.png)
%20%E6%8B%B7%E8%B4%9D-ewjs.jpg)

【摘要】AI赋能敏捷开发,治理须先行。本文详述六大实战法则,聚焦数据安全、渐进试点与人机协同,旨在规避风险,实现可度量的价值提升。
引言
敏捷开发方法论推行多年,其初心在于打破业务与技术之间的壁垒,实现快速迭代与价值交付。然而,在许多大型组织中,敏捷的规模化扩展已显疲态,其实践成熟度近十年未见显著突破。与此同时,业务部门对技术团队的投资回报率(ROI)与创新能力的期望却与日俱增。这双重压力,将行业目光引向了人工智能(AI)。
业界普遍期待,AI能成为敏捷团队的“新队友”,贯穿整个软件开发生命周期(SDLC),让敏捷“再敏捷”。这种期待不无道理,AI在代码生成、测试自动化、文档编写等领域的潜力已初步显现。但我们必须清醒地认识到,AI并非解决所有工程问题的“银弹”。当前,真正实现大规模自主决策的AI代理案例凤毛麟角,其应用价值更多体现在“生产力助理”层面。
将一个强大的、尚在演进中的技术直接注入高度协同的研发体系,其过程远比调用一个新API复杂。它带来的不仅是效率的变量,更是安全的变量、流程的变量和文化的变量。任何脱离治理的盲目提速,最终都将导致技术债、安全漏洞乃至合规灾难。因此,正确的路径只有一条,先建立规则,再追求速度。本文将系统阐述AI融入敏捷开发的六大实战法则,并深入剖析其首要风险,为技术领导者提供一份可落地的行动蓝图。
一、 数据与隐私安全优先——构筑不可逾越的红线
%20拷贝-zosl.jpg)
将AI引入研发流程,首当其冲的挑战便是数据安全。研发数据,包括源代码、API密钥、内部文档、客户信息等,是企业的核心数字资产。一旦这些数据通过不受控的AI工具泄露,其后果不堪设想。三星公司因工程师使用公有大模型泄露内部源代码而紧急禁用ChatGPT,迪士尼客户数据因“影子AI”工具泄露,这些都是前车之鉴。因此,数据安全是基石,而非选项。
1.1 明确数据禁区与治理策略
在引入任何AI工具之前,首要任务是进行数据资产盘点与分类分级,明确哪些数据是绝对禁止流向外部或未经审批的AI模型的。
1.1.1 划定核心禁区
以下类型的数据必须被列为最高敏感级,严禁在任何未受控的环境中使用。
身份凭证与密钥。API Keys, 数据库连接字符串, 私钥, OAuth Tokens等。
个人可识别信息 (PII)。客户或员工的姓名、身份证号、联系方式、地址等。
受监管的敏感数据。金融、医疗等行业受特定法规(如GDPR, HIPAA)保护的数据。
知识产权 (IP)。未公开的源代码、算法、设计文档、商业机密。
1.1.2 实施数据最小化与脱敏
对于必须由AI处理的数据,应遵循最小化原则,仅传递任务所必需的最少量信息。同时,必须在数据离开可信环境前进行自动化脱敏处理,用占位符替换所有敏感实体。
1.2 实施严格的环境隔离与防护
不同敏感度的AI应用场景,需要匹配不同级别的环境安全策略。
1.2.1 优先选择私有化部署
对于处理核心代码或敏感数据的场景,自托管或在私有云(VPC)内部署的开源模型是首选。这能确保数据流量和模型状态完全在组织内部可控,从物理层面杜绝外部泄露风险。
1.2.2 强化外部SaaS工具管控
若必须使用外部AI服务,则必须满足以下条件。
数据非留存协议。服务商承诺不使用用户数据进行再训练。
传输与静态加密。全程使用TLS 1.3以上协议,存储数据采用AES-256等强加密。
零信任访问控制。基于最小权限原则,对访问AI服务的身份和设备进行严格认证。
1.2.3 在DevSecOps流水线中嵌入防护
安全不应是事后审查,而应是内置于开发流程的能力。
