.png)


【摘要】阿里巴巴联合多所顶尖研究机构推出的DeepPHY平台,首次系统性地揭示了当前最先进AI视觉模型在物理推理能力上的严重短板。本文深度剖析了AI在动态物理世界中“知行不一”的困境,并探讨了其对未来通用人工智能发展的深远启示。

引言
想象一个孩童在堆叠积木,他似乎凭着一种与生俱来的直觉,便能判断出哪块积木可以稳固地放在另一块之上,哪种结构会瞬间崩塌。又或者,当他看着一个皮球从斜坡上滚落,他能大致预判球的滚动轨迹。这种根植于我们与物理世界无数次互动中的本能理解,我们称之为物理直觉或物理推理。它看似简单,却是构成人类智能的基石。然而,对于我们这个时代最精密的人工智能(AI)而言,这块基石却出奇地脆弱。
近年来,AI,特别是视觉语言模型(VLM),在静态任务上取得了令人瞩目的成就。它们能以超乎人类的准确度识别图像中的物体,能撰写诗歌,能进行复杂的逻辑对话。但当我们要求这些聪明的“数字大脑”从观察者转变为行动者,在动态的物理世界中做出决策时,它们的表现却常常令人大跌眼镜。它们仿佛是博览群书的理论物理学家,能对物理现象侃侃而谈,却在最简单的动手实验中束手无策。
这种“理论”与“实践”的脱节,暴露了当前AI评估体系的巨大盲区。我们习惯于用静态的问答来衡量AI的“智商”,却忽略了智能的本质——在与环境的动态交互中学习、推理和行动。为了填补这一空白,系统性地量化AI在物理世界中的真实能力,一个由阿里巴巴淘宝天猫集团的徐新润团队领衔,联合中国科学院软件研究所、中国科学院大学、中国人民大学以及巴西里约热内卢天主教大学(PUC-Rio)的顶尖学者们,共同构建了一个全新的评估基准——DeepPHY。
这项于2025年8月发表的开创性研究,其论文《DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning》为我们提供了一个前所未有的视角,来审视AI的物理推理能力。DeepPHY不像传统的考卷,它更像一个为AI量身打造的“物理世界游乐场”,内含六个精心设计的、难度各异的交互环境。它迫使AI不再是纸上谈兵,而是必须亲身“下场”,通过行动来证明自己是否真正理解了重力、碰撞、惯性和因果。
本文将带您深入DeepPHY的世界,不仅详细解读其精巧的设计理念和六大考验,更将剖析其揭示出的、令人深思的实验结果。我们将一同探寻为何当今最强大的AI模型,会在这些看似简单的物理任务中惨败,并揭示其背后“描述性知识”与“程序性控制”之间那道难以逾越的鸿 chiffres。这不仅是对当前AI技术的一次全面体检,更是对未来通用人工智能发展方向的一次深刻反思。
🌍 一、AI物理推理的困境:从“知道”到“做到”的鸿沟
%20拷贝.jpg)
在人工智能的星辰大海中,我们常常被那些闪耀的灯塔所吸引:AlphaGo在棋盘上的神之一手,GPT系列在语言生成上的挥洒自如,或是视觉大模型对世间万物的精准识别。这些成就定义了我们对“智能”的想象。然而,这种想象在很大程度上是静态的、非交互的。真正的智能,尤其是能在物理世界中自主运行的通用智能,其核心能力远不止于此。
1.1 现有评估体系的“理论陷阱”
当前的AI评估体系,很大程度上继承了传统的监督学习范式,其核心是“输入-输出”的匹配。这导致了一种“理论陷阱”。
静态问答的局限性:大量的基准测试,如VQA(Visual Question Answering),都集中在静态的问答任务上。你可以给AI看一张图片,问它:“如果我推倒左边的多米诺骨牌,会发生什么?”一个训练有素的模型很可能会根据海量文本和图像数据,给出一个看似完美的答案:“它会引发连锁反应,推倒所有的骨牌。”然而,这个答案是基于模式匹配和知识检索,而非真正的因果推理。它知道“是什么”,但并不理解“为什么”,更不知道“怎么做”。这就像一个学生背熟了所有物理公式,却从未走进实验室亲手验证过任何一个。
