.png)
%20%E6%8B%B7%E8%B4%9D-yqug.jpg)

【摘要】英伟达正通过极致协同设计,将数据中心重塑为AI工厂。其核心是大幅降低Token生成成本,驱动AI工业革命的良性循环,并将算力边界拓展至物理AI与实体经济。
引言
计算领域的旧秩序正在瓦解。摩尔定律,这个指导了半导体行业半个多世纪的黄金法则,其物理极限已然显现。黄仁勋在GTC大会上的宣告,与其说是对一个时代的告别,不如说是对一个新纪元的开篇。我们正面临一个前所未有的局面,AI模型对算力的需求呈现出“双重指数级”增长。一方面,模型自身从预训练、后训练到更高阶“思考”阶段的演进,带来了计算复杂度的指数级攀升。另一方面,模型智能水平的提升吸引了指数级增长的用户与应用,进一步放大了算力缺口。
在传统性能提升路径失效的背景下,单纯依靠增加晶体管数量已无力应对这场算力风暴。这并非简单的技术瓶颈,而是一场计算范式的根本性变革。英伟达给出的答案是**“极致协同设计”(Extreme Co-Design)**,这是一种从芯片、系统、网络、软件到应用的全栈垂直整合思维。本文将深入剖析英伟达如何通过这一战略,构建从Grace Blackwell超级芯片到AI工厂的完整基础设施,并探讨其对未来技术生态的深远影响。
一、 算力经济学的重构:从成本压缩到价值创造
%20拷贝-epcr.jpg)
AI的商业闭环能否持续运转,其关键经济杠杆在于推理成本。当AI模型足够智能,能够创造显著价值时,用户愿意为其付费。这笔收入继而可以投入到更多的计算资源中,训练出更智能的模型,从而吸引更多用户。这个**良性循环(Virtuous Cycle)**的转动速度,直接取决于每一次AI交互,即生成Token的成本。
1.1 双重指数增长下的算力困境
当前AI算力需求面临两大指数级增长引擎的驱动。
模型复杂度的指数增长
预训练(Pre-training):模型通过学习海量数据掌握基础知识,如同人类的学前教育。
后训练(Post-training):模型学习推理、规划和使用工具的技能,解决复杂问题。
思考(Thinking):在实际应用中,AI需要处理上下文、分解问题、制定计划并执行。这一过程的计算量远超前两个阶段,是推理成本的主要构成。
应用渗透率的指数增长
模型越智能,应用场景越广泛,用户基数就越大。从代码助手Cursor到生物制药领域的AI研究员,AI正从“工具”转变为“工作者”,其应用价值驱动了用户需求的指数级增长。
这两个指数函数叠加,对全球计算资源构成了前所未有的压力。在摩尔定律失效的背景下,若无法以指数级的速度降低Token生成成本,AI的良性循环将难以为继。
1.2 极致协同设计:打破物理定律的枷锁
英伟达的破局之道是极致协同设计。它不再将芯片视为孤立的性能单元,而是将其置于一个从上至下、软硬一体的完整架构中进行系统性优化。
这种全栈协同设计带来的性能提升是乘法效应,而非简单的加法。它使得英伟达能够摆脱单一芯片性能提升的限制,实现系统级的指数级性能增长。
1.3 Blackwell架构:10倍性能与最低TCO
Blackwell架构是极致协同设计的直接产物,其核心目标是最大化每瓦性能和最低化Token生成成本。
1.3.1 从多GPU到单一虚拟超级GPU