IDE插件。在开发者编写代码时实时扫描,提示潜在的密钥或PII泄露。
Git Hooks。在
pre-commit阶段自动运行扫描,阻止敏感信息进入版本库。CI/CD流水线。集成自动化扫描工具(如TruffleHog, Gitleaks),在构建过程中进行深度检测,一旦发现问题立即中断流程。
提示防火墙 (Prompt Firewall)。作为API网关的一部分,在请求发送至外部模型前,自动拦截和清洗提示中的敏感内容。
1.3 严防“影子AI”的滋生
“影子AI”指员工未经组织批准,私自使用的AI工具、浏览器插件或个人账号。这是数据治理中最难防范的环节,因为它源于员工提升效率的自发行为。
1.3.1 建立工具白名单与备案机制
组织应评估并建立一份官方批准的AI工具“白名单”。所有未在名单内的工具,原则上禁止在工作设备和网络中使用。员工若有新的工具需求,应通过正式的评估和备案流程。
1.3.2 强化终端与网络监控
通过终端管理软件(MDM)和网络流量分析,识别未经授权的AI服务访问请求和异常数据传输行为。这有助于及时发现并处置“影子AI”的使用。
1.3.3 明确违规处置流程
制定清晰的政策,告知员工使用未经批准的AI工具可能带来的风险以及相应的纪律处分。疏堵结合,在提供合规工具的同时,也要划清违规的底线。
二、 治理先行,防患于未然
在确保数据安全的基础上,需要建立一套全面的AI治理框架。这套框架是AI在组织内安全、合规、高效运行的“交通规则”。没有规则,自由探索只会导致混乱。
2.1 制定清晰的治理框架
一个完备的AI治理框架应至少包含以下几个方面。
用途边界定义。明确AI可以用于哪些场景(如代码辅助、测试生成),禁止用于哪些场景(如生产环境自动决策、员工绩效评估)。
模型与工具目录。维护一份经过审查的AI模型和工具清单,包括其版本、能力、限制和适用场景。
数据类型许可。详细规定不同类型的AI工具可以访问和处理哪些级别的数据。
IP与安全责任归属。明确由AI辅助生成的代码、文档等产物的知识产权归属。同时,定义当AI应用出现安全漏洞或合规问题时,由谁承担最终责任(原则上,人始终是最终责任人)。
审计与留存策略。规定AI交互的日志(包括提示、输出、人工反馈)需要保留多久,以及审计的频率和范围。
2.2 建立风险分级与责任矩阵
并非所有AI用例的风险都相同。对AI用例进行分级管理,是实现资源有效分配和风险精准控制的关键。
通过建立这样的责任矩阵,可以确保每个AI用例都经过与其风险相匹配的审慎评估。
2.3 推广模型卡与使用说明
为了提升AI应用的透明度,应强制要求每款引入的模型或代理工具都配备“双卡”。
模型卡 (Model Card)。这是一份技术说明书,详细描述模型的训练数据、算法、性能基准、局限性、潜在偏见以及风险缓解措施。它帮助使用者了解模型的“能力边界”和“行为倾向”。
使用说明 (Usage Guide)。这是一份面向最终用户的操作手册,用通俗的语言解释该工具的最佳实践、典型提示范例、常见错误以及安全注意事项。
“双卡”制度确保了AI工具不是一个无法理解的“黑箱”,让每个使用者都能在充分知情的情况下,负责任地使用它。
三、 小步快跑且可量化——在实践中验证价值
%20拷贝-rxag.jpg)
在完善的治理框架下,AI的引入应遵循敏捷自身的原则,即小步快跑、迭代验证。避免一开始就追求宏大的、颠覆性的目标,而是从低风险、高收益的场景切入,用数据证明其价值。
3.1 选择合适的试点场景
理想的试点场景应具备以下特征。
高频重复。任务本身是开发流程中频繁出现的,效率提升的累积效应明显。