过度简化的交互环境:为了让AI具备交互能力,研究者们开发了许多模拟环境。但这些环境往往为了降低复杂性而做出了妥协,无形中绕过了真正的物理推理挑战。
游戏环境:许多游戏AI(如在《星际争霸》或Dota中)虽然需要复杂策略,但它们的观察和动作空间通常是高度抽象的。AI接收的是“单位生命值”、“地图坐标”等高层信息,执行的是“攻击”、“移动”等宏观指令,底层的物理碰撞、寻路等都由游戏引擎处理了。AI无需理解“力”和“质量”的概念。
GUI环境:在网页或软件界面操作的AI,虽然也需要交互,但其面对的是一个逻辑世界,而非物理世界。点击按钮、填写表单,这些行为遵循的是程序逻辑,与现实世界的物理动力学(Physics Dynamics)毫无关系。
机器人环境:机器人模拟环境看似最接近真实,但为了训练效率和稳定性,物理过程往往被极度简化。例如,摩擦力可能被设为一个恒定值,物体的形变被忽略,复杂的流体动力学更是无从谈起。
这种评估体系的缺陷,导致我们对AI的能力产生了系统性的误判。我们像一个只通过笔试来认证飞行员的驾校,培养出的“飞行员”或许能对空气动力学原理对答如流,但一旦坐进驾驶舱,面对真实的气流和复杂的仪表盘,他们可能连如何平稳起飞都做不到。我们高估了AI的理解能力,因为它从未被真正考验过。
1.2 物理推理:通往通用智能的必经之路
为什么物理推理如此重要?因为它代表了一种更根本的智能形式——具身智能(Embodied Intelligence)。一个真正智能的代理(Agent),无论是软件还是机器人,都必须能够:
感知(Perceive):从复杂的传感器数据(如像素)中理解环境状态。
推理(Reason):基于对世界运作规律(尤其是物理规律)的理解,预测不同行为可能产生的后果。
行动(Act):选择并执行能最有效达成目标的动作。
这三者构成了一个闭环。物理推理正是连接“感知”和“行动”的关键桥梁。没有它,AI的行动就是盲目的、随机的。一个无法预测“苹果会从树上掉下来”的机器人,永远不可能学会如何安全地在果园里采摘。一个不理解“惯性”的自动驾驶汽车,在湿滑路面上将是致命的。
因此,DeepPHY的诞生,其意义远不止是又一个基准测试。它是一面镜子,旨在照出现有AI模型在通往真正通用智能道路上的最大短板。它迫使我们正视这个尖锐的问题:我们的AI究竟是真的“理解”了世界,还是仅仅学会了如何巧妙地“模仿”我们对世界的描述?
🔬 二、六重物理世界的考验:DeepPHY的核心设计
DeepPHY的设计哲学,是构建一个多样化且富有挑战性的“物理实验室集群”。它没有选择单一的、大而全的环境,而是精心挑选并改造了六个经典的、各具特色的物理交互环境。每一个环境都像一位严苛的考官,从不同维度对AI的物理推理能力进行深度拷问。这种设计确保了评估的全面性,避免了模型在某一特定类型任务上的“偏科”带来的虚高分数。
下表直观地展示了这六大环境的核心挑战以及AI与人类表现的巨大差距:
2.1 PHYRE:2D物理拼图的智慧
PHYRE (Physical Reasoning) 是一个经典的2D物理拼图环境。任务目标看似简单:在一个静态场景中,你只能放置一个红色的球,利用它来启动一系列连锁反应,最终让场景中已有的绿球碰到蓝色或紫色的目标区域。
挑战所在:这背后需要模型理解一系列复杂的物理概念。它需要预测红球下落后的轨迹,与其他物体碰撞后如何传递能量,如何利用杠杆撬动重物,以及如何维持或打破一个结构的稳定性。研究团队精选了1000个难度各异的任务,从简单的直接碰撞到需要精巧设计的复杂机关。
