.png)


【摘要】随着AI大模型的普及,90%算力需求正加速向端边迁移,存算一体芯片成为AI芯片未来主流。本文系统梳理端边计算崛起的动力、存算一体技术的突破、产业化进展与挑战,以及未来趋势,深度剖析其对智能社会的深远影响。
引言
人工智能大模型的浪潮席卷全球,推动着算力需求的结构性变革。过去,云端是AI计算的主战场,数据汇聚、模型训练与推理均依赖于庞大的数据中心。然而,随着5G、物联网、智能终端的普及,端边设备的智能化需求激增,AI推理任务正加速从云端向端侧和边缘侧迁移。与此同时,存算一体芯片的崛起,为端边大模型部署提供了全新技术路径。本文将系统梳理端边计算需求增长的动力、存算一体技术的突破、产业化进展与挑战,以及未来趋势,深度剖析其对智能社会的深远影响。
一、🌐 端边计算需求的快速增长
%20拷贝.jpg)
1.1 端边算力崛起的时代背景
AI大模型的广泛应用,正在重塑算力分布格局。随着智能手机、IoT设备、自动驾驶终端等边缘设备的普及,端边侧的计算需求呈现爆发式增长。预计到2025年,超过50%的AI推理任务将在边缘设备完成,端边算力渗透率将达到25%。这一趋势不仅是技术演进的必然结果,更是产业需求和用户体验的共同驱动。
1.1.1 5G与物联网的推动作用
5G网络的高速率、低延迟特性,为端边设备的智能化提供了坚实基础。物联网的广泛部署,使得数以亿计的终端设备具备了数据采集与处理能力。智能家居、智慧城市、工业互联网等场景,对本地化、实时化AI推理的需求日益迫切,推动端边算力需求持续攀升。
1.1.2 大模型推理任务的本地化趋势
随着大模型参数规模的不断扩展,推理任务对算力的需求水涨船高。云端推理虽然具备强大算力,但在实时性、隐私保护、带宽消耗等方面存在天然短板。端边设备本地化推理,能够实现毫秒级响应,保障数据安全,降低带宽压力,成为大模型落地的关键路径。
1.2 端边计算迁移的核心动力
端边计算需求的快速增长,源于多重动力的共同作用。以下列表系统梳理了主要驱动因素:
1.2.1 实时性与低延迟的极致追求
在自动驾驶、智能家居、工业控制等场景中,AI推理的响应速度直接关系到系统的安全与用户体验。端边部署AI模型,能够实现毫秒级响应,极大提升系统的实时性和可靠性。
1.2.2 隐私保护与数据安全的刚性需求
数据本地处理,避免了敏感信息上传云端的风险,满足了用户对隐私保护的高标准要求。在医疗、金融等对数据安全要求极高的领域,端边推理成为不可或缺的选择。
1.2.3 经济性与能效的双重提升
云端推理虽然算力强大,但能耗高昂,运营成本巨大。端边推理不仅能效更高,还能显著降低带宽和数据中心的运营压力,实现经济性与能效的双赢。
1.2.4 带宽与系统鲁棒性的提升
本地推理减少了对网络带宽的依赖,即使在网络不稳定或带宽受限的环境下,系统依然能够稳定运行,提升了整体鲁棒性。
1.3 端边算力需求的未来展望
随着AI大模型的持续演进,端边算力需求将持续攀升。预计到2030年,端边设备的AI推理任务占比将进一步提升,成为AI应用的主流形态。端边算力的崛起,不仅重塑了AI计算的空间分布,也为存算一体等新型芯片架构的创新提供了广阔舞台。
二、🔗 存算一体技术成为关键支撑
2.1 存算一体架构的创新突破
传统冯·诺依曼架构下,计算单元与存储单元分离,数据在两者之间频繁搬运,导致“存储墙”“功耗墙”问题日益突出。存算一体芯片通过将存储与计算单元集成,极大减少了数据搬运,显著提升了能效比和带宽利用率,成为突破端边大模型部署瓶颈的核心路径。
2.1.1 架构创新的技术原理
存算一体芯片将计算单元嵌入存储阵列内部,实现数据在存储单元内的直接处理。这样不仅缩短了数据传输路径,还降低了能耗和延迟,为大模型推理提供了理想的硬件基础。
2.1.2 典型芯片案例分析
以最新一代SRAM-CIM(存内计算)芯片为例,10W功耗下可实现160TOPS INT8算力,支持1.5B到70B参数大模型的本地推理,能效比提升5-10倍。清华大学的忆阻器存算一体芯片,能效比提升10-100倍,展现出极强的技术潜力。
2.2 存算一体技术的多元路线
存算一体技术并非单一路线,而是多种技术并行发展的格局。主要技术路线包括SRAM-CIM、DRAM-PIM、Flash存内计算、忆阻器等。不同路线各有优势,推动存算一体芯片向更高能效、更大规模、更强通用性演进。
2.2.1 技术路线的多样性与竞争性
SRAM-CIM以高性能著称,DRAM-PIM则在大容量和带宽方面具备优势,Flash存内计算和忆阻器则在低功耗和高密度方面表现突出。多元技术路线的并行发展,为不同应用场景提供了丰富的选择,也推动了存算一体芯片的持续创新。