低风险性。任务不直接触碰生产环境或核心敏感数据,即使AI表现不佳,纠错成本也低。
效果易于衡量。任务的产出质量和效率有明确的评估标准。
以下是一些推荐的初始试点领域。
测试用例生成。基于需求文档或代码变更,自动生成单元测试、集成测试的骨架。
文档与摘要自动化。根据代码变更自动生成Pull Request描述、发布说明(Release Notes)和API文档更新。
代码静态分析与重构建议。分析代码中的坏味道(Code Smells),并提供符合团队规范的重构建议。
需求与Backlog分析。对用户故事、缺陷报告进行聚类分析,识别重复项,并初步建议优先级。
3.2 坚持数据驱动的价值评估
评估AI试点的成效,绝不能依赖“感觉上变快了”这类主观判断,而必须基于可量化的指标。采用A/B测试或前后对照实验是验证价值的最佳方式。
为每个试点设定明确的成功标准、评估周期以及退出或复盘的条件。只有被数据证明有效的实践,才值得推广。
3.3 设立严格的技术护栏
在试点期间,必须设立严格的技术护栏,防止AI的负面影响扩散。
严禁AI代码自动合并。所有由AI生成的代码,必须经过至少一名开发人员的严格审查(Code Review),确认无误后方可手动合并到主干分支。
使用影子分支或沙箱环境。让AI在隔离的环境中运行,其产出先在非生产环境中进行充分验证。
安全护栏并行推进。在试点AI功能的同时,必须同步运行前述的所有安全扫描和防护措施,确保试点过程本身是安全的。
四、 可解释、可追溯、可审计——构建信任的链条
当AI的参与度加深,其行为的透明度就变得至关重要。一个无法解释、无法追溯其决策过程的AI系统,是不可信的,也无法在出现问题时进行归责。因此,必须构建一个完整的信任链条。
4.1 确保AI生成内容的可溯源性
每一项由AI生成的产出,都必须像代码提交一样,带有清晰的“元数据”标签。
来源标注。明确标注内容由哪个AI模型、哪个版本生成。
提示摘要。附上生成该内容的核心提示(Prompt)的哈希值或摘要,便于复现。
置信度说明。如果模型能提供,应附上对其输出的置信度评分,帮助人工判断其可靠性。
例如,一段AI生成的代码注释可以是这样的。
java:
/**
* This method calculates the factorial of a non-negative integer.
*
* @param n The non-negative integer.
* @return The factorial of n.
*
* AI-Generated: true
* Model: gpt-4-turbo-2024-04-09
* Prompt-Hash: a1b2c3d4...
* Confidence: 0.95
*/
public long factorial(int n) {
// ... implementation
}
4.2 将提示与审批链纳入版本控制
将AI的使用过程本身也视为一种“代码”,进行版本化管理。
提示即代码 (Prompts-as-Code)。将高质量、经过验证的提示语存储在版本控制系统(如Git)中,作为团队的共享资产。这确保了AI行为的一致性和可复现性。
审批链记录。对于需要人工审批的AI操作(如代码合并),审批的意见、决策者和时间戳都应被记录在版本控制系统或工单系统中,形成完整的决策链。
4.3 固化人工审批的关键关口
AI可以作为高效的执行者,但最终的决策权和发布权必须掌握在人手中。必须在流程中定义清晰的、不可绕过的人工审批关口。
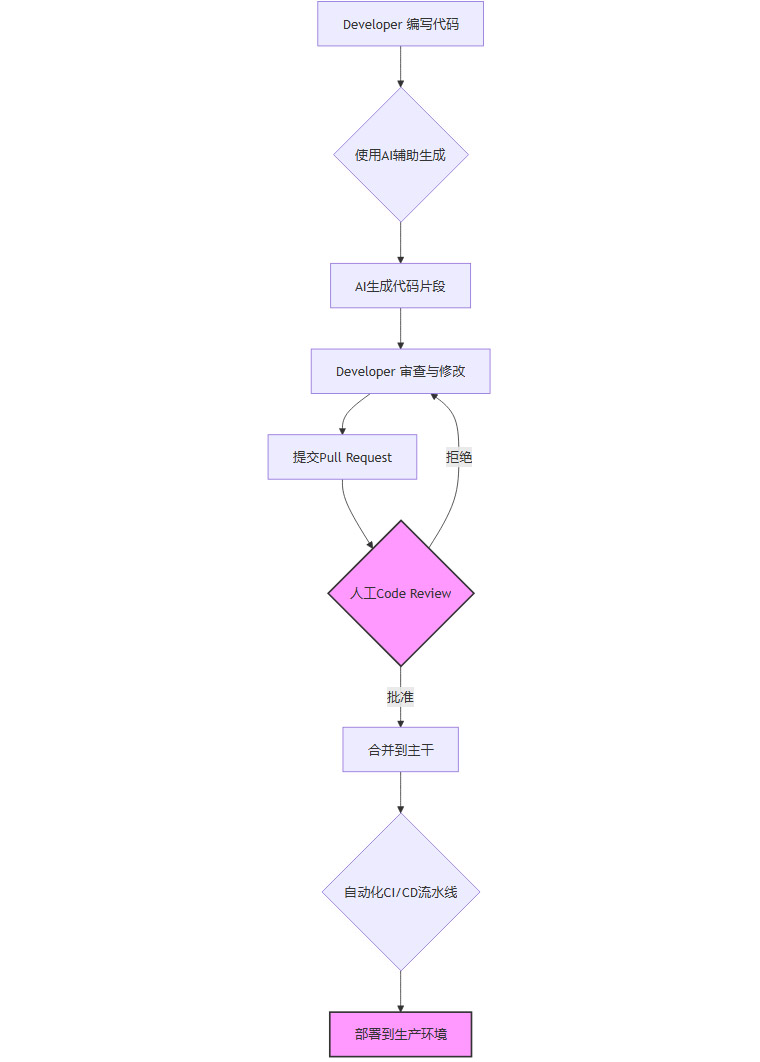
