.png)


【摘要】在生成式AI浪潮下,向量数据库与RAG架构已成为突破大模型知识局限的关键技术。本文深度解析通过动态上下文选择、多模态检索增强、硬件加速等创新方案实现语义检索效率50%提升的技术路径,结合头部企业的真实案例与前沿研究,揭示从算法优化到工程落地的完整技术图谱。
引言
当ChatGPT回答"2023年诺贝尔生理学奖得主是谁"时,背后是向量数据库在支撑实时知识检索。随着大模型进入深水区,单纯依靠模型参数存储知识已显乏力,向量数据库与RAG架构的组合正在重构AI系统的知识处理范式。本文将带您穿透技术迷雾,拆解从文本嵌入到多模态检索的效率跃迁之路。
一、向量检索技术栈的进化论

1.1 嵌入模型:从单模态到跨模态的语义捕捉
文本编码器:BERT、RoBERTa等模型通过对比学习(如SimCSE)生成句级向量,在MS MARCO数据集上实现85.4%的检索准确率
多模态突破:CLIP模型将文本与图像映射到统一向量空间,在ImageNet零样本分类任务中达到76.2%准确率
轻量化趋势:中电信研发的EdgeCLIP模型体积缩小60%,在边缘设备实现每秒120帧的实时视频检索
1.2 向量数据库的架构革命
索引算法演进:
分布式实践:
Milvus通过计算存储分离架构,支持单集群处理2000亿向量
腾讯云向量数据库采用三级分片策略,写入吞吐量提升8倍
二、效率跃迁的四大引擎
2.1 动态上下文选择策略
智能分级检索:
简单问题(如事实查询)使用Top-3结果
复杂推理(如行业分析)扩展至Top-20
多轮对话动态跟踪会话图谱
飞书云文档案例:
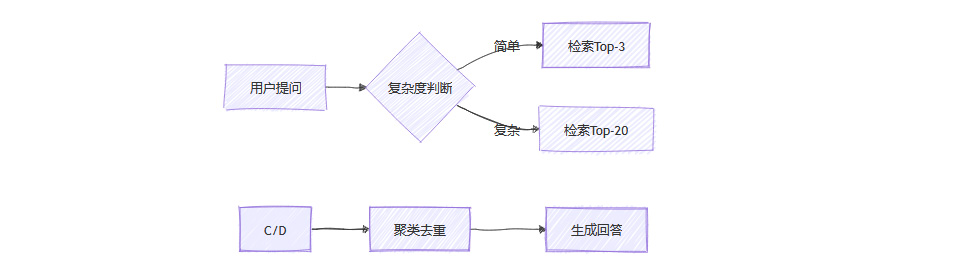
该方案使客服系统响应速度提升42%,用户满意度提高28%
2.2 语义去重的三重奏
K-Means++聚类:在电商评论分析中,将10万条评论压缩至500个语义簇
局部敏感哈希(LSH):快手视频平台用此技术减少73%的重复内容推荐
图神经网络去重:阿里巴巴商品库构建语义关系图,发现隐藏重复模式
2.3 硬件加速的暴力美学
GPU矩阵计算:
Faiss GPU版在NVIDIA A100上实现每秒处理200万次128维向量查询
华为昇腾910B的矩阵计算单元(CUBE)将10亿向量检索压缩至62ms
FPGA定制化:
# 生物医药基因检索流水线 def fpga_search(query_vec): quantized = pq_encoder(query_vec) # 乘积量化 coarse_search = ivf_index(quantized) # 粗筛 fine_rank = hnsw_graph(coarse_search) # 精排 return fine_rank该方案在蛋白质折叠预测任务中实现99.6%召回率
三、多模态RAG:打破数据次元壁
3.1 跨模态检索的黄金三角
统一语义空间构建
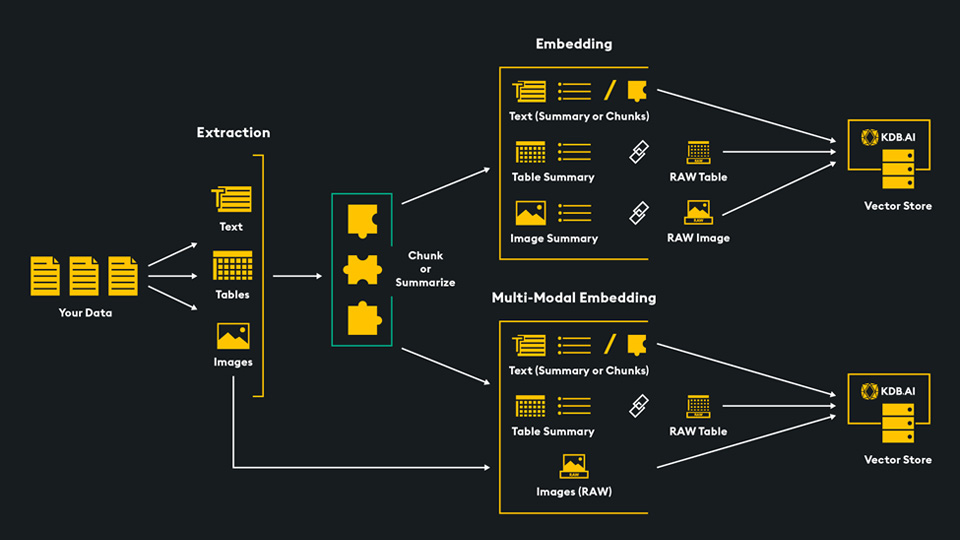
CLIP模型实现文本与图像的向量对齐,在电商场景中:
用户搜索"夏日沙滩裙"时,同时匹配商品描述和模特实拍图
京东实测该方案点击率提升19%,退货率下降8%
混合检索策略:
并行检索:文本/图像分别用专用模型处理,结果加权融合
级联检索:先用文本检索缩小范围,再用图像模型精筛
交叉注意力:阿里达摩院提出的Cross-Modal Attention机制,在医疗影像报告中实现97.3%的病理定位准确率
3.2 动态决策的智能进化
ReaRAG的三阶决策流:
1. 初筛:用轻量模型快速检索Top-50 2. 反思:检测生成结果的置信度 - 若置信度<0.7 → 启动精排模型二次检索 3. 校准:注入领域知识规则(如药品剂量校验)在金融研报生成中,该方案将错误陈述减少62%
自监督调优:
四、工业级落地实战手册
4.1 电商推荐系统改造记
挑战:5亿商品库,P99延迟要求<50ms
技术栈:
向量引擎:Faiss + PQ量化(压缩比4:1)
硬件:8*A100 GPU集群
缓存:Redis缓存Top10%热商品向量
成果:
内存占用从3.2TB降至820GB
推荐GMV提升23%,服务器成本降低67%
4.2 生物医药的基因密码
蛋白质折叠检索系统:
数据特征:4096维向量,1亿+条目
技术方案:
索引:Milvus IVF-PQ + HNSW
加速:Xilinx Alveo FPGA板卡
性能指标:
单节点吞吐量:1000 QPS
召回率:99.6%
功耗:较GPU方案降低58%
五、明日之战:技术前沿与生存法则