惊人结果:结果令人大跌眼镜。即便是当前最强大的闭源模型之一GPT-4o,在经过10次试错后,其成功率也仅有23.1%。这个数字对于人类玩家来说几乎是不可思议的低,凸显了AI在基础物理直觉上的巨大鸿沟。
2.2 I-PHYRE:时间的维度
I-PHYRE (Interactive PHYRE) 在PHYRE的基础上增加了一个关键维度:时间。在这里,模型不能再添加物体,而是需要在恰当的时机移除场景中的灰色障碍物。例如,一个球正在来回摆动,你必须在它摆到特定位置时移除下方的平台,才能让它精准地掉入目标。
挑战所在:这要求模型具备**时空推理(Spatiotemporal Reasoning)**的能力。它不仅要理解“在哪里”行动,更要理解“在何时”行动。这需要对物体的运动轨迹和速度有精确的预测。
意外表现:有趣的是,顶级模型在这个环境中的表现相对出色。GPT-4o取得了**81.7%**的成功率。这或许表明,当前的大模型在处理结构化、序列化的决策任务(即在预设的时间点列表中选择一个)时,确实具备一定的能力。但这并不能完全等同于人类那种对时机的直觉把握。
2.3 Kinetix:复杂的动力学控制
Kinetix环境将难度提升到了一个全新的层次。它是一个物理控制实验室,任务目标很明确:控制场景中的绿色物体去接触蓝色目标,同时必须避开所有红色的障碍物。但实现这一目标的方式极其复杂,模型需要同时协调控制多个不同类型的马达和推进器。
挑战所在:Kinetix直接考验模型对**动力学(Kinetics)**的理解和多体协调控制能力。任务被分为S(简单)、M(中等)、L(困难)三个等级。随着需要控制的组件增多,任务的复杂度呈指数级增长。
能力断崖:实验结果清晰地展示了AI能力的“断崖”。在最简单的S级任务中,最好的模型成功率尚能达到60%左右。但到了复杂的L级任务,所有模型的成功率都暴跌至10%以下。这表明,当前AI模型完全不具备处理多组件、高维度协调控制问题的能力,它们的推理能力在复杂性面前迅速崩溃。
2.4 Pooltool:被误解的“完美”
Pooltool是一个高精度的3D台球模拟器。任务是在标准的8球规则下,通过击打最小号码的彩球,最终将9号球送入袋中。这个环境旨在测试模型对精确碰撞、动量传递和长期规划的能力。
挑战所在:真正的台球高手需要考虑击球力度、角度、加塞(旋转效应)等多种因素,来精妙地控制母球和目标球的走位。
误导性成功:一些模型在这里取得了惊人的“完美”成绩。例如,GPT-4o-mini的成功率达到了100%。然而,深入分析其行为策略后,研究者发现这完全是一种假象。该模型采取了一种极其简单粗暴的策略:永远用最大力度,直接瞄准目标球的中心进行撞击。在一些布局简单的球局中,这种“大力出奇迹”的方法确实有效。但它完全忽略了台球运动的精髓——对母球的控制、K球(走位)以及旋转效应的利用。这是一种典型的“钻空子”行为,反映了模型并未真正理解任务的深层目标,只是找到了一个肤浅的最优解。
2.5 Angry Birds:结构与抛射的艺术
风靡全球的《愤怒的小鸟》游戏,被改造成了一个绝佳的物理测试场。模型需要通过调整弹弓的弹射角度和力度,发射小鸟来摧毁由木块、冰块和石块搭建的堡垒,消灭所有绿色小猪。
挑战所在:这个看似简单的游戏,实际上融合了多种物理知识。模型需要理解抛射运动(Projectile Motion)的轨迹,评估不同材料的结构强度,找到堡垒的弱点,并预测撞击后可能引发的连锁反应。