上图中的人工Code Review和最终的部署决策就是两个典型的强制人工关口。这些关口可以通过策略即代码 (Policy-as-Code) 的方式,利用Open Policy Agent (OPA)等工具在CI/CD流水线中强制执行,确保流程合规。
4.4 强化DevSecOps自动化门禁
除了人工关口,自动化的质量与安全门禁同样不可或缺。
自动化代码审查。集成静态代码分析(SAST)、动态代码分析(DAST)工具,自动检查AI生成的代码是否存在安全漏洞。
依赖与许可证扫描。检查AI引入的第三方库是否存在已知漏洞(CVE)或不合规的软件许可证。
合规扫描。根据组织的安全基线和行业法规,自动扫描基础设施配置和代码实践是否合规。
这些自动化的“硬性闸门”与人工审批互为补充,共同构筑起一道坚实的质量与安全防线。
五、 人机协同,团队心智转型——重塑协作的范式
%20拷贝-ctqf.jpg)
引入AI,不仅仅是增加一个工具,更是对团队协作模式和成员心智模式的一次重塑。如果处理不当,很容易引发团队成员的抵触情绪,如担心“被替代”、“被降本增效”。因此,技术领导者必须主动引导这场转型,将AI定位为增强团队能力的伙伴,而非取代人类的对手。
5.1 将AI定位为“新队友”而非纯工具
这意味着在敏捷实践中,要为AI找到合适的“角色”,让它自然地融入团队的工作节奏。
参与敏捷仪式。在Backlog梳理会(Grooming)上,可以利用AI对大量用户故事进行初步的聚类和标签化,帮助团队快速识别主题。在复盘会(Retrospective)上,AI可以分析周期内的各类数据(如Commit记录、工单流转),帮助发现潜在的流程瓶颈。
辅助评审而非决策。在Code Review过程中,AI可以作为“第一位评审员”,自动检查代码风格、潜在bug和性能问题,让人类评审员能更专注于业务逻辑和架构设计。但最终的评审结论,必须由团队成员基于共识做出。
赋能创新与探索。鼓励团队使用AI进行头脑风暴、探索新的技术方案或快速构建原型。AI可以极大地降低试错成本,让团队敢于尝试更大胆的想法。
5.2 积极沟通,管理团队预期
透明、坦诚的沟通是消除恐惧、建立信任的唯一途径。
明确引入AI的目标。领导者需要清晰地向团队阐明,引入AI的目的是赋能创新、减轻重复性劳动,让工程师能将更多精力投入到高价值的创造性工作中,而不是为了裁员。
强调“人最终负责”原则。反复强调,无论AI提供了多么智能的建议,对最终产品质量和业务结果负责的,永远是人。这既是责任的界定,也是对人类工程师专业价值的肯定。
建立反馈与改进渠道。鼓励团队成员分享使用AI的经验、遇到的问题和改进建议。让团队感觉自己是这场变革的参与者,而非被动的接受者。
5.3 投资于团队能力建设
要让团队真正驾驭AI,必须为他们配备新的技能。
设立Prompt工程师或AI Champion角色。在团队中培养一两位对AI技术有浓厚兴趣和深入研究的成员,让他们负责探索和分享最佳的提示工程(Prompt Engineering)实践,并作为团队内部的AI技术顾问。
组织系统性培训。定期组织关于提示工程、AI伦理、数据安全等主题的培训,提升整个团队的“AI素养”。
建立共享提示库。鼓励团队将高效、实用的提示语沉淀下来,形成一个共享的、版本化的提示库。这不仅能提升整体效率,也是一种知识管理的有效方式。
5.4 设定合理的激励与守则
错误的激励机制会引导错误的行为。
反对以AI产出量为KPI。绝对不能将“使用AI生成代码的行数”或“调用AI的次数”作为绩效考核指标。这只会鼓励团队为了刷量而产生大量低质量、未经思考的“垃圾代码”。