2.3 存算一体芯片的广泛应用
存算一体芯片已在AI PC、智能手机、机器人、工业互联网、自动驾驶等多元场景实现落地。其高算力、低功耗、本地化推理和数据安全等特性,满足了端边设备对AI推理的多样化需求。
2.3.1 典型应用场景分析
AI PC与智能手机:实现本地大模型推理,提升用户体验与数据安全。
机器人与自动驾驶:支持复杂环境下的实时决策与感知,保障系统安全与可靠性。
工业互联网:实现边缘设备的智能化升级,提升生产效率与安全水平。
智能家居与IoT设备:实现本地语音识别、图像处理等AI功能,提升智能化水平。
2.4 存算一体技术的能效与性能提升
存算一体芯片通过架构创新,实现了能效与性能的双重提升。以SRAM-CIM芯片为例,能效比提升5-10倍,支持1.5B到70B参数大模型的本地推理。忆阻器存算一体芯片则能效比提升10-100倍,为端边大模型部署提供了坚实基础。
三、🚀 产业化进展与挑战
%20拷贝.jpg)
3.1 市场规模与发展预测
全球存算一体芯片市场正处于快速增长阶段。预计2025年市场规模将突破120亿美元,2030年有望达到500亿美元。中国市场占比显著,政策支持力度大,成为全球存算一体芯片产业的重要引擎。
3.1.1 市场规模预测的多元视角
不同机构对市场规模的预测存在一定差异。乐观估计认为2030年市场规模可达500亿美元,保守估计则为260亿美元。实际规模将取决于技术突破和应用落地速度。
3.2 产业生态的加速成熟
主流芯片企业和科研机构积极布局存算一体技术。英特尔、三星、华为、清华大学等国际巨头持续加大研发投入,国内初创公司如后摩智能、知存科技等快速迭代产品,推动产业生态加速成熟。
3.2.1 产业链协同与创新
产业链上下游协同创新,推动存算一体芯片从设计、制造到应用的全流程优化。产学研协同加速技术落地,地方政府积极支持,形成了良好的创新生态。
3.3 工艺与生态的挑战
尽管存算一体芯片展现出巨大潜力,但在工艺与生态方面仍面临诸多挑战。
3.3.1 工艺良率与制程匹配的技术难题
高性能存算一体芯片对工艺制程提出了更高要求。28nm以下工艺良率不足60%,成为大规模量产的瓶颈。存储与逻辑单元的制程匹配,也需要持续优化,以提升芯片性能与可靠性。
3.3.2 软件生态与开发工具链的完善
存算一体芯片的广泛应用,离不开完善的软件生态。当前缺乏统一的开发工具链,软件适配成本高,占据开发总成本的40%。推动软件生态建设,降低开发门槛,是产业化进程中的关键任务。
3.4 政策与产学研的协同推动
中国将存算一体技术列入“先进计算”重点研发计划,地方政府积极出台支持政策,推动产学研协同创新。政策引导与资金支持,为存算一体芯片的技术突破与产业化落地提供了有力保障。
四、🌟 未来趋势与展望
%20拷贝.jpg)
4.1 技术融合与创新驱动
存算一体技术正处于快速演进阶段。3D集成、Chiplet封装、HBM接口等新技术的引入,将进一步提升算力密度和带宽。模拟存算向8bit以上精度演进,支持更复杂的大模型部署,拓展了存算一体芯片的应用边界。
4.1.1 技术融合的未来图景
流程图:存算一体技术演进路径
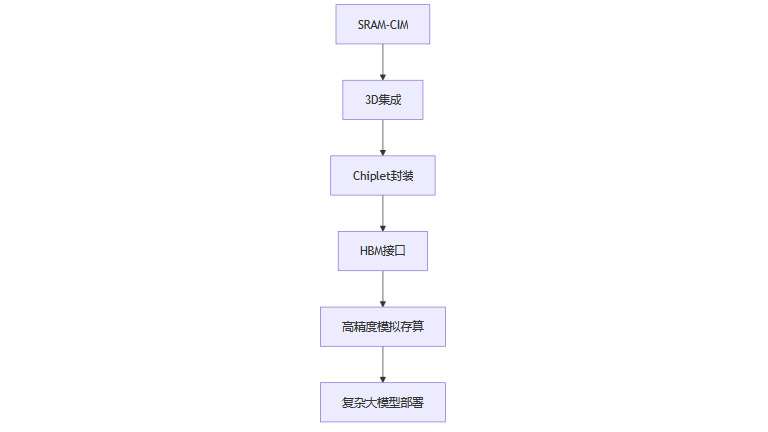
4.2 应用场景的持续扩展
存算一体技术的应用场景正不断拓展。从智能家居、工业互联网延伸至“感存算一体”视觉处理,实现毫秒级图像响应。未来,存算一体芯片将在更多领域实现落地,推动AI应用的普及与深化。
4.2.1 场景扩展的典型案例
智能家居:本地语音识别、图像处理,提升智能化体验。
工业互联网:边缘设备智能化升级,提升生产效率与安全。
自动驾驶:实时感知与决策,保障行车安全。
医疗健康:本地化AI诊断,保护患者隐私。
4.3 普惠化与智能社会的到来
存算一体芯片有望成为AI大模型端边部署的“最优解”,推动AI普惠化和智能社会的到来。未来,大模型算力将像电力一样随处可得、随取随用,真正走进每一条产线、每一台设备、每一个人的指尖。
结论
大模型90%的计算需求向端边迁移已成行业共识。驱动力来自实时性、隐私保护、能效和经济性等多重需求。存算一体技术凭借其突破传统架构瓶颈、极大提升能效和带宽利用率的能力,成为端边大模型部署的核心技术路径。尽管面临工艺、生态等挑战,但在政策、产业和技术多方推动下,存算一体芯片有望在未来十年内实现大规模应用,成为AI芯片领域的主流架构,推动AI普惠化和智能社会的到来。
📢💻 【省心锐评】
“存算一体不是选项而是必然,它终结了数据搬运的能源浪费时代。三年内,端侧AI芯片能效将超越人类神经元。”

评论