据法规(如GDPR),DePIN网络必须对数据进行彻底的脱敏处理。
个人身份信息(PII)剥离。所有可能关联到具体个人的信息,如精确的家庭住址、车牌号码、设备ID等,都会被彻底移除或进行哈希处理。
数据匿名化与聚合。数据通常以聚合的形式提供,而不是单个数据点。例如,数据购买方得到的是“某街区过去一小时的平均车速”,而不是“张三的汽车在下午3点15分时的车速”。
前沿隐私技术应用。一些更先进的DePIN项目正在探索使用**零知识证明(ZKP)**等前沿密码学技术。这允许网络在不暴露原始数据本身的情况下,向数据购买方证明某些数据属性的真实性。例如,一个保险公司可以在不知道车主具体驾驶行为的情况下,通过ZKP验证该车主“过去一年内没有超速记录”。
这个精炼提纯的过程,确保了最终产出的数据既是合规的、安全的,又是易于使用的、标准化的。
3.4 第四步:封装上架——标准化RDA产品的诞生
价值链的最后一步,是将处理好的数据打包成可供交易的最终产品。
这些数据不再是零散的数据流,而是被精心封装成具有明确定义和商业价值的标准化RDA产品。例如:
“过去24小时纽约市中心各主干道路口车流量与平均等待时长数据包”
“加州中部农业区过去一周土壤湿度与光照强度分钟级数据订阅”
“北美地区特斯拉车型冬季电池衰减曲线数据集”
这些标准化的RDA产品,最终会在专门的DataFi(数据金融)平台上进行挂牌。AI公司、研究机构、对冲基金、政府部门等数据需求方,可以在这些平台上像逛网店一样,浏览、筛选、购买或订阅他们需要的数据产品。交易过程通过智能合约自动执行,确保了透明、高效与公平。
至此,从物理世界的一个个原始比特,到AI模型可以直接“食用”的高价值数据“罐头”,DePIN的数据价值链完成了它的使命。
四、飞轮效应:驱动数据永续增长的强大引擎
DePIN最令人着迷的地方,在于其内生的、能够自我强化的“飞轮效应”。一旦这个正向循环被启动,它就能像一个永动机一样,驱动网络以惊人的速度扩张,并持续不断地提升数据质量。
这个强大的增长引擎,由一系列环环相扣的逻辑构成。
4.1 飞轮的启动:AI需求点燃第一把火
飞轮的转动,始于一个强大的外部推力,那就是AI产业对高质量RDA的巨大需求。
当AI公司意识到,模型的下一次突破依赖于更真实、更独家的数据时,它们便会愿意为此支付高昂的价格。这种强烈的市场需求,直接作用于DataFi平台上的RDA产品,推高了其售价。一个高质量的城市交通数据集,对于训练自动驾驶模型的公司来说,其价值可能高达数百万美元。
AI需求激增 → RDA产品价格上涨
这是飞轮的第一推动力。
4.2 飞轮的加速:从激励到增长的闭环
RDA产品价格的上涨,意味着DePIN网络获得了更多的收入。这些收入的大部分,会通过代币回购、增加奖励池等方式,返还给网络的贡献者。
更高的代币激励。网络可以将出售数据获得的收入,用于在公开市场上回购其原生代币,从而推高币价。或者,直接增加对数据贡献者的代币发放量。无论是哪种方式,都意味着用户贡献数据所能获得的实际回报(ROI)增加了。
吸引更多用户加入。更高的回报率,会像磁石一样吸引全球更多的新用户加入网络。看到早期参与者通过安装一个简单的设备就能获得可观的收入,潜在用户加入的意愿会大大增强。Hivemapper的用户数在一年内从数千激增至数万,DIMO的连接车辆数量突破十万,都是这一效应的真实写照。
网络覆盖与密度的提升。更多用户的加入,直接带来了网络物理覆盖范围的爆炸式增长。数据不再局限于几个大城市,而是延伸到更广泛的城镇甚至乡村。同时,在同一区域内,数据节点的密度也大大增加。
这个过程形成了一个紧密的闭环。
RDA价格上涨 → DePIN网络收入增加 → 代币激励增强 → 吸引更多用户加入 → 数据供给量和覆盖面扩大
4.3 飞轮的成果:数据维度的全面提升
飞轮的每一次转动,带来的不仅仅是数据量的增加,更是数据质量在多个维度上的质变。
覆盖广度(Coverage)。网络从最初的几个核心城市,扩展到全国乃至全球。
数据密度(Density)。在同一条街道上,过去可能只有一个数据点,现在可能有十个、一百个。这使得数据分析的粒度更细,结论更可靠。
更新频率(Frequency)。更多的节点意味着数据可以被更频繁地采集和更新。地图数据可以从每月更新,提升到每日甚至每小时更新。
这些数据质量的提升,使得DePIN网络能够满足AI模型更复杂、更精细的训练需求。例如,一个最初只能用于分析城市主干道交通的AI,现在可以被用来优化整个城市的毛细血管道路网络。
数据供给扩大 → 数据质量(广度、密度、频率)提升 → 更好地满足AI的高级需求
4.4 飞轮的终局:掌控数据底座
当数据质量提升后,它会吸引更多、更强大的AI需求方入场,进一步推高RDA产品的价值,从而让整个飞轮转动得更快、更有力。
更好地满足AI需求 → 吸引更多AI公司购买 → RDA需求进一步激增 → RDA价格继续上涨...