远逊人类:在这个任务中,表现最好的模型Claude 3.5 Sonnet的成功率仅为41.18%,而人类玩家的平均成功率则高达64.71%。这清晰地表明,AI在理解结构力学和规划破坏性策略方面,与人类的直觉相去甚远。
2.6 Cut the Rope:时空推理的终极考验
《割绳子》可能是这六个环境中对AI挑战最大的一个。模型需要通过在精确时机切断绳索、戳破气泡、打开气垫等一系列操作,克服重重障碍,将一颗糖果送到绿色小怪物Om Nom的嘴里。
挑战所在:这个环境是时空推理和复杂物理直觉的集大成者。它要求模型理解绳索的摆动周期、气泡的浮力、气垫的弹力,并能将多个道具的效果进行组合,规划出一条复杂的、时序严格的解决方案。
感知层面的溃败:Cut the Rope暴露了AI模型一个更根本的问题——基础感知能力的缺陷。研究者发现,即使是GPT-4o这样的顶级模型,在被要求“数出图中有几根绳子”时,也常常给出错误的答案。如果连场景中的基本元素都无法准确识别,那么后续的复杂物理推理就成了无源之水、无本之木。这揭示了AI在从卡通化、风格化的视觉信息中提取关键物理要素方面的严重不足。
🛠️ 三、评估方法的革新:为AI打造公平的赛场
%20拷贝.jpg)
要准确评估AI的物理推理能力,就必须确保考试本身是公平的。如果考题本身存在歧义,或者考试方式超出了考生的能力范围,那么考试结果就失去了意义。因此,DeepPHY的研究团队不仅设计了精巧的环境,更在评估方法上进行了大量创新,旨在剥离无关变量,让AI模型能够在一个公平的赛场上,专注于物理推理这一核心能力的较量。
这就像为一群来自不同国家、母语各异的考生准备一场全球性的数学竞赛。你必须用一种通用的、无歧义的语言来呈现题目(观察空间),并提供一种标准化的答题方式(动作空间),这样才能确保竞赛比的是数学能力,而不是语言能力或书写能力。
3.1 观察空间的“降噪”处理
研究团队敏锐地意识到,当前的视觉语言模型虽然强大,但在处理精细、复杂的视觉细节方面存在显著缺陷,尤其是在非真实感渲染的场景中。正如在Cut the Rope中看到的,模型连绳子的数量都数不清。如果直接将原始的游戏截图作为输入,那么模型的失败可能更多地源于“看不懂”,而非“想不明白”。
为了解决这个问题,团队为每个环境的视觉输入都增加了辅助视觉标注,其目标是降低感知负荷,让模型能聚焦于推理。
网格化与标签化:
在PHYRE中,他们在场景图像上叠加了一个5x5的网格,并将可交互的物体用字母标记出来。这样,模型在描述或决定动作时,可以引用具体的网格坐标(如“在C3格放置红球”),而不是模糊的方位描述。
在I-PHYRE和Kinetix中,所有可交互的元素(如可移除的障碍物、马达、推进器)都被打上了清晰的数字标签。
视图转换:
在Pooltool中,原始的3D视角对于AI来说信息过于冗余且难以处理。团队将其转换为更简洁、信息更集中的2D俯视图,并明确标示出所有球的位置、号码以及袋口的位置。
这些改造的本质,是将物理推理问题从复杂的感知问题中解耦出来。这确保了DeepPHY测试的是模型的核心推理能力,而不是它在特定视觉风格下的图像识别能力。
3.2 动作空间的“结构化”简化
另一个巨大的挑战在于动作的输出。物理世界中的动作往往是连续的,例如,击打台球的力度可以是从0到100的任意一个浮点数,角度可以是0到360度的任意值。然而,研究发现,当前的大语言模型在生成这种连续的、多维度的动作参数方面表现极差。它们的“母语”是文本(Token),让它们直接输出精确的浮点数向量,无异于让一位诗人去解微积分方程。
为了绕过这个技术瓶颈,研究团队将所有环境的连续动作空间,都巧妙地转换为了离散的、结构化的格式。
从坐标到选择:在PHYRE中,模型不再需要输出一个连续的(x, y)坐标来放置红球,而是从预先定义的25个网格中选择一个。