传统的AI集群中,GPU通过PCIe或有限的NVLink连接,节点间通信延迟高、带宽低,成为扩展瓶颈。尤其对于拥有数万亿参数的混合专家模型(MoE, Mixture of Experts),模型需要被拆分到多个GPU上,频繁的跨节点通信严重影响了推理速度。
Blackwell通过NVLink-72架构彻底改变了这一局面。它将一个机架内的72颗GPU(36个GB200节点)连接成一个拥有130TB/s总带宽的单一虚拟GPU。这意味着,一个万亿参数级别的模型可以完整地驻留在这个虚拟GPU的显存中,所有专家(Experts)之间的通信都在高速NVLink网络内部完成,延迟极低。
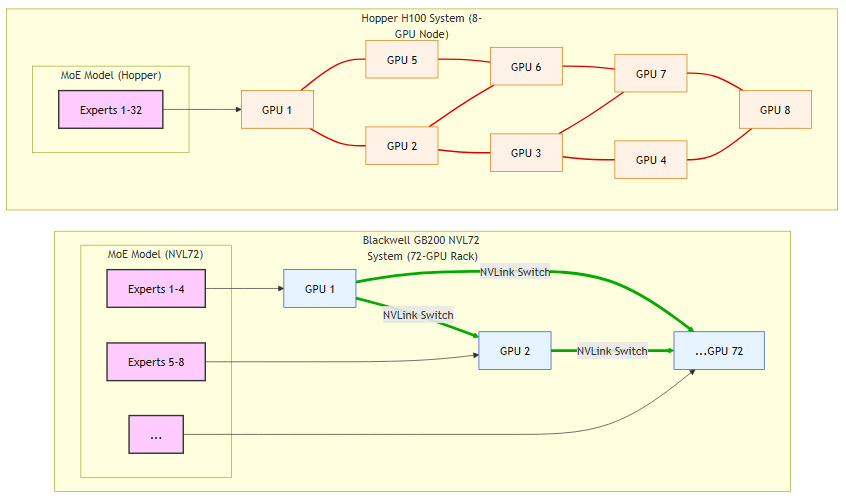
图解:Hopper系统中,单个GPU需承载大量专家,通信受限。Blackwell NVL72系统中,专家分布在多个GPU上,通过高速NVLink Switch实现无缝通信,大幅提升效率。
1.3.2 经济杠杆:总拥有成本(TCO)的极致优化
尽管GB200机架的初始采购成本高昂,但其总拥有成本(TCO)却是最低的。TCO的核心衡量指标是单位时间内生成有效Token的成本,这包括了硬件折旧、电力、冷却和运维等多方面费用。
GB200在推理性能上实现了相较于上一代H100高达10倍的提升。这意味着,在相同的能耗和物理空间下,GB200能够产出10倍的Token。这种极致的性能密度直接摊薄了每一枚Token的生成成本,为AI服务的规模化商业落地提供了坚实的经济基础。
英伟达已经规划了下一代架构Rubin,并展示了其机架级设计。这表明英伟达将延续每年迭代一次的节奏,通过持续的极致协同设计,确保算力性能的指数级增长和成本的指数级下降,为AI的良性循环持续注入动力。
二、 AI工厂:新一代计算基础设施的具象化
随着算力需求的爆炸式增长,传统的数据中心正在向一个全新的形态进化——AI工厂(AI Factory)。
2.1 从通用数据中心到专用AI工厂
传统数据中心是通用计算平台,承载着存储、网页浏览、数据库等多样化的应用。而AI工厂的目标则高度专一,它只生产一种产品:有价值的Token。
AI工厂的设计和运营是一项复杂的系统工程,涉及计算、网络、电力、冷却等多个环节的深度耦合。
2.2 Omniverse DSX:AI工厂的数字孪生蓝图
为了应对吉瓦级(Gigawatt-scale)AI工厂的设计挑战,英伟达推出了**Omniverse DSX(Data Center Supercomputing Extension)**平台。这是一个用于设计、规划、模拟和运营AI工厂的数字孪生平台。
通过DSX,西门子、施耐德电气等生态伙伴可以在一个物理精确的虚拟环境中协同工作。
规划与设计:模拟计算密度、机架布局、电力分配和液冷系统的最优方案。
建设与部署:在动工前发现并解决潜在的工程问题,大幅缩短建设周期。
运营与优化:实时监控工厂运行状态,通过AI进行预测性维护和能效优化。
对于一个1吉瓦的AI工厂,通过DSX进行的设计优化,每年可带来数十亿美元的额外收入或成本节约。这使得AI工厂的建设从传统的工程项目,转变为一个可预测、可优化、快速迭代的数字化流程。
2.3 系统级协同:网络与数据处理的进化
在AI工厂中,网络和数据处理单元不再是辅助角色,而是与GPU深度协同设计的核心组件。
2.3.1 专为AI设计的网络