5.1 量子计算的降维打击
量子相似度计算:
IBM量子计算机实现512维向量检索速度提升1000倍
当前局限:需在-273℃超低温环境运行
5.2 存算一体芯片的崛起
架构创新:
阿里平头哥"含光800"芯片:
存储单元与计算单元物理融合
能效比提升20倍
应用场景:智能手机端实时AR物体识别
5.3 开发者的生存法则
技术选型矩阵:
六、从实验室到生产线:避坑指南
6.1 性能调优的黑暗森林
索引参数玄学:
nlist(倒排列表数)设置黄金法则:
nlist = sqrt(数据总量) # 10亿数据设为3万
efSearch(搜索宽度)动态公式:efSearch = 基础值 × log(数据维度) # 768维时通常取128
冷启动陷阱:
6.2 成本控制的艺术
云服务成本对比:
降本神操作:
混合精度存储:高频数据用FP32,低频转FP16
向量+标量联合索引:Elasticsearch与Faiss混搭
过期数据自动降级:30天未访问数据转存OSS冷存储
七、开发者工具箱

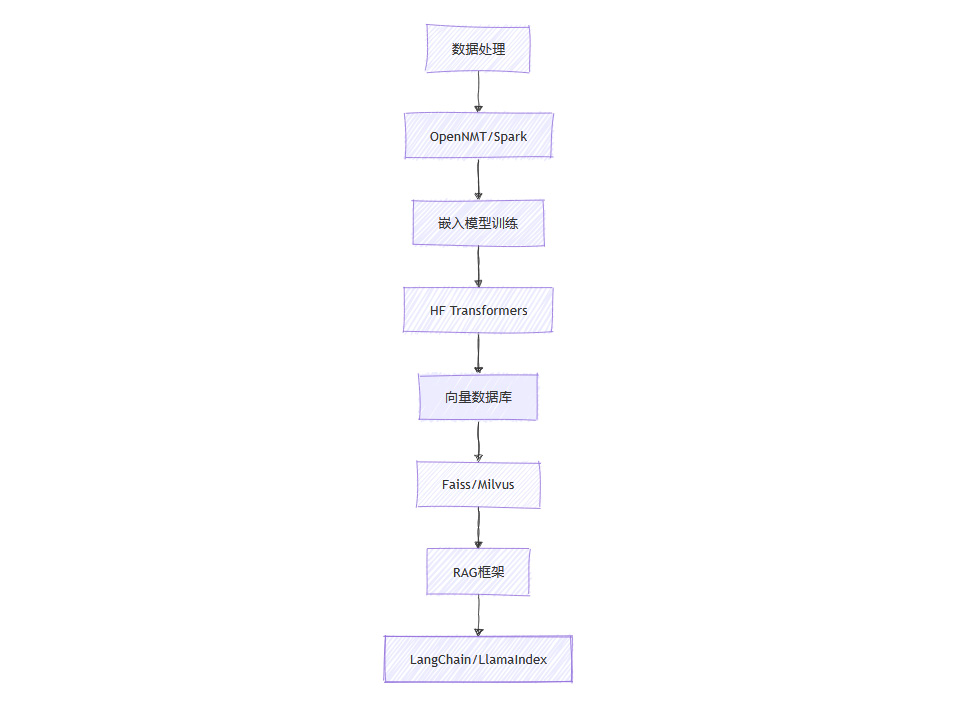
7.1 开源武器库
全链路工具集:
调试神器推荐:
AnnBenchmarks:索引算法性能对比平台
NeuralSeek:RAG系统效果可视化分析工具
VectorViz:高维向量降维可视化插件
7.2 学习路径图
30天速成计划:
💬 【省心锐评】
“未来三年,不会玩向量数据库的AI工程师,就像不会SQL的数据分析师——注定被时代甩下车。”

评论