从参数到选项:在Pooltool中,复杂的击球力度和旋转参数被简化为几个预定义的离散选项组合,例如{力度: 低/中/高, 旋转: 无/左/右}。模型只需要像做选择题一样,输出一个组合即可。
结构化指令:在Kinetix中,模型需要输出一个结构化的JSON或类似格式的指令,明确指定要激活哪个带标签的马达,以及激活的力度等级(同样是离散的)。
这种“离散化”处理,极大地降低了AI的行动门槛。它让模型可以专注于“做什么”(What to do)的策略思考,而不是被“如何精确地做”(How to do it)的技术细节所困扰。这保证了评估的焦点始终是物理推理本身。
3.3 两种提示策略:检验“真懂”与“假懂”
为了更深入地探究模型的内在能力,研究团队设计了两种不同的提示(Prompting)策略来与模型进行交互。这两种策略旨在测试模型是否仅仅是一个“行为模仿器”,还是真正拥有一个内在的“世界模型”。
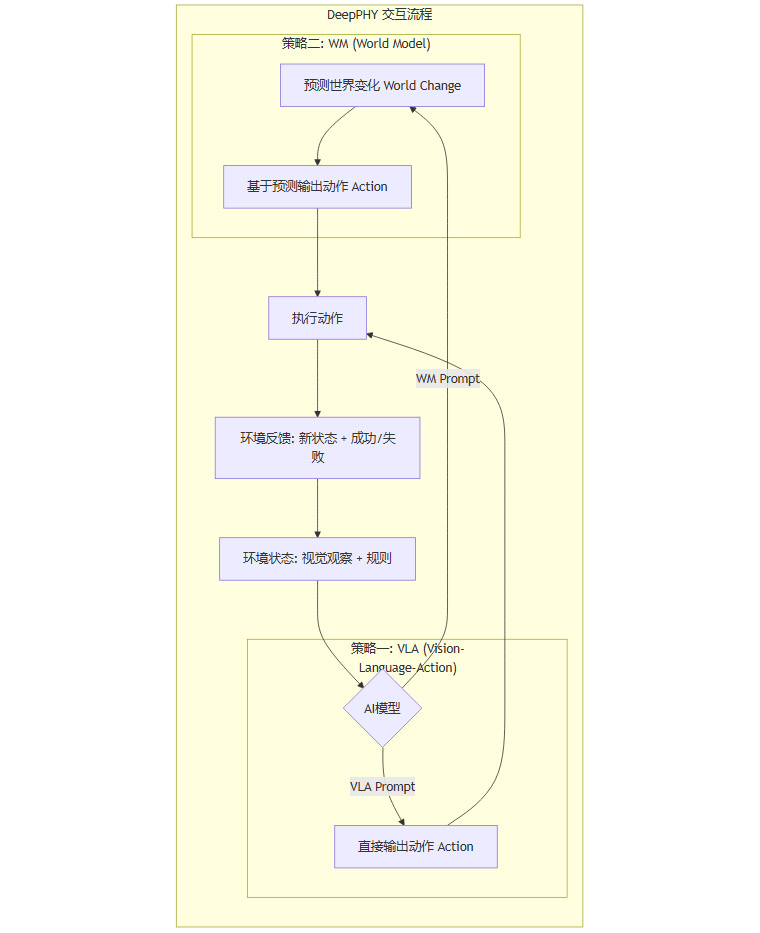
视觉-语言-动作(VLA)格式:这是一种直接的指令式交互。系统向模型提供环境规则、当前的视觉观察(经过标注的图像)以及过去所有失败尝试的历史记录。然后,模型被要求直接输出一个它认为能够成功的动作。这测试的是模型从观察到行动的直接映射能力。
世界模型(WM)格式:这种策略更进一步,它要求模型进行一次“思想实验”。在输出动作之前,模型必须先用自然语言预测这个动作将会导致环境发生什么样的变化。例如,“如果我切断这根绳子,糖果会向下摆动,撞到右边的气垫,然后向上弹起。” 在做出这个预测之后,模型再输出最终的动作。这种设计的目的是检验模型是否具备一个内在的、可预测的物理世界模型。理论上,如果模型能准确预测未来,它的决策质量应该更高。
通过对比这两种策略下的表现,研究者试图回答一个核心问题:AI的物理知识,究竟是能够指导行动的、可执行的程序性知识,还是仅仅停留在口头上的、无法付诸实践的描述性知识?实验结果,正如我们将在下一节看到的,给出了一个出人意料且发人深省的答案。
📊 四、令人震撼的实验结果:AI的物理推理盲区
当DeepPHY的实验数据汇总呈现时,其结果足以让最乐观的AI研究者感到震惊。这并非一次小修小补的性能评估,而是一次近乎残酷的“真相揭露”。它像一盆冷水,浇在了当前AI技术看似火热的躯体上,让我们清醒地认识到,在通往物理世界的道路上,AI还只是一个步履蹒跚的幼儿。
4.1 总体性能:惨淡的现实
开源模型的集体溃败:一个令人沮丧的发现是,几乎所有的开源模型,在DeepPHY的大多数任务中,其表现都无法超越随机行动的基线水平。这意味着,闭上眼睛胡乱操作,其成功率可能都比这些精心训练的AI模型要高。这表明,从海量互联网数据中学到的通用知识,并不能自然地迁移到需要精确物理推理的交互任务中。
顶级模型的表现平平:即便是那些代表了当前最高技术水平的闭源商业模型(如GPT系列、Claude系列),其表现也远未达到“智能”的标准。在最具代表性的PHYRE环境中,表现最好的GPT-4o在10次尝试后的最终成功率仅为23.1%。考虑到这类任务对人类而言通常并不构成巨大挑战,这个数字 starkly 凸显了AI在基本物理直觉上的巨大缺失。
4.2 学习能力的缺失:在失败中原地踏步
真正的智能不仅在于一次成功,更在于从失败中学习和适应的能力。DeepPHY通过允许多次尝试来评估模型的这种能力,但结果同样不容乐观。