ConnectX-9 SuperNIC:新一代网络接口卡,提供超高带宽和低延迟,专为GPU Direct RDMA优化。
Spectrum-X以太网交换机:具备自适应路由和拥塞控制能力,能够智能地规划数据路径,避免在大规模GPU集群中出现网络热点和拥塞,确保通信效率。
2.3.2 BlueField-4 DPU:从数据处理器到“上下文处理器”
新一代BlueField-4 DPU的角色发生了根本性转变。它被定位为**“上下文处理器”(Context Processor)**。随着AI应用需要处理的上下文信息(如长篇文档、视频、对话历史)越来越庞大,传统的CPU+GPU架构在处理这些数据时力不从心。
BlueField-4专门用于卸载和加速这些上下文处理任务,特别是**KV缓存(KV Cache)**的管理。KV缓存存储了对话历史的关键信息,随着对话轮次增加,KV缓存会急剧膨胀,导致AI响应速度变慢。BlueField-4通过硬件加速KV缓存的检索和管理,解决了当前大模型在处理长对话时越来越慢的痛点,确保了流畅的用户体验。
三、 物理AI:将算力延伸至实体经济
%20拷贝-tgzi.jpg)
英伟达的战略版图远不止于数字世界。其最终目标是将AI的核心能力注入实体经济,即物理AI(Physical AI)——能够理解并与物理世界互动的AI。
3.1 物理AI的三大计算平台
实现物理AI需要一个端到端的计算架构,涵盖训练、模拟和端侧运行三个环节。
训练计算机(GB200 NVL72):用于训练物理AI模型,使其理解物理规律、因果关系和复杂行为。
模拟计算机(Omniverse Computer):基于Omniverse平台的数字孪生环境。AI在其中进行数百万小时的虚拟训练和测试,学习如何在物理世界中安全、高效地运行。这台计算机需要兼具卓越的生成式AI能力和物理精确的仿真能力(光线追踪、传感器模拟)。
机器人计算机(Jetson Thor):部署在机器人、自动驾驶汽车等边缘设备上的高性能计算平台,负责实时感知、决策和执行。
这三大平台共享统一的CUDA架构,使得模型和算法可以无缝地从云端训练、模拟环境迁移到边缘设备上,极大地加速了物理AI的开发和部署周期。
3.2 关键应用领域的战略布局
英伟达正通过与各行业领导者建立深度合作,将其物理AI平台推广到关键的实体经济领域。
3.2.1 电信:NVIDIA ARC与6G革命
英伟达与诺基亚合作推出**NVIDIA ARC(Aerial RAN Computer)**平台。这是一个基于Grace CPU、Blackwell GPU和ConnectX网卡的软件定义无线通信系统。
AI for RAN:利用AI优化无线电波束成形和频谱管理,提高频谱效率,降低网络能耗。
AI on RAN:将基站转变为边缘AI计算节点,为工业机器人、自动驾驶等低延迟应用提供算力基础设施。
此举旨在重塑价值3万亿美元的电信市场,并推动美国在下一代6G技术革命中占据核心地位。
3.2.2 机器人:从人形到工业的全覆盖
人形机器人被视为继智能手机之后的下一个万亿级市场。英伟达为Figure等顶级人形机器人公司提供从训练(GB200)、模拟(Omniverse)到运行(Jetson Thor)的全栈平台。此外,与迪士尼合作开发的机器人,展示了在物理感知环境中进行强化学习的巨大潜力。在工业领域,英伟达正与富士康等伙伴合作,利用数字孪生技术打造未来的“机器人工厂”,即由机器人协调运作来制造产品的工厂。