激励高质量的人机协同成果。奖励那些通过巧妙利用AI,显著提升了产品质量、解决了复杂技术难题或优化了核心业务流程的案例。
制定团队AI使用守则。与团队共同制定一份简洁明了的AI使用守则,内容包括必须遵守的安全红线、推荐的使用场景和提倡的协作精神。
六、 以价值流为导向,度量创新ROI——确保AI服务于业务目标
引入AI的最终目的,是为了更快、更好地交付业务价值。因此,对AI成效的度量,必须与软件交付的价值流紧密对齐,避免陷入“为了技术而技术”的局部优化陷阱。
6.1 对齐DORA与核心质量指标
DORA(DevOps Research and Assessment)指标是业界公认的衡量软件交付性能的黄金标准。应将AI的应用成效与这些指标直接挂钩,验证其是否带来了真实的收益。
除了DORA指标,还应关注其他核心质量指标,如缺陷逃逸率、代码覆盖率、返工率等。杜绝“只提速,不补质量”的现象,确保AI带来的效率提升没有以牺牲软件质量为代价。
6.2 利用AI洞察与优化价值流
AI不仅能优化价值流的单个环节,更能帮助我们洞察整个价值流的瓶颈所在。
瓶颈识别。通过分析版本控制系统、项目管理工具和CI/CD系统中的海量数据,AI可以识别出流程中的常见等待点,例如“PR长时间无人审核”、“测试环境准备缓慢”等,为流程优化提供数据支持。
跨团队可视化。AI驱动的仪表盘可以将复杂的开发数据转化为直观的图表和摘要,让非技术背景的业务方也能理解项目进展和瓶颈,促进跨职能协作。
辅助需求管理。AI可以分析客户反馈、用户行为日志和市场趋势报告,帮助产品经理识别潜在的需求主题,并为Backlog中的用户故事提供数据驱动的优先级建议。但最终的优先级决策,仍需与公司战略目标对齐。
6.3 建立持续学习与改进的闭环
AI赋能不是一蹴而就的项目,而是一个持续学习和优化的过程。
建立A/B测试文化。对于新的AI应用,尽可能通过A/B测试来验证其对业务指标的真实影响。
定期复盘ROI。将AI工具的投入成本(许可证费用、计算资源、培训成本)与产出的价值(节省的工时、提升的质量指标、带来的业务增长)进行定期核算,确保其ROI为正。
纳入季度业务评审。将AI赋能的进展和成效作为技术部门向业务部门汇报的重要内容,确保技术创新与业务目标始终保持一致。
常见反模式与规避策略
在AI融入敏捷的探索过程中,一些常见的错误做法会严重阻碍其价值的发挥,甚至带来负面影响。识别并规避这些“反模式”至关重要。
结论
将AI融入敏捷开发,是一场深刻的技术与文化变革。它要求我们保持一种审慎的乐观,既要拥抱其作为“生产力倍增器”的巨大潜力,也要正视其作为“风险放大器”的潜在威胁。成功的关键,不在于追求最前沿的模型或最大胆的应用,而在于构建一个稳固的、以治理为核心的实践框架。
回顾本文提出的六大法则,它们共同指向一个核心思想,AI是辅助人类智慧的强大工具,而非替代人类判断的自主决策者。从划定数据安全的红线,到建立清晰的治理规则;从可量化的试点,到全链路的可追溯;从重塑人机协同的文化,到对齐业务价值的度量。每一步,都强调了“人在回路”的核心地位和最终责任。
短期内,引入AI可能会因为学习曲线和流程磨合而导致生产力的暂时下降。但当团队掌握了与AI高效协作的方法,当AI与研发流程深度联动,其在提升软件交付速度与质量方面的长期价值才会稳定地显现出来。这条路没有捷径,唯有稳扎稳打,方能行稳致远。
📢💻 【省心锐评】
AI赋能敏捷,核心是规则而非工具。忘记“银弹”幻想,从治理、安全和度量开始,让人机协同真正服务于业务价值,这才是唯一的可持续路径。

评论