低效的试错:在多次尝试的任务中,大多数模型都表现出极低的學習效率。它们似乎无法从上一次的失败中提取有用的信息来指导下一次的决策。例如,在Kinetix中,如果第一次尝试因为动力过大而撞墙,模型在第二次尝试中很可能依然选择同样大的动力,仿佛完全“忘记”了刚刚发生的失败。
无法构建内在世界模型:这种现象的背后,是模型未能建立一个准确的、可更新的内在世界模型。它们无法将“动作A导致了坏结果B”这一经验,内化为对物理世界因果关系的修正。这就像一个学生在做数学题,即使你告诉他前三道题都用错了公式,他依然会在第四道题上使用同样的错误公式,缺乏举一反三和调整策略的能力。
4.3 复杂度诅咒:表现的断崖式下跌
Kinetix环境的难度分级设计,完美地展示了当前AI模型面对复杂性时的脆弱性。
从尚可到崩溃:在简单的S级任务中,一些顶级模型尚能达到50-60%的成功率,表现出一定的控制能力。然而,一旦任务复杂度提升到L级(需要协调更多组件),几乎所有模型的成功率都断崖式地跌至10%以下。
缺乏组合推理能力:这种急剧的性能衰减,暴露了模型在**组合推理(Compositional Reasoning)**上的根本缺陷。它们或许能处理一两个变量的简单因果关系,但无法理解一个由多个相互作用的组件构成的复杂系统。它们无法将对单个马达的控制知识,组合成一个协调整个系统运动的宏观策略。
4.4 反直觉的发现:“思考”越多,表现越差?
在比较VLA(直接行动)和WM(先预测再行动)两种提示策略时,研究团队得到了一个极其反直觉的结论:要求模型预测物理结果的WM策略,在大多数情况下,其表现并不比直接输出动作的VLA策略更好,有时甚至更差。
这个发现是DeepPHY研究中最具洞察力的部分之一。它揭示了一个深刻的问题:AI模型生成的物理描述,与其行为控制之间存在着巨大的鸿沟。 即使模型能够生成一段听起来完全正确的物理预测(例如,“球会向右滚动”),这种描述性的知识似乎并不能被其自身的决策模块有效利用,来生成一个更精确的控制指令。它就像一个能言善辩的体育评论员,能分析场上局势,却无法亲自上场踢好一个球。这种“说”与“做”的脱节,我们将在下一节深入探讨。
4.5 误导性的“完美”与策略的肤浅
Pooltool环境中GPT-4o-mini的100%成功率,是另一个值得警惕的信号。它提醒我们,在评估AI时,必须深入分析其行为策略,而不能仅仅看最终的成功率。
确定性行为的陷阱:研究者发现,当模型的“温度”参数(控制输出的随机性)设定较低时,它会表现出完全确定性的行为,即对于同一个输入,永远输出同一个动作。GPT-4o-mini的“成功”正是在这种设定下,通过一次次重复相同的“大力出奇迹”策略,恰好在第8次尝试时蒙对了。
与智能无关的成功:这种成功与真正的物理推理或策略规划毫无关系。它依赖的是环境的确定性和一种极其简单的、不考虑长期后果的贪心策略。这警示我们,未来的AI评估必须设计得更加巧妙,以防止模型通过这种“钻空子”的方式获得虚高的分数。
🤔 五、深层问题的揭示:描述与控制的鸿沟
%20拷贝.jpg)
DeepPHY的价值不仅在于量化了AI的失败,更在于通过对失败模式的细致分析,揭示了其背后深层次的、系统性的问题。最核心的发现,便是当前AI模型的物理“理解”,在本质上是描述性的(Descriptive),而非预测性(Predictive)和程序性的(Procedural)。这三者的差异,是理解AI物理推理困境的关键。
描述性知识:知道“是什么”。例如,“重力使物体下落”。这是从文本中学到的事实。
预测性知识:知道“会怎样”。例如,“如果我松手,这个苹果会以9.8m/s²的加速度掉向地面”。这需要一个定量的因果模型。
程序性知识:知道“怎么做”。例如,为了接住下落的苹果,我需要计算它的轨迹,并协调我的手部肌肉在正确的时间到达正确的位置。这是将预测转化为行动的控制策略。