3.2.3 自动驾驶:DRIVE Hyperion与全球Robo-Taxi网络
NVIDIA DRIVE Hyperion平台通过标准化的环绕摄像头、雷达和激光雷达套件,将汽车打造为一个“轮式计算平台”。这使得Wayve、Waabi等众多自动驾驶算法公司可以在一个统一的硬件底盘上部署其软件。
更具战略意义的是,英伟达宣布与**优步(Uber)**合作,将所有搭载DRIVE Hyperion的车辆接入其全球网络。这一举措为Robo-Taxi的全球化、规模化部署奠定了基础,有望将自动驾驶从区域性试点推向全球性商业服务。
四、 跨界融合:从量子计算到企业生态
%20拷贝-qygo.jpg)
英伟达的布局体现了其作为平台型公司的战略纵深,通过将核心技术与前沿科学及企业核心业务深度融合,构建了一个难以逾越的生态壁垒。
4.1 量子计算:CUDA-Q与混合计算未来
英伟达并未将量子计算视为传统计算的替代品,而是其延伸和补充。通过发布CUDA-Q平台和NVQLink互联架构,英伟达的目标是将GPU超级计算机与量子处理器(QPU)直接连接。
量子纠错:利用GPU的强大算力对脆弱的量子比特进行实时错误校正,这是实现容错量子计算的关键。
混合模拟:将计算任务在GPU和QPU之间动态分配,发挥各自优势,解决传统计算机难以处理的科学问题。
美国能源部(DOE)下属的八大国家实验室已采用该混合架构,标志着量子-经典混合计算正从理论走向实践。
4.2 企业AI:从“工具”到“工作者”的范式转变
黄仁勋强调,AI的本质是**“工作者”(Workers)**,而非“工具”(Tools)。传统IT工具(如数据库、ERP)触及的是数万亿美元的IT市场,而能够使用工具的AI工作者,将直接参与到价值100万亿美元的全球经济活动中,提升各行各业的生产力。
为了将AI工作者部署到企业核心业务中,英伟达宣布了多项重量级合作。
网络安全:与CrowdStrike合作,打造基于云和边缘的AI网络安全代理,以“光速”应对AI带来的新型安全威胁。
商业洞察:与Palantir合作,加速其Ontology平台的数据处理能力,为政府和企业提供更大规模、更快速的决策支持。
代理式SaaS(Agentic SaaS):将CUDA-X库深度集成到SAP、ServiceNow、Synopsys等企业SaaS平台中,将传统的工作流软件转变为能够自主执行任务的AI代理。
结论
此次GTC大会标志着英伟达完成了从一家芯片公司到AI工业平台领导者的彻底蜕变。其战略核心清晰而坚定,即通过极致协同设计,在摩尔定律终结的时代,持续以指数级速度提升算力性能、降低智能成本。
从Blackwell架构定义的算力新经济,到AI工厂勾勒的基础设施蓝图,再到物理AI描绘的实体经济未来,英伟达正在构建一套覆盖硬件、软件、生态和行业的完整体系。它不再仅仅是售卖“铁锹”的公司,而是在定义新一轮工业革命的底层标准,试图将AI打造成像电力一样无处不在、成本低廉的基础设施。这条道路充满挑战,但其展现的战略决心和技术执行力,预示着一个由AI驱动的全新计算纪元正加速到来。
📢💻 【省心锐评】
英伟达不再销售芯片,它正在交付整座“AI发电厂”。其战略核心是将智能的生产成本降至极限,让AI成为驱动全球经济的新电力。

评论