这个正向循环一旦形成,便很难被打破。它会驱动DePIN网络进入一个指数级增长的轨道,最终成为特定领域内不可或缺的数据基础设施。
谁能率先启动并主导这个飞轮,谁就能掌控这个领域的数据底座。在AI时代,掌控了数据底座,就等于掌控了创新的源头和行业的话语权。这正是DePIN模式最深远的战略意义所在。
五、未来展望与挑战
%20拷贝-rjji.jpg)
DePIN为AI描绘了一幅无比诱人的未来图景。它不再是加密世界里一个供少数极客把玩的小众概念,而是正在迅速崛起,有望成为支撑整个AI产业发展的关键基石。然而,通往这个未来的道路并非一片坦途,机遇与挑战并存。
5.1 展望:AI创新的“终极燃料库”
DePIN的真正潜力,在于它能够驱动从数字世界到物理世界的全面智能化。
智能城市的神经网络。由DePIN网络采集的实时交通流、环境数据、能源消耗数据,将成为构建真正智能城市的大脑和神经网络。交通信号灯可以根据实时车流动态调整,城市规划可以基于精确的人口流动数据进行,灾害预警可以达到前所未有的精度。
个性化医疗的基石。通过可穿戴设备组成的DePIN网络,可以匿名化地收集海量的个人健康数据(如心率、血糖、睡眠模式)。AI模型在这些数据上进行训练,将极大推动疾病的早期诊断、个性化治疗方案的制定以及新药的研发。
颠覆传统行业。从需要超本地化气象数据的精准农业,到依赖真实驾驶行为数据的智能保险,再到需要全球物流追踪的供应链金融,DePIN产出的RDA将像催化剂一样,在各行各业引发连锁的创新革命。
可以说,DePIN正在构建一个AI创新的“燃料库”。它提供的不再是经过提纯的汽油,而是能够驱动下一代核动力航母的高能燃料。
5.2 挑战:黎明前的荆棘之路
尽管前景光明,但DePIN作为一个新兴事物,仍需穿越一片荆棘丛生的地带。其中两大挑战尤为突出。
复杂的监管合规迷雾。DePIN的本质是全球化和去中心化的,而数据法规却往往是区域化和中心化的。一个横跨上百个国家的数据网络,如何同时遵守欧盟的《通用数据保护条例》(GDPR)、加州的《消费者隐私法案》(CCPA)以及其他国家截然不同的数据主权要求?
责任主体模糊。当数据泄露或滥用事件发生时,责任应该由谁来承担?是匿名的节点贡献者,是网络协议的开发者,还是使用数据的AI公司?法律上的模糊地带给DePIN的商业化落地带来了不确定性。
跨境数据流动。许多国家对本国公民的数据出境有严格限制。DePIN网络如何在保证去中心化特性的同时,满足这些合规要求,是一个巨大的技术和法律难题。
数据隐私的“达摩克利斯之剑”。DePIN将隐私保护作为其核心价值主张之一,但理论上的承诺与工程上的完美实现之间,仍有距离。
“去匿名化”的风险。尽管网络层面对数据进行了脱敏和聚合,但理论上,通过交叉比对多个数据集,仍有可能重新识别出部分个人身份。随着数据维度的增加,这种风险也在同步上升。
技术成熟度与成本。像零知识证明(ZKP)这样的前沿隐私计算技术,虽然能提供极强的隐私保障,但目前其计算开销较大,在处理海量实时数据流时可能会面临性能瓶颈和成本问题。如何在安全性、性能和成本之间找到最佳平衡点,是所有DePIN项目必须面对的考验。
这些挑战并非不可逾越,但它们要求DePIN的建设者们不仅要懂技术和经济模型,更要成为法律、合规和隐私保护领域的专家。
综合结论
我们正处在一个深刻的转折点。AI竞赛的下半场,哨声已经吹响,赛场已从算力的角斗场,转移到了数据的广袤原野。在这场新的竞赛中,谁能掌握最丰富、最真实、最独家的数据,谁就能定义智能的边界。
DePIN,以其去中心化的架构、代币驱动的激励、以及内生的飞轮效应,为这场数据争夺战提供了迄今为止最令人信服的答案。它不再是简单的“数据众包”,而是一套完整的、从物理世界捕获价值并将其安全、高效地注入AI核心的精密系统。
它通过遍布全球的“数据工厂”,重塑了AI的数据供给链,为RDA市场注入了前所未有的活力。其独特的价值链,确保了数据从源头的可信,到处理过程中的安全,再到最终产品的可用。其强大的飞轮效应,则保证了这条数据生命线能够持续、指数级地成长和进化。
未来,DePIN网络将如同我们今天所依赖的电力网和通信网一样,成为数字社会不可或缺的基础设施。它将是AI时代的“血液循环系统”,为从智能城市到个性化医疗的每一次心跳,输送着最关键的养分。
尽管前路依然存在合规与隐私的挑战,但历史的车轮已经开始转动。掌控DePIN,就是掌控AI的“终极饲料”。在这场关乎未来的智能革命中,谁能率先在这片新大陆上插上旗帜,谁就将在新时代中占据无法撼动的领先地位。
📢💻 【省心锐评】
AI的下半场,算力让位数据。DePIN不是在挖矿,是在铸造新时代的数字石油。谁掌握了数据源头,谁就定义了智能的边界。

评论