当前的大模型,精通第一种知识,对第二种知识的掌握也初见端倪(如WM策略下的预测),但在第三种知识上则几乎完全空白。
5.1 案例研究:Kinetix中的“状态遗忘症”
在Kinetix环境中,一个典型的失败案例生动地展示了这种鸿沟。
第一次尝试:模型面对初始状态,做出了一个堪称完美的预测和行动。它分析道:“绿色物体需要向右上移动。激活左侧和底部的推进器可以提供向右上方的合力,使其远离下方的红色地面和右侧的红色墙壁,从而接近目标。” 随后,它执行了这个动作,物体确实如预期般向目标移动了一段距离,第一次尝试成功。
第二次尝试:现在,物体处于一个新的位置,并且拥有了向右上方运动的初始动量。然而,当被要求进行下一步操作时,模型完全重复了第一次的动作。它似乎“忘记”了物体当前的状态(新的位置和动量),只是机械地重复了上一次成功的策略。结果,物体因为叠加了新的推力和原有的动量,直接一头撞上了右上方的障碍物,任务失败。
这个案例揭示了模型一个致命的缺陷:缺乏状态感知的控制能力(State-aware Control)。它能够基于一个静态的初始状态做出合理的“开环”决策,但无法根据环境中动态变化的状态,进行“闭环”的实时调整。它就像一个只能在出发时规划一次路线的GPS,一旦遇到修路或堵车,它就彻底失灵了,只会固执地让你“在前方路口掉头”。
5.2 感知与推理的断裂
Cut the Rope环境则暴露了更底层的问题:感知与推理的脱节。模型不仅在高级推理上失败,在最基础的视觉感知上就已经步履维艰。
看不懂的卡通世界:当研究人员明确要求模型“数出图中有几根绳子”时,即便是最先进的模型也频繁出错。在研究人员给出提示(“你再仔细看看?”)后,其修正的准确率依然很低。
基础不牢,地动山摇:这种基础感知能力的缺失是灾难性的。如果模型连场景中的关键物理元素(绳索、气泡、怪物)都无法稳定、准确地识别,那么后续的一切推理都建立在了一个错误或不完整的世界表征之上。这就像一个厨师,如果连盐和糖都分不清,无论他的菜谱多么精妙,最终做出的菜肴也必然是失败的。
5.3 时空推理的“失语”
在需要精确时机控制的任务中(如I-PHYRE和Cut the Rope),模型普遍表现出对时间流逝的“无感”。
要么过早,要么过晚:它们的行动往往要么急不可耐,在时机远未成熟时就草草出手;要么犹豫不决,错过了转瞬即逝的最佳窗口。
缺乏直觉节律:人类玩家在玩《割绳子》时,会凭直觉感受到绳索摆动的周期和节奏,从而在摆到最高点(势能最大,动能为零)时切断,以获得最大的水平抛射距离。这种对物理节律的直觉把握,在当前AI模型中完全不存在。它们对时间的理解是离散和抽象的,无法形成连续、动态的时空感知。
总而言之,DeepPHY的研究结果共同指向了一个结论:当前AI的“智能”是一种高度依赖语言符号的、抽象的、静态的智能。当它被迫离开舒适的文本世界,进入充满不确定性、动态变化且需要亲身参与的物理世界时,其能力的脆弱性便暴露无遗。描述世界和改变世界,是两种截然不同的能力,而我们的AI,显然只掌握了前者。
🚀 六、对未来AI发展的深远启示
DeepPHY的研究成果,如同一声响亮的警钟,不仅揭示了当前AI技术的局限,更为未来人工智能的研究与发展指明了方向,带来了极其深远的启示。这些启示超越了技术细节,触及了我们对智能本质的理解。
6.1 重新定义“智能”的评估标准
这项研究最直接的贡献,就是雄辩地证明了评估AI物理推理能力的必要性和紧迫性。
告别静态问答:我们必须摆脱对静态问答式基准的过度依赖。就像评估一名外科医生的能力,不能只靠笔试,必须有临床实践考核一样,评估通用AI的智能水平,也必须引入更多像DeepPHY这样强调动态交互和物理真实性的测试环境。
拥抱具身智能:未来的AI评估,需要更多地从“具身智能”的视角出发,考察AI在感知-推理-行动闭环中的综合表现。这不仅仅是测试AI“知道什么”,更是测试它在真实或模拟的物理世界中“能做什么”。
6.2 训练范式的根本性变革
DeepPHY揭示了当前主流训练方法(即在海量静态文本和图像上进行预训练)的根本缺陷:过分偏重描述性知识,而严重忽视了程序性技能的培养。
从“阅读世界”到“体验世界”:未来的AI训练,需要引入更多包含动态、交互和因果信息的数据。这可能包括:
从视频中学习物理:让AI观看海量的真实世界视频(不仅仅是带字幕的视频),从中自主学习物体的运动规律和相互作用。
强化学习与世界模型:将大规模预训练与在物理模拟器中的强化学习相结合。让AI在虚拟世界中通过数万亿次的“试错”来建立对物理的直觉,并构建一个可预测的内在世界模型。
多模态的统一:不仅仅是视觉和语言,更要融合触觉、力反馈等更多模态的信息,让AI对物理世界的理解更加丰满和立体。
6.3 系统架构的深度整合
“描述与控制的鸿沟”表明,单纯地将一个强大的语言模型和一个视觉编码器拼接起来,并不能创造出一个具备物理智能的代理。
超越模块化拼接:未来的AI系统设计,必须追求感知、推理和控制能力的深度集成。这可能需要全新的AI架构,在这种架构中,语言符号的推理能力和对物理状态的感知、控制能力不再是分离的模块,而是在底层就进行了有机的融合。
端到端的学习:探索更多从原始传感器输入(像素)到低层控制输出(力矩)的端到端学习范式,减少中间人为设计的抽象层,让AI自主发现更有效的世界表征和控制策略。
6.4 对AI安全与可靠性的警示
这项研究对AI在现实世界中的应用,尤其是安全攸关领域的应用,提出了严峻的警示。
物理世界的风险:一个在模拟环境中表现不佳的AI,如果被部署到现实世界的自动驾驶汽车、家用机器人或工业机械臂上,其后果可能是灾难性的。它可能会因为对摩擦力或惯性的错误理解而导致事故。
可靠性的基础:准确的物理推理能力,是AI在物理世界中安全、可靠运行的基础前提。在这一能力得到根本性解决之前,任何将AI大规模部署于需要与物理世界进行复杂交互的场景中的尝试,都必须慎之又慎。
总结
DeepPHY的诞生,是AI发展史上的一个重要里程碑。它如同一面棱镜,折射出当前人工智能光鲜外表下的真实底色。它告诉我们,尽管AI在语言和静态视觉任务上取得了辉煌的成就,但在理解和驾驭我们所生活的这个物理世界方面,它依然处于起步阶段。
这项研究系统性地揭示了“描述性知识”与“程序性控制”之间的巨大鸿沟,让我们清醒地认识到,真正的智能远不止是信息的处理和模式的识别,它更是一种在与世界的动态交互中涌现出的、能够预测未来并有效行动的能力。
然而,揭示问题本身就是解决问题的开始。DeepPHY不仅是一个诊断工具,更是一个研究平台和催化剂。它为全世界的AI研究者提供了一个共同的靶心,激励我们去开发新的模型架构、新的训练范式,去弥合那道知与行之间的鸿沟。
通往真正通用人工智能的道路依然漫长且充满挑战。但正是像DeepPHY这样的研究,以其严谨的科学精神和深刻的洞察力,为我们照亮了前行的道路。它提醒我们,在仰望星空的同时,更要脚踏实地,回归到对“智能”最本源问题的探索上。未来的突破,或许就蕴藏在教会AI如何像孩童一样,去理解一块积木的倒下,一个皮球的滚动之中。
📢💻 【省心锐评】
DeepPHY撕下了当前AI“万能”的假面。它证明了,没有在物理世界摸爬滚打过的“智能”,终究是空中楼阁。真正的突破,在于让AI从“博览群书”的理论家,蜕变为“知行合一”的实践者